ubantu 16.4 Hadoop 完全分布式搭建
一个虚拟机
- 1.以 NAT网卡模式 装载虚拟机
- 2.最好将几个用到的虚拟机修改主机名,静态IP /etc/network/interface,这里 是 s101 s102 s103 三台主机 ubantu,改/etc/hostname文件
- 3.安装ssh
- 在第一台主机那里s101 创建公私密匙
- ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
- >cd .ssh
- >cp id_rsa.pub >authorized_keys 创建密匙库
- 将id_rsa.pub传到其他主机上,到.ssh目录下
- 通过 服务端 nc -l 8888 >~/.ssh/authorized_keys
- 客户端 nc s102 8888 <id_rsa.pub
- 在第一台主机那里s101 创建公私密匙
开始安装Hadoop/jdk
- 安装VM-tools 方便从win 10 拖拉文件到ubantu
- 创建目录 /soft
- 改变组 chown ubantu:ubantu /soft 方便传输文件有权限
- 将文件放入到/soft (可以从桌面cp/mv src dst)
- tar -zxvf jdk或hadoop 自动创建解压目录
- 配置安装环境 (/etc/environment)
- 添加 JAVA_HOME=/soft/jdk-...jdk目录
- 添加 HADOOP_HOME=/soft/hadoop(Hadoop目录)
- 在path里面加/soft/jdk-...jdk/bin:/soft/hadoop/bin/:/soft/hadoop/sbin
- 通过 java -version 查看有版本号 成功
- hadoop version 有版本号 成功
开始配置HDFS四大文件 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml
- core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://s101:9000</value>
</property> </configuration>
2.hdfs-site.xml
<configuration>
<!-- Configurations for NameNode: -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>file:/data/hdfs/name</value>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>file:/data/hdfs/data</value>
</property> <property>
<name>dfs.namenode.secondary.http-address</name>
<value>s101:50090</value>
</property> <property>
<name>dfs.namenode.http-address</name>
<value>s101:50070</value>
<description>
The address and the base port where the dfs namenode web ui will listen on.
If the port is 0 then the server will start on a free port.
</description>
</property> <property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/data/hdfs/checkpoint</value>
</property> <property>
<name>dfs.namenode.checkpoint.edits.dir</name>
<value>file:/data/hdfs/edits</value>
</property>
</configuration>
3. mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>s101</value>
</property>
</configuration>
到此成功一半。。。。。。。。。。。。。。
创建文件夹
mkdir /data/hdfs/tmp
mkdir /data/hdfs/var
mkdir /data/hdfs/logs
mkdir /data/hdfs/dfs
mkdir /data/hdfs/data
mkdir /data/hdfs/name
mkdir /data/hdfs/checkpoint
mkdir /data/hdfs/edits
记得将目录权限修改
- sudo chown ubantu:ubantu /data
接下来传输 /soft文件夹到其他主机
创建 xsync可执行文件
- sudo touch xsync
- sudo chmod 777 xsync 权限变成可执行文件
- sudo nano xsync
#!/bin/bash
pcount=$#
if((pcount<));then
echo no args;
exit;
fi p1=$;
fname=`basename $p1`
pdir=`cd -P $(dirname $p1);pwd` cuser=`whoami`
for((host= ; host< ;host=host+));do
echo --------s$host--------
rsync -rvl $pdir/$fname $cuser@s$host:$pdir
done- xsync /soft-------->就会传文件夹到其他主机
- xsync /data
创建 xcall 向其他主机传命令
#!/bin/bash
pcount=$#
if((pcount<));then
echo no args;
exit;
fi
echo --------localhost-------- $@
for ((host=;host<;host=host+));do
echo --------$shost--------
ssh s$host $@
done
别着急 快结束了 哈
还得配置 workers问价
- 将需要配置成数据节点(DataNode)的主机名放入其中,一行一个
注意重点来了
- 先格式化 hadoop -namenode -format
- 再 启动 start-all.sh
- 查看进程 xcall jps
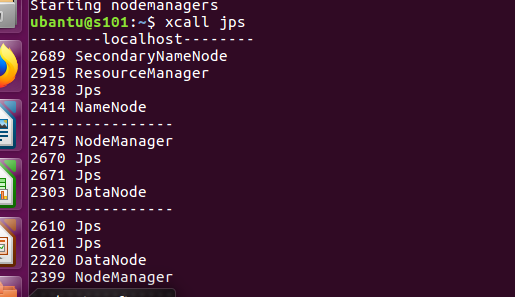
进入网页
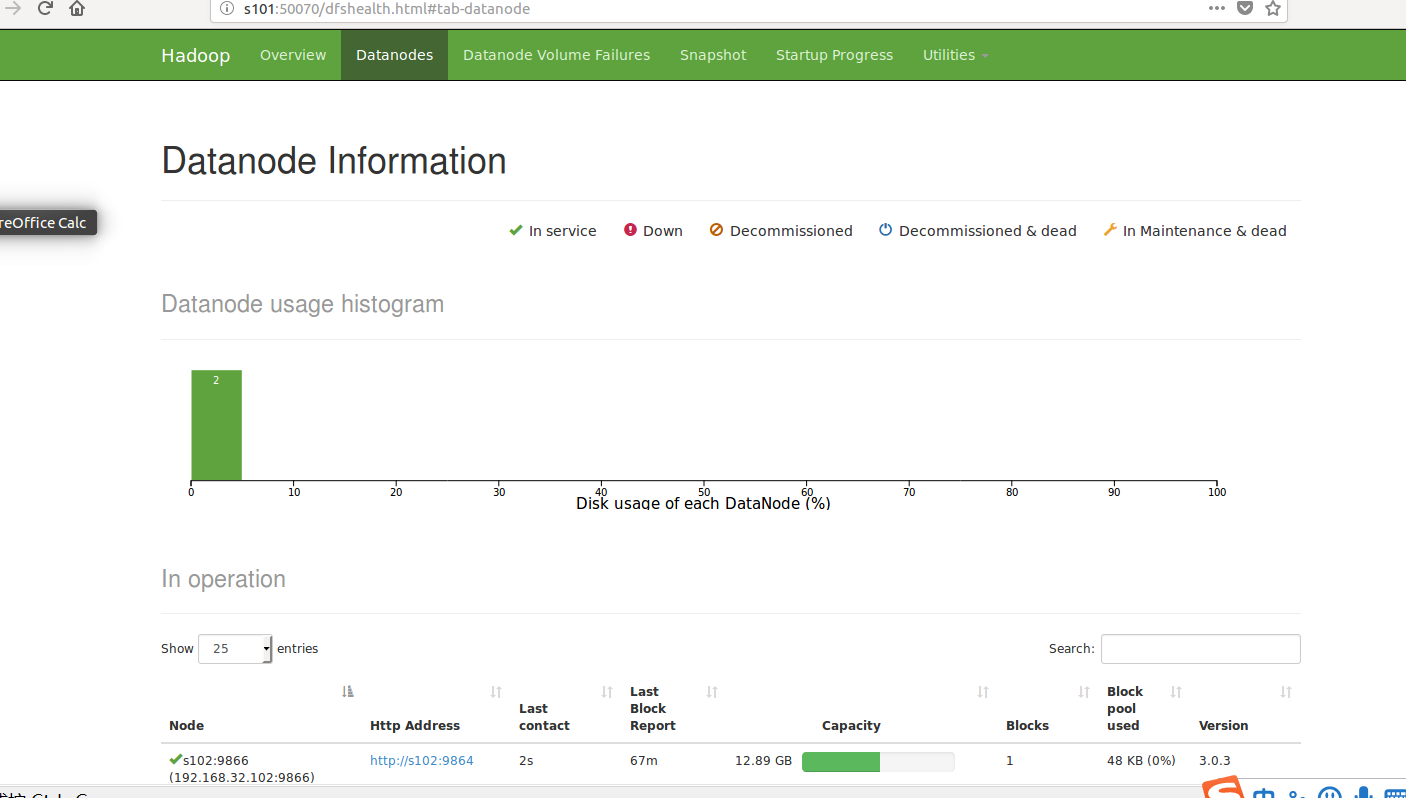
是不是很想牛泪,成功了耶!!!
中间出现了很多问题
1, rsync 权限不够 :删除文件夹 更改文件夹权限chown
2.学会看日志 log
ubantu 16.4 Hadoop 完全分布式搭建的更多相关文章
- hadoop完全分布式搭建HA(高可用)
2018年03月25日 16:25:26 D调的Stanley 阅读数:2725 标签: hadoop HAssh免密登录hdfs HA配置hadoop完全分布式搭建zookeeper 配置 更多 个 ...
- 超详细解说Hadoop伪分布式搭建--实战验证【转】
超详细解说Hadoop伪分布式搭建 原文http://www.tuicool.com/articles/NBvMv2原原文 http://wojiaobaoshanyinong.iteye.com/b ...
- 3.hadoop完全分布式搭建
3.Hadoop完全分布式搭建 1.完全分布式搭建 配置 #cd /soft/hadoop/etc/ #mv hadoop local #cp -r local full #ln -s full ha ...
- Hadoop伪分布式搭建(一)
下面内容主要说明在Windows虚拟机上面,怎么搭建一个Hadoop伪分布式,并如何运行wordcount程序和网页查看HDFS文件系统. 1 相关软件下载和安装 APACH官网提供hadoop版本 ...
- Hadoop伪分布式搭建步骤
说明: 搭建环境是VMware10下用的是Linux CENTOS 32位,Hadoop:hadoop-2.4.1 JAVA :jdk7 32位:本文是本人在网络上收集的HADOOP系列视频所附带的 ...
- Hadoop 完全分布式搭建
搭建环境 https://www.cnblogs.com/YuanWeiBlogger/p/11456623.html 修改主机名------------------- 1./etc/hostname ...
- hadoop 伪分布式搭建
下载hadoop1.0.4版本,和jdk1.6版本或更高版本:1. 安装JDK,安装目录大家可以自定义,下面是我的安装目录: /usr/jdk1.6.0_22 配置环境变量: [root@hadoop ...
- Hadoop完全分布式搭建过程中遇到的问题小结
前一段时间,终于抽出了点时间,在自己本地机器上尝试搭建完全分布式Hadoop集群环境,也是借助网络上虾皮的Hadoop开发指南系列书籍一步步搭建起来的,在这里仅代表hadoop初学者向虾皮表示衷心的感 ...
- Hadoop完全分布式搭建流程
centos7 搭建完全分布式 Hadoop 环境 SSR 前言 本次教程是以先创建 四台虚拟机 为基础,再配置好一台虚拟机的情况下,直接复制文件到另外的虚拟机中(这样做大大简化了安装流程) 且本次 ...
随机推荐
- CLR关于语言文化的类型一CultureInfo类和字符串与线程的关联
.Net Frameword使用System.Globalization.Culture类型表示一个"语言/国家"对(根据RFC 1766标准).例如,'en-US'代表美国英语, ...
- c++的动态绑定和静态绑定
为了支持c++的多态性,才用了动态绑定和静态绑定. 1.对象的静态类型:对象在声明时采用的类型.是在编译期确定的. 2.对象的动态类型:目前所指对象的声明.在运行期决定.对象的动态类型可以更改,但是静 ...
- 确保线程安全下使用Queue的Enqueue和Dequeue
场景是这样,假设有一台设备会触发类型为Alarm的告警信号,并把信号添加到一个Queue结构中,每隔一段时间这个Queue会被遍历检查,其中的每个Alarm都会调用一个相应的处理方法.问题在于,检查机 ...
- 工具-CrashMonkey4IOS,Monkey测试方案
在TesterHome看到了CrashMonkey4IOS,顿时觉得之前用instrument在做monkey测试,非常的弱智!crash后啥都看不到,无crashlog,无crash步骤,并且也不能 ...
- GO入门——4. 数组、切片与map
1. 数组 定义数组的格式:var [n],n>=0 数组长度也是类型的一部分,因此具有不同长度的数组为不同类型 注意区分指向数组的指针和指针数组 //数组的指针 a := [2]int{1, ...
- jenkins持续集成的步骤
项目的持续集成分享 源代码管理 项目仓库 配置仓库 发布仓库 ci/cd相关 gitlab,管理版本,测试流水线 jenkins,对项目进行持续集成 各模块的关系 graph TD a(jenkins ...
- JAVA与DOM解析器基础 学习笔记
要求 必备知识 JAVA基础知识.XML基础知识. 开发环境 MyEclipse10 资料下载 源码下载 文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的 ...
- C# Claims-based(基于声明)的认证
本文是通过验证与网上资料整合的,请读者注意. 目录: 1. 什么是Claims-based认证 2.进一步理解Claims-based认证 3.Claims-based的简单demo 1. 什么是Cl ...
- sql 中有关时间的语句
1.比较得到两个时间相差的间隔 SELECT datediff(minute, ’2009-04-28 12:05:00′, getdate()); SELECT datediff(month, ’2 ...
- SVN问题之——org.apache.subversion.javahl.ClientException: Attempted to lock an already-locked dir(网摘文)
一.问题描述 今天在 Eclipse 中用 SVN 插件提交代码时遇到 org.apache.subversion.javahl.ClientException: Attempted to lock ...