python3初探
官方网站:https://www.python.org/
类库大全:https://pypi.python.org/pypi
基础类库:https://docs.python.org/3/library/index.html
安装
解释器
交互式编程
脚本式编程
基础语法
编码
标识符
关键字
注释
行与缩进
基本数据类型
Numbers(数字)
String(字符串)
List(列表)
Tuple(元组)
Sets(集合)
Dictionaries(字典)
条件控制
循环
while 循环
for语句
range()函数
break和continue语句及循环中的else子句
pass语句
函数
变量作用域
缺省参数
返回值
可变参数
匿名函数
map/reduce
类
继承
私有属性与方法
元类type
@property
异常处理
抛出异常
自定义异常
finally与with
自定义模块
参考
简介
Python(英国发音:/ˈpaɪθən/ 美国发音:/ˈpaɪθɑːn/), 是一种面向对象、解释型计算机程序设计语言,由Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。
Python是纯粹的自由软件, 源代码和解释器CPython遵循 GPL(GNU General Public License)协议[1] 。
Python的哲学是“做一件事情有且只有一种方法”(There should be one– and preferably only one –obvious way to do it.)。
Python是完全面向对象的语言。函数、模块、数字、字符串都是对象。并且完全支持继承、重载、派生、多继承,有益于增强源代码的复用性。Python支持重载运算符和动态类型。
Python具有丰富和强大的库。它常被昵称为胶水语言,能够把用其他语言制作的各种模块(尤其是C/C++)很轻松地联结在一起。常见的一种应用情形是,使用Python快速生成程序的原型(有时甚至是程序的最终界面),然后对其中有特别要求的部分,用更合适的语言改写,比如3D游戏中的图形渲染模块,性能要求特别高,就可以用C/C++重写,而后封装为Python可以调用的扩展类库。需要注意的是在您使用扩展类库时可能需要考虑平台问题,某些可能不提供跨平台的实现。
由于Python语言的简洁、易读以及可扩展性,在国外用Python做科学计算的研究机构日益增多,一些知名大学已经采用Python教授程序设计课程。例如卡耐基梅隆大学的编程基础、麻省理工学院的计算机科学及编程导论就使用Python语言讲授。众多开源的科学计算软件包都提供了Python的调用接口,例如著名的计算机视觉库OpenCV、三维可视化库VTK、医学图像处理库ITK。而Python专用的科学计算扩展库就更多了,例如如下3个十分经典的科学计算扩展库:NumPy、SciPy和matplotlib,它们分别为Python提供了快速数组处理、数值运算以及绘图功能。因此Python语言及其众多的扩展库所构成的开发环境十分适合工程技术、科研人员处理实验数据、制作图表,甚至开发科学计算应用程序。
Python开发人员尽量避开不成熟或者不重要的优化。一些针对非重要部位的加快运行速度的补丁通常不会被合并到Python内。所以很多人认为Python很慢。不过,根据二八定律,大多数程序对速度要求不高。在某些对运行速度要求很高的情况,Python设计师倾向于使用JIT技术,或者用使用C/C++语言改写这部分程序。
安装
curl -R -O https://www.python.org/ftp/python/3.5.1/Python-3.5.1.tgz
tar zxf Python-3.5.1.tgzz代表gzip的压缩包;x代表解压;v代表显示过程信息;f代表后面接的是文件
cd Python-3.5.1
./configure
make
make install
设置环境变量
export PATH=”$PATH:/usr/local/bin/python3”
安装完成
leestar@leestar-ThinkPad-SL410:~$ python3
python3
Python 3.5.1 (default, Mar 14 2016, 22:23:55)
[GCC 5.2.1 20151010] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
>>>
python包管理工具pypi
https://pip.pypa.io/en/latest/installing/
curl -R -O https://bootstrap.pypa.io/get-pip.py
sudo python get-pip.py
pip -V
pip 8.1.0 from /usr/local/lib/python2.7/dist-packages (python 2.7)
解释器
Linux/Unix的系统上,Python解释器通常被安装在 /usr/local/bin/python3.5 这样的有效路径(目录)里。
我们可以将路径 /usr/local/bin 添加到您的Linux/Unix操作系统的环境变量中,这样您就可以通过 shell 终端输入下面的命令来启动 Python 。
交互式编程
我们可以在命令提示符中输入”python3”命令来启动Python解释器:
leestar@leestar-ThinkPad-SL410:~$ python3
python3
Python 3.5.1 (default, Mar 14 2016, 22:23:55)
[GCC 5.2.1 20151010] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
>>>
当键入一个多行结构时,续行是必须的。我们可以看下如下 if 语句:
>>> the_world_is_flat = True
>>> if the_world_is_flat:
… print(“Be careful not to fall off!”)
…
Be careful not to fall off!
脚本式编程
通过以下命令执行该脚本:
python hello.py
在Linux/Unix系统中,你可以在脚本顶部添加以下命令让Python脚本可以像SHELL脚本一样可直接执行:
#! /usr/bin/python3
然后修改脚本权限,使其有执行权限,命令如下:
$ chmod +x hello.py
执行./hello.py
基础语法
编码
默认情况下,Python 3源码文件以 UTF-8 编码,所有字符串都是 unicode 字符串。 当然你也可以为源码文件指定不同的编码:
# -- coding: cp-1252 --
标识符
- 第一个字符必须是字母表中字母或下划线’_’。
- 标识符的其他的部分有字母、数字和下划线组成。
- 标识符对大小写敏感。
关键字
Python的标准库提供了一个keyword module,可以输出当前版本的所有关键字:
>>> import keyword
>>> keyword.kwlist [‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’, ‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’]
注释
Python中单行注释以#开头,多行注释用三个单引号(”’)或者三个双引号(”“”)将注释括起来。
#!/usr/bin/python3'''这是多行注释,用三个单引号这是多行注释,用三个单引号这是多行注释,用三个单引号'''print("Hello, World!")
行与缩进
python最具特色的就是使用缩进来表示代码块。缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
基本数据类型
Python中的变量不需要声明。每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建。
在Python中,变量就是变量,它没有类型,我们所说的”类型”是变量所指的内存中对象的类型。
Python 3中有六个标准的数据类型:
Numbers(数字)String(字符串)List(列表)Tuple(元组)Sets(集合)Dictionaries(字典)
Numbers(数字)
Python 3支持int、float、bool、complex(复数)。
数值类型的赋值和计算都是很直观的,就像大多数语言一样。内置的type()函数可以用来查询变量所指的对象类型。
2 / 4 # 除法,得到一个浮点数 0.5
2 // 4 # 除法,得到一个整数 0
2 ** 5 # 乘方 32
1、Python可以同时为多个变量赋值,如a, b = 1, 2。
2、一个变量可以通过赋值指向不同类型的对象。
3、数值的除法(/)总是返回一个浮点数,要获取整数使用//操作符。
4、在混合计算时,Python会把整型转换成为浮点数。
String(字符串)
Python中的字符串str用单引号(’ ‘)或双引号(” “)括起来,同时使用反斜杠()转义特殊字符。
如果你不想让反斜杠发生转义,可以在字符串前面添加一个r,表示原始字符串:
>>> print(r’C:\some\name’)
C:\some\name
另外,反斜杠可以作为续行符,表示下一行是上一行的延续。还可以使用”“”…”“”或者”’…”’跨越多行。
字符串可以使用 + 运算符串连接在一起,或者用 * 运算符重复:
>>> print(‘str’+’ing’, ‘my’*3)
string mymymy
Python中的字符串有两种索引方式,第一种是从左往右,从0开始依次增加;第二种是从右往左,从-1开始依次减少。
注意,没有单独的字符类型,一个字符就是长度为1的字符串。
>>> word = ‘Python’
>>> print(word[0], word[5])
P n
>>> print(word[-1], word[-6])
n P
还可以对字符串进行切片,获取一段子串。用冒号分隔两个索引,形式为变量[头下标:尾下标]。
截取的范围是前闭后开的,并且两个索引都可以省略:
>>> word = ‘ilovepython’
>>> word[1:5]
‘love’
>>> word[:]
‘ilovepython’
>>> word[5:]
‘python’
>>> word[-10:-6]
‘love’
与C字符串不同的是,Python字符串不能被改变。向一个索引位置赋值,比如word[0] = ‘m’会导致错误。
1、反斜杠可以用来转义,使用r可以让反斜杠不发生转义。
2、字符串可以用+运算符连接在一起,用*运算符重复。
3、Python中的字符串有两种索引方式,从左往右以0开始,从右往左以-1开始。
4、Python中的字符串不能改变。
List(列表)
列表是写在方括号之间、用逗号分隔开的元素列表。列表中元素的类型可以不相同
和字符串一样,列表同样可以被索引和切片,列表被切片后返回一个包含所需元素的新列表。
列表还支持串联操作,使用+操作符:
>>> a=[1,2,3,4]
>>> a+[5,6,7]
[1, 2, 3, 4, 5, 6, 7]
与Python字符串不一样的是,列表中的元素是可以改变的
1、List写在方括号之间,元素用逗号隔开。
2、和字符串一样,list可以被索引和切片。
3、List可以使用+操作符进行拼接。
4、List中的元素是可以改变的。
Tuple(元组)
元组(tuple)与列表类似,不同之处在于元组的元素不能修改。元组写在小括号里,元素之间用逗号隔开。
元组中的元素类型也可以不相同:
>>> a = (1991, 2014, ‘physics’, ‘math’)
元组与字符串类似,可以被索引且下标索引从0开始,也可以进行截取/切片。
其实,可以把字符串看作一种特殊的元组。
虽然tuple的元素不可改变,但它可以包含可变的对象,比如list列表。
构造包含0个或1个元素的tuple是个特殊的问题,所以有一些额外的语法规则:
tup1 =()# 空元组tup2 =(20,)# 一个元素,需要在元素后添加逗号
元组也支持用+操作符,string、list和tuple都属于sequence(序列)。
1、与字符串一样,元组的元素不能修改。
2、元组也可以被索引和切片,方法一样。
3、注意构造包含0或1个元素的元组的特殊语法规则。
4、元组也可以使用+操作符进行拼接。
Sets(集合)
集合(set)是一个无序不重复元素的集。
基本功能是进行成员关系测试和消除重复元素。重复的元素被自动去掉
可以使用大括号 或者 set()函数创建set集合,注意:创建一个空集合必须用 set() 而不是 { },因为{ }是用来创建一个空字典。
>>> student = {‘Tom’, ‘Jim’, ‘Mary’, ‘Tom’, ‘Jack’, ‘Rose’}
>>> print(student) # 重复的元素被自动去掉
{‘Jim’, ‘Jack’, ‘Mary’, ‘Tom’, ‘Rose’}
>>> ‘Rose’ in student # membership testing(成员测试)
True
>>> # set可以进行集合运算 …
>>> a = set(‘abracadabra’)
>>> b = set(‘alacazam’)
>>> a {‘a’, ‘b’, ‘c’, ‘d’, ‘r’}
>>> a - b # a和b的差集
{‘b’, ‘d’, ‘r’}
>>> a | b # a和b的并集
{‘l’, ‘m’, ‘a’, ‘b’, ‘c’, ‘d’, ‘z’, ‘r’}
>>> a & b # a和b的交集
{‘a’, ‘c’}
>>> a ^ b # a和b中不同时存在的元素
{‘l’, ‘m’, ‘b’, ‘d’, ‘z’, ‘r’}
Dictionaries(字典)
字典(dictionary)是Python中另一个非常有用的内置数据类型。
字典是一种映射类型(mapping type),它是一个无序的键 : 值对集合。
关键字必须使用不可变类型,也就是说list和包含可变类型的tuple不能做关键字。
在同一个字典中,关键字还必须互不相同。
>>> dic = {} # 创建空字典
>>> tel = {‘Jack’:1557, ‘Tom’:1320, ‘Rose’:1886}
>>> tel
{‘Tom’: 1320, ‘Jack’: 1557, ‘Rose’: 1886}
>>> tel[‘Jack’] # 主要的操作:通过key查询
1557
>>> del tel[‘Rose’] # 删除一个键值对
>>> tel[‘Mary’] = 4127 # 添加一个键值对
>>> tel
{‘Tom’: 1320, ‘Jack’: 1557, ‘Mary’: 4127}
>>> list(tel.keys()) # 返回所有key组成的list
[‘Tom’, ‘Jack’, ‘Mary’]
>>> sorted(tel.keys()) # 按key排序
[‘Jack’, ‘Mary’, ‘Tom’]
>>> ‘Tom’ in tel # 成员测试
True
>>> ‘Mary’ not in tel # 成员测试
False
构造函数 dict() 直接从键值对sequence中构建字典,当然也可以进行推导
>>> dict([(‘sape’, 4139), (‘guido’, 4127), (‘jack’, 4098)])
{‘jack’: 4098, ‘sape’: 4139, ‘guido’: 4127}
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
>>> dict(sape=4139, guido=4127, jack=4098)
{‘jack’: 4098, ‘sape’: 4139, ‘guido’: 4127}
1、字典是一种映射类型,它的元素是键值对。
2、字典的关键字必须为不可变类型,且不能重复。
3、创建空字典使用{ }。
条件控制
if condition_1:statement_block_1elif condition_2:statement_block_2else:statement_block_3
1、每个条件后面要使用冒号(:),表示接下来是满足条件后要执行的语句块。
2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。
3、在Python中没有switch – case语句。
循环
while 循环
while判断条件:statements
同样需要注意冒号和缩进。另外,在Python中没有do..while循环。
for语句
Python for循环可以遍历任何序列的项目,如一个列表或者一个字符串。
for<variable>in<sequence>:<statements>else:<statements>
break语句用于跳出当前循环体
range()函数
如果你需要遍历数字序列,可以使用内置range()函数。它会生成数列
>>> for i in range(5):
… print(i)
…
0
1
2
3
4
>>> for i in range(0, 10, 3) :
… print(i)
…
0
3
6
9
结合range()和len()函数以遍历一个序列的索引
>>> a = [‘Mary’, ‘had’, ‘a’, ‘little’, ‘lamb’]>>> for i in range(len(a)):
… print(i, a[i])
…
0 Mary
1 had
2 a
3 little
4 lamb
break和continue语句及循环中的else子句
break语句可以跳出for和while的循环体。如果你从for或while循环中终止,任何对应的循环else块将不执行。
continue语句被用来告诉Python跳过当前循环块中的剩余语句,然后继续进行下一轮循环。
循环语句可以有else子句;它在穷尽列表(以for循环)或条件变为假(以while循环)循环终止时被执行,但循环被break终止时不执行.如下查寻质数的循环例子:
pass语句
pass语句什么都不做。它只在语法上需要一条语句但程序不需要任何操作时使用.例如:
>>> while True:
… pass # 等待键盘中断 (Ctrl+C)
函数
Python 定义函数使用 def 关键字,一般格式如下:
def area(width, height):return width * heightdef print_welcome(name):print("Welcome", name)print_welcome("Fred")w =4h =5print("width =", w," height =", h," area =", area(w, h))WelcomeFredwidth =4 height =5 area =20
变量作用域
定义在函数内部的变量拥有一个局部作用域,定义在函数外的拥有全局作用域。
#!/usr/bin/env python3a =4# 全局变量def print_func1():a =17# 局部变量print("in print_func a = ", a)def print_func2():print("in print_func a = ", a)print_func1()print_func2()print("a = ", a)in print_func a =17in print_func a =4a =4
缺省参数
函数也可以使用 kwarg=value 的关键字参数形式被调用
def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'):print("-- This parrot wouldn't", action, end=' ')print("if you put", voltage,"volts through it.")print("-- Lovely plumage, the", type)print("-- It's", state,"!")parrot(1000)# 1 positional argumentparrot(voltage=1000)# 1 keyword argumentparrot(voltage=1000000, action='VOOOOOM')# 2 keyword argumentsparrot(action='VOOOOOM', voltage=1000000)# 2 keyword argumentsparrot('a million','bereft of life','jump')# 3 positional argumentsparrot('a thousand', state='pushing up the daisies')# 1 positional, 1 keyword
返回值
def return_sum(x,y):c = x + yreturn cres = return_sum(4,5)print(res)
可变参数
def arithmetic_mean(*args):sum =0for x in args:sum += xreturn sumprint(arithmetic_mean(45,32,89,78))print(arithmetic_mean(8989.8,78787.78,3453,78778.73))print(arithmetic_mean(45,32))print(arithmetic_mean(45))print(arithmetic_mean())244170009.3177450
匿名函数
匿名函数lambda x: x * x实际上就是:
def f(x):return x * x
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数
>>> f = lambda x: x * x
>>> f
<function at 0x101c6ef28>
>>> f(5)
25
map/reduce
Python内建了map()和reduce()函数。
我们先看map。map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:
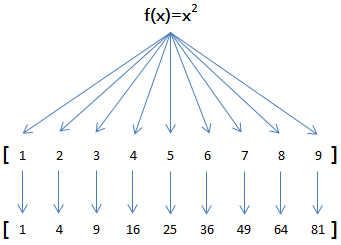
>>>def f(x):...return x * x...>>> r = map(f,[1,2,3,4,5,6,7,8,9])>>> list(r)[1,4,9,16,25,36,49,64,81]
再看reduce的用法。reduce把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算
>>>from functools import reduce>>>def add(x, y):...return x + y...>>> reduce(add,[1,3,5,7,9])25
类
和其它编程语言相比,Python 在尽可能不增加新的语法和语义的情况下加入了类机制。
Python中的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法。
对象可以包含任意数量和类型的数据。
类定义了 init() 方法的话,类的实例化操作会自动调用 init() 方法。
class people:#定义基本属性name =''age =0#定义私有属性,私有属性在类外部无法直接进行访问__weight =0#定义构造方法def __init__(self,n,a,w):self.name = nself.age = aself.__weight = w#在类地内部,使用def关键字可以为类定义一个方法,与一般函数定义不同,类方法必须包含参数self,且为第一个参数def speak(self):print("%s is speaking: I am %d years old"%(self.name,self.age))p = people('tom',10,30)p.speak()
继承
#单继承示例class student(people):grade =''def __init__(self,n,a,w,g):#调用父类的构函people.__init__(self,n,a,w)self.grade = g#覆写父类的方法def speak(self):print("%s is speaking: I am %d years old,and I am in grade %d"%(self.name,self.age,self.grade))s = student('ken',20,60,3)s.speak()
Python有限的支持多继承形式。
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
#另一个类,多重继承之前的准备class speaker():topic =''name =''def __init__(self,n,t):self.name = nself.topic = tdef speak(self):print("I am %s,I am a speaker!My topic is %s"%(self.name,self.topic))#多重继承class sample(speaker,student):a =''def __init__(self,n,a,w,g,t):student.__init__(self,n,a,w,g)speaker.__init__(self,n,t)test = sample("Tim",25,80,4,"Python")test.speak()#方法名同,默认调用的是在括号中排前地父类的方法
私有属性与方法
__private_attrs:两个下划线开头,声明该属性为私有,不能在类地外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
__private_method:两个下划线开头,声明该方法为私有方法,不能在类地外部调用。在类的内部调用 slef.__private_methods。
内置方法如下:
init 构造函数,在生成对象时调用
del 析构函数,释放对象时使用
repr 打印,转换
__setitem__按照索引赋值
__getitem__按照索引获取值
__len__获得长度
__cmp__比较运算
__call__函数调用
__add__加运算
__sub__减运算
__mul__乘运算
__div__除运算
__mod__求余运算
__pow__称方
元类type
type()函数可以查看一个类型或变量的类型,Hello是一个class,它的类型就是type,而h是一个实例,它的类型就是class Hello。
我们说class的定义是运行时动态创建的,而创建class的方法就是使用type()函数。
type()函数既可以返回一个对象的类型,又可以创建出新的类型,比如,我们可以通过type()函数创建出Hello类,而无需通过class Hello(object)…的定义
>>>def fn(self, name='world'):# 先定义函数...print('Hello, %s.'% name)...>>>Hello= type('Hello',(object,), dict(hello=fn))# 创建Hello class>>> h =Hello()>>> h.hello()Hello, world.>>>print(type(Hello))<class'type'>>>>print(type(h))<class'__main__.Hello'>
要创建一个class对象,type()函数依次传入3个参数:
- class的名称;
- 继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;
- class的方法名称与函数绑定,这里我们把函数fn绑定到方法名hello上。
通过type()函数创建的类和直接写class是完全一样的,因为Python解释器遇到class定义时,仅仅是扫描一下class定义的语法,然后调用type()函数创建出class。
正常情况下,我们都用class Xxx…来定义类,但是,type()函数也允许我们动态创建出类来,也就是说,动态语言本身支持运行期动态创建类,这和静态语言有非常大的不同,要在静态语言运行期创建类,必须构造源代码字符串再调用编译器,或者借助一些工具生成字节码实现,本质上都是动态编译,会非常复杂。
metaclass
除了使用type()动态创建类以外,要控制类的创建行为,还可以使用metaclass。
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据metaclass创建出类,所以:先定义metaclass,然后创建类。
连接起来就是:先定义metaclass,就可以创建类,最后创建实例。
所以,metaclass允许你创建类或者修改类。换句话说,你可以把类看成是metaclass创建出来的“实例”。
定义ListMetaclass,按照默认习惯,metaclass的类名总是以Metaclass结尾,以便清楚地表示这是一个metaclass
# metaclass是类的模板,所以必须从`type`类型派生:classListMetaclass(type):def __new__(cls, name, bases, attrs):attrs['add']=lambda self, value: self.append(value)return type.__new__(cls, name, bases, attrs)classMyList(list, metaclass=ListMetaclass):pass>>> L =MyList()>>> L.add(1)>> L[1]
动态修改有什么意义?直接在MyList定义中写上add()方法不是更简单吗?正常情况下,确实应该直接写,通过metaclass修改纯属变态。
但是,总会遇到需要通过metaclass修改类定义的。ORM就是一个典型的例子。
ORM全称“Object Relational Mapping”,即对象-关系映射,就是把关系数据库的一行映射为一个对象,也就是一个类对应一个表,这样,写代码更简单,不用直接操作SQL语句。
要编写一个ORM框架,所有的类都只能动态定义,因为只有使用者才能根据表的结构定义出对应的类来。
@property
Python内置的@property装饰器就是负责把一个方法变成属性调用
classStudent(object):@propertydef score(self):return self._score@score.setterdef score(self, value):ifnot isinstance(value, int):raiseValueError('score must be an integer!')if value <0or value >100:raiseValueError('score must between 0 ~ 100!')self._score = value>>> s =Student()>>> s.score =60# OK,实际转化为s.set_score(60)>>> s.score # OK,实际转化为s.get_score()60>>> s.score =9999Traceback(most recent call last):...ValueError: score must between 0~100!
注意到这个神奇的@property,我们在对实例属性操作的时候,就知道该属性很可能不是直接暴露的,而是通过getter和setter方法来实现的
还可以定义只读属性,只定义getter方法,不定义setter方法就是一个只读属性:
classStudent(object):@propertydef birth(self):return self._birth@birth.setterdef birth(self, value):self._birth = value@propertydef age(self):return2015- self._birth
异常处理
让用户输入一个合法的整数,但是允许用户中断这个程序(使用 Control-C 或者操作系统提供的方法)。用户中断的信息会引发一个 KeyboardInterrupt 异常。
whileTrue:try:x = int(input("Please enter a number: "))breakexceptValueError:print("Oops! That was no valid number. Try again ")
try语句按照如下方式工作;
- 首先,执行try子句(在关键字try和关键字except之间的语句)
- 如果没有异常发生,忽略except子句,try子句执行后结束。
- 如果在执行try子句的过程中发生了异常,那么try子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的except子句将被执行。最后执行 try 语句之后的代码。
- 如果一个异常没有与任何的except匹配,那么这个异常将会传递给上层的try中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的try子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except(RuntimeError,TypeError,NameError):pass
最后一个except子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
import systry:f = open('myfile.txt')s = f.readline()i = int(s.strip())exceptOSErroras err:print("OS error: {0}".format(err))exceptValueError:print("Could not convert data to an integer.")except:print("Unexpected error:", sys.exc_info()[0])raise
try except 语句还有一个可选的else子句,如果使用这个子句,那么必须放在所有的except子句之后。这个子句将在try子句没有发生任何异常的时候执行。
for arg in sys.argv[1:]:try:f = open(arg,'r')exceptIOError:print('cannot open', arg)else:print(arg,'has', len(f.readlines()),'lines')f.close()
抛出异常
Python 使用 raise 语句抛出一个指定的异常。
raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。
try:raiseNameError('HiThere')exceptNameError:print('An exception flew by!')raise
自定义异常
classError(Exception):"""Base class for exceptions in this module."""passclassInputError(Error):"""Exception raised for errors in the input.Attributes:expression -- input expression in which the error occurredmessage -- explanation of the error"""def __init__(self, expression, message):self.expression = expressionself.message = messageclassTransitionError(Error):"""Raised when an operation attempts a state transition that's notallowed.Attributes:previous -- state at beginning of transitionnext -- attempted new statemessage -- explanation of why the specific transition is not allowed"""def __init__(self, previous, next, message):self.previous = previousself.next = nextself.message = message
finally与with
不管try子句里面有没有发生异常,finally子句都会执行。
如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后再次被抛出。
>>>def divide(x, y):try:result = x / yexceptZeroDivisionError:print("division by zero!")else:print("result is", result)finally:print("executing finally clause")>>> divide(2,1)result is2.0executing finally clause>>> divide(2,0)division by zero!executing finally clause>>> divide("2","1")executing finally clauseTraceback(most recent call last):File"<stdin>", line 1,in?File"<stdin>", line 3,in divideTypeError: unsupported operand type(s)for/:'str'and'str'
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
当执行完毕后,文件会保持打开状态,并没有被关闭。
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法(类似C#中的using)
with open("myfile.txt")as f:for line in f:print(line, end="")
自定义模块
#!/usr/bin/env python3# -*- coding: utf-8 -*-' a test module '__author__ ='Michael Liao'import sysdef test():args = sys.argvif len(args)==1:print('Hello, world!')elif len(args)==2:print('Hello, %s!'% args[1])else:print('Too many arguments!')if __name__=='__main__':test()
以上就是Python模块的标准文件模板,当然也可以全部删掉不写,但是,按标准办事肯定没错。
sys模块有一个argv变量,用list存储了命令行的所有参数。argv至少有一个元素,因为第一个参数永远是该.py文件的名称,例如:
运行python3 hello.py获得的sys.argv就是[‘hello.py’];
运行python3 hello.py Michael获得的sys.argv就是[‘hello.py’, ‘Michael]。
参考
http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
http://www.runoob.com/python/python-tutorial.html
python3初探的更多相关文章
- Python3+unitest自动化测试初探(中篇)
目录 6.生成测试报告 7.编写邮件发送工具 8.发送邮件 发布 0 86 编辑 删除 Python3+unitest自动化测试初探(中篇)(2019-04-18 01:41) 发布 3 245 编辑 ...
- Python3+unitest自动化测试初探(下篇)
目录 9.用例结果校验 10.跳过用例 11.Test Discovery 12.加载用例 unittest官方文档 本篇随笔承接: Python3+unitest自动化测试初探(中篇) Python ...
- python3爬虫初探(一)之urllib.request
---恢复内容开始--- #小白一个,在此写下自己的python爬虫初步的知识.如有错误,希望谅解并指出. #欢迎和大家交流python爬虫相关的问题 #2016/6/18 #----第一把武器--- ...
- python3爬虫初探(五)之从爬取到保存
想一想,还是写个完整的代码,总结一下前面学的吧. import requests import re # 获取网页源码 url = 'http://www.ivsky.com/tupian/xiaoh ...
- python3爬虫初探(四)之文件保存
接着上面的写,抓取到网址之后,我们要把图片保存到本地,这里有几种方法都是可以的. #-----urllib.request.urlretrieve----- import urllib.request ...
- python3爬虫初探(三)之正则表达式
前面已经写了如何获取网页源码,那么接下来就是该解析网页并提取需要的数据了.这里简单写一下正则表达的用法. 首先,找个要抓取图片的网站,获取源码. import requests import re # ...
- python3爬虫初探(二)之requests
关于请求网页,不得不提requests这个库,这是爬虫经常用到的一个第三方库,用pip安装即可. requests用法很多,这里只写一些基础的,其他高级功能可参考官方文档. import reques ...
- Python3+unitest自动化测试初探(上篇)
目录 1.概念介绍 2.准备工作 3.一个简单的例子 4.test fixture 5.测试套 1.概念介绍 unit test:单元测试,可以简单粗暴地理解成用一段代码去测试另外一段代码.unitt ...
- Python3画图系列——NetworkX初探
NetworkX 概述 NetworkX 主要用于创造.操作复杂网络,以及学习复杂网络的结构.动力学及其功能.用于分析网络结构,建立网络模型,设计新的网络算法,绘制网络等等.安装networkx看以参 ...
随机推荐
- 为docker设置国内镜像
docker的默认镜像(https://hub.docker.com/)地址,拉取镜像时是比较慢的,经常会超时,有时拉取几个小时.为了加快拉取的时间和速度,需要添加中国的镜像地址: 国内的加速地址: ...
- Aircrack使用
Aircrack Aircrack-ng 组件功能之一就是采集WEP及WPA-PSK字典并应用无线端口扫描进行破解,具体组件说明如下: aircrack-ng 功能主要是WEP及WPA-PSK密码的恢 ...
- c# 半角转换为全角 判断是否是全角
#region 半角转换为全角 /// <summary> /// 半角转换为全角 ////转全角的函数(SBC case) ///任意字符串 ///全角空格为12288,半角空格为32 ...
- screen工具
1.背景 系统管理员经常需要SSH 或者telent 远程登录到Linux 服务器,经常运行一些需要很长时间才能完成的任务,比如系统备份.ftp 传输等等.通常情况下我们都是为每一个这样的任务开一个远 ...
- orcl 对table的一些操作
删除 table:drop table 表名: 恢复删除 : flashback table 表名 to before drop: 清空table : truncate table 表名; 恢复清空: ...
- 以太坊系列之十三: evm指令集
evm指令集手册 Opcodes 结果列为"-"表示没有运算结果(不会在栈上产生值),为"*"是特殊情况,其他都表示运算产生唯一值,并放在栈顶. mem[a.. ...
- linux chmod对文件权限的操作
在Unix和Linux的各种操作系统下,每个文件(文件夹也被看作是文件)都按读.写.运行设定权限. 例如我用ls -l命令列文件表时,得到如下输出: -rw-r--r-- 1 apple users ...
- 864. Shortest Path to Get All Keys
We are given a 2-dimensional grid. "." is an empty cell, "#" is a wall, "@& ...
- loj #2051. 「HNOI2016」序列
#2051. 「HNOI2016」序列 题目描述 给定长度为 n nn 的序列:a1,a2,⋯,an a_1, a_2, \cdots , a_na1,a2,⋯,an,记为 a[1: ...
- OpenStack-Mitaka
一.Cloud 基础概念 IAAS:Infrastructre As A Service 基础架构及服务,OpenStack,CloudStack PAAS:Platform As A Service ...