Python爬虫基础(一)——HTTP
前言
因特网联系的是世界各地的计算机(通过电缆),万维网联系的是网上的各种各样资源(通过超文本链接),如静态的HTML文件,动态的软件程序······。由于万维网的存在,处于因特网中的每台计算机可以很方便地进行消息交流、文件资源交流······。基于因特网的帮助,我们可以在web客户端(如浏览器等)通过HTTP访问或者下载web服务端(如网站服务器)上面的web资源。
因特网由TCP/IP统筹,在TCP/IP的基础上进行HTTP活动。HTTP位于TCP/IP的应用层。了解HTTP是为了让爬虫程序模拟客户端的行为去请求服务器数据和反爬虫。
通过在开发者工具里查看分析网页客户端(浏览器)HTTP的请求报文,获得网页HTTP的请求URL、请求方法、请求头、cookie······,爬虫程序可以完备的模拟浏览器去爬取网站的资源;通过查看分析服务器(网站)返回的HTTP响应报文,了解响应状态,响应主体······,爬虫程序就可以根据这些响应内容去实现程序逻辑、处理响应内容、提取目标信息······
HTTP基础
相关术语
- Internet:因特网,一种把各个网络联系起来的网络,主要由许多计算机和电缆组成
- WWW(world wide web):万维网,一种抽象的信息空间
- web浏览器(web browser):可以显示网页服务器或者文件系统的HTML网页,并让用户与网页交互的软件。
- Web服务器(Web Server):是驻留于因特网上某种类型计算机的程序,可以向浏览器等Web客户端提供文档,也可以放置网站文件,让全世界浏览;可以放置数据文件,让全世界下载。一般指网站服务器,
- HTTP(HyperText Transfer Protocol):超文本传输(转移)协议,处于TCP/IP协议簇的应用层。
- URL(Uniform Resource Locator):统一资源定位符
- URI(Uniform Resource Identifier):统一资源标识符
- URN(Universal Resource Name):统一资源名称
- HTML(HyperText Markup Language):超文本标记语言
- TCP/IP(TCP/IP Protocol Suite):TCP/IP协议族,其中一种定义为互联网相关的各类协议族的总称
- TCP(Transmission Control Protocol):传输控制协议
- IP(Internet Protocol Address):网际协议地址
- cookie:一种用户识别机制,一种功能强大且高效的持久身份识别的技术
- DNS(Domain Name System):域名系统,提供域名到IP地址的解析服务,处于TCP/IP协议簇的应用层。
- IPv4(Internet Protocol Version 4):网际协议第四版,规定IP长度为32位
- IPv6(Internet Protocol Version 6):网际协议第六版,规定IP长度为128位
URL
通常我们说的网址就是一个URL,URL是URI的一个子集,URN也是URI的一个子集,URL和URN存在交集,大概率的情况都是URI=URL,关系如下:
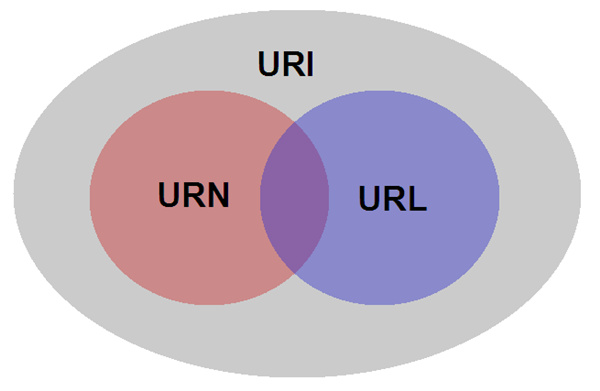
当我们在web客户端浏览器输入网址(URL)的时候,如果网址无误,通过HTTP就能得到web服务端的响应。URL语法如下:

- scheme:方案,访问web服务器时使用的协议类型,如http:或https:不区分大小写,最后加一个冒号:
- user:用户,访问服务器时指定用户登录,为可选项
- password:用户密码,和用户相连,可选
- host:主机,服务器地址,可以是DNS可解释的域名(人性化)或IPv4/IPv6地址
- port:端口号,指定服务器连接的端口号,即监听的端口号,若客户端省略则为默认端口,HTTP默认端口为80
- path:路径,指定服务器上的文件路径,定位资源。由一个斜杠/与前面的URL组件分隔开
- params:参数,指定输入参数,形式为键值对,用;将其与path的部分隔开。可选
- query:查询,为查询字符串,针对已选的路径内的资源,传入参数,用?将其与URL其他部分隔开。可选
- frag:片段,为片段标识符,通常标记出以获取的资源的子资源,通过#与URL其它部分隔开,不会传递到服务端,由客户端内部使用。可选
了解这些是有用的,其中的一个用途就是在爬虫中构建自己的URL请求参数。例如书上所说的如果要爬取作者新的浪微博,由于微博是是ajax的方式加载,需要在开发者工具才能看到ajax请求和服务器的响应,所以请求url需要在开发者工具里查找,经过查找分析,发现xhr(可以查看ajax的请求和响应信息)中的请求URL传入了4个参数(问号后面的即为查询传入的参数),前面三个是不变的,而变化的是最后一个,我们可以利用urllib模块中的urlencode模块来传递这些参数,链接如下:
https://m.weibo.cn/api/container/getIndex?type=uid&value=2830678474&containerid=1076032830678474&page=2
代码如下:
import requests
from urllib.parse import urlencode
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2830678474',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
} # 模拟请求头
def get_page(page):
params = {
'type': 'uid',
',
',
'page': page
}
url = base_url + urlencode(params)
response = requests.get(url, headers=headers)
return response.json() # 由于内容是由ajax加载,响应的内容是json的形式
if __name__ == '__main__':
for page in range(1,3):
result = get_page(page)
print(result)
再如要要抓取今日头条一些街拍的图片,在搜索框输入“街拍”二字之后回车便进入到街拍页面,看下网页的url是:https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D,但是直接拿这个去爬取图片是不成功的,因为这些数据是ajax加载,不存在网页源代码文件中,为之奈何?和前面的处理方法一样啊,其中可变参数是offset,这是构造的关键,其中链接的形式如下:
https://www.toutiao.com/search_content/?offset=20&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&curtab=1&from=search_tab
代码如下:
import requests
from urllib.parse import urlencode
def get_page(offset):
headers = {
'User-Agent': "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0;"
" .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
}
params = {
'offset': offset,
'format': 'json',
'keyword': '街拍',
'autoload': 'true',
',
',
'from': 'search_tab',
}
base_url = 'https://www.toutiao.com/search_content/?'
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
print(response.status_code)
return response.json()
except requests.ConnectionError:
return None
if __name__ == '__main__':
for offset in range(20, 60, 20):
result = get_page(offset)
print(result)
HTTP方法
GET方法和POST方法是HTTP中最常用的方法。它们能够访问和下载和访问网站服务器资源,这些网页就是我们要爬取并摘取数据的资源,爬虫程序模拟了浏览器实现这种HTTP的GET或者POST等方法去获取资源。
GET方法
GET 方法用来请求访问已被 URI 识别的资源。指定的资源经服务器端解析后返回响应内容。也就是说,如果请求的资源是文本,那就保持原样返回;如果是像 CGI(Common Gateway Interface,通用网关接口)那样的程序,则返回经过执行后的输出结果。如图:

POST方法
POST 方法用来传输实体的主体。
虽然用 GET 方法也可以传输实体的主体,但一般不用 GET 方法进行传输,而是用 POST 方法。虽说 POST 的功能与 GET很相似,但POST 的主要目的并不是获取响应的主体内容。如图:

HTTP报文
HTTP报文是指客户端和服务器用于HTTP交互的的信息,客户端的HTTP报文称为请求报文,服务器端的报文称为响应报文。需要爬虫某网页的时候,我们可以在开发者工具里面查找并分析这些报文以了解客户端的HTTP请求及URL等,从而模拟客户端去进行数据爬取。
HTTP报文大致可以分为报文首部和主体,两者由最初出现的空行(CR+LF)来划分,如图:

请求首部和请求实例
请求首部由请求行(HTTP请求方法、URL、HTTP协议版本)和首部字段(请求首部字段、通用首部字段、实体首部字段)及其他内容组成,以下是请求头部结构和请求实例,其中请求头User-Agent是爬虫在模拟HTTP方法请求网页资源时常常需要添加的一个参数。
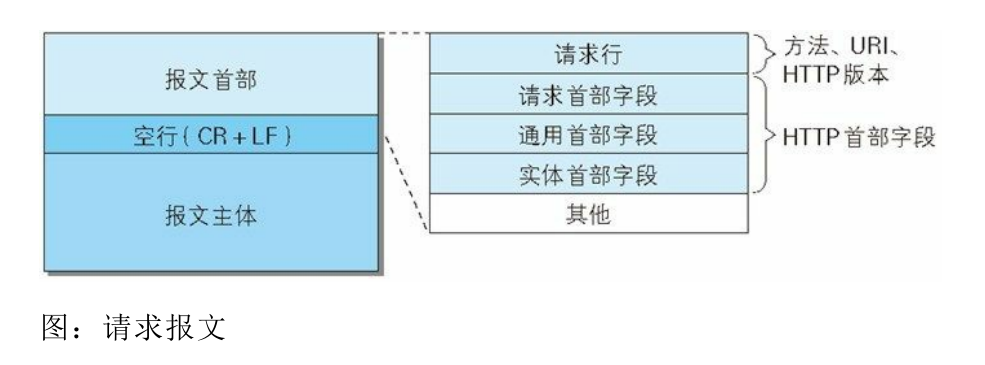
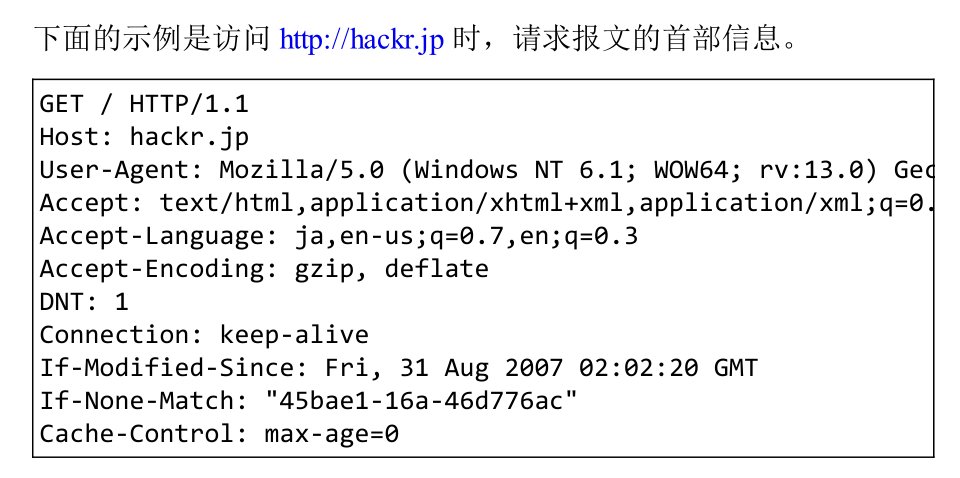
响应首部和响应实例
响应首部则由状态行(HTTP协议版本、响应状态码(数字和原因短语))和HTTP首部字段(响应首部字段、通用首部字段、实体首部字段)组成,以下分别是响应头部结构和响应实例
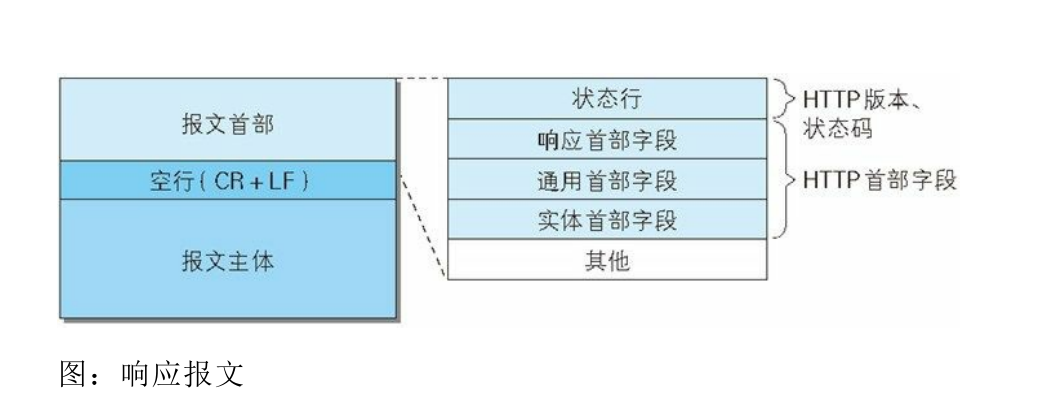
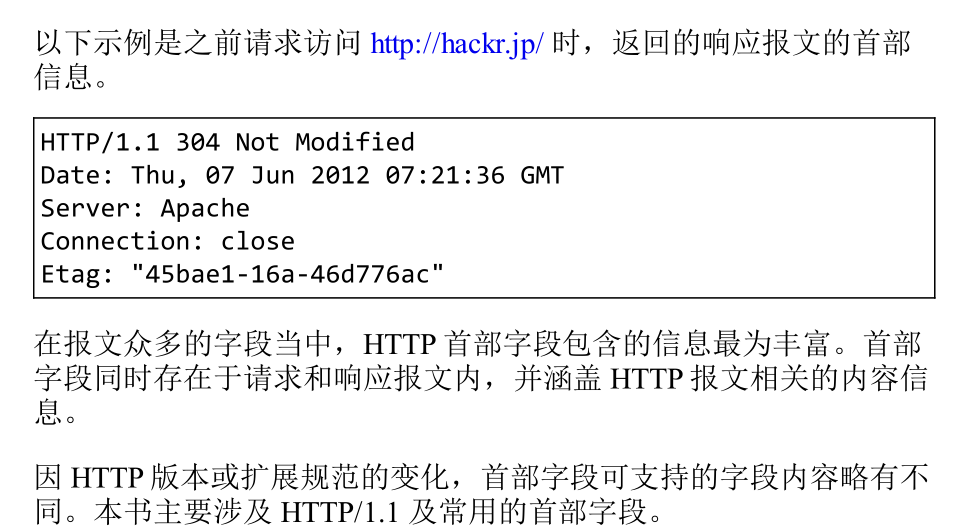
通用首部字段
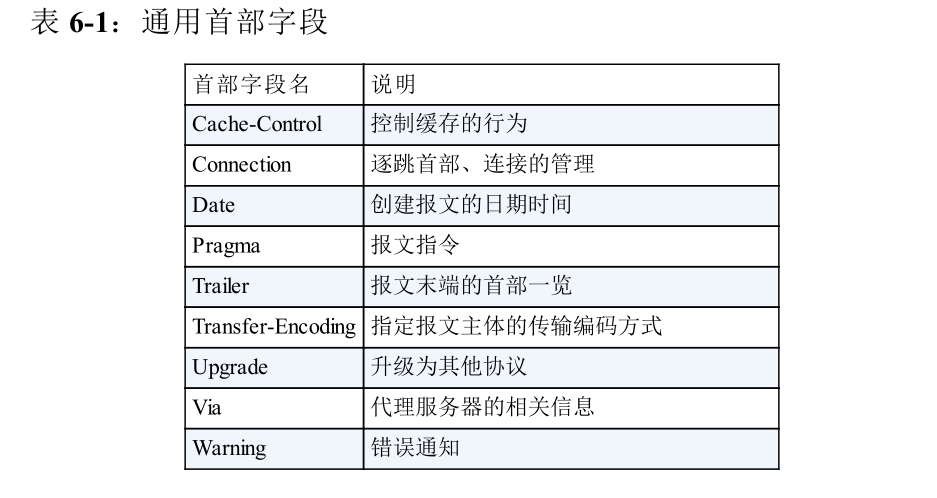
请求首部字段
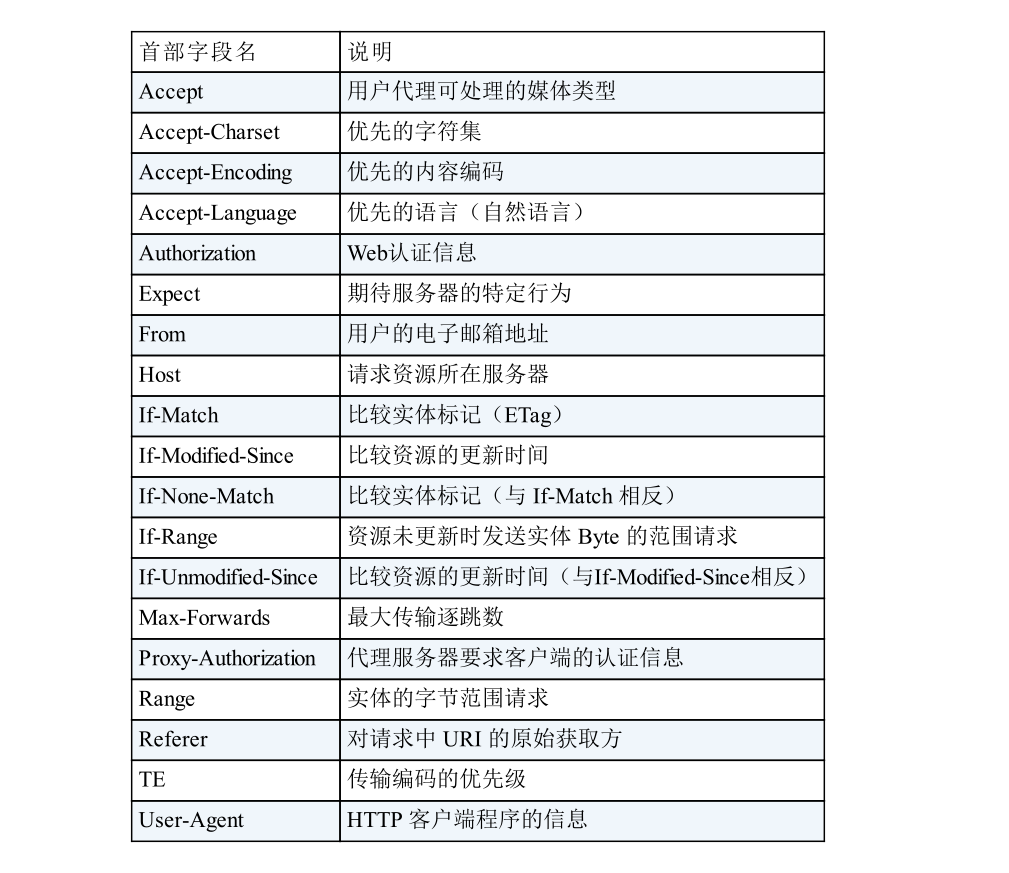
- 响应首部字段
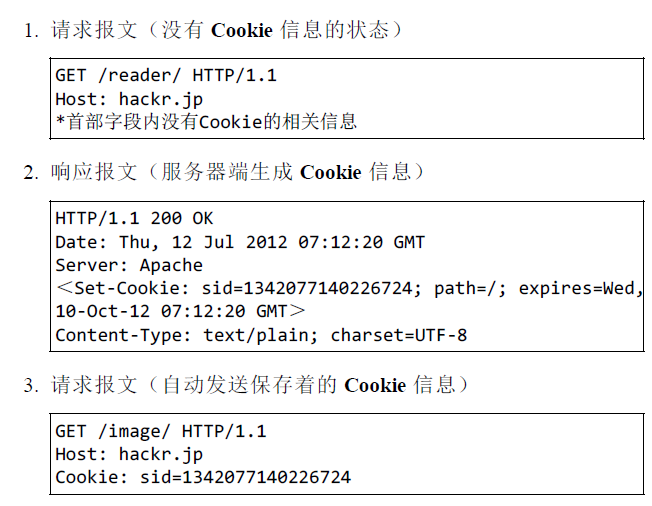
Cookie
HTTP 是无状态协议,它不对之前发生过的请求和响应的状态进行管理。也就是说,无法根据之前的状态进行本次的请求处理。为解决此矛盾,Cookie技术通过在请求和响应报文中写入Cookie信息来控制客户端的状态。Cookie会根据从服务端发送过来的报文内的一个叫Set-Cookie的首部字段信息,通知客户端保存cookie。当下次客户端再向此服务器发送请求时,客户端会自动在请求报文加入值后再发过去给服务端。服务端接收到客户端发送过来的cookie之后,会检查这个cookie究竟是从哪一个客户端发送过来,然后对比之前的服务记录,最后得到之前的状态信息。爬虫中也会模拟这种带cookie的HTTP请求来实现反爬虫或使得抓取的数据更全面等,如图
TCP/IP 的分层管理
因特网由TCP/IP统筹,所以万维网间接由它统筹。由于HTTP位于TCP/IP协议簇的应用层,了解TCP/IP协议簇有助于我们更加了解HTTP。CP/IP协议族里重要的一点就是分层,分层的好处在于,当互联网需要改动时,分层之后只需把变动对应的层替换掉即可,设计也变得相对简单。TCP/IP协议族按层次分别分为以下4层:应用层、传输层、网络层和数据链路层。如图:
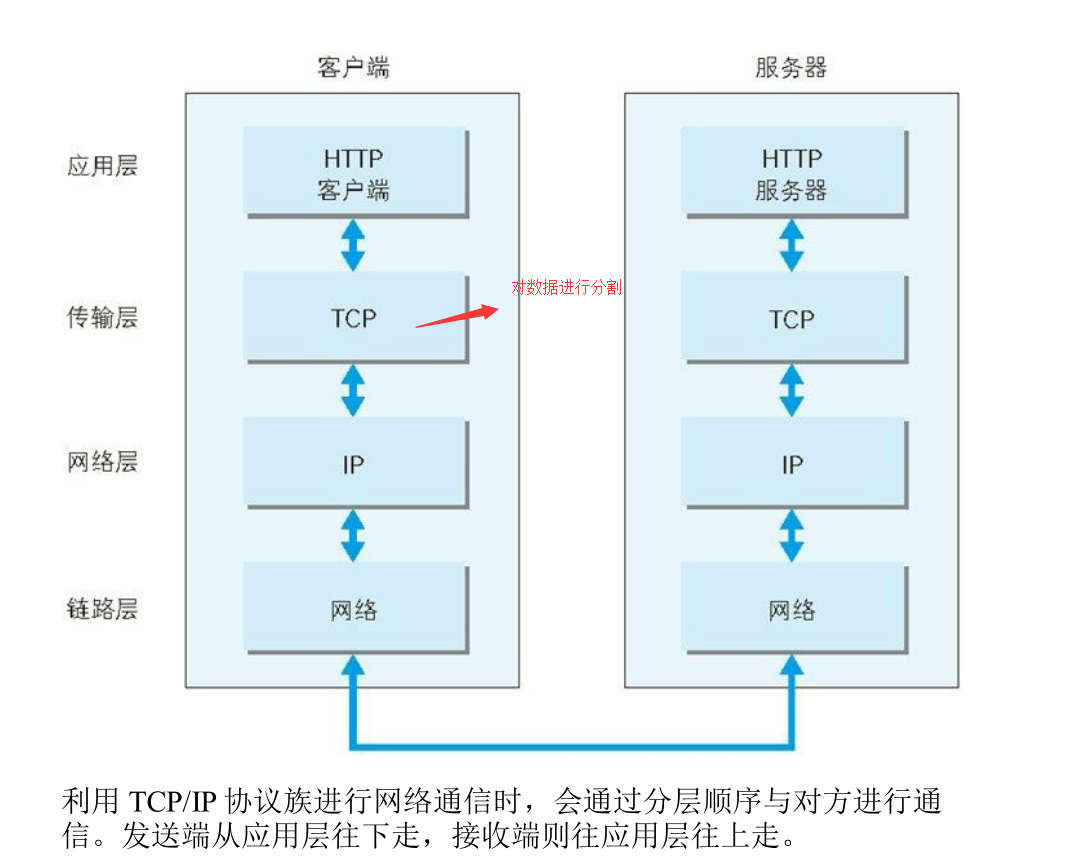
- 应用层:应用层决定了向用户提供应用服务时通信的活动。
TCP/IP协议族内预存了各类通用的应用服务。比如FTP(FileTransfer Protocol,文件传输协和DNS(Domain Name System,域名系统)服务就是其中两类。HTTP协议也处于该层。
- 传输层:传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。
在传输层有两个性质不同的协议:TCP(Transmission ControlProtocol,传输控制协议)和UDP(User Data Protocol,用户数据报协议)。
- 网络层(又名网络互连层):
网络层用来处理在网络上流动的数据包。数据包是网络传输的最小数据单位。该层规定了通过怎样的路径(所谓的传输路线)到达对方计算机,并把数据包传送给对方。与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所起的作用就是在众多的选项内选择一条传输路线。
- 链路层(又名数据链路层,网络接口层):
用来处理连接网络的硬件部分。包括控制操作系统、硬件的设备驱动、NIC(Network Interface Card,网络适配器,即网卡),及光纤等物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在链路层的作用范围之内。
利用 TCP/IP 协议族进行网络通信时,会通过分层顺序与对方进行通信。发送端从应用层往下走,接收端则往应用层往上走。如图:
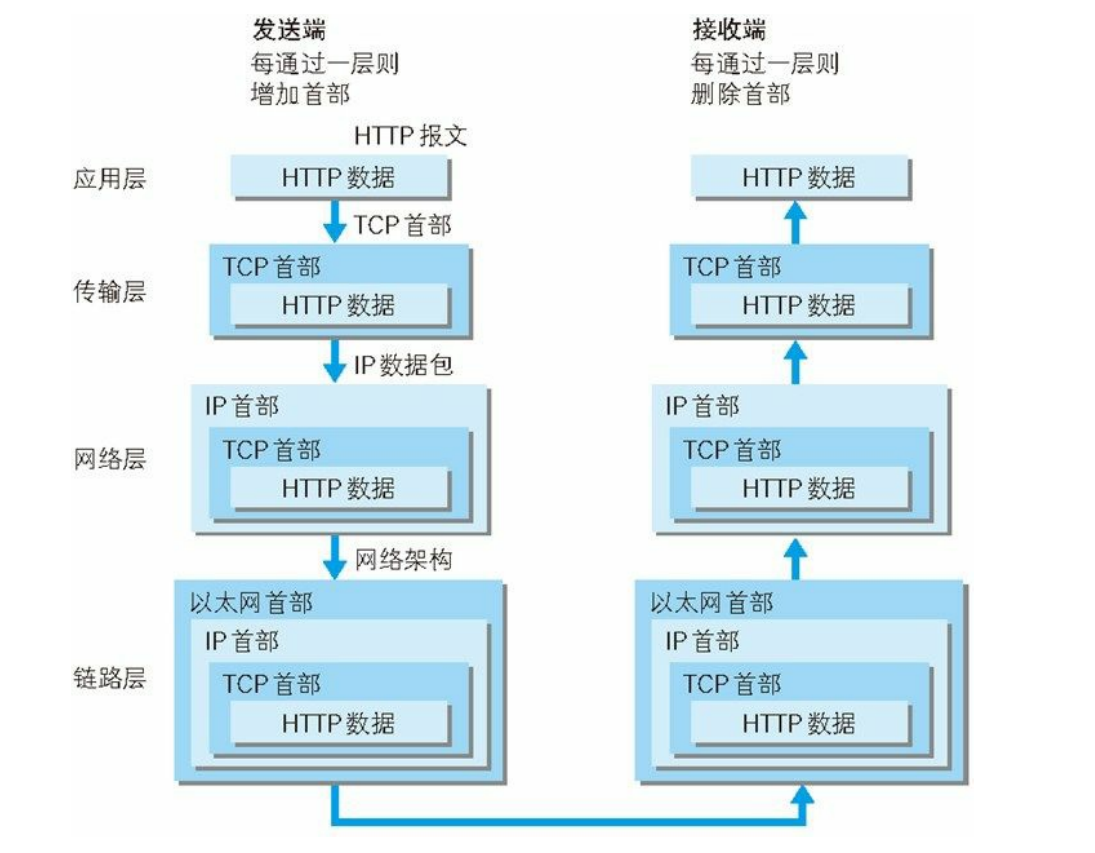
首先,客户端在应用层(HTTP协议)发出一个想看某个网页的HTTP请求,接着为了传输方便,传输层(TCP协议)把从应用层接受到的数据(请求报文)进行分割,并在各个报文上打上标记序号和端口号发送给网络层,在网络层(IP协议),增加作为通信目的地的MAC地址发送给链路层,至此,发往服务器的通信请求就准备齐全了
接着服务端在链路层接收到客户端发来的请求,然后按序一直往上发送到应用层,当请求传到应用层服务端才算真正接收到客户端发送过来的HTTP请求。发送端在层与层之间传输数据时,每经过一层时必定会被打上一个该层所属的首部信息。反之,接收端在层与层传输数据时,每经过一层时会把对应的首部消去。这种把数据信息包装起来的做法称为封装(encapsulate)
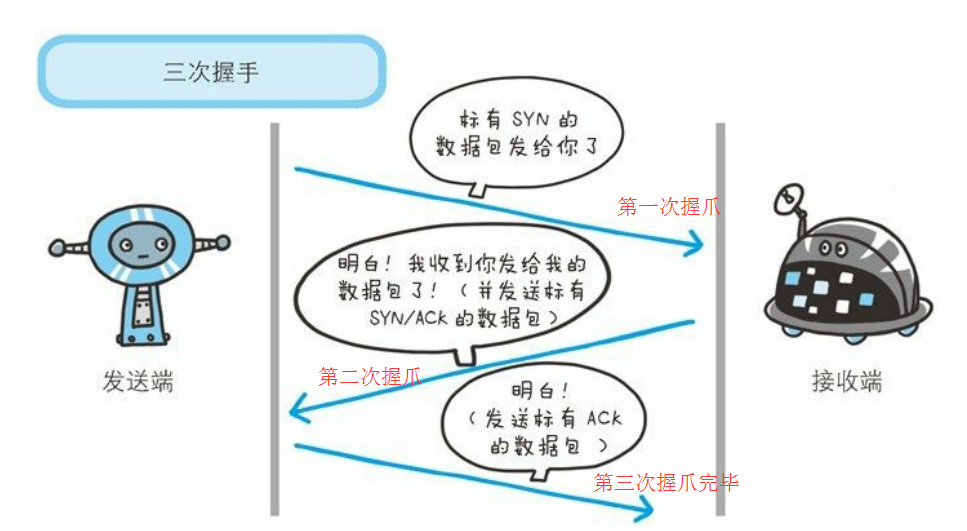
TCP三次握手
TCP处于HTTP协议的传输层,三次握手的目的在于保证请求信息的有效性,防止失效的连接请求报文段被服务端接收,从而产生错误。关于三次握手网上很多有趣的解释
参考
本文叙述的是一些与Python爬虫相关的HTTP内容,主要参考自《HTTP权威指南》、《图解HTTP》和《Python3网络爬虫开发实战》,仅仅是个人理解,望指正。
Python爬虫基础(一)——HTTP的更多相关文章
- Python爬虫基础
前言 Python非常适合用来开发网页爬虫,理由如下: 1.抓取网页本身的接口 相比与其他静态编程语言,如java,c#,c++,python抓取网页文档的接口更简洁:相比其他动态脚本语言,如perl ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
- python爬虫-基础入门-爬取整个网站《3》
python爬虫-基础入门-爬取整个网站<3> 描述: 前两章粗略的讲述了python2.python3爬取整个网站,这章节简单的记录一下python2.python3的区别 python ...
- python爬虫-基础入门-爬取整个网站《2》
python爬虫-基础入门-爬取整个网站<2> 描述: 开场白已在<python爬虫-基础入门-爬取整个网站<1>>中描述过了,这里不在描述,只附上 python3 ...
- python爬虫-基础入门-爬取整个网站《1》
python爬虫-基础入门-爬取整个网站<1> 描述: 使用环境:python2.7.15 ,开发工具:pycharm,现爬取一个网站页面(http://www.baidu.com)所有数 ...
- Python爬虫基础之认识爬虫
一.前言 爬虫Spider什么的,老早就听别人说过,感觉挺高大上的东西,爬网页,爬链接~~~dos黑屏的数据刷刷刷不断地往上冒,看着就爽,漂亮的校花照片,音乐网站的歌曲,笑话.段子应有尽有,全部都过来 ...
- python 爬虫基础知识一
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 网络爬虫必备知识点 1. Python基础知识2. P ...
- 【学习笔记】第二章 python安全编程基础---python爬虫基础(urllib)
一.爬虫基础 1.爬虫概念 网络爬虫(又称为网页蜘蛛),是一种按照一定的规则,自动地抓取万维网信息的程序或脚本.用爬虫最大的好出是批量且自动化得获取和处理信息.对于宏观或微观的情况都可以多一个侧面去了 ...
- python爬虫基础要学什么,有哪些适合新手的书籍与教程?
一,爬虫基础: 首先我们应该了解爬虫是个什么东西,而不是直接去学习带有代码的内容,新手小白应该花一个小时去了解爬虫是什么,再去学习带有代码的知识,这样所带来的收获是一定比你直接去学习代码内容要多很多很 ...
随机推荐
- C# winform 跨线程修改界面
我们可以使用invoke和bengininvoke invoke同步执行一个委托 begininvoke异步执行一个委托
- javascript typeof()的用法与运算符用法
typeof 运算符 返回一个用来表示表达式的数据类型的字符串. typeof[()expression[]] ; expression 参数是需要查找类型信息的任意表达式. 说明 typeof 运算 ...
- SQL-MySQL使用教程-对MySQL的初步尝试
出现问题:中文无法显示.存储:不对任何数据做检测,只管理数据类型.
- PS软件怎么把视频转成gif动态图?
PS软件怎么把视频转成gif动态图?Adobe PhotoShop软件的最新版本是可以编辑视频的,并且可以将视频转换为GIF动态图,使用也很简单,下面分享ps制作gif动态图的教程,需要的朋友可以参考 ...
- Jerry的ABAP原创技术文章合集
我之前发过三篇和ABAP相关的文章: 1. Jerry的ABAP, Java和JavaScript乱炖 这篇文章包含我多年来在SAP成都研究院使用ABAP, Java和JavaScript工作过程中的 ...
- typescript import需要注意的地方以及一点疑问
在使用 import {XXX} from './xxx'的时候,到浏览器上会报错,提示找不到xxx文件,原因在于没有加入后缀,这时候要写成import {XXX} from './xxx.js'注意 ...
- 创建maven项目后缺少jar包下载失败等问题
transfer.......fail.........等问题 The container 'Maven Dependencies' references non existing library ' ...
- [USACO12FEB]牛券Cow Coupons
嘟嘟嘟 这其实是一道贪心题,而不是dp. 首先我们贪心的取有优惠券中价值最小的,并把这些东西都放在优先队列里,然后看[k + 1, n]中,有些东西使用了优惠券减的价钱是否比[1, k]中用了优惠券的 ...
- 行云管家V4.9正式发布:监控全面提升,首页、主机详情大幅优化,新增大量实用功能.md
让大家久等啦!4.9版本中我们对监控模块进行了重构,在数据准确性与稳定性方面做了大幅提升.我们也对首页及主机详情页面做了大幅重构,以追求为您提供极致的用户体验.同时我们在新版本中增加了如:运维报表.用 ...
- 【转】iOS保持界面流畅的技巧
原文链接:iOS保持界面流畅的技巧 这篇文章会非常详细的分析 iOS 界面构建中的各种性能问题以及对应的解决思路,同时给出一个开源的微博列表实现,通过实际的代码展示如何构建流畅的交互. Index演示 ...