Docker:docker部署PXC-5.7.21(mysql5.7.21)集群搭建负载均衡实现双机热部署方案
单节点数据库弊端
- 大型互联网程序用户群体庞大,所以架构必须要特殊设计
- 单节点的数据库无法满足性能上的要求
- 单节点的数据库没有冗余设计,无法满足高可用
推荐Mysql集群部署方案
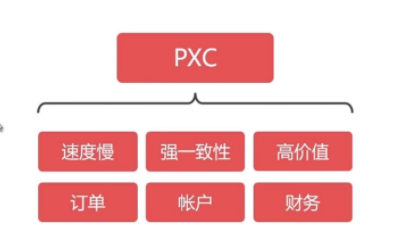
PXC (Percona XtraDB Cluster)
- 速度慢,但能保证强一致性,适用于保存价值较高的数据,比如订单、客户、支付等。
- 数据同步是双向的,在任一节点写入数据,都会同步到其他所有节点,在任何节点上都能同时读写。
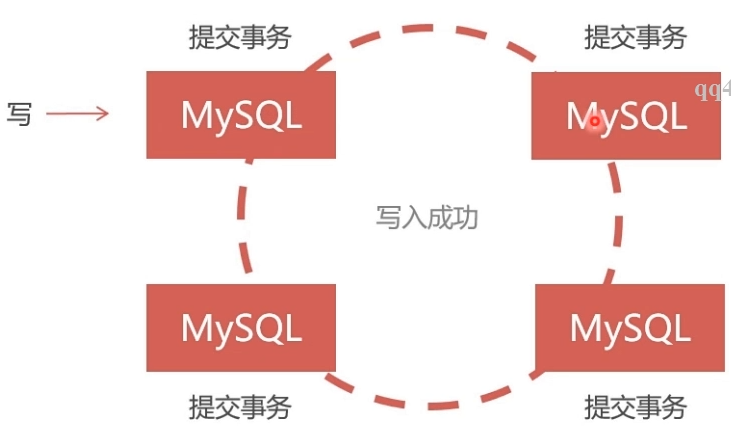
- 采用同步复制,向任一节点写入数据,只有所有节点都同步成功后,才会向客户端返回成功。事务在所有节点要么同时提交,要么不提交。
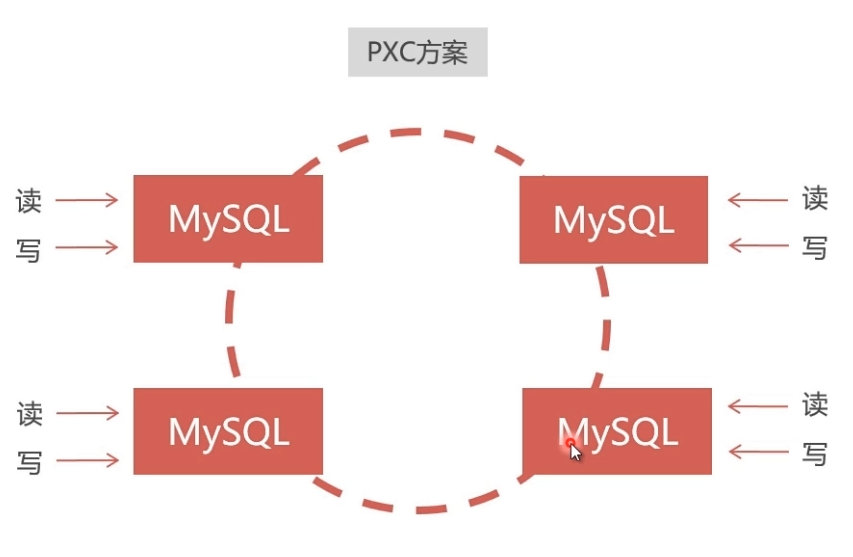
建议PXC使用PerconaServer (MySQL改进版,性能提升很大)
PXC的数据强一致性
- 同步复制,事务在所有集群节点要么同时提交,要么不提交
- Replication采用异步复制,无法保证数据的一致性

PXC集群部署
在Docker中安装PXC集群,使用Docker仓库中的PXC官方镜像
docker官方仓库中拉下PXC镜像
docker pull percona/percona-xtradb-cluster:5.7.21
重命名镜像:(名称太长,可以重命名一下)
docker tag percona/percona-xtradb-cluster:5.7.21 pxc
出于安全考虑,给PXC集群创建Docker Swarm虚拟网络
( docker network create -d overlay --attachable swarm_mysql(自定义名称) )
#初始化swarm虚拟网络
docker swarm init #查看Swarm节点下的主机,只能在主机下查看
docker node ls #删除节点的某一台主机
docker node rm -f vhmhgzyfyl710x0ojkbg9yywm(节点ID) #解散Swarm集群
docker swarm leave -f
docker swarm leave #查看docker网络
docker network ls #创建swarm虚拟网络
docker network create -d overlay --attachable swarm_mysql(自定义名称) #删除swarm虚拟网络
docker network rm swarm_mysql
创建Docker数据卷
使用Docker时,业务数据应保存在宿主机中,采用目录映射,这样可以使数据与容器独立。但是容器中的PXC无法直接使用映射目录,解决办法是采用Docker卷来映射!
# 创建名称为v1的数据卷,--name可以省略
docker volume create --name v1
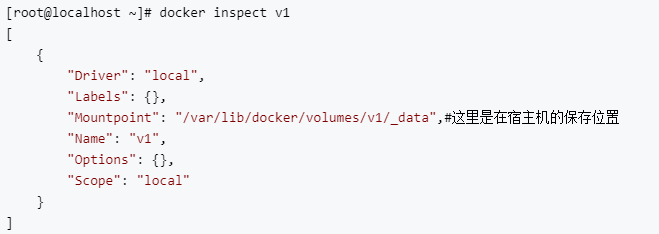
查看数据卷
#查看数据卷元信息
docker inspect v1
删除数据卷
#删除数据卷命令
docker volume rm v1
创建部署PXC集群所需的数据卷
# 创建5个数据卷
docker volume create --name v1
docker volume create --name v2
docker volume create --name v3
docker volume create --name v4
docker volume create --name v5
创建5个PXC容器
# 创建5个PXC容器构成集群
# 第一个节点
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -v v1:/var/lib/mysql --name=node1 --network=swarm_mysql pxc
# 在第一个节点启动后要等待一段时间,等候mysql启动完成。 # 第二个节点
docker run -d -p 3307:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v2:/var/lib/mysql --name=node2 --net=swarm_mysql pxc
# 第三个节点
docker run -d -p 3308:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v3:/var/lib/mysql --name=node3 --net=swarm_mysql pxc
# 第四个节点
docker run -d -p 3309:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v4:/var/lib/mysql --name=node4 --net=swarm_mysql pxc
# 第五个节点
docker run -d -p 3310:3306 -e MYSQL_ROOT_PASSWORD=abc123456 -e CLUSTER_NAME=PXC -e XTRABACKUP_PASSWORD=abc123456 -e CLUSTER_JOIN=node1 -v v5:/var/lib/mysql --name=node5 --net=swarm_mysql pxc

数据库负载均衡的必要性
数据库单节点处理所有请求,负载高,性能差
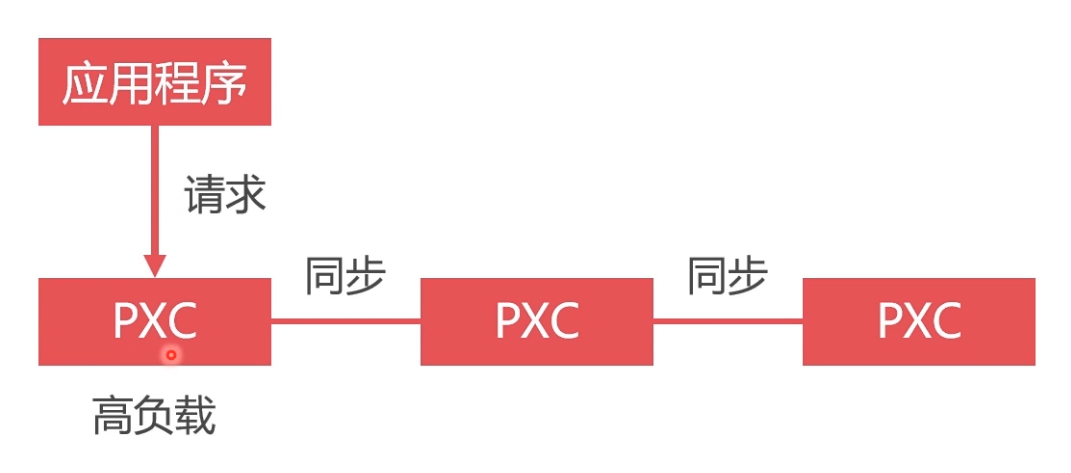
将请求均匀地发送给集群中的每一个节点。
- 所有请求发送给单一节点,其负载过高,性能很低,而其他节点却很空闲。
- 使用Haproxy做负载均衡,可以将请求均匀地发送给每个节点,单节点负载低,性能好
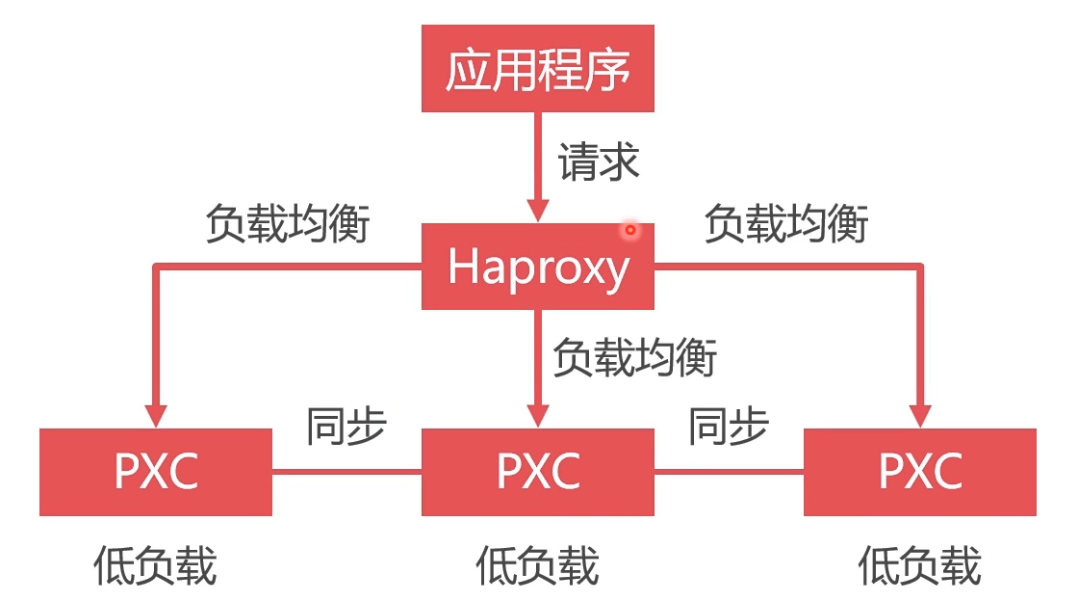
安装负载均衡中间件Haproxy
从Docker仓库拉取haproxy镜像
#下载haproxy镜像
docker pull haproxy
创建Haproxy配置文件。供Haproxy容器使用( haproxy.cfg )
global
#工作目录
chroot /usr/local/etc/haproxy
#日志文件,使用rsyslog服务中local5日志设备(/var/log/local5),等级info
log 127.0.0.1 local5 info
#守护进程运行
daemon defaults
log global
mode http
#日志格式
option httplog
#日志中不记录负载均衡的心跳检测记录
option dontlognull
#连接超时(毫秒)
timeout connect 5000
#客户端超时(毫秒)
timeout client 50000
#服务器超时(毫秒)
timeout server 50000 #监控界面
listen admin_stats
#监控界面的访问的IP和端口
bind 0.0.0.0:8888
#访问协议
mode http
#URI相对地址
stats uri /dbs
#统计报告格式
stats realm Global\ statistics
#登陆帐户信息
stats auth admin:abc123456
#数据库负载均衡
listen proxy-mysql
#访问的IP和端口
bind 0.0.0.0:3306
#网络协议
mode tcp
#负载均衡算法(轮询算法)
#轮询算法:roundrobin
#权重算法:static-rr
#最少连接算法:leastconn
#请求源IP算法:source
balance roundrobin
#日志格式
option tcplog
#在MySQL中创建一个没有权限的haproxy用户,密码为空。Haproxy使用这个账户对MySQL数据库心跳检测
option mysql-check user haproxy
server MySQL_1 172.18.0.2:3306 check weight 1 maxconn 2000
server MySQL_2 172.18.0.3:3306 check weight 1 maxconn 2000
server MySQL_3 172.18.0.4:3306 check weight 1 maxconn 2000
server MySQL_4 172.18.0.5:3306 check weight 1 maxconn 2000
server MySQL_5 172.18.0.6:3306 check weight 1 maxconn 2000
#使用keepalive检测死链
option tcpka
文件映射到容器内部
#映射文件
docker cp 宿主机的haproxy.cfg的路径 haproxy:/usr/local/etc/haproxy/
在数据库集群中创建空密码、无权限用户haproxy,来供Haproxy对MySQL数据库进行心跳检测
#示例
#进入node1容器
docker exec -it node1 bash
#登录mysql
mysql -u root -p
#指定数据库
use mysql;
#创建用户
create user 'haproxy'@'%' identified by '';
创建Haproxy容器
# 这里要加 --privileged
docker run -it -d -p 4001:8888 -p 4002:3306 -v /home/haproxy:/usr/local/etc/haproxy --name haproxy --net=swarm_mysql --privileged haproxy
(容器启动后,haproxy自动启动,如果没启动使用下面命令启动)进入容器并启动haproxy
#进入容器
docker exec -it h1 bash
#启动haproxy
haproxy -f /usr/local/etc/haproxy/haproxy.cfg
浏览器中打开Haproxy监控界面
根据配置文件和启动容器设置的端口,我的访问路径为:http://192.168.63.144:4001/dbs ,用户名admin,密码abc123456
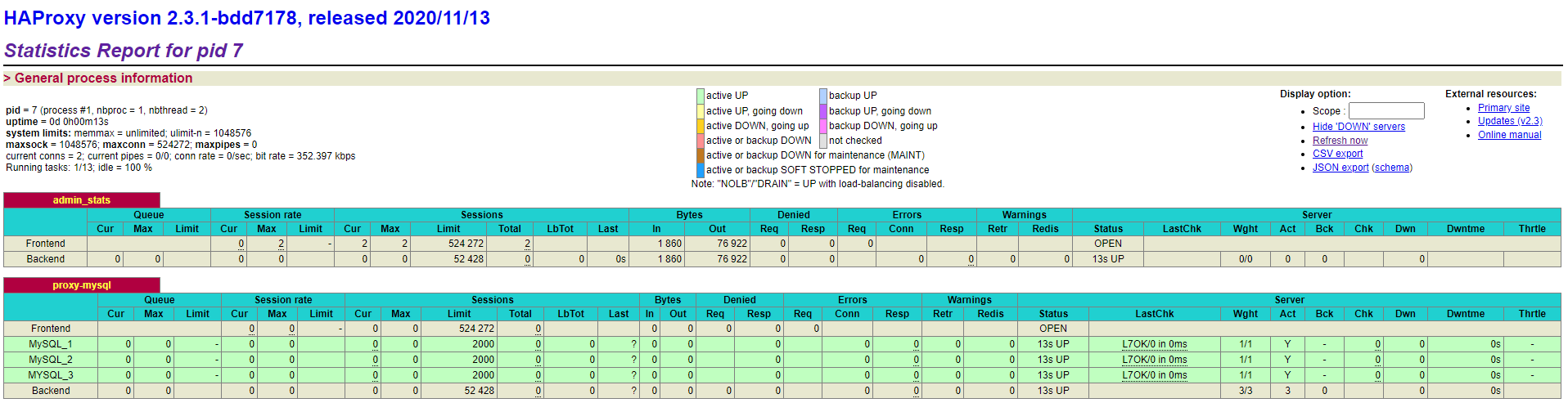
尝试宕掉一台数据库
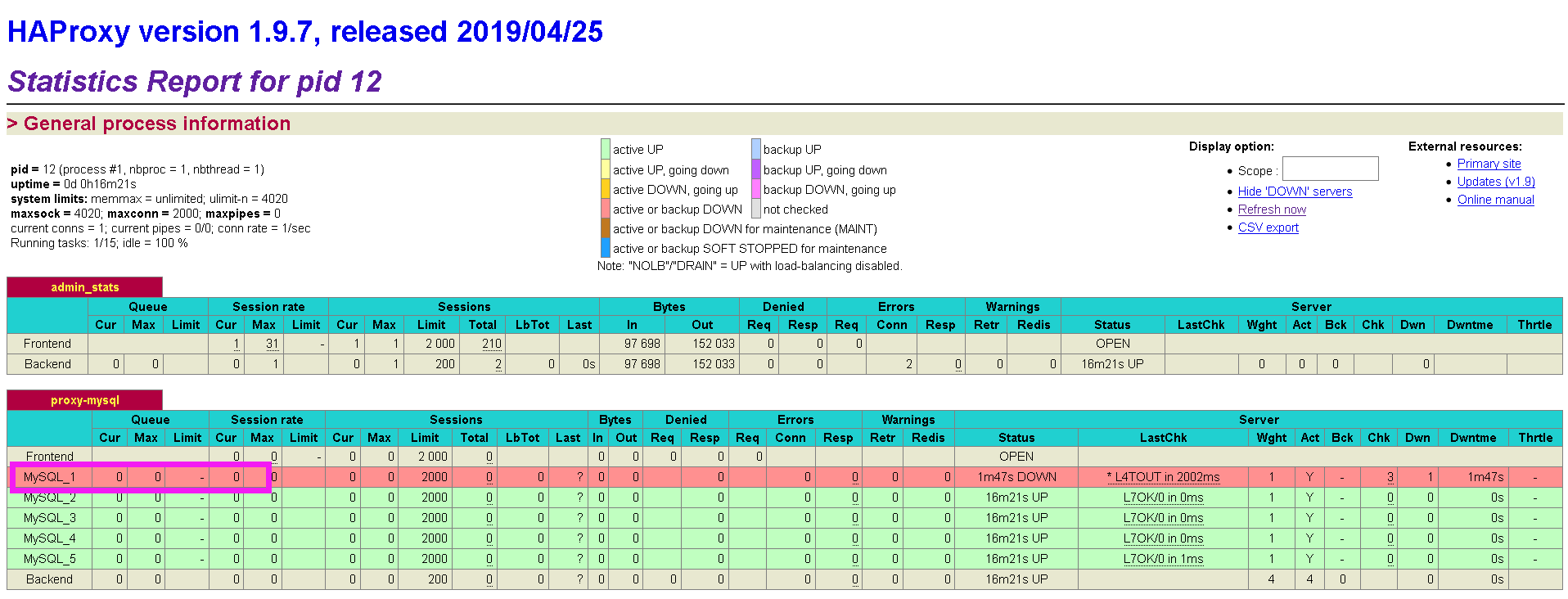
Haproxy不存储数据,只转发数据。可以在数据库中建立Haproxy的连接,端口4002,用户名和密码为数据库集群的用户名和密码
双机热备场景
单节点Haproxy不具备高可用,必须要有冗余设计

双机就是两个请求处理程序,比如两个haproxy,当一个挂掉的时候,另外 一个可以顶上。热备我理解就是keepalive。在haproxy 容器中安装keepalive。
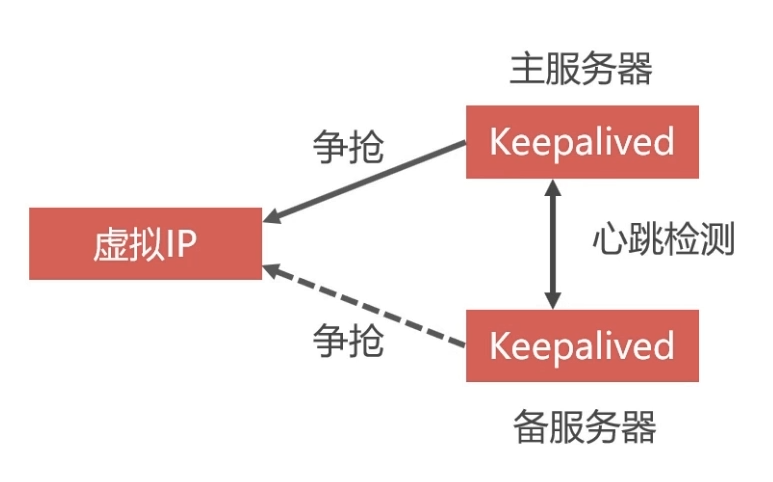
虚拟IP
定义一个虚拟ip,然后比如两个haproxy分别安装keepalive镜像,因为haproxy是ubuntu系统的,所以安装用apt-get,keepalive是作用是抢占虚拟ip,抢到的就是主服务器,没有抢到的就是备用服务器,然后两个keepalive进行心跳检测(就是创建一个用户到对方那里试探,看是否还活着,mysql的集群之间也是心跳检测),如果 挂掉抢占ip。
Haproxy的双机热备方案最关键的技术就是虚拟IP。宿主机安装keepalive,容器安装keepalive,通过虚拟IP转发进行通信,实现双机热备。

Keepalive实现双机热备方案
- 定义虚拟IP
- 在Docker中启动两个Haproxy容器,每个容器中还需要安装Keepalived程序(以下简称KA)
- 两个KA会争抢虚拟IP,一个抢到后,另一个没抢到就会等待,抢到的作为主服务器,没抢到的作为备用服务器
- 两个KA之间会进行心跳检测,如果备用服务器没有受到主服务器的心跳响应,说明主服务器发生故障,那么备用服务器就可以争抢虚拟IP,继续工作
- 我们向虚拟IP发送数据库请求,一个Haproxy挂掉,可以有另一个接替工作
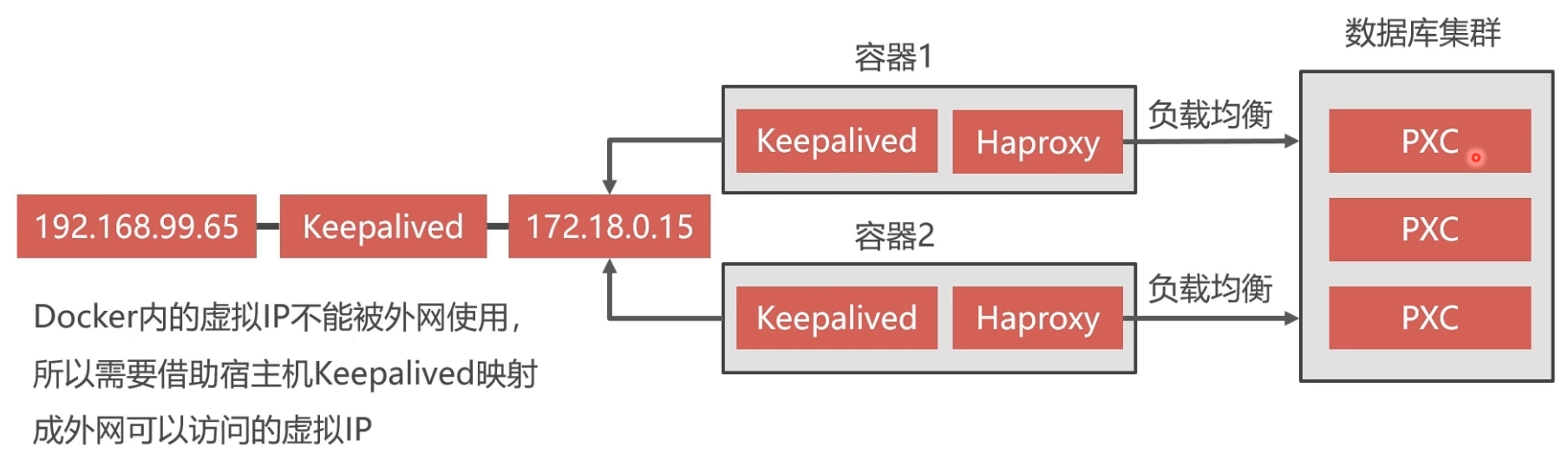
docker内的虚拟IP不能被外网,所以需要借助宿主机Keepalived映射成外网可以访问地虚拟IP
Haproxy容器安装Keepalived
安装keeplived
#进入容器
docker exec -it haproxy bash
#更新apt-get工具
apt-get update
#下载keepalived
apt-get install keepalived
编写Keepalived配置文件
Keepalived的配置文件复制到 /etc/keepalived/keepalived.conf 路径
vrrp_instance VI_1 {
state MASTER # Keepalived的身份(MASTER主服务要抢占IP,BACKUP备服务器不会抢占IP)。
interface eth0 # docker网卡设备,虚拟IP所在
virtual_router_id 51 # 虚拟路由标识,MASTER和BACKUP的虚拟路由标识必须一致。从0~255
priority 100 # MASTER权重要高于BACKUP数字越大优先级越高
advert_int 1 # MASTER和BACKUP节点同步检查的时间间隔,单位为秒,主备之间必须一致
authentication { # 主从服务器验证方式。主备必须使用相同的密码才能正常通信
auth_type PASS
auth_pass 123456
}
virtual_ipaddress { # 虚拟IP。可以设置多个虚拟IP地址,每行一个
172.18.0.201
}
}
启动Keepalived
#启动keepalived
service keepalived start
#查看网卡虚拟IP是否生效
ip a
可以按照以上步骤,再另外创建一个Haproxy容器,注意映射的宿主机端口不能重复,Haproxy配置一样。
宿主机安装Keepalived
首先查看当前局域网IP分配情况
#下载nmap工具
yum install nmap -y
#查看当前网段所有占用的IP
nmap -sP 192.168.1.0/24
在宿主机中安装Keepalived
yum install keepalived
编写宿主机Keepalived配置
复制到 /etc/keepalived/keepalived.conf 路径
vrrp_instance VI_1 {
state MASTER
#这里是宿主机的网卡,可以通过ip a查看当前自己电脑上用的网卡名是哪个
interface ens33
virtual_router_id 100
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
#这里是指定的一个宿主机上的虚拟ip,一定要和宿主机网卡在同一个网段,
#我的宿主机网卡ip是192.168.63.144,所以指定虚拟ip是160
192.168.63.160
}
}
#接受监听数据来源的端口,网页入口使用
virtual_server 192.168.63.160 8888 {
delay_loop 3
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
#把接受到的数据转发给docker服务的网段及端口,由于是发给docker服务,所以和docker服务数据要一致
real_server 172.18.0.201 8888 {
weight 1
}
}
#接受数据库数据端口,宿主机数据库端口是3306,所以这里也要和宿主机数据接受端口一致
virtual_server 192.168.63.160 3306 {
delay_loop 3
lb_algo rr
lb_kind NAT
persistence_timeout 50
protocol TCP
#同理转发数据库给服务的端口和ip要求和docker服务中的数据一致
real_server 172.18.0.201 3306 {
weight 1
}
}
启动Keepalived服务
#启动keepalived
service keepalived start
#查看keepalived状态
service keepalived status
#关闭keepallived
service keepalived stop
其他电脑便可以通过虚拟IP 192.168.63.160 的8888和3306端口来访问宿主机Docker中的 172.18.0.201 的相应端口。
文章转载至:https://www.cnblogs.com/wanglei957/p/11819547.html#autoid-0-0-0
Docker:docker部署PXC-5.7.21(mysql5.7.21)集群搭建负载均衡实现双机热部署方案的更多相关文章
- Docker 与 K8S学习笔记(二十三)—— Kubernetes集群搭建
小伙伴们,好久不见,这几个月实在太忙,所以一直没有更新,今天刚好有空,咱们继续k8s的学习,由于我们后面需要深入学习Pod的调度,所以我们原先使用MiniKube搭建的实验环境就不能满足我们的需求了, ...
- nginx负载均衡和tomcat热部署简单了解
简单说下几个名词 nginx 它是一个反向代理,实际上就是一台负责转发的代理服务器,貌似充当了真正服务器的功能,但实际上并不是,代理服务器只是充当了转发的作用,并且从真正的服务器那里取得返回的 ...
- (七) Docker 部署 MySql8.0 一主一从 高可用集群
参考并感谢 官方文档 https://hub.docker.com/_/mysql y0ngb1n https://www.jianshu.com/p/0439206e1f28 vito0319 ht ...
- docker swarm英文文档学习-6-添加节点到集群
Join nodes to a swarm添加节点到集群 当你第一次创建集群时,你将单个Docker引擎置于集群模式中.为了充分利用群体模式,可以在集群中添加节点: 添加工作节点可以增加容量.当你将服 ...
- docker实验--redis集群搭建
背景介绍: 我经常在做一些小项目的时候,采用了Redis来做缓存,但是都是基于单节点的,一旦redis挂了,整个项目就挂了.于是乎,想到了多节点集群的方式来使用,就开始折腾着怎么去搭建这个集群.在网上 ...
- 基于Docker的Consul服务发现集群搭建
在去年的.NET Core微服务系列文章中,初步学习了一下Consul服务发现,总结了两篇文章.本次基于Docker部署的方式,以一个Demo示例来搭建一个Consul的示例集群,最后给出一个HA的架 ...
- docker redis4.0集群搭建
一.前言 redis集群对于很多人来说非常熟悉,在前些日子,我也有一位大兄弟也发布过一篇关于在阿里云(centOS7)上搭建redis 集群的文章,虽然集群搭建的文章在网上很多,我比较喜欢这篇文章的地 ...
- Zookeeper集群搭建(多节点,单机伪集群,Docker集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
- Docker下ETCD集群搭建
搭建集群之前首先准备两台安装了CentOS 7的主机,并在其上安装好Docker. Master 10.100.97.46 Node 10.100.97.64 ETCD集群搭建有三种方式,分别是Sta ...
随机推荐
- Linux_搭建Samba服务(认证访问)
[RHEL8]-SMBserver:[RHEL7]-SMBclient !!!测试环境我们首关闭防火墙和selinux(SMBserver和SMBclient都需要) [root@localhost ...
- 1.5linux用户权限相关命令
用户权限相关命令 目标 用户 和 权限 的基本概念 用户管理 终端命令 组管理 终端命令 修改权限 终端命令 01. 用户 和 权限 的基本概念 1.1 基本概念 用户 是 Linux 系统工作中重要 ...
- Boa Web Server 缺陷报告及其修正方法
综述 Boa 作为一种轻巧实用的 WEB 服务器广泛应用于嵌入式设备上, 但 Boa 对实现动态网页的 CGI 的支持上仍存在一些缺陷, 本文描述了 Boa 对 CGI 的 Status/Locat ...
- 关于Ajax 的 cache 属性 (Day_34)
最近做项目,在某些页面显示,ajax刷新总是拿不到新内容,时常需要清除缓存,才能到达想要的效果. 经过再次查看文档,最后加了一行属性:cache:false 即可解决问题 我们先看下文档的说明: 可以 ...
- CUDA运行时 Runtime(四)
CUDA运行时 Runtime(四) 一. 图 图为CUDA中的工作提交提供了一种新的模型.图是一系列操作,如内核启动,由依赖项连接,依赖项与执行分开定义.这允许定义一次图形,然后重复启动.将 ...
- 人工智能AI智能加速卡技术
人工智能AI智能加速卡技术 一. 可编程AI加速卡 1. 概述: 这款可编程AI加速器卡具备 FPGA 加速的强大性能和多功能性,可部署AI加速器IP(WNN/GNN,直接加速卷积神经网络,直接运行常 ...
- 如何在TVM上集成Codegen(下)
如何在TVM上集成Codegen(下) Bring DNNL to TVM: JSON Codegen/Runtime 现在实现将中继图序列化为JSON表示的DNNL codegen,然后实现DNNL ...
- CodeGen字段循环Field Loop
CodeGen字段循环Field Loop 字段循环是一个模板文件构造,它允许迭代CodeGen拥有的有关字段的集合.这些字段定义可以来自以下两个位置之一: •如果基于从存储库结构中获取的信息生成代码 ...
- Redux/Mobx/Akita/Vuex对比 - 选择更适合低代码场景的状态管理方案
近期准备开发一个数据分析 SDK,定位是作为数据中台向外输出数据分析能力的载体,前端的功能表现类似低代码平台的各种拖拉拽.作为中台能力的载体,SDK 未来很大概率会需要支持多种视图层框架,比如Vue2 ...
- 在pycham中安装win32
导言:在应用import win32时,需要先在pycham 中安装pywin32 ,如下为安装步骤. 一.升级pycham中的pip为最新的版本 备注:如果pip不是最新版本,直接安装pywin3 ...