吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据
import requests
from bs4 import BeautifulSoup url = "http://www.cntour.cn/"
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text,"lxml")
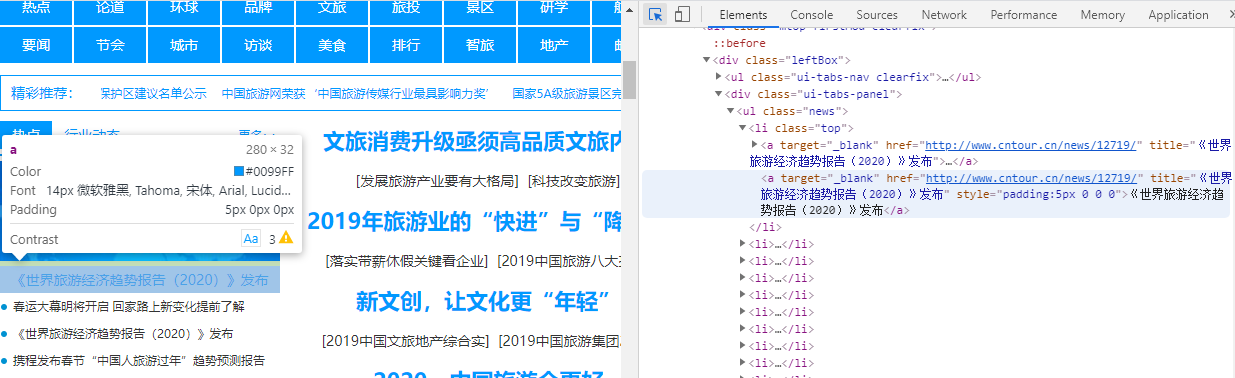
#下面的参数由网站开发者模式中Copy->copy selector复制而来
data = soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li:nth-child(1) > a")
print(data)

import requests
from bs4 import BeautifulSoup url = "http://www.cntour.cn/"
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text,"lxml")
#下面的参数由网站开发者模式中Copy->copy selector复制而来,获取该网站所有超链接内容,删掉::nth-child(1),如下:
data = soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a")
print(data)

#清洗和组织爬取到的数据
import requests
from bs4 import BeautifulSoup url = "http://www.cntour.cn/"
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text,"lxml")
#下面的参数由网站开发者模式中Copy->copy selector复制而来,获取该网站所有超链接内容,删掉::nth-child(1),如下:
data = soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a")
for item in data:
result={
"title":item.get_text(),
"link":item.get("href")
}
print(result)

#清洗和组织爬取到的数据,获取每个链接后面的ID
import re
import requests
from bs4 import BeautifulSoup url = "http://www.cntour.cn/"
strhtml = requests.get(url)
soup = BeautifulSoup(strhtml.text,"lxml")
#下面的参数由网站开发者模式中Copy->copy selector复制而来,获取该网站所有超链接内容,删掉::nth-child(1),如下:
data = soup.select("#main > div > div.mtop.firstMod.clearfix > div.centerBox > ul.newsList > li > a")
for item in data:
result={
"title":item.get_text(),
"link":item.get("href"),
"ID":re.findall("\d+",item.get("href"))
}
print(result)

吴裕雄--天生自然PYTHON爬虫:使用BeautifulSoup解析中国旅游网页数据的更多相关文章
- 吴裕雄--天生自然PYTHON爬虫:使用Scrapy抓取股票行情
Scrapy框架它能够帮助提升爬虫的效率,从而更好地实现爬虫.Scrapy是一个为了抓取网页数据.提取结构性数据而编写的应用框架,该框架是封装的,包含request异步调度和处理.下载器(多线程的Do ...
- 吴裕雄--天生自然PYTHON爬虫:使用Selenium爬取大型电商网站数据
用python爬取动态网页时,普通的requests,urllib2无法实现.例如有些网站点击下一页时,会加载新的内容,但是网页的URL却没有改变(没有传入页码相关的参数),requests.urll ...
- 吴裕雄--天生自然PYTHON爬虫:爬取某一大型电商网站的商品数据(效率优化以及代码容错处理)
这篇博文主要是对我的这篇https://www.cnblogs.com/tszr/p/12198054.html爬虫效率的优化,目的是为了提高爬虫效率. 可以根据出发地同时调用多个CPU,每个CPU运 ...
- 吴裕雄--天生自然PYTHON爬虫:爬虫攻防战
我们在开发者模式下不仅可以找到URL.Form Data,还可以在Request headers 中构造浏览器的请求头,封装自己.服务器识别浏览器访问的方法就是判断keywor是否为Request h ...
- 吴裕雄--天生自然PYTHON爬虫:安装配置MongoDBy和爬取天气数据并清洗保存到MongoDB中
1.下载MongoDB 官网下载:https://www.mongodb.com/download-center#community 上面这张图选择第二个按钮 上面这张图直接Next 把bin路径添加 ...
- 吴裕雄--天生自然PYTHON爬虫:用API爬出天气预报信息
天气预报网址:https://id.heweather.com/,这个网站是需要注册获取一个个人认证后台密钥key的,并且每个人都有访问次数的限制,这个key就是访问API的钥匙. 这个key现在是要 ...
- 吴裕雄--天生自然python爬虫:使用requests模块的get和post方式抓取中国旅游网站和有道翻译网站翻译内容数据
import requests url = 'http://www.cntour.cn/' strhtml = requests.get(url) print(strhtml.text) URL='h ...
- 吴裕雄--天生自然python学习笔记:pandas模块删除 DataFrame 数据
Pandas 通过 drop 函数删除 DataFrarne 数据,语法为: 例如,删除陈聪明(行标题)的成绩: import pandas as pd datas = [[65,92,78,83,7 ...
- 吴裕雄--天生自然python学习笔记:抓取网络公开数据
当前,有许多政府或企事业单位会在网上为公众提供相关的公开数据.以 http://api.help.bj.cn/api/均 .cn/api /网站为例,打开这个链接,大家可以看到多种可供调用的数据 . ...
随机推荐
- Go_排序
package main import ( "fmt" "sort" "math/rand" ) //1.声明Hero结构体 type He ...
- 【jQuery基础】
" 目录 #. 介绍 1. 优势 2. 版本 3. jQuery对象 #. 查找标签 1. 选择器 /. 基本选择器 /. 层级选择器 /. 基本筛选器 /. 使用jQuery实现弹框 / ...
- 「CF1142B」Lynyrd Skynyrd
传送门 Luogu 解题思路 发现一个性质: 对于排列的任何一个循环位移,排列中的同一个数的前驱肯定是不变的. 而且,如果一个排列的循环位移是某一个区间的子序列,那么这个循环位移的结尾的 \(n-1\ ...
- Python3.5学习之旅——day6
面向对象编程的学习 一.定义 首先跟大家介绍一位资深的程序员前辈说过的编程心得: 1.写重复代码是非常不好且低级的行为 2.完成的代码需要经常变更 所以根据以上两个心得,我们可以知道写的代码一定要遵循 ...
- springmvc基于java配置的实现
该案例的github地址:https://github.com/zhouyanger/demo/tree/master/springmvc-noxml-demo 1.介绍 之前搭建SpringMvc项 ...
- Python:字典类型
概念 无序的,可变的,键值对集合 定义 方式1 {key1: value1, key2: value2, ......} 方式2 fromkeys(S, v=None) 静态方法:类和对象都可以调用 ...
- DHCP报文交互流程
1.发现阶段,即DHCP客户机寻找DHCP服务器的阶段(DHCPdiscover) DHCP客户机以广播方式(因为DHCP服务器的IP地址对于客户机来说是未知的)发送DHCPdiscover发现信息来 ...
- 什么是SOA架构
什么是SOA架构 SOA是Service-Oriented Architecture的首字母简称,它是一种支持面向服务的架构样式.从服务.基于服务开发和服务的结果来看,面向服务是一种思考方式.其实SO ...
- [读书]The Man Who Solved the Market
出乎个人意料的是,西蒙斯是从FICC类品种起步的,包括量化投资方法获得第一次重大突破也是在FICC品种上. FICC市场的深度不够,所以文艺复兴科技实现规模扩张是股票策略成功之后的事情,很靠后. 虽然 ...
- 「USACO5.5」矩形周长Picture
题目描述 墙上贴着许多形状相同的海报.照片.它们的边都是水平和垂直的.每个矩形图片可能部分或全部的覆盖了其他图片.所有矩形合并后的边长称为周长. 编写一个程序计算周长. 如图1所示7个矩形. 如图2所 ...