【原创】MapReduce程序如何在集群上执行
首先了解下资源调度管理框架Yarn。
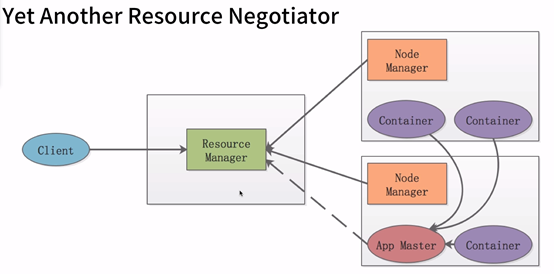
Yarn的结构(如图):
Resource Manager (rm)负责调度管理整个集群上的资源,而每一个计算节点上都会有一个Node Manager(nm)来负责该节点上的计算资源,我们把计算资源抽象成一个个Container(容器),每个Container包含一定数量的cpu核数和一定大小的内存。一个应用程序由一个App Master 来管理,App Master 负责将一个程序运行在各个节点的Container中。
Yarn 组件分工:
1. Resource Manager
主要职责是调度,对应用程序的整体进行资源分配。
2. Container
单个节点的物理资源的集合,比如内存,cpu。
3. Node Manage
管理Container生命周期,资源使用情况,节点健康状况,并且将这些信息汇报给Recource Manager。
4. Application Master
协调集群中的应用程序,与Resource Manager协商资源,并且将这个应用程序运行在集群之中。
MapReduce程序如何在集群上执行?
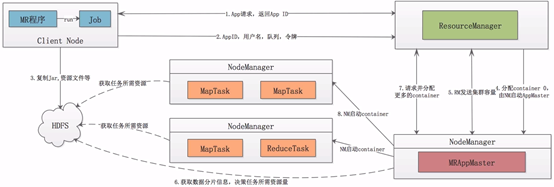
执行过程:
- mr会在客户端启动,客户端会向rm 发送一个 app 请求,rm会返回一个appid给客户端,
- 客户端会拿着appid,用户名,队列,令牌向rm进行请求,
- 客户端会将应用程序所用的jar包,资源文件,以及程序运行时所需要的数据传送到hdfs,
- rm会分配一个container0的资源包,由nm启动一个 appmaster
- rm将集群容量信息发送给appmaster,
- appmaster计算这个程序需要的资源量
- 向rm 请求分配更多的container
- nm在各个节点上启动map任务和reduce任务。
总结:
- 客户端提交mr程序,向rm请求资源,并将程序依赖的资源上传到hdfs,
- Rm分配一个container0,nm启动am,用来管理这个mr程序,am计算好所需要的资源后向rm请求更多的资源。
- nm在各个节点上启动map task和reduce task
【原创】MapReduce程序如何在集群上执行的更多相关文章
- [MapReduce_add_1] Windows 下开发 MapReduce 程序部署到集群
0. 说明 Windows 下开发 MapReduce 程序部署到集群 1. 前提 在本地开发的时候保证 resource 中包含以下配置文件,从集群的配置文件中拷贝 在 resource 中新建 ...
- 在local模式下的spark程序打包到集群上运行
一.前期准备 前期的环境准备,在Linux系统下要有Hadoop系统,spark伪分布式或者分布式,具体的教程可以查阅我的这两篇博客: Hadoop2.0伪分布式平台环境搭建 Spark2.4.0伪分 ...
- 攻城狮在路上(陆)-- 提交运行MapReduce程序到hadoop集群运行
此种方式不能直接在eclipse中调试代码. 首先需要在src下放置服务器上的hadoop配置文件:core-site.xml\yarn-site.xml\hdfs-site.xml\mapred-s ...
- CDH集群spark-shell执行过程分析
目的 刚入门spark,安装的是CDH的版本,版本号spark-core_2.11-2.4.0-cdh6.2.1,部署了cdh客户端(非集群节点),本文主要以spark-shell为例子,对在cdh客 ...
- MapReduce编程入门实例之WordCount:分别在Eclipse和Hadoop集群上运行
上一篇博文如何在Eclipse下搭建Hadoop开发环境,今天给大家介绍一下如何分别分别在Eclipse和Hadoop集群上运行我们的MapReduce程序! 1. 在Eclipse环境下运行MapR ...
- 用python + hadoop streaming 编写分布式程序(二) -- 在集群上运行与监控
写在前面 相关随笔: Hadoop-1.0.4集群搭建笔记 用python + hadoop streaming 编写分布式程序(一) -- 原理介绍,样例程序与本地调试 用python + hado ...
- hadoop 把mapreduce任务从本地提交到hadoop集群上运行
MapReduce任务有三种运行方式: 1.windows(linux)本地调试运行,需要本地hadoop环境支持 2.本地编译成jar包,手动发送到hadoop集群上用hadoop jar或者yar ...
- 在集群上运行caffe程序时如何避免Out of Memory
不少同学抱怨,在集群的GPU节点上运行caffe程序时,经常出现"Out of Memory"的情况.实际上,如果我们在提交caffe程序到某个GPU节点的同时,指定该节点某个比较 ...
- [Spark Core] 在 Spark 集群上运行程序
0. 说明 将 IDEA 下的项目导出为 Jar 包,部署到 Spark 集群上运行. 1. 打包程序 1.0 前提 搭建好 Spark 集群,完成代码的编写. 1.1 修改代码 [添加内容,判断参数 ...
随机推荐
- 面对对象二,super......反射
一.super() super() : 主动调用其他类的成员 # 单继承 # 在单继承中 super,主要是用来调用父类的方法的. class A: def __init__(self): self ...
- shell__常用命令__grep
grep | zgrep (不用解压zip就能直接搜索) -i 不区分大小写 -I 忽略二进制文件 -R或r 递归文件目录 -c 计算找到的总数量 -n 显示行号 -v 显示不包含匹配文本的所有行 - ...
- Struts2框架里面action与前端jsp页面进行交互路径问题---》一个对话框里面有很多超链接,进行相应的跳转
一个对话框里面有很多超链接,右边是点击超链接跳转到的相应页面(在一个页面上就相当于点击该超链接时候,就把该简短页面置顶):这个问题困扰我两天:还请大神给我解决,也没有解决,我仔细对比了相关路径,后面添 ...
- (一)使用appium之前为什么要安装nodejs???
很多人在刚接触appium自动化时,可能会像我一样,按照教程搭建好环境后,却不知道使用appium之前为什么要用到node.js,nodejs到底和appium是什么关系,对nodejs也不是很了解, ...
- 第九届蓝桥杯大赛个人赛决赛(软件类)真题Java
更新中.......... 同一年的题解:https://www.cnblogs.com/dgwblog/p/10111903.html 01 结果填空 (满分11分) 标题:年龄问题 s夫人一向 ...
- Springboot第一篇:框架了解与搭建
在上一章,我讲解了React+node+express相应的框架搭建,一个项目只有一个前端框架够么,当然不够啦!!! 所以这节我们就来讲后台springboot框架的搭建和相关原理吧~~~版本(2.1 ...
- CDQZ Day3
模拟题 day3出题人: liu_runda题目名称 摆渡 摆车 背包源程序文件名 boat.cpp ju.cpp pack.cpp输入文件名 boat.in ju.in pack.in输出文件名 b ...
- 使用app-inspector查看元素,无法连接到手机,提示错误{ Error: Command failed ……forward tcp:9001 tcp:9001错误解决
在学习使用app-inspector查看元素时,碰到一个问题.在cmd窗口执行命令app-inspector --port 5678 -u 85EABNFSU53R --verbose ,连接不到手 ...
- DP Intro - poj 1947 Rebuilding Roads(树形DP)
版权声明:本文为博主原创文章,未经博主允许不得转载. Rebuilding Roads Time Limit: 1000MS Memory Limit: 30000K Total Submissi ...
- MySQL查询操作select
查找记录 SELECT select_expr [,select_expr ...] [ FROM table_references(表的参照) [WHERE where_condition](条件) ...