朴素贝叶斯算法的python实现
朴素贝叶斯
算法优缺点
优点:在数据较少的情况下依然有效,可以处理多类别问题
缺点:对输入数据的准备方式敏感
适用数据类型:标称型数据
算法思想:
朴素贝叶斯
比如我们想判断一个邮件是不是垃圾邮件,那么我们知道的是这个邮件中的词的分布,那么我们还要知道:垃圾邮件中某些词的出现是多少,就可以利用贝叶斯定理得到。
朴素贝叶斯分类器中的一个假设是:每个特征同等重要
函数
loadDataSet()
创建数据集,这里的数据集是已经拆分好的单词组成的句子,表示的是某论坛的用户评论,标签1表示这个是骂人的
createVocabList(dataSet)
找出这些句子中总共有多少单词,以确定我们词向量的大小
setOfWords2Vec(vocabList, inputSet)
将句子根据其中的单词转成向量,这里用的是伯努利模型,即只考虑这个单词是否存在
bagOfWords2VecMN(vocabList, inputSet)
这个是将句子转成向量的另一种模型,多项式模型,考虑某个词的出现次数
trainNB0(trainMatrix,trainCatergory)
计算P(i)和P(w[i]|C[1])和P(w[i]|C[0]),这里有两个技巧,一个是开始的分子分母没有全部初始化为0是为了防止其中一个的概率为0导致整体为0,另一个是后面乘用对数防止因为精度问题结果为0
classifyNB(vec2Classify, p0Vec, p1Vec, pClass1)
根据贝叶斯公式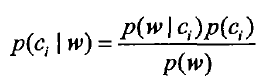 计算这个向量属于两个集合中哪个的概率高
计算这个向量属于两个集合中哪个的概率高
#coding=utf-8
from numpy import *
def loadDataSet():
postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
classVec = [0,1,0,1,0,1] #1 is abusive, 0 not
return postingList,classVec #创建一个带有所有单词的列表
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet) def setOfWords2Vec(vocabList, inputSet):
retVocabList = [0] * len(vocabList)
for word in inputSet:
if word in vocabList:
retVocabList[vocabList.index(word)] = 1
else:
print 'word ',word ,'not in dict'
return retVocabList #另一种模型
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec def trainNB0(trainMatrix,trainCatergory):
numTrainDoc = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = sum(trainCatergory)/float(numTrainDoc)
#防止多个概率的成绩当中的一个为0
p0Num = ones(numWords)
p1Num = ones(numWords)
p0Denom = 2.0
p1Denom = 2.0
for i in range(numTrainDoc):
if trainCatergory[i] == 1:
p1Num +=trainMatrix[i]
p1Denom += sum(trainMatrix[i])
else:
p0Num +=trainMatrix[i]
p0Denom += sum(trainMatrix[i])
p1Vect = log(p1Num/p1Denom)#处于精度的考虑,否则很可能到限归零
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1):
p1 = sum(vec2Classify * p1Vec) + log(pClass1) #element-wise mult
p0 = sum(vec2Classify * p0Vec) + log(1.0 - pClass1)
if p1 > p0:
return 1
else:
return 0 def testingNB():
listOPosts,listClasses = loadDataSet()
myVocabList = createVocabList(listOPosts)
trainMat=[]
for postinDoc in listOPosts:
trainMat.append(setOfWords2Vec(myVocabList, postinDoc))
p0V,p1V,pAb = trainNB0(array(trainMat),array(listClasses))
testEntry = ['love', 'my', 'dalmation']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb)
testEntry = ['stupid', 'garbage']
thisDoc = array(setOfWords2Vec(myVocabList, testEntry))
print testEntry,'classified as: ',classifyNB(thisDoc,p0V,p1V,pAb) def main():
testingNB() if __name__ == '__main__':
main()机器学习笔记索引
朴素贝叶斯算法的python实现的更多相关文章
- 朴素贝叶斯算法的python实现方法
朴素贝叶斯算法的python实现方法 本文实例讲述了朴素贝叶斯算法的python实现方法.分享给大家供大家参考.具体实现方法如下: 朴素贝叶斯算法优缺点 优点:在数据较少的情况下依然有效,可以处理多类 ...
- 朴素贝叶斯算法的python实现-乾颐堂
算法优缺点 优点:在数据较少的情况下依然有效,可以处理多类别问题 缺点:对输入数据的准备方式敏感 适用数据类型:标称型数据 算法思想: 朴素贝叶斯 比如我们想判断一个邮件是不是垃圾邮件,那么我们知道的 ...
- 朴素贝叶斯算法的python实现 -- 机器学习实战
import numpy as np import re #词表到向量的转换函数 def loadDataSet(): postingList = [['my', 'dog', 'has', 'fle ...
- 朴素贝叶斯算法--python实现
朴素贝叶斯算法要理解一下基础: [朴素:特征条件独立 贝叶斯:基于贝叶斯定理] 1朴素贝叶斯的概念[联合概率分布.先验概率.条件概率**.全概率公式][条件独立性假设.] 极大似然估计 ...
- 朴素贝叶斯算法原理及Spark MLlib实例(Scala/Java/Python)
朴素贝叶斯 算法介绍: 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法. 朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,在没有其它可用信息下,我 ...
- 机器学习:python中如何使用朴素贝叶斯算法
这里再重复一下标题为什么是"使用"而不是"实现": 首先,专业人士提供的算法比我们自己写的算法无论是效率还是正确率上都要高. 其次,对于数学不好的人来说,为了实 ...
- Python机器学习笔记:朴素贝叶斯算法
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论的分类算法.对于大多数的分类算法,在所有的机器学习分类算法中,朴素贝叶斯和其他绝大多数的分类算法都不同.比如决策树,KNN,逻辑回归,支持向 ...
- Python机器学习算法 — 朴素贝叶斯算法(Naive Bayes)
朴素贝叶斯算法 -- 简介 朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法.最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Baye ...
- 机器学习---用python实现朴素贝叶斯算法(Machine Learning Naive Bayes Algorithm Application)
在<机器学习---朴素贝叶斯分类器(Machine Learning Naive Bayes Classifier)>一文中,我们介绍了朴素贝叶斯分类器的原理.现在,让我们来实践一下. 在 ...
随机推荐
- BZOJ 3223: Tyvj 1729 文艺平衡树
3223: Tyvj 1729 文艺平衡树 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 3628 Solved: 2052[Submit][Sta ...
- 初步搭建RocketMQ环境
1. 去官网https://github.com/alibaba/RocketMQ/releases下载alibaba-rocketmq-3.2.6.tar.gz,这个是已经maven install ...
- [Think In Java]基础拾遗2 - 多态、反射、异常、字符串
目录 第八章 多态第十四章 类型信息第十二章 通过异常处理错误第十三章 字符串 第八章 多态 1. 前期绑定 & 后期绑定 绑定是指将方法调用同一个方法主体关联起来的这么一个过程.如果在程序执 ...
- 【BZOJ-2669】局部极小值 状压DP + 容斥原理
2669: [cqoi2012]局部极小值 Time Limit: 3 Sec Memory Limit: 128 MBSubmit: 561 Solved: 293[Submit][Status ...
- <<< html图片背景平铺
CSS背景图片平铺技巧 使用CSS来设置背景图片同传统的做法一样简单,但相对于传统控制方式,CSS提供了更多的可控选项,我们先来看看最基本的设置图片的方法.html代码: 代码如下: <divi ...
- 个人学习记录1:二维数组保存到cookie后再读取
二维数组保存到cookie后再读取 var heartsArray = [[0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0],[0,0,0,0,0,0,0,0,0,0,0],[0,0, ...
- jQuery验证控件jquery.validate.js使用说明
官网地址:http://bassistance.de/jquery-plugins/jquery-plugin-validation jQuery plugin: Validation 使用说明 转载 ...
- [NHibernate]组件之依赖对象
目录 写在前面 文档与系列文章 组件之依赖对象 一个例子 总结 写在前面 周一至周四一直在成都出差,也一直没有更新博客了,一回到家第一件事就是扒一扒最近博客园更新的文章,然后把想看的收藏了,大概有20 ...
- 再谈vim中多窗口的编辑
参考:http://blog.csdn.net/shuangde800/article/details/11430659 很好 鼠标在各个窗口间循环移动: ctrl+w+(小写的 hjkl), &qu ...
- jenkins使用简记
一.安装 jenkins有多种安装方式,可以使用内嵌的Servlet容器运行,也可以基于Apache运行,也可以安装成Linux或Windows服务. 1.使用 Servlet 容器运行 从官网下载 ...