论文翻译——Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection
Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection
动态池和展开递归自动编码器的意译检测 论文地址
Richard Socher,Eric H. Huang, Jeffrey Pennington∗ , Andrew Y. Ng, Christopher D. Manning
Computer Science Department, Stanford University, Stanford, CA 94305, USA ∗SLAC National Accelerator Laboratory, Stanford University, Stanford, CA 94309, USArichard@socher.org, { ehhuang, jpennin, ang, manning}@stanford.edu Abstract
Abstract
Paraphrase detection** is the task of examining two sentences and determining whether they have the same meaning.
意译检测的任务是检查两个句子,并确定它们是否具有相同的意义。
In order to obtain high accuracy on this task, thorough syntactic and semantic analysis of the two statements is needed.
为了在这项任务中获得较高的准确性,需要对这两个语句进行彻底的语法和语义分析。
We introduce a method for paraphrase detection based on recursive autoencoders (RAE).
介绍了一种基于递归自编码(RAE)的意译检测方法。
Our unsupervised RAEs are based on a novel unfolding objective and learn feature vectors for phrases in syntactic trees.
我们的无监督RAEs是基于一个新的展开目标和学习特征向量的短语在句法树。
These features are used to measure the word- and phrase-wise similarity between two sentences.
这些特征用于测量两个句子之间的词和短语的相似性。
Since sentences may be of arbitrary length, the resulting matrix of similarity measures is of variable size.
由于句子的长度可能是任意的,因此相似度度量的结果矩阵的大小是可变的。
We introduce a novel dynamic pooling layer which computes a fixed-sized representation from the variable-sized matrices.
我们介绍了一个新的动态池层,它从可变大小的矩阵计算固定大小的表示。
The pooled representation is then used as input to a classifier.
然后将池表示用作分类器的输入。
Our method outperforms other state-of-the-art approaches on the challenging MSRP paraphrase corpus.
我们的方法在有挑战性的MSRP释义语料库上优于其他最先进的方法。
1 Introduction
Paraphrase detection determines whether two phrases of arbitrary length and form capture the same meaning.
意译检测确定任意长度和形式的两个短语是否具有相同的含义。
Identifying paraphrases is an important task that is used in information retrieval, question answering [1], text summarization, plagiarism detection [2] and evaluation of machine translation [3], among others.
摘要释义识别是信息检索、问答[1]、文本摘要、抄袭检测[2]、机器翻译评价[3]等领域的一项重要工作。
For instance, in order to avoid adding redundant information to a summary one would like to detect that the following two sentences are paraphrases:
例如,为了避免在摘要中添加冗余信息,可以检测以下两句话是否属于释义:
S1 The judge also refused to postpone the trial date of Sept. 29.
S2 Obus also denied a defense motion to postpone the September trial date
We present a joint model that incorporates the similarities between both single word features as well as multi-word phrases extracted from the nodes of parse trees.
我们提出了一个联合模型,该模型结合了从解析树节点中提取的单字特征和多字短语之间的相似性。
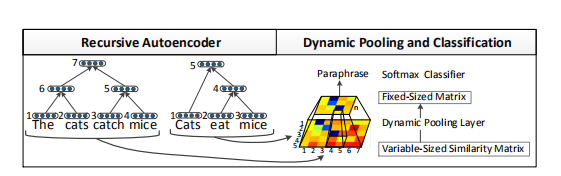
Our model is based on two novel components as outlined in Fig. 1.
我们的模型基于两个新的组件,如图1所示。
The first component is an unfolding recursive autoencoder (RAE) for unsupervised feature learning from unlabeled parse trees.
第一个组件是展开递归自动编码器 (RAE),用于从未标记的解析树中学习非监督特性。
The RAE is a recursive neural network.
RAE是一个递归神经网络。
It learns feature representations for each node in the tree such that the word vectors underneath each node can be recursively reconstructed.
它学习树中每个节点的特征表示,以便可以递归地重构每个节点下的单词向量。
2 Recursive Autoencoders
In this section we describe two variants of unsupervised recursive autoencoders which can be used to learn features from parse trees.
在本节中,我们将描述两种无监督递归自动编码器的变体,它们可用于从解析树中学习特性。
The RAE aims to find vector representations for variable-sized phrases spanned by each node of a parse tree.
RAE的目标是找到由解析树的每个节点张成的可变大小短语的向量表示。
These representations can then be used for subsequent supervised tasks.
这些表示可以用于后续的监督任务。
Before describing the RAE, we briefly review neural language models which compute word representations that we give as input to our algorithm.
在描述RAE之前,我们简要回顾了计算单词表示的神经语言模型,并将其作为算法的输入。
2.1 Neural Language Models
Bengio等人提出的神经语言模型的思想是联合学习将单词嵌入到n维向量空间中,并使用这些向量来预测给定上下文的单词的可能性。
Collobert and Weston [6] introduced a new neural network model to compute such an embedding.
Collobert和Weston[6]提出了一种新的神经网络模型来计算这种嵌入。
When these networks are optimized via gradient ascent the derivatives modify the word embedding matrix L ∈ R ^{n×|V|} , where |V| is the size of the vocabulary.
当这些网络通过梯度上升优化后,其导数修改单词嵌入矩阵L∈R ^{n×|V|},其中|V|是词汇量的大小。
The word vectors inside the embedding matrix capture distributional syntactic and semantic information via the word’s co-occurrence statistics.
嵌入矩阵中的词向量通过词的共现统计信息获取分布的句法和语义信息。
For further details and evaluations of these embeddings, see [5, 6, 7, 8].
有关这些嵌入的进一步细节和评估,请参见[5、6、7、8]。
Once this matrix is learned on an unlabeled corpus, we can use it for subsequent tasks by using each word’s vector (a column in L) to represent that word.
一旦在未标记的语料库上学习了这个矩阵,我们就可以通过使用每个单词的向量(L中的一列)来表示该单词,从而将其用于后续任务。
In the remainder of this paper, we represent a sentence (or any n-gram) as an ordered list of these vectors (x1, . . ., xm).
在本文的其余部分中,我们将一个句子(或任何n-gram)表示为这些向量的有序列表(x1,…,xm)。
This word representation is better suited for autoencoders than the binary number representations used in previous related autoencoder models such as the recursive autoassociative memory (RAAM) model of Pollack [9, 10] or recurrent neural networks [11] since the activations are inherently continuous.
相对于以前相关的自动编码器模型(如Pollack[9,10]的递归自联想记忆(RAAM)模型或递归神经网络[11])中使用的二进制数字表示,这个词表示更适合于自动编码器,因为激活本身是连续的。
2.2 Recursive Autoencoder
Fig. 2 (left) shows an instance of a recursive autoencoder (RAE) applied to a given parse tree as introduced by [12].
图2(左)显示了应用于给定解析树的递归自动编码器(RAE)的实例,由[12]引入。
Unlike in that work, here we assume that such a tree is given for each sentence by a parser.
与前面的工作不同,这里我们假设解析器为每个句子提供了这样的树。
Initial experiments showed that having a syntactically plausible tree structure is important for paraphrase detection.
初步实验表明,具有一个合理的语法树结构对意译检测很重要。
Assume we are given a list of word vectors x = (x1, . . . *, x**m*) as described in the previous section.
假设我们有一个单词向量x = (x1, . . *, x**m*)的列表,如前一节所述。
The binary parse tree for this input is in the form of branching triplets of parents with children: (p → c1c2).
这个输入的二进制解析树是带有子节点的父节点的三个一分支(p → c1c2)。
The trees are given by a syntactic parser.
这些树是由语法分析器给出的。
Each child can be either an input word vector x i or a nonterminal node in the tree.
每个子节点可以是一个输入字向量 x i,也可以是树中的一个非终端节点。
For both examples in Fig. 2, we have the following triplets:
对于图2中的两个例子,我们有以下三个一组:
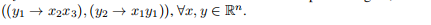
Given this tree structure, we can now compute the parent representations.
给定这个树形结构,我们现在可以计算父表示。
The fifirst parent vector p = y1 is computed from the children (c1, c2) = (x2, x3) by one standard neural network layer:
第五代父向量 p = y1由一标准神经网络层计算得到(c1, c2) = (x2, x3)
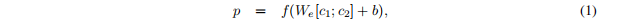
where [c1 c2] is simply the concatenation of the two children, f an element wise activation function such as tanh and *W**e* ∈ R n × 2n the encoding matrix that we want to learn.
其中[c1 c2]是两个子节点的简单拼接,对于tanh和W e* ∈ R n **×* 2n我们要学习的编码矩阵f个元素智能激活函数。
One way of assessing how well this n-dimensional vector represents its direct children is to decode their vectors in areconstruction layer and then to compute the Euclidean distance between the original input and its reconstruction:
评估这个n维向量表示它的直接子向量的一种方法是在构造层中解码它们的向量,然后计算原始输入与其重构之间的欧氏距离:
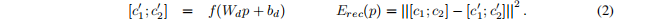
In order to apply the autoencoder recursively, the same steps repeat.
为了递归地应用自动编码器,重复相同的步骤。
Now that y1 is given, we can use Eq. 1 to compute y2 by setting the children to be (c1, c2) = (x1, y1).
现在给定了y1,我们可以使用公式1来计算y2,方法是将子元素设为(c1, c2) = (x1, y1)。
Again, after computing the intermediate parent vector p = y2, we can assess how well this vector captures the content of the children by computing the reconstruction error as in Eq. 2.
同样,在计算中间父向量p = y2之后,我们可以通过计算公式2中的重构误差来评估这个向量捕获子内容的能力。
The process repeats until the full tree is constructed and each node has an associated reconstruction error.
这个过程重复进行,直到构建完整的树,并且每个节点都有一个相关的重构错误。
During training, the goal is to minimize the reconstruction error of all input pairs at nonterminal nodes p in a given parse tree T :
在训练过程中,目标是最小化给定解析树T中所有非末端节点p的输入对的重构误差:
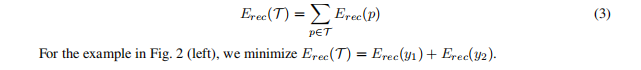
Since the RAE computes the hidden representations it then tries to reconstruct, it could potentially lower reconstruction error by shrinking the norms of the hidden layers.
由于RAE计算隐藏的表示,然后尝试重建,它可以通过缩小隐藏层的规范潜在地降低重建误差。
In order to prevent this, we add a length normalization layer p = p/||p ||to this RAE model (referred to as the standard RAE).
为了防止这种情况,我们在这个RAE模型中添加了一个长度归一化层p = p/||p ||(简称标准RAE)。
Another more principled solution is to use a model in which each node tries to reconstruct its entire subtree and then measure the reconstruction of the original leaf nodes.
另一个更有原则的解决方案是使用一个模型,其中每个节点试图重建其整个子树,然后测量原始叶节点的重建。
Such a model is described in the next section.
下一节将描述这种模型。
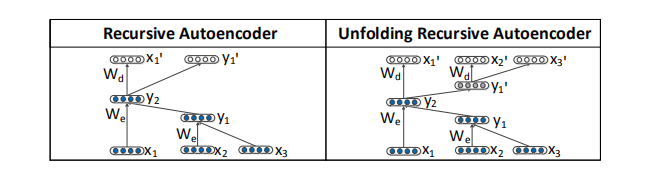
Figure 2: Two autoencoder models with details of the reconstruction at node y2.
图2:两个带有节点y2重构细节的自动编码器模型。
For simplicity we left out the reconstruction layer at the first node y1 which is the same standard autoencoder for both models.
为了简单起见,我们省略了第一个节点的重建层y1,这是两个模型相同的标准自动编码器。
Left: A standard autoencoder that tries to reconstruct only its direct children.
左:一个标准的自动编码器,试图重建它的直接子。
Right: The unfolding autoencoder which tries to reconstruct all leaf nodes underneath each node.
右:展开的自动编码器,它试图重建每个节点下面的所有叶节点。
2.3 Unfolding Recursive Autoencoder
The unfolding RAE has the same encoding scheme as the standard RAE.
展开RAE与标准RAE具有相同的编码方案。
The difference is in the decoding step which tries to reconstruct the entire spanned subtree underneath each node as shown 1in Fig. 2 (right) .
不同之处在于解码步骤,它试图重建每个节点下的整个跨子树,如图2(右)所示1。
For instance, at node y2, the reconstruction error is the difference between the leaf nodes underneath that node [x1 x2 x3] and their reconstructed counterparts [x 01 x 02 x 03].
例如,在节点y2处,重构误差就是该节点下的叶节点[x1 x2 x3]与被重构节点[x01 x02 x03]之间的差值。
The unfolding produces the reconstructed leaves by starting at y2 and computing
展开后,通过从y2开始并进行计算得到重构叶

Then it recursively splits y01 again to produce vectors
然后它再次递归地分解y01来生成向量

In general, we repeatedly use the decoding matrix W d to unfold each node with the same tree structure as during encoding.
一般情况下,我们重复使用解码矩阵W d展开与编码过程中具有相同树结构的每个节点。
The reconstruction error is then computed from a concatenation of the word vectors in that node’s span.
然后根据该节点张成的词向量的串联计算重构误差。
For a node y that spans words i to j:
对于一个节点 y 跨越单词 i 到 j:

The unfolding autoencoder essentially tries to encode each hidden layer such that it best reconstructs its entire subtree to the leaf nodes.
展开的自动编码器本质上是尝试对每个隐藏层进行编码,以便最好地将其整个子树重构到叶节点。
Hence, it will not have the problem of hidden layers shrinking in norm.
因此,它不会有在norm中隐藏层缩小的问题。
Another potential problem of the standard RAE is that it gives equal weight to the last merged phrases even if one is only a single word (in Fig. 2, x1 and y1 have similar weight in the last merge).
标准RAE的另一个潜在问题是,即使最后合并的短语只有一个单词,它也给予相同的权重(在图2中,x1和y1在最后一次合并中具有相似的权重)。
In contrast, the unfolding RAE captures the increased importance of a child when the child represents a larger subtree.
相比之下,当孩子代表一个更大的子树时,展开的RAE抓住了孩子重要性的增加。
2.4 Deep Recursive Autoencoder
Both types of RAE can be extended to have multiple encoding layers at each node in the tree.
这两种类型的RAE都可以扩展为在树中的每个节点上具有多个编码层。
Instead of transforming both children directly into parent p, we can have another hidden layer h in between.
与其直接将两个子元素转换成父元素p,我们可以在它们之间加入另一个隐含层h。
While the top layer at each node has to have the same dimensionality as each child (in order for the same network to be recursively compatible), the hidden layer may have arbitrary dimensionality.
虽然每个节点的顶层必须具有与每个子节点相同的维数(为了使相同的网络递归兼容),但是隐含层可以具有任意的维数。
For the two-layer encoding network, we would replace Eq. 1 with the following:
对于两层编码网络,我们将式1替换为:

2.5 RAE Training
For training we use a set of parse trees and then minimize the sum of all nodes’ reconstruction errors.
对于训练,我们使用一组解析树,然后最小化所有节点重构错误的总和。
We compute the gradient effificiently via backpropagation through structure [13].
通过结构[13]的反向传播有效地计算了梯度。
Even though the objective is not convex, we found that L-BFGS run with mini-batch training works well in practice.
虽然目标不是凸的,但我们发现L-BFGS在实际运行中具有良好的小批量训练效果。
Convergence is smooth and the algorithm typically fifinds a good locally optimal solution.
该算法具有良好的收敛性和局部最优性。
After the unsupervised training of the RAE, we demonstrate that the learned feature representations capture syntactic and semantic similarities and can be used for paraphrase detection.
在对RAE进行无监督训练后,我们证明了所学习的特征表示能够捕获语法和语义的相似性,并可用于意译检测。
3 An Architecture for Variable-Sized Similarity Matrices
Now that we have described the unsupervised feature learning, we explain how to use these features to classify sentence pairs as being in a paraphrase relationship or not.
既然我们已经描述了无监督特征学习,我们解释如何使用这些特征来分类句子对是否属于释义关系。
3.1 Computing Sentence Similarity Matrices
Our method incorporates both single word and phrase similarities in one framework.
我们的方法将单个单词和短语的相似性合并到一个框架中。
First, the RAE computes phrase vectors for the nodes in a given parse tree.
首先,RAE为给定解析树中的节点计算短语向量。
We then compute Euclidean distances between all word and phrase vectors of the two sentences.
然后计算两个句子中所有单词和短语向量之间的欧氏距离。
These distances fifill a similarity matrix S as shown in Fig. 1.
这些距离构成一个相似矩阵S,如图1所示。
For computing the similarity matrix, the rows and columns are fifirst fifilled by the words in their original sentence order.
为了计算相似矩阵,行和列由原来句子顺序的单词填充。
We then add to each row and column the nonterminal nodes in a depth-fifirst, right-to-left order.
然后,我们按照从右到左的顺序,以深度-fifirst的方式将非终端节点添加到每行和列中。
Simply extracting aggregate statistics of this table such as the average distance or a histogram of distances cannot accurately capture the global structure of the similarity comparison.
简单地提取该表的汇总统计信息,例如平均距离或距离直方图,并不能准确地捕获相似性比较的全局结构。
For instance, paraphrases often have low or zero Euclidean distances in elements close to the diagonal of the similarity matrix.
例如,在相似矩阵对角线附近的元素中,释义的欧氏距离通常很低或为零。
This happens when similar words align well between the two sentences.
当相似的单词在两个句子之间排列得很好时,就会发生这种情况。
However, since the matrix dimensions vary based on the sentence lengths one cannot simply feed the similarity matrix into a standard neural network or classififier.
然而,由于矩阵的维数是根据句子长度而变化的,因此不能简单地将相似矩阵输入到标准的神经网络或分类器中。
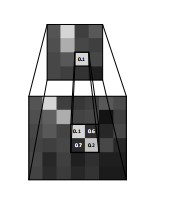
Figure 3: Example of the dynamic min-pooling layer fifinding the smallest number in a pooling window region of the original similarity matrix S.
图3:动态最小池层查找原始相似矩阵S的池窗口区域中的最小数的例子。
3.2 Dynamic Pooling
Consider a similarity matrix S generated by sentences of lengths n and m.
考虑长度为n和m的句子生成的相似矩阵S。
Since the parse trees are binary and we also compare all nonterminal nodes, S ∈ R ^(2n-1)×(2m-1).
由于解析树是二进制的,而且我们还比较了所有非末端节点,所以S∈ R ^(2n-1)×(2m-1)。
We would like to map S into a matrix Spooled of fifixed size, n_p × n_p.
我们希望将S映射到一个大小固定的矩阵池中,即n_p × n_p。
Our fifirst step in constructing such a map is to partition the rows and columns of S into n p roughly equal parts, producing an n_p × n_p grid.
构造这样一个映射的第一步是将S的行和列划分为n p大致相等的部分,生成一个n_p × n_p网格。
We then defifine S pooled to be the matrix of minimum values of each rectangular region within this grid, as shown in Fig. 3.
然后我们将挑战S合并为该网格中每个矩形区域的最小值矩阵,如图3所示。
The matrix S_pooled loses some of the information contained in the original similarity matrix but it still captures much of its global structure.
矩阵S丢失了原始相似矩阵中包含的一些信息,但仍然捕获了它的大部分全局结构。
Since elements of S with small Euclidean distances show that there are similar words or phrases in both sentences, we keep this information by applying a min function to the pooling regions.
由于欧氏距离较小的S元素表示两个句子中有相似的单词或短语,因此我们通过对池区域应用最小函数来保留该信息。
Other functions, like averaging, are also possible, but might obscure the presence of similar phrases. This dynamic pooling layer could make use of overlapping pooling regions, but for simplicity, we consider only non-overlapping pooling regions. After pooling, we normalize each entry to have 0 mean and variance 1.
其他函数,比如求平均值,也是可能的,但是可能会掩盖类似短语的存在。这个动态池化层可以利用重叠池化区域,但是为了简单起见,我们只考虑非重叠池化区域。合并后,我们将每个条目标准化,使其均值为0,方差为1。

Table 1: Nearest neighbors of randomly chosen phrases.
表1:随机选择的短语的最近邻居。
Recursive averaging and the standard RAE focus mostly on the last merged words and incorrectly add extra information.
递归平均和标准RAE主要关注最后合并的单词,并错误地添加额外的信息。
The unfolding RAE captures most closely both syntactic and semantic similarities.
展开的RAE最接近地捕捉到了句法和语义的相似性。
1 The partitions will only be of equal size if 2n n 1 and 2m m 1 are divisible by n_p.
只有当2n n 1和2m m 1能被n_p整除时,分区的大小才相等。
We account for this in the following way, although many alternatives are possible.
我们用下面的方法来说明这一点,尽管有许多可能的替代方法。
Let the number of rows of S be R = 2n-1.
令S的行数R = 2n-1。
Each pooling window then has [R/n_p] many rows.
每个池化窗口都有[R/n_p]多行。
Let M = R mod n_p, be the number of remaining rows.
设M = R mod n_p,为剩余行数。
We then evenly distribute these extra rows to the last M window regions which will have [ R/n_p] + 1 rows.
然后我们将这些额外的行均匀地分布到最后的M窗口区域,这些区域将有[R/n_p] + 1行。
The same procedure applies to the number of columns for the windows.
同样的过程也适用于窗口的列数。
This procedure will have a slightly fifiner granularity for the single word similarities which is desired for our task since word overlap is a good indicator for paraphrases.
这个过程将对单个单词的相似性有更细的粒度,这是我们的任务所需要的,因为单词重叠是解释的一个很好的指示器。
In the rare cases when n_p > R, the pooling layer needs to fifirst up-sample.
在极少数情况下,当n_p > R,池层需要fifirst up-sample。
We achieve this by simply duplicating pixels row-wise until R ≥ n_p.
我们通过简单地复制像素行,直到R ≥ n_p来实现这一点。
4 Experiments
For unsupervised RAE training we used a subset of 150,000 sentences from the NYT and AP sections of the Gigaword corpus.
在无人监督的RAE培训中,我们使用了来自《纽约时报》和美联社的十五万个句子。
We used the Stanford parser [14] to create the parse trees for all sentences.
我们使用Stanford parser[14]来创建所有句子的解析树。
For initial word embeddings we used the 100-dimensional vectors computed via the unsupervised method of Collobert and Weston [6] and provided by Turian et al. [8].
对于初始词嵌入,我们使用了由Turian等人提供的Collobert和Weston[6]的无监督方法计算的100维向量。
For all paraphrase experiments we used the Microsoft Research paraphrase corpus (MSRP) introduced by Dolan et al. [4].
对于所有的释义实验,我们都使用了Dolan等人引入的微软研究释义语料库(MSRP)。
The dataset consists of 5,801 sentence pairs.
数据集由5801个句子对组成。
The average sentence length is 21, the shortest sentence has 7 words and the longest 36.
平均句子长度为21个,最短的有7个单词,最长的有36个单词。
3,900 are labeled as being in the paraphrase relationship (technically defifined as “mostly bidirectional entailment”).
有3900个被标注为“释义关系”(严格意义上说,是“基本上是双向隐含关系”)。
We use the standard split of 4,076 training pairs (67.5% of which are paraphrases) and 1,725 test pairs (66.5% paraphrases).
我们使用了4076个训练对(其中67.5%是释义)和1725个测试对(66.5%是释义)的标准分割。
All sentences were labeled by two annotators who agreed in 83% of the cases.
所有的句子都由两名注释员标注,83%的情况下,两名注释员表示同意。
A third annotator resolved conflflicts.
第三个注释者解决了冲突。
During dataset collection, negative examples were selected to have high lexical overlap to prevent trivial examples.
在数据集收集的过程中,为了避免琐碎的例子,我们选择了负例来进行词汇重叠。
For more information see [4, 15].
更多信息见[4,15]。
As described in Sec. 2.4, we can have deep RAE networks with two encoding or decoding layers.
如第2.4节所述,我们可以有两个编码或解码层的深层RAE网络。
The hidden RAE layer (see h in Eq. 8) was set to have 200 units for both standard and unfolding RAEs
隐藏的RAE层(参见公式8中的h)被设置为标准RAE和展开RAE都有200个单元
.
4.1 Qualitative Evaluation of Nearest Neighbors
In order to show that the learned feature representations capture important semantic and syntactic information even for higher nodes in the tree, we visualize nearest neighbor phrases of varying length.
为了证明所学习的特征表示能够捕获重要的语义和语法信息,甚至对于树中的较高节点,我们可视化了不同长度的最近邻短语。
After embedding sentences from the Gigaword corpus, we compute nearest neighbors for all nodes in all trees.
在嵌入来自Gigaword语料库的句子之后,我们为所有树中的所有节点计算最近的邻居。
In Table 1 the fifirst phrase is a randomly chosen phrase and the remaining phrases are the closest phrases in the dataset that are not in the same sentence.
在表1中,第一个短语是随机选择的短语,其余的短语是数据集中不属于同一句话的最接近的短语。
We use Euclidean distance between the vector representations.
我们使用向量表示之间的欧氏距离。
Note that we do not constrain the neighbors to have the same word length.
注意,我们不限制相邻的单词具有相同的长度。
We compare the two autoencoder models above: RAE and unfolding RAE without hidden layers, as well as a recursive averaging baseline (R.Avg).
我们比较了以上两种自动编码器模型:无隐含层的RAE和展开RAE,以及递归平均基线(r.a avg)。
R.Avg recursively takes the average of both child vectors in the syntactic tree.
R.Avg递归地取句法树中两个子向量的平均值。
We only report results of RAEs without hidden layers between the children and parent vectors.
我们只报告子向量和父向量之间没有隐藏层的rae的结果。
Even though the deep RAE networks have more parameters to learn complex encodings they do not perform as well in this and the next task.
尽管深层RAE网络有更多的参数来学习复杂的编码,但它们在这个和下一个任务中表现得并不好。
This is likely due to the fact that they get stuck in local optima during training.
这可能是由于他们在训练时卡在了局部的optima中。
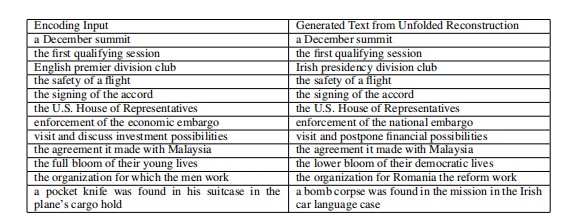
Table 2: Original inputs and generated output from unfolding and reconstruction.
表2:展开和重构的原始输入和生成的输出。
Words are the nearest neighbors to the reconstructed leaf node vectors.
单词是重构的叶节点向量的最近邻。
The unfolding RAE can reconstruct perfectly almost all phrases of 2 and 3 words and many with up to 5 words.
展开的RAE可以完美地重构几乎所有2 - 3个单词的短语,许多短语最多可以重构5个单词。
Longer phrases start to get incorrect nearest neighbor words.
较长的短语开始出现不正确的近邻词。
For the standard RAE good reconstructions are only possible for two words.
对于标准的RAE,好的重构只可能是两个词。
Recursive averaging cannot recover any words.
递归平均不能恢复任何单词。
Table 1 shows several interesting phenomena.
表1显示了几个有趣的现象。
Recursive averaging is almost entirely focused on an exact string match of the last merged words of the current phrase in the tree.
递归平均几乎完全集中于树中当前短语的最后合并单词的精确字符串匹配。
This leads the nearest neighbors to incorrectly add various extra information which would break the paraphrase relationship if we only considered the top node vectors and ignores syntactic similarity.
这将导致最近的邻居错误地添加各种额外信息,如果只考虑顶部节点向量而忽略语法相似性,则会破坏释义关系。
The standard RAE does well though it is also somewhat focused on the last merges in the tree.
标准的RAE做得很好,尽管它也在一定程度上关注于树中的最后合并。
Finally, the unfolding RAE captures most closely the underlying syntactic and semantic structure.
最后,展开的RAE最接近地捕获了底层的语法和语义结构。
4.2 Reconstructing Phrases via Recursive Decoding
In this section we analyze the information captured by the unfolding RAE’s 100-dimensional phrase vectors.
在本节中,我们将分析由展开的RAE的100维短语向量捕获的信息。
We show that these 100-dimensional vector representations can not only capture and memorize single words but also longer, unseen phrases.
我们证明了这些100维的向量表示不仅可以捕获和记忆单个单词,还可以捕获和记忆更长的、看不见的短语。
In order to show how much of the information can be recovered we recursively reconstruct sentences after encoding them.
为了显示有多少信息可以被恢复,我们在编码后递归地重构句子。
The process is similar to unfolding during training.
这个过程类似于在训练中展开。
It starts from a phrase vector of a nonterminal node in the parse tree.
它从解析树中一个非终结节点的短语向量开始。
We then unfold the tree as given during encoding and fifind the nearest neighbor word to each of the reconstructed leaf node vectors.
然后我们按照编码时给出的树展开,找到每个重构叶节点向量的最近邻。
Table 2 shows that the unfolding RAE can very well reconstruct phrases of up to length fifive.
表2显示,展开的RAE可以很好地重构长度为fi5的短语。
No other method that we compared had such reconstruction capabilities.
我们比较的其他方法都没有这样的重构能力。
Longer phrases retain some correct words and usually the correct part of speech but the semantics of the words get merged.
较长的短语保留了一些正确的词,通常也保留了正确的词性,但这些词的语义却被合并了。
The results are from the unfolding RAE that directly computes the parent representation as in Eq. 1.
结果来自于直接计算如式(1)中的父表示的展开RAE。
4.3 Evaluation on Full-Sentence Paraphrasing
We now turn to evaluating the unsupervised features and our dynamic pooling architecture in our main task of paraphrase detection.
现在,我们将在主要的意译检测任务中评估非监督特性和动态池架构。
Methods which are based purely on vector representations invariably lose some information.
纯粹基于向量表示的方法总是会丢失一些信息。
For instance, numbers often have very similar representations, but even small differences are crucial to reject the paraphrase relation in the MSRP dataset.
例如,数字通常具有非常相似的表示,但是即使是很小的差异对于拒绝MSRP数据集中的释义关系也是至关重要的。
Hence, we add three number features.
因此,我们添加了三个数字特性。
The fifirst is 1 if two sentences contain exactly the same numbers or no number and 0 otherwise, the second is 1 if both sentences contain the same numbers and the third is 1 if the set of numbers in one sentence is a strict subset of the numbers in the other sentence.
fifirst是1如果两个句子包含完全相同的数字或没有数量和0否则,第二个是1如果两个句子包含相同的数字和第三是1如果数字的集合在一个句子是一个严格的子集的数据在另一个句子。
Since our pooling-layer cannot capture sentence length or the number of exact string matches, we also add the difference in sentence length and the percentage of words and phrases in one sentence that are in the other sentence and vice-versa.
由于我们的池化层不能捕获句子长度或精确字符串匹配的数量,所以我们还添加了句子长度的差异以及一个句子中的单词和短语在另一个句子中的百分比,反之亦然。
We also report performance without these three features (only S).
我们还报告了没有这三个特性的性能(只有S)。
For all of our models and training setups, we perform 10-fold cross-validation on the training set to choose the best regularization parameters and n_p, the size of the pooling matrix S ∈ Rn_p×n_p .
对于我们所有的模型和训练设置,我们对训练集进行10次交叉验证,选择最佳的正则化参数和n_p,池矩阵S∈ Rn_p×n_p的大小。
In our best model, the regularization for the RAE was 10^-5 and 0.05 for the softmax classififier.
在我们的最佳模型中,RAE的正则化为10^ (-5),softmax分类器的正则化为0.05。
The best pooling size was consistently n_p = 15, slightly less than the average sentence length.
最佳的池大小始终是n_p = 15,略小于平均句子长度。
For all sentence pairs (S1, S2) in the training data, we also added (S2, S1) to the training set in order to make the most use of the training data.
对于训练数据中所有的句子对(S1, S2),我们也将(S2, S1)添加到训练集中,以便最大限度地利用训练数据。
This improved performance by 0.2%.
这使性能提高了0.2%。
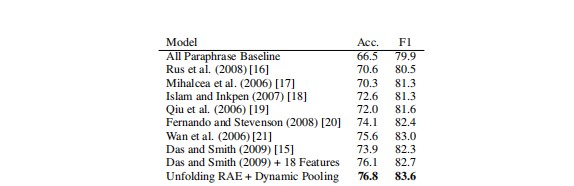
Table 3: Test results on the MSRP paraphrase corpus.
表3:MSRP释义语料库测试结果。
Comparisons of unsupervised feature learning methods (left), similarity feature extraction and supervised classifification methods (center) and other approaches (righ).
无监督特征学习方法(左)、相似特征提取方法(中)和监督分类方法(右)的比较。
In our fifirst set of experiments we compare several unsupervised feature learning methods: Recursive averaging as defifined in Sec. 4.1, standard RAEs and unfolding RAEs.
在我们的第5组实验中,我们比较了几种无监督特征学习方法:4.1节中的递归平均法、标准RAEs法和展开RAEs法。
For each of the three methods, we cross-validate on the training data over all possible hyperparameters and report the best performance.
对于这三种方法,我们在所有可能的超参数上交叉验证训练数据,并报告最佳性能。
We observe that the dynamic pooling layer is very powerful because it captures the global structure of the similarity matrix which in turn captures the syntactic and semantic similarities of the two sentences.
我们注意到,动态池层非常强大,因为它捕获了相似矩阵的全局结构,而相似矩阵又捕获了两个句子的语法和语义相似性。
With the help of this powerful dynamic pooling layer and good initial word vectors even the standard RAE and recursive averaging perform well on this dataset with an accuracy of 75.5% and 75.9% respectively.
在这个强大的动态池化层和良好的初始字向量的帮助下,即使是标准的RAE和递归平均在这个数据集上也有很好的表现,其准确性分别为75.5%和75.9%。
We obtain the best accuracy of 76.8% with the unfolding RAE with out hidden layers.
我们获得了最佳的精度为76.8%的展开RAE与外隐层。
We tried adding 1 and 2 hidden encoding and decoding layers but performance only decreased by 0.2% and training became slower.
我们尝试添加1层和2层隐藏的编码和解码层,但性能只下降了0.2%,训练速度变慢。
A histogram of values in the matrix S.
矩阵S中的值的直方图。
The low performance shows that our
低的性能表明我们的
dynamic pooling layer better captures the global similarity information than aggregate statistics.
动态池化层比聚合统计信息更好地捕获全局相似信息。
(ii) Only Feat: 73.2%.
(ii)只完成壮举:73.2%。
Only the three features described above.
只有上面描述的三个特性。
This shows that simple binary string and number matching can detect many of the simple paraphrases but fails to detect complex cases.
这表明,简单的二进制字符串和数字匹配可以检测许多简单的释义,但不能检测复杂的情况。
(iii) Only Spooled: 72.6%.
(iii)只有S池:72.6%。
Without the three features mentioned above.
没有上面提到的三个特征。
This shows that some infor mation still gets lost in Spooled and that a better treatment of numbers is needed.
这表明一些信息仍然丢失在S池中,需要更好的数字处理。
In order to better recover exact string matches it may be necessary to explore overlapping pooling regions.
为了更好地恢复精确的字符串匹配,可能需要探索重叠池区域。
(iv) Top Unfolding RAE Node: 74.2%.
(iv)顶部展开RAE节点:74.2%。
Instead of Spooled, use Euclidean distance between the two top sentence vectors.
而不是S池,使用欧几里德距离之间的两个顶级句子向量。
The performance shows that while the unfolding RAE is by itself very powerful, the dynamic pooling layer is needed to extract all information from its trees.
性能表明,虽然展开的RAE本身非常强大,但是需要动态池化层从其树中提取所有信息。
Table 3 shows our results compared to previous approaches (see next section).
表3显示了与以前方法相比的结果(参见下一节)。
Our unfolding RAE and dynamic similarity pooling architecture achieves state-of-the-art performance without hand designed semantic taxonomies and features such as WordNet.
我们的展开RAE和动态相似池架构实现了最先进的性能,而无需手工设计语义分类和特性,如WordNet。
Note that the effective range of the accuracy lies between 66% (most frequent class baseline) and 83% (interannotator agreement).
注意,精确度的有效范围在66%(最常见的类基线)和83%(注释者间协议)之间。

In Table 4 we show several examples of correctly classifified paraphrase candidate pairs together with their similarity matrix after dynamic min-pooling.
在表4中,我们展示了几个例子的正确分类意译候选对及其相似矩阵后,动态最小池。
The fifirst and last pair are simple cases of paraphrase and not paraphrase.
第5和最后一对是简单的释义和非释义。
The second example shows a pooled similarity matrix when large chunks are swapped in both sentences.
第二个例子显示了在两个句子中交换大块时合并的相似矩阵。
Our model is very robust to such transformations and gives a high probability to this pair.
我们的模型对这样的转换非常健壮,并且对这一对有很高的概率。
Even more complex examples such as the third with very few direct string matches (few blue squares) are correctly classifified.
甚至更复杂的例子,如直接匹配很少的第三个字符串(很少的蓝色方块),也可以正确地分类。
The second to last example is highly interesting.
倒数第二个例子非常有趣。
Even though there is a clear diagonal with good string matches, the gap in the center shows that the fifirst sentence contains much extra information.
尽管有一条明显的对角线,而且字符串匹配得很好,但中间的空白表明第一个句子包含了很多额外的信息。
This is also captured by our model.
我们的模型也捕捉到了这一点。
5 Related Work
The fifield of paraphrase detection has progressed immensely in recent years.
近年来,意译检测领域发展迅速。
Early approaches were based purely on lexical matching techniques [22, 23, 19, 24].
早期的方法完全基于词汇匹配技术[22,23,19,24]。
Since these methods are often based on exact string matches of n-grams, they fail to detect similar meaning that is conveyed by synonymous words.
由于这些方法通常基于n-gram的精确字符串匹配,因此无法检测同义词所表达的类似含义。
Several approaches [17, 18] overcome this problem by using Wordnet and corpus-based semantic similarity measures.
有几种方法[17,18]通过使用Wordnet和基于语料库的语义相似度度量来克服这个问题。
In their approach they choose for each open-class word the single most similar word in the other sentence.
在他们的方法中,他们为每一个开放类单词选择另一个句子中最相似的单词。
Fernando and Stevenson [20] improved upon this idea by computing a similarity matrix that captures all pair-wise similarities of single words in the two sentences.
Fernando和Stevenson[20]通过计算一个相似矩阵改进了这一思想,该矩阵捕获了两个句子中单个单词的所有成对相似点。
They then threshold the elements of the resulting similarity matrix and compute the mean of the remaining entries.
然后,他们对产生的相似矩阵的元素进行阈值,并计算其余元素的平均值。
There are two shortcomings of such methods: They ignore (i) the syntactic structure of the sentences (by comparing only single words) and (ii) the global structure of such a similarity matrix (by computing only the mean).
这种方法有两个缺点:一是忽略了句子的句法结构(只比较单个单词);二是忽略了这种相似矩阵的整体结构(只计算平均值)。
Table 4: Examples of sentence pairs with: ground truth labels L (P - Paraphrase, N - Not Paraphrase), the probabilities our model assigns to them (P r(S1, S2) > 0.5 is assigned the label Paraphrase) and their similarity matrices after dynamic min-pooling.
表4:与:ground truth label L (P - ase, N - Not ase)配对的句子例子,我们的模型赋予它们的概率(P r(S1, S2) > 0.5被赋予标签释义)以及它们的相似矩阵经过动态min-pooling。
Simple paraphrase pairs have clear diagonal structure due to perfect word matches with Euclidean distance 0 (dark blue).
简单的意译对有清晰的对角线结构,因为完美的单词匹配欧几里德距离0(深蓝色)。
That structure is preserved by our min-pooling layer.
这个结构被我们的min-pooling层保留了下来。
Best viewed in color.See text for details.
彩色效果最佳。详情见正文。
Instead of comparing only single words [21] adds features from dependency parses.
[21]没有只比较单个单词,而是添加了依赖项解析的特性。
Most recently, Das and Smith [15] adopted the idea that paraphrases have related syntactic structure.
最近,Das和Smith[15]采用了意译具有相关句法结构的思想。
Their quasisynchronous grammar formalism incorporates a variety of features from WordNet, a named entity recognizer, a part-of-speech tagger, and the dependency labels from the aligned trees.
它们的准同步语法形式合并了来自WordNet、命名实体识别器、词性标记器和来自对齐树的依赖标签的各种特性。
In order to obtain high performance they combine their parsing-based model with a logistic regression model that uses 18 hand-designed surface features.
为了获得高性能,他们将基于解析的模型与使用18个手工设计的表面特征的逻辑回归模型相结合。
We merge these word-based models and syntactic models in one joint framework: Our matrix consists of phrase similarities and instead of just taking the mean of the similarities we can capture the global layout of the matrix via our min-pooling layer.
我们将这些基于单词的模型和语法模型合并在一个联合框架中:我们的矩阵由短语相似性组成,而不是仅仅取相似性的平均值,我们可以通过最小池层捕获矩阵的全局布局。
The idea of applying an autoencoder in a recursive setting was introduced by Pollack [9] and extended recently by [10].
在递归设置中应用自动编码器的想法是由Pollack[9]提出的,最近由[10]扩展。
Pollack’s recursive auto-associative memories are similar to ours in that they are a connectionist, feedforward model.
波拉克的递归自动联想记忆与我们的类似,因为它们是一种连接主义的前馈模型。
One of the major shortcomings of previous applications of recursive autoencoders to natural language sentences was their binary word representation as discussed in Sec. 2.1.
以前递归自动编码器在自然语言句子中的一个主要缺点是它们的二进制单词表示,如2.1节所述。
Recently, Bottou discussed related ideas of recursive autoencoders [25] and recursive image and text understanding but without experimental results.
最近,Bottou讨论了递归自动编码器[25]和递归图文理解的相关思想,但没有实验结果。
Larochelle [26] investigated autoencoders with an unfolded “deep objective”.
Larochelle[26]用展开的“深度目标”研究了自动编码器。
Supervised recursive neural networks have been used for parsing images and natural language sentences by Socher et al. [27, 28].
Socher等[27,28]曾将监督递归神经网络用于图像和自然语言句子的解析。
Lastly, [12] introduced the standard recursive autoencoder as mentioned in Sect. 2.2.
最后,[12]引入了2.2节中提到的标准递归自动编码器。
6 Conclusion
We introduced an unsupervised feature learning algorithm based on unfolding, recursive autoencoders.
介绍了一种基于展开递归自编码的无监督特征学习算法。
The RAE captures syntactic and semantic information as shown qualitatively with nearest neighbor embeddings and quantitatively on a paraphrase detection task.
RAE捕获语法和语义信息,定性地显示最近邻嵌入,定量地显示释义检测任务。
Our RAE phrase features allow us to compare both single word vectors as well as phrases and complete syntactic trees.
我们的RAE短语特性允许我们比较单个单词向量以及短语和完整的语法树。
In order to make use of the global comparison of variable length sentences in a similarity matrix we introduce a new dynamic pooling architecture that produces a fifixed-sized representation.
为了在相似矩阵中利用变长句的全局比较,我们引入了一种新的动态池结构,它产生一个固定大小的表示。
We show that this pooled representation captures enough information about the sentence pair to determine the paraphrase relationship on the MSRP dataset with a higher accuracy than any previously published results.
我们表明,这个集合表示捕获了关于句子对的足够信息,从而能够在MSRP数据集上以比以前发布的任何结果更高的精度确定释义关系。
References
[1] E. Marsi and E. Krahmer. Explorations in sentence fusion. In European Workshop on Natural Language Generation, 2005.
句子融合的探索。在欧洲自然语言生成研讨会上
[2] P. Clough, R. Gaizauskas, S. S. L. Piao, and Y. Wilks. METER: MEasuring TExt Reuse. In ACL, 2002.
测量文本重用
[3] C. Callison-Burch. Syntactic constraints on paraphrases extracted from parallel corpora. In Proceedings of EMNLP, pages 196–205, 2008.
从平行语料库中提取意译的句法约束
[4] B. Dolan, C. Quirk, and C. Brockett. Unsupervised construction of large paraphrase corpora: exploiting massively parallel news sources. In COLING, 2004.
大型释义语料库的无监督构建:利用大量并行的新闻来源
[5] Y. Bengio, R. Ducharme, P. Vincent, and C. Janvin. A neural probabilistic language model. j. Mach.Learn. Res., 3, March 2003.
神经概率语言模型
[6] R. Collobert and J. Weston. A unifified architecture for natural language processing: deep neural network, with multitask learning. In ICML, 2008.
自然语言处理的统一架构:具有多任务学习的深度神经网络
[7] Y. Bengio, J. Louradour, Collobert R, and J. Weston. Curriculum learning. In ICML, 2009.
课程学习
[8] J. Turian, L. Ratinov, and Y. Bengio. Word representations: a simple and general method for semisupervised learning. In Proceedings of ACL, pages 384–394, 2010.
单词表示:一种简单而通用的半监督学习方法
[9] J. B. Pollack. Recursive distributed representations. Artificial Intelligence, 46, November 1990.
递归的分布式表征
[10] T. Voegtlin and P. Dominey. Linear Recursive Distributed Representations. Neural Networks, 18(7), 2005.
线性递归分布表示
[11] J. L. Elman. Distributed representations, simple recurrent networks, and grammatical structure. Machine Learning, 7(2-3), 1991.
分布式表示、简单递归网络和语法结构。
[12] R. Socher, J. Pennington, E. H. Huang, A. Y. Ng, and C. D. Manning. Semi-Supervised Recursive Autoencoders for Predicting Sentiment Distributions. In EMNLP, 2011.
用于预测情绪分布的半监督递归自动编码器
[13] C. Goller and A. Kuchler. Learning task-dependent distributed representations by backpropagation through structure. In Proceedings of the International Conference on Neural Networks (ICNN-96), 1996.
通过结构反向传播学习任务相关的分布式表示
[14] D. Klein and C. D. Manning. Accurate unlexicalized parsing. In ACL, 2003.
准确unlexicalized解析 ( lexical adj. 词汇的)
[15] D. Das and N. A. Smith. Paraphrase identification as probabilistic quasi-synchronous recognition. In In Proc. of ACL-IJCNLP, 2009.
将酶识别解释为概率准同步识别。
[16] V. Rus, P. M. McCarthy, M. C. Lintean, D. S. McNamara, and A. C. Graesser. Paraphrase identifification with lexico-syntactic graph subsumption. In FLAIRS Conference, 2008.
用词法-句法图包容解释识别
[17] R. Mihalcea, C. Corley, and C. Strapparava. Corpus-based and Knowledge-based Measures of Text Semantic Similarity. In Proceedings of the 21st National Conference on Artifificial Intelligence - Volume 1, 2006.
基于语料库和基于知识的文本语义相似性度量
[18] A. Islam and D. Inkpen. Semantic Similarity of Short Texts. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2007), 2007.
短文本的语义相似性
[19] L. Qiu, M. Kan, and T. Chua. Paraphrase recognition via dissimilarity signifificance classifification. In EMNLP, 2006.
通过不同的意义分类意译识别
[20] S. Fernando and M. Stevenson. A semantic similarity approach to paraphrase detection. Proceedings of the 11th Annual Research Colloquium of the UK Special Interest Group for Computational Linguistics, 2008.
一种语义相似的意译检测方法
[21] S. Wan, M. Dras, R. Dale, and C. Paris. Using dependency-based features to take the “para-farce” out of paraphrase. In Proceedings of the Australasian Language Technology Workshop 2006, 2006.
使用基于依赖的特性将“对偶闹剧”从释义中去掉
[22] R. Barzilay and L. Lee. Learning to paraphrase: an unsupervised approach using multiple-sequence alignment. In NAACL, 2003.
学习释义:使用多序列对齐的无监督方法
[23] Y. Zhang and J. Patrick. Paraphrase identifification by text canonicalization. In Proceedings of the Australasian Language Technology Workshop 2005, 2005.
解释文本规范化的标识
[24] Z. Kozareva and A. Montoyo. Paraphrase Identifification on the Basis of Supervised Machine Learning Techniques. In Advances in Natural Language Processing, 5th International Conference on NLP, FinTAL, 2006.
解释识别的基础上监督机器学习技术
[25] L. Bottou. From machine learning to machine reasoning. CoRR, abs/1102.1808, 2011.
从机器学习到机器推理
[26] H. Larochelle, Y. Bengio, J. Louradour, and P. Lamblin. Exploring strategies for training deep neural networks. JMLR, 10, 2009.
探索深度神经网络的训练策略
[27] R. Socher, C. D. Manning, and A. Y. Ng. Learning continuous phrase representations and syntactic parsing with recursive neural networks. In Proceedings of the NIPS-2010 Deep Learning and Unsupervised Feature Learning Workshop, 2010.
使用递归神经网络学习连续短语表示和句法分析
[28] R. Socher, C. Lin, A. Y. Ng, and C.D. Manning. Parsing Natural Scenes and Natural Language with Recursive Neural Networks. In ICML, 2011.
用递归神经网络解析自然场景和自然语言
论文翻译——Dynamic Pooling and Unfolding Recursive Autoencoders for Paraphrase Detection的更多相关文章
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- R-CNN论文翻译
R-CNN论文翻译 Rich feature hierarchies for accurate object detection and semantic segmentation 用于精确物体定位和 ...
- SSD: Single Shot MultiBoxDetector英文论文翻译
SSD英文论文翻译 SSD: Single Shot MultiBoxDetector 2017.12.08 摘要:我们提出了一种使用单个深层神经网络检测图像中对象的方法.我们的方法,名为SSD ...
- R-FCN论文翻译
R-FCN论文翻译 R-FCN: Object Detection viaRegion-based Fully Convolutional Networks 2018.2.6 论文地址:R-FCN ...
- 深度学习论文翻译解析(四):Faster R-CNN: Down the rabbit hole of modern object detection
论文标题:Faster R-CNN: Down the rabbit hole of modern object detection 论文作者:Zhi Tian , Weilin Huang, Ton ...
- 《论文翻译》Xception
目录 深度可分离网络-Xception 注释 1. 摘要 2. 介绍 3. Inception假设 4. 卷积和分离卷积之间的联系 4. 先验工作 5. Xception 架构 6. 个人理解 单词汇 ...
- 论文翻译——R-CNN(目标检测开山之作)
R-CNN论文翻译 <Rich feature hierarchies for accurate object detection and semantic segmentation> 用 ...
- 论文翻译—SPP-Net(目标检测)
SPPNet论文翻译 <Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition> Kai ...
- 【论文翻译】NIN层论文中英对照翻译--(Network In Network)
[论文翻译]NIN层论文中英对照翻译--(Network In Network) [开始时间]2018.09.27 [完成时间]2018.10.03 [论文翻译]NIN层论文中英对照翻译--(Netw ...
随机推荐
- ZOJ - 2671 Cryptography(线段树+求区间矩阵乘积)
题意:已知n个矩阵(下标从1开始),求下标x~y区间矩阵的乘积.最多m次询问,n ( 1 <= n <= 30,000) and m ( 1 <= m <= 30,000). ...
- MacOS Safari无响应卡死解决方法
之前也是用的好好的,突然一次进入一个网页就卡死了,强制退出,后面再重新进入Safari都会处于卡死状态,一直找不到解决方法,Safari也不能卸载重装,想着得等到更新系统或者重装系统,今天看到贴吧一个 ...
- windows driver 驱动程序我的下载地址
http://download.csdn.net/detail/sz76211822/8197619 版权声明:本文为博主原创文章,未经博主允许不得转载.
- 自己整理的常用SQL Server 2005 语句、
--创建数据库 create database 数据库 go --打开数据库 use 数据库 --删除数据库 drop database 数据库 Go --创建数据表 create table 数据表 ...
- linux服务重启命令
/etc/init.d/sshd restart/etc/init.d/sshd reload systemctl status sshd.servicesystemctl restart sshd. ...
- Java length、length()、size()区别
1.length: 是一个 属性 针对的是 数组 得到的结果是 数组的长度 eg: String [] array = {"abc","def","g ...
- 18 12 4 SQL 的基本 语法
数据库的基本语法 -- 数据库的操作 -- 链接数据库 mysql -uroot -p mysql -uroot -pmysql -- 退出数据库 exit/quit/ctrl+d -- sql语句最 ...
- 工程日记之ChildLost(2) :如何编写一个多线程的程序
Dispatch Dispatch结合语言特性,运行时,和系统的特点,提供了系统的,全面的高层次API来提升多核多线程编程的能力. Dispatch会自动的根据CPU的使用情况,创建线程来执行任务,并 ...
- 《C Primer Plus》- 第一章 初试C语言
本笔记写于2020年1月25日. 从今天开始,我要全面的.彻底的将未来计划中所有的知识重新规划学习一遍,并整理成一套全面的笔记体系.为我将来的职业打下坚实的基础.而所有的一切从C语言开始. 本系列文章 ...
- delphi的procedure of object
delphi的procedure of object(一个特殊的指针类型) 理论: //适用于实现不是某一特定过程或函数 type TNotifyEvent = procedure(Sender: T ...