Optimizing Java笔记:高级垃圾回收
原书地址:https://www.safaribooksonline.com/library/view/optimizing-java/9781492039259/
感觉挺不错的一本书,断断续续在读.
来自原书第七章的笔记,记录一些感觉比较重要的概念.
原书这个章节内容比较丰富,笔记只是选择性地进行了一些归纳和简单翻译,建议有兴趣的不妨阅读一下原书.
Tradeoffs and Pluggable Collectors
权衡的可插拔垃圾回收器
在Sun的环境中 GC子系统是可插拔的子系统
GC的运行不能改变程序的语义 但性能上可能会有差异
只有权衡 没有银弹
需要权衡的因素:
- 停顿时间
- 吞吐量(GC所占运行时时间)
- 停顿频率
- 回收效率
- 停顿一致性(是否所有停顿时间大致一样)
并发GC原理
在一些特定的系统 比如动画播放,常常有固定的帧率,用来提供有规律的 固定的机会执行GC.
但通用的GC就不会有这样的知识来提高停顿的确定性了
JVM safepoints
安全点
基于协商
有两个主要规则控制:
- JVM不能强制一个线程进入安全点状态
- JVM可以阻止一个线程离开安全点状态
一个简化的过程:
1.JVM设置一个全局的"time to safepoint" flag.
2.每个应用线程独自拉取这个flag 发现被设置了
3.他们停下并且等待再次醒来
这个标志被设置意味着素有线程都必须停下来.
停的快的线程也要等待还没停的线程停止(这个时间可能不会完全被pause time statistics统计到)
通常的app线程使用poll的机制
解释器会在任意两个字节码之间去检查 JIT编译器通常会在退出编译方法的位置插入一个poll
这个有点像CountDownLatch 所有线程到这个位置了才去做GC
自动在safepoint的状态:
- 正被monitor block了
- 正在执行JNI代码
不可能在safepoint的状态:
- 正执行了部分
bytecode(解释器模式) - 已经被
OS中断了
三色标记
tri-color marking算法
工作原理:
- GC roots染为灰色
- 所有的其他对象染成白色
- 一个标记线程移动到随机的灰色节点上
- 如果这个节点有白色子节点们 标记线程会先将子节点染成灰色 再将该节点染成黑色
- 过程一直进行直到没有灰色节点剩余
- 所有黑色节点已经被证明可达并且必须保持存活
- 白色节点可被回收
并发收集也频繁利用SATB(snapshot at the beginning)
如果对象在收集开始是可达或者在收集之后被分配的 就认为是存活的
这带来了一些额外的工作 需要应用线程在收集过程中创建的对象染黑 非收集过程中的染白
在这个过程中 应用线程会不断改变对像图
还有一个情况是标记黑色的对象在这个过程中又去指向了白色的对象
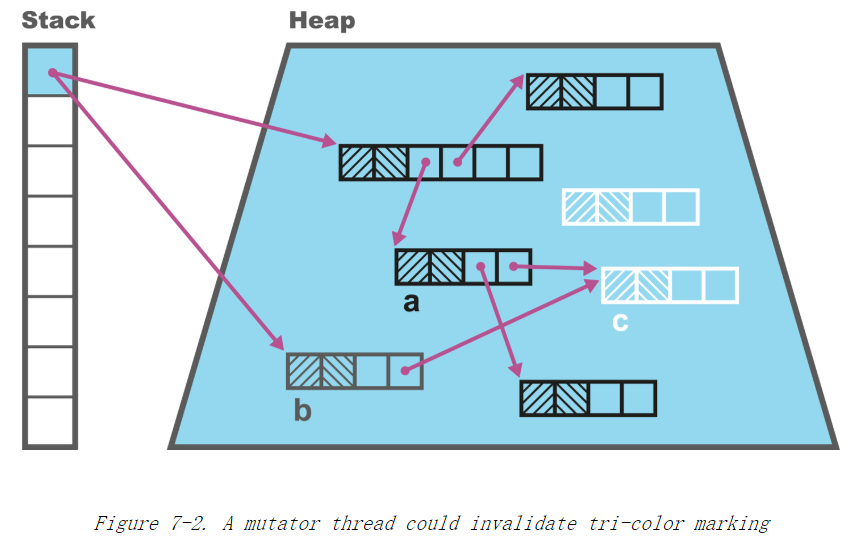
解决方式:
- 黑色更新指向外部白色对象的时候变为灰色
- 不允许黑色指向外部白色对象
- 维护一个修改的队列 然后进行第二轮fixup
以及其他的
CMS
为老年代设计的极其低停顿的收集器
一般和一个轻量修改的年轻代并行收集器一起用(ParNew 而不是Parallel GC)
步骤:
- 初始标记(Initial Mark) STW
- 并发标记(Concurrent Mark)
- 并发预清理(Concurrent Preclean)
- 重标记(Remark) STW
- 并发清理(Concurrent Sweep)
- 并发重置(Concurrent Reset)
将一个长的STW停顿变为两个较短的STW停顿
明显的影响:
- 应用线程不会像之前一样停的久
- 单个完整的GC循环会花得更久
- CMS GC循环的时候应用吞吐量会下降
- GC会花更多的内存跟踪对象
- 使用更多的CPU时间用来进行GC
- CMS不会压缩heap 所以老年代会碎片化
默认情况 CMS会用一半可用线程来处理并发阶段 剩下一半运行Java代码
这时候如果Eden满了…就会触发YGC 但这时候已经没那么多线程了..YGC会更久
YGC之后一些对象可能被提升到老年代了 这两个收集器之间需要一些协调 这也是为什么CMS需要一个稍微不同的Young收集器(ParNew)
另一种情况 如果YGC提升到老年代的对象过多…老年代没有空间…emmmm
就触发了并发模式失败(concurrent mode failure,CMF),JVM只能降级转为使用ParallelOld
为了避免频繁的CMF CMS需要在老年代完全满之前就开始一轮收集循环 默认是75%
另外一个场景会引发CMF的是内存碎片 提升的对象没有连续的内存空间可放
降级的ParallelOld有压缩
使用CMS的主要问题是避免CMF
内部CMS使用一个free list记录内存块来管理可用空间
在Concurrent sweep阶段 连续的可用块会被sweeper线程合并在一起 这样可以提供更大的可用空间块来避免因为内存问题造成的CMF
但这个过程也是并发的 sweeper会锁上free lists.
基本参数
-XX:+UseConcMarkSweepGC
启用CMS(同时激活ParNew)
此外还有60多个参数…
G1
Java6引入 Java7里重写 Java8u40就是可靠和生产可用的
不建议在8u40之前使用他
比CMS更容易优化
对老年代提升更不敏感
在大heap下更好的scale(特别是停顿时间)
能够避免(或大幅降低 回退到)full STW收集
G1和并行GC CMS不同 每代没有专用的 连续空间的内容
此外他也没有沿用半球空间(s0 s1)的布局
G1堆空间和Regions
G1堆基于regions的概念.
默认1M(在更大堆下会更大)
注意G1的堆空间是连续的 只是每代本身不连续
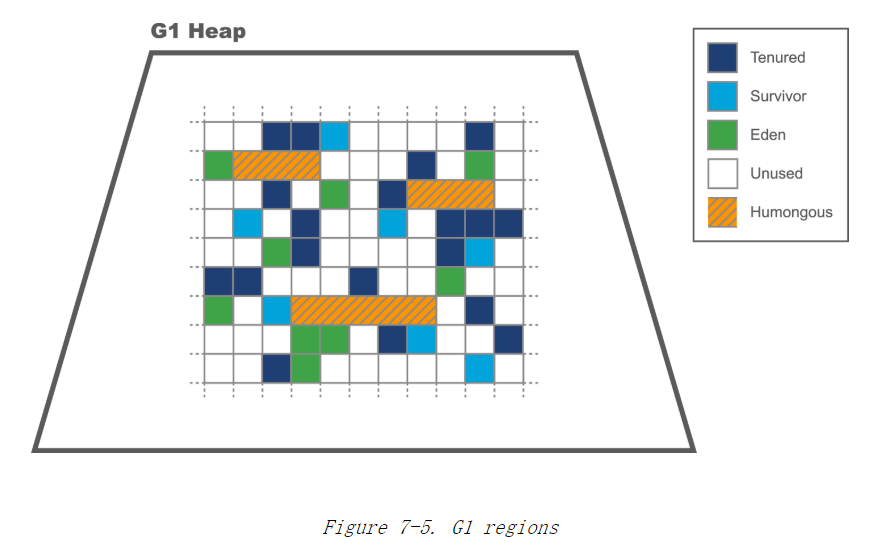
G1的算法允许1 2 4 - 64M 应该为32MB
参考:heapRegionBounds
默认 他期望有2048-4095个regions
G1算法设计
使用并发标记阶段
是一个evacuating(搬空)收集器
提供"基于统计的压缩"(statistical compaction)
如果一个对象占用超过一半一个region的大小 就会被认为是一个巨大(humongous)对象.
直接分配在特殊的humongous regions中.空间连续.
年轻代的概念保留 Eden survivor regions.
但不连续
空间随着整体停顿目标变化.
RSets(remembered sets)
pre-region entries
记录自身对象被外部region对象引用的情况
这个是用来处理ygc时 一部分年轻代对象被老年代引用着
不需要扫描整个heap只要检查这个RSets看看外部有没有老年代的region引用着就好了
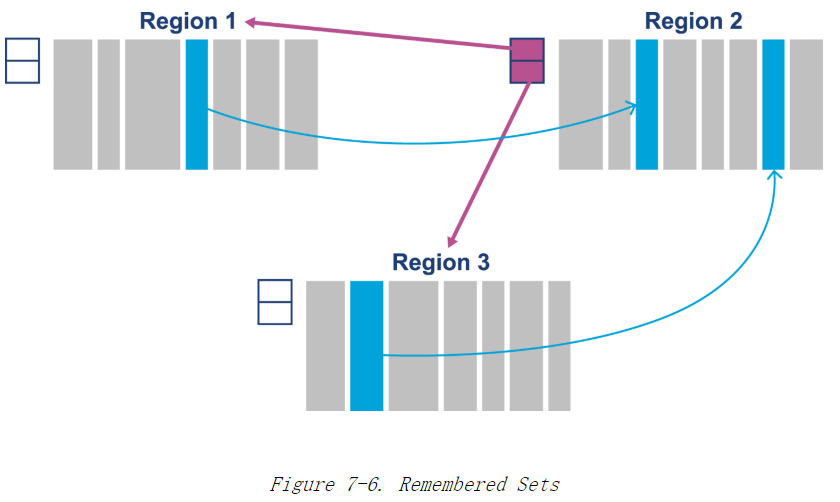
RSets和card table都是帮助GC解决浮动垃圾(floating garbage)的问题. dead对象间的引用.
G1阶段
- 初始标记(Initial Mark) STW
- 并发根扫描(Concurrent Root Scan)
- 并发标记(Concurrent Mark)
- 重标记(Remark) STW
- 清理(Cleanup) STW
基本参数
启用参数
-XX:UseG1GC
G1是基于停顿目标的 允许开发者指定一个期望的停顿最大时间
这只是一个目标 没有保证一定能达成
毕竟回收的的前提是分配 分配过程很多是不可预测的
-XX:MaxFCPauseMillis=200
200ms
实践中 100ms以下的目标是很难达到的
-XX:G1HeapRegionSize=n
必须是2的倍数 1- 64 32 单位是MB
Shenandoah
红帽 openjdk项目
项目wiki:https://wiki.openjdk.java.net/display/shenandoah/Main
还不能用于生产
和G1目的一样 是为了降低大堆下的停顿时间
- 初始标记 (Initial Mark) STW
- 并发标记(Concurrent Marking)
- 最终标记(Final Marking) STW
- 并发压缩(Concurrent Compaction)
阶段看上去类似
一些实现机制比如SATB也相似
但有一些根本上的不同
最显著的特点就是在压缩阶段 应用线程依旧可以访问对象
使用了brooks pointer.
每个对象使用了一个额外的字(word)来标记是否在上一个gc阶段发生了重定位(relocated) 并且放置了新的位置
如果对象没被重放置 brooks pointer指向内存里的下一个字
压缩阶段涉及到复制 在这个过程中复制对象 然后将原对象的字指向新的复制的对象 相当于做了一个路由
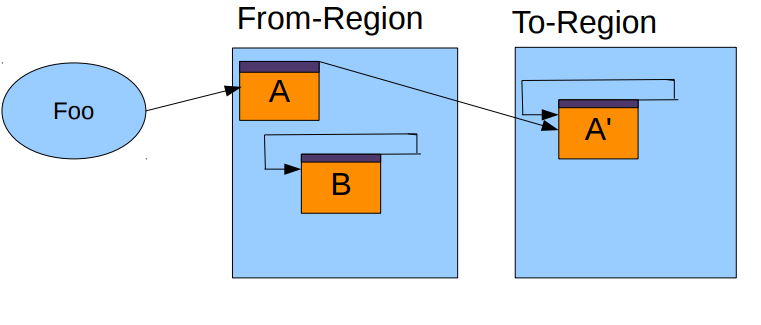
并发压缩
现在的抽空(evacuation)步骤如下:
- 复制对象到
TLAB(冒险的) - 使用
CAS操作更新brooks pointer到那个冒险的副本 - 如果成功 那么压缩线程赢了这次race,之后所有的访问该对象会经过
Brooks pointer - 如果失败 压缩对象失败.那个冒险的副本会被取消,赢得的线程设置
Brooks pointer.
在提供了该回收器上使用
-XX:+UseShenandoahGC
C4(Azul Zing)
Balanced(IBM J9)
Open J9
Lengacy Hotspot Collectors
一些组合在Java8被废弃 在Java9会被移除
Serial和SerialOld
和Parallel ParallelOld类似 但使用单个线程
Incremental CMS(iCMS)
-XX:+CMSIncrementalMode
一些改进尝试 Java9中被移除
Optimizing Java笔记:高级垃圾回收的更多相关文章
- Java虚拟机学习笔记——JVM垃圾回收机制
Java虚拟机学习笔记——JVM垃圾回收机制 Java垃圾回收基于虚拟机的自动内存管理机制,我们不需要为每一个对象进行释放内存,不容易发生内存泄漏和内存溢出问题. 但是自动内存管理机制不是万能药,我们 ...
- Java编程思想学习笔记_1(Java内存和垃圾回收)
1.Java中对象的存储数据的地方: 共有五个不同的地方可以存储数据. 1)寄存器.最快,因为位于处理器的内部,寄存器按需求分配,不能直接控制. 2)堆栈.位于通用RAM,通过堆栈指针可以从处理器那里 ...
- Java虚拟机之垃圾回收详解一
Java虚拟机之垃圾回收详解一 Java技术和JVM(Java虚拟机) 一.Java技术概述: Java是一门编程语言,是一种计算平台,是SUN公司于1995年首次发布.它是Java程序的技术基础,这 ...
- 【java虚拟机序列】java中的垃圾回收与内存分配策略
在[java虚拟机系列]java虚拟机系列之JVM总述中我们已经详细讲解过java中的内存模型,了解了关于JVM中内存管理的基本知识,接下来本博客将带领大家了解java中的垃圾回收与内存分配策略. 垃 ...
- 高吞吐低延迟Java应用的垃圾回收优化
高吞吐低延迟Java应用的垃圾回收优化 高性能应用构成了现代网络的支柱.LinkedIn有许多内部高吞吐量服务来满足每秒数千次的用户请求.要优化用户体验,低延迟地响应这些请求非常重要. 比如说,用户经 ...
- java中存在垃圾回收机制,但是还会有内存泄漏的问题,原因是
答案是肯定的,但不能拿这一句回答面试官的问题.分析:JAVA是支持垃圾回收机制的,在这样的一个背景下,内存泄露又被称为“无意识的对象保持”.如果一个对象引用被无意识地保留下来,那么垃圾回收器不仅不会处 ...
- 每日一问:讲讲 Java 虚拟机的垃圾回收
昨天我们用比较精简的文字讲了 Java 虚拟机结构,没看过的可以直接从这里查看: 每日一问:你了解 Java 虚拟机结构么? 今天我们必须来看看 Java 虚拟机的垃圾回收算法是怎样的.不过在开始之前 ...
- 0030 Java学习笔记-面向对象-垃圾回收、(强、软、弱、虚)引用
垃圾回收特点 垃圾:程序运行过程中,会为对象.数组等分配内存,运行过程中或结束后,这些对象可能就没用了,没有变量再指向它们,这时候,它们就成了垃圾,等着垃圾回收程序的回收再利用 Java的垃圾回收机制 ...
- (转)《深入理解java虚拟机》学习笔记3——垃圾回收算法
Java虚拟机的内存区域中,程序计数器.虚拟机栈和本地方法栈三个区域是线程私有的,随线程生而生,随线程灭而灭:栈中的栈帧随着方法的进入和退出而进行入栈和出栈操作,每个栈帧中分配多少内存基本上是在类结构 ...
随机推荐
- 玩转CSS3(一)----CSS3实现页面布局
请珍惜小编劳动成果,该文章为小编原创,转载请注明出处. 摘要: CSS3相对CSS2增加了一些新的布局方式:多栏布局和盒子布局.在这篇文章中,将对CSS2的布局进行简单的回忆,并总结CSS3的 ...
- C++使用类和对象
1. 内置函数 程序调用函数时需要一定的时间和空间开销,其执行过程一般如下: 而C++提供了一种高效率的方法,即在编译的时候将所调用函数的代码直接嵌入到主函数中,而不是将流程转出去,这样可以避免函数调 ...
- mongoDB身份验证
超级管理员 为了更安全的访问mongodb,需要访问者提供用户名和密码,于是需要在mongodb中创建用户 采用了角色-用户-数据库的安全管理方式 常用系统角色如下:root:只在admin数据库中可 ...
- python反编译工具
开发类在线工具:https://tool.lu/一个反编译网站:https://tool.lu/pyc/ 一看这个标题,就是搞坏事用的, 用 java 写程序多了,很习惯用反编译工具了,而且玩java ...
- memcache 和 redis 之间的区别
结论 应该说Memcached和Redis都能很好的满足解决我们的问题,它们性能都很高,总的来说,可以把Redis理解为是对Memcached的拓展,是更加重量级的实现,提供了更多更强大的功能.具体来 ...
- CSS实现核辐射警告标志
今天做了下360的前端星计划测试题,碰到一个有趣的css题,实现如下图效果,记得上次也是在360面试的时候碰到一个有趣的css实现宝马logo,不得不说360的面试题还是很有创意的. 我一直努力想用一 ...
- BZOJ_3503_[Cqoi2014]和谐矩阵_高斯消元
BZOJ_3503_[Cqoi2014]和谐矩阵_高斯消元 题意: 我们称一个由0和1组成的矩阵是和谐的,当且仅当每个元素都有偶数个相邻的1.一个元素相邻的元素包括它本身,及他上下左右的4个元素(如果 ...
- java.lang.ClassNotFoundException: com.mysql.jdbc.Drive
Linux下使用eclipse开发web项目,运行的时候出现 Java.lang.ClassNotFoundException: com.MySQL.jdbc.Driver,解决办法如下: 1.导入M ...
- Keras框架简介
Keras是基于Theano的一个深度学习框架,它的设计参考了Torch,用Python语言编写,是一个高度模块化的神经网络库,支持GPU和CPU.使用文档在这:http://keras.io/,中文 ...
- 初探机器学习之使用百度EasyDL定制化模型
一.Why 定制化模型 一般来说,各大云服务厂商只会提供一些最常见通用的AI服务,针对具体场景的AI应用则需要在云服务厂商提供的服务之上进行定制.例如,通常的图像识别只能做到分析照片的主题内容,而我的 ...