HashMap JDK1.8实现原理
HashMap概述
HashMap存储的是key-value的键值对,允许key为null,也允许value为null。HashMap内部为数组+链表的结构,会根据key的hashCode值来确定数组的索引(确认放在哪个桶里),如果遇到索引相同的key,桶的大小是2,如果一个key的hashCode是7,一个key的hashCode是3,那么他们就会被分到一个桶中(hash冲突),如果发生hash冲突,HashMap会将同一个桶中的数据以链表的形式存储,但是如果发生hash冲突的概率比较高,就会导致同一个桶中的链表长度过长,遍历效率降低,所以在JDK1.8中如果链表长度到达阀值(默认是8),就会将链表转换成红黑二叉树。
HashMap数据结构
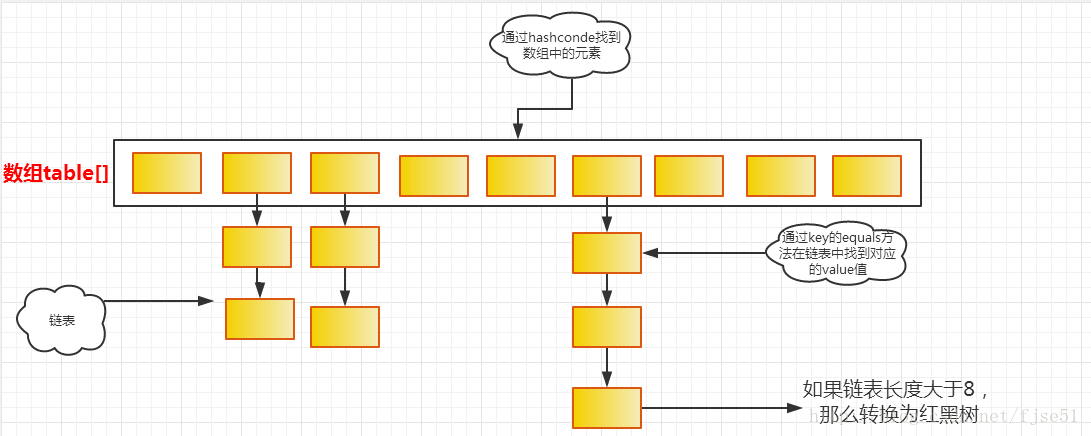
//Node本质上是一个Map.存储着key-value
static class Node<K,V> implements Map.Entry<K,V> {
final int hash; //保存该桶的hash值
final K key; //不可变的key
V value;
Node<K,V> next; //指向一个数据的指针
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
从源码上可以看到,Node实现了Map.Entry接口,本质上是一个映射(k-v)
刚刚也说过了,有时候两个key的hashCode可能会定位到一个桶中,这时就发生了hash冲突,如果HashMap的hash算法越散列,那么发生hash冲突的概率越低,如果数组越大,那么发生hash冲突的概率也会越低,但是数组越大带来的空间开销越多,但是遍历速度越快,这就要在空间和时间上进行权衡,这就要看看HashMap的扩容机制,在说扩容机制之前先看几个比较重要的字段
//默认桶16个
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 //默认桶最多有2^30个
static final int MAXIMUM_CAPACITY = 1 << 30; //默认负载因子是0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f; //能容纳最多key_value对的个数
int threshold; //一共key_value对个数
int size;
threshold=负载因子 * length,也就是说数组长度固定以后, 如果负载因子越大,所能容纳的元素个数越多,如果超过这个值就会进行扩容(默认是扩容为原来的2倍),0.75这个值是权衡过空间和时间得出的,建议大家不要随意修改,如果在一些特殊情况下,比如空间比较多,但要求速度比较快,这时候就可以把扩容因子调小以较少hash冲突的概率。相反就增大扩容因子(这个值可以大于1)。
size就是HashMap中键值对的总个数。还有一个字段是modCount,记录是发生内部结构变化的次数,如果put值,但是put的值是覆盖原有的值,这样是不算内部结构变化的。
因为HashMap扩容每次都是扩容为原来的2倍,所以length总是2的次方,这是非常规的设置,常规设置是把桶的大小设置为素数,因为素数发生hash冲突的概率要小于合数,比如HashTable的默认值设置为11,就是桶的大小为素数的应用(HashTable扩容后不能保证是素数)。HashMap采用这种设置是为了在取模和扩容的时候做出优化。
hashMap是通过key的hashCode的高16位和低16位异或后和桶的数量取模得到索引位置,即key.hashcode()^(hashcode>>>16)%length,当length是2^n时,h&(length-1)运算等价于h%length,而&操作比%效率更高。而采用高16位和低16位进行异或,也可以让所有的位数都参与越算,使得在length比较小的时候也可以做到尽量的散列。
在扩容的时候,如果length每次是2^n,那么重新计算出来的索引只有两种情况,一种是 old索引+16,另一种是索引不变,所以就不需要每次都重新计算索引。
确定哈希桶数据索引位置
//方法一:
static final int hash(Object key) { //jdk1.8 & jdk1.7
int h;
// h = key.hashCode() 为第一步 取hashCode值
// h ^ (h >>> 16) 为第二步 高位参与运算
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//方法二:
static int indexFor(int h, int length) { //jdk1.7的源码,jdk1.8没有这个方法,但是实现原理一样的
return h & (length-1); //第三步 取模运算
}
HashMap的put方法实现
思路如下:
1.table[]是否为空
2.判断table[i]处是否插入过值
3.判断链表长度是否大于8,如果大于就转换为红黑二叉树,并插入树中
4.判断key是否和原有key相同,如果相同就覆盖原有key的value,并返回原有value
5.如果key不相同,就插入一个key,记录结构变化一次
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
//判断table是否为空,如果是空的就创建一个table,并获取他的长度
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果计算出来的索引位置之前没有放过数据,就直接放入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
//进入这里说明索引位置已经放入过数据了
Node<K,V> e; K k;
//判断put的数据和之前的数据是否重复
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) //key的地址或key的equals()只要有一个相等就认为key重复了,就直接覆盖原来key的value
e = p;
//判断是否是红黑树,如果是红黑树就直接插入树中
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果不是红黑树,就遍历每个节点,判断链表长度是否大于8,如果大于就转换为红黑树
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//判断索引每个元素的key是否可要插入的key相同,如果相同就直接覆盖
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//如果e不是null,说明没有迭代到最后就跳出了循环,说明链表中有相同的key,因此只需要将value覆盖,并将oldValue返回即可
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
//说明没有key相同,因此要插入一个key-value,并记录内部结构变化次数
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
HashMap的get方法实现
实现思路:
1.判断表或key是否是null,如果是直接返回null
2.判断索引处第一个key与传入key是否相等,如果相等直接返回
3.如果不相等,判断链表是否是红黑二叉树,如果是,直接从树中取值
4.如果不是树,就遍历链表查找
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
//如果表不是空的,并且要查找索引处有值,就判断位于第一个的key是否是要查找的key
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
//如果是,就直接返回
return first;
//如果不是就判断链表是否是红黑二叉树,如果是,就从树中取值
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//如果不是树,就遍历链表
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
扩容机制
我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
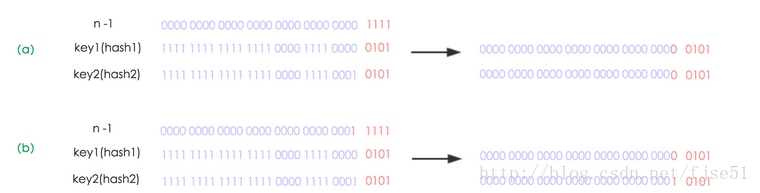
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
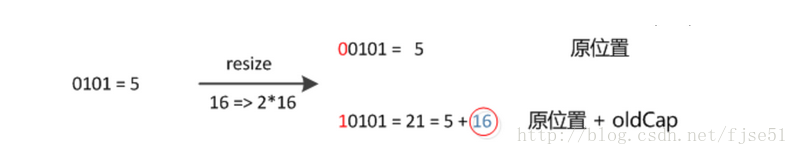
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图:

这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。
HashMap JDK1.8实现原理的更多相关文章
- HashMap底层实现及原理
注意:文章的内容基于JDK1.7进行分析.1.8做的改动文章末尾进行讲解. 一.先来熟悉一下我们常用的HashMap: 1.HashSet和HashMap概述 对于HashSst及其子类而 ...
- 详解HashMap的内部工作原理
本文将用一个简单的例子来解释下HashMap内部的工作原理.首先我们从一个例子开始,而不仅仅是从理论上,这样,有助于更好地理解,然后,我们来看下get和put到底是怎样工作的. 我们来看个非常简单的例 ...
- 关于HashMap put元素的原理
HashMap集合put元素的原理:(1)计算key的hashCode(2)将key的hashCode作为计算因子,通过哈希算法计算HashMap的数组下标index(3)如果index下标的数组元素 ...
- HashMap的底层实现原理
HashMap的底层实现原理1,属性static final int MAX_CAPACITY = 1 << 30;//1073741824(十进制)0100000000000000000 ...
- HashMap (JDK1.8) 分析
一.HashMap(JDK1.8) 1.基本知识.数据结构 (1)时间复杂度:用来衡量算法的运行时间. 参考:https://blog.csdn.net/qq_41523096/article/det ...
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- Java集合:HashMap底层实现和原理(源码解析)
Note:文章的内容基于JDK1.7进行分析.1.8做的改动文章末尾进行讲解. 一.先来熟悉一下我们常用的HashMap: 1.概述 HashMap基于Map接口实现,元素以键值对的方式存储,并且允许 ...
- HashMap底层结构、原理、扩容机制
https://www.jianshu.com/p/c1b616ff1130 http://youzhixueyuan.com/the-underlying-structure-and-princip ...
- HashMap内部结构及实现原理
简单介绍 在研究HashMap之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能 数组:采用一段连续的存储单元来存储数据.对于指定下标的查找,时间复杂度为O(1):通过给定值进行查找,需 ...
随机推荐
- 爬虫入门之jsonPath PhantomJS与 selenium详解(六)
1 jsonPath数据格式 pip安装: pip install jsonpath 用来解析json格式的字符串,类似于xpath (1) json对象的转换 json.loads() json.d ...
- Apache常见问题
Apache如何修改端口? 找到Apache安装目录,conf目录下的httpd.conf文件,用编辑器打开. 找到“Listen 80”,修改为我们想要的端口号就可以了,如“Listen 8080” ...
- 使用 webpack 各种插件提升你的开发效率
前沿 项目地址 vue-admin 欢迎 star 近几个月,接手了一个老项目的重构规划,有多老呢?就是前端青铜时代的项目,一个前后端都在同一个锅里的项目.完全没有使用任何的打包工具. 后台 php ...
- Twitter Typeahead plugin Example
原文网址: http://dhtmlexamples.com/2012/02/27/using-the-typeahead-plugin-with-twitter-bootstrap-2-and-jq ...
- 特殊权限的介绍 SGID SUID SBIT
Set UID 当s这个标志出现在文件所有者的x权限上时,如/usr/bin/passwd这个文件的权限状态:“-rwsr-xr-x.”,此时就被称为Set UID,简称为SUID.那么这个特殊权限的 ...
- Python语言程序设计基础(2)—— Python程序实例解析
温度转换 def tempConvert(ValueStr): if ValueStr[-1] in ['F','f']: ans = (eval(ValueStr[0:-1]) - 32)/1.8 ...
- 「SDOI2008沙拉公主的困惑」
题目 看着有点可怕 求 \[\sum_{i=1}^{n!}[(i,m!)=1]\] 考虑一下\(m=n\)的时候的答案 非常显然就是\(\varphi(m!)\) 而如果\(n>m\) 非常显然 ...
- 百度提供的LBS服务
并不是所有 LBS 云服务 都可以使用 js Ajax 访问,涉及跨域问题 (Jsonp 方式解决)Jsonp 解决跨域问题原理,在页面生成<script> 加载远程 js 代码片段.在L ...
- 去掉video视频播放器下的下载按钮
去掉video视频播放器下的下载按钮: video::-internal-media-controls-download-button { display:none; } video::-webkit ...
- 用keytool制作证书并在tomcat配置https服务(四)
用keytool制作证书并在tomcat配置https服务(一) 用keytool制作证书并在tomcat配置https服务(二) 用keytool制作证书并在tomcat配置https服务(三) 上 ...