分布式服务框架 Zookeeper(二)官方介绍
ZooKeeper:为分布式应用而生的分布式协调服务
ZooKeeper是一个为分布式应用而设计的分布式的、开源的协调服务。它提供了一套简单的原语,分布式应用利用这套原语可以实现更高层的服务,比如一致性,配置维护,分组以及命名。它被设计为易于编程,并且采用了一套和文件系统的树形结构相似的数据模型。它在Java虚拟机上运行,并且同时绑定了Java和C。
协调服务是出了名的难以获取。在竞态条件以及死锁的时候尤其容易出错。推动ZooKeeper发展的动力是为了使分布式应用不用承受从底层开始构建协调服务的痛苦过程。
设计目标
ZooKeeper是简洁的。ZooKeeper允许分布式进程通过一个类似于标准文件系统的共享分层命名空间来彼此协调。命名空间包括数据注册——在ZooKeeper的术语中被称为znodes——它们就像是文件和目录一样。和标准的文件系统为了存储数据不一样的是,ZooKeeper的数据是存储在内存中的,这意味ZooKeeper能获得更高的吞吐量以及更低的延迟。
ZooKeeper的实现注重于高性能,高可用,严格的顺序访问。ZooKeeper的高性能使得它可以用于大型分布式系统中。高可靠性使得它免于单点失效的危险。严格的顺序意味着在客户端上可以实现复杂的一致性原语。
ZooKeeper是备份的(replicated)。就像它所协调的分布式进程一样,ZooKeeper本身就是在多个主机上部署的,就像是合奏一样。
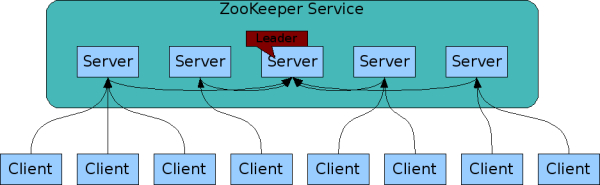
ZooKeeper服务
ZooKeeper是有序的。ZooKeeper给每次更新都会打一个戳,这个戳反映了ZooKeeper所有事物的顺序。后续的操作可以用这个顺序来实现更高层的抽象,比如一致性原语。
ZooKeeper是高速的。它在”以读为主“的负载中尤其快。ZooKeeper应用可以在数千台机器上运行,它在读比写更频繁的场景(读写比例大概是10:1)中性能是最好的。
数据模型和分层命名空间
ZooKeeper提供的命名空间就像是标准的文件系统一样。一个名字是以斜线(/)分隔的路径序列。在ZooKeeper命名空间中的每个节点都通过一个路径标识。
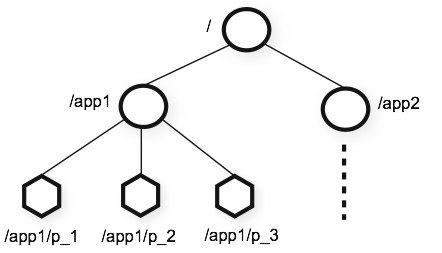
ZooKeeper的分层命名空间
节点和临时节点
和标准的文件系统不一样的是,在ZooKeeper命名空间中的每个节点有和它相关的数据和子节点。就像是允许文件系统中的可以同时是目录。(ZooKeeper被设计用于存储协调数据:状态信息,配置,本地信息等,因此每个节点中存储的数据通常都很小,范围在byte到kb之间。)我们用术语znode来表明我们谈论的是ZooKeeper中的数据节点。
znode中维护了一个包含数据改变,ACL改变以及时间戳的版本号的统计结构,并将其用于缓存验证以及协调更新。每次znode中的数据改变时,版本号就会增加。例如,在客户端取回数据的同时也会数据的版本信息。
命名空间中的每个znode上存储的数据都是以原子的方式读和写的。读操作获取和一个znode相关的所有数据,而写操作则会替换掉所有的数据。每个节点都有一个权限控制列表(ACL)来限制每个人可以做些什么。
ZooKeeper也有所谓的临时节点。这些节点只有在创建这些节点存在的时候才会存活。当会话结束的时候,这些节点就会被删除。临时节点在你想实现【tbd】的时候非常有用。
条件更新和监视
ZooKeeper支持监视的概念。客户端可以在一个znode上设置一个监视。当znode发生改变时,监视会被触发和移除。当监视触发的时候客户端会接收一个数据包表明znode已经发生变化了。并且如果在客户端和某个ZooKeeper服务器断开连接的时候,客户端将会接收到一个本地通知。这些特性可以用于【tbd】。
保障
ZooKeeper非常快速和简洁。由于它的目标是用于构建更加复杂的服务,例如一致性,所以他提供了一套保障。分别是:
序列化一致性:客户端发送的更新操作将会以发送顺序来执行。
原子性:更新要么成功,要么失败,没有多余的结果。
单一系统镜像:一个客户端将会看到同一的服务试图,不管它连接的是哪个服务器。
可靠性:一旦更新被执行,之后会持久保存下来直到有新的客户端发送新的覆盖更新。
及时性:系统的客户端视图在一定的时间范围内可以保证达到最新状态。
简单的API
ZooKeeper的设计目标之一就是提供简单的编程接口。因此,它仅仅提供如下的操作:
create:在树的某个位置创建一个节点
delete:删除一个节点
exists:测试在某个位置是否有一个节点
get data:读取一个节点上的数据
set data:向一个节点写入数据
get children:获取一个节点的子节点列表
sync:等待数据的传播
想要更加深入的讨论以及它们如何用于实现更高层的操作请参考【tbd】。
实现
ZooKeeper组件展示了ZooKeeper的高层组件。除了请求处理器,每个服务器都可以通过复制每个组件本身来构建。(马丹,就是请求处理器只能有一个,其他的组件都可以有多份。)
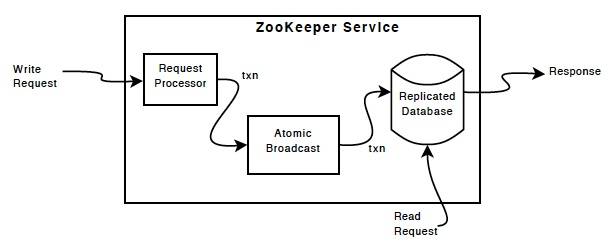
ZooKeeper组件
复制的数据库是一个包含了整个数据树的内存数据库。为了可恢复性,更新操作都会被记录到磁盘中,并且写操作在应用于内存数据库之前会先序列化到磁盘中。
每个ZooKeeper服务器都可以为客户端提供服务。客户端只会和一个服务器连接来提交请求。读请求可以从每个服务器的数据库中本地备份提供。更改服务状态的请求,比如写请求,会通过一个agreement协议来执行。
agreement协议规定所有的客户端发出写请求都会发送到一个单个服务器中,这个服务器称之为leader。剩下的服务器被称之为followers,follower会从leader那儿接受消息处理并同意消息发送。消息层会小心地替换失效的leader以及通过leader来同步所有的followers。
ZooKeeper使用私有的原子消息协议。由于消息层是原子的,ZooKeeper可以保证本地的备份不会出现分歧。当leader接收到了一个写请求,它会计算出当写操作执行之后系统的状态是什么,并且转移到补货新状态的事务中。
使用
ZooKeeper的编程接口故意设计的很简单。但是有了它之后,你可以实现更高阶的操作,比如一致性原语,分组关系,所有关系等。
性能和可靠性
树新风的我就不写了。
ZooKeeper项目
ZooKeeper已经成功应用于多个企业级项目。它在最开被用于Yahoo!的Yahoo! Message Broker的协调以及故障恢复中,Yahoo! Message Broker是一个高度可伸缩的发布-订阅系统,管理着数以千计的topics的备份和数据发送。它被用于Yahoo!爬虫的Fetching Service中,管理失效的恢复。有很多Yahoo!的广告系统同样使用ZooKeeper来实现可靠的服务。
notoriously 出了名的,臭名昭著的
prone
parlance
puts a premium on
ephemeral
diverge
deliberately
分布式服务框架 Zookeeper(二)官方介绍的更多相关文章
- 分布式服务框架 Zookeeper — 管理分布式环境中的数据
本节本来是要介绍ZooKeeper的实现原理,但是ZooKeeper的原理比较复杂,它涉及到了paxos算法.Zab协议.通信协议等相关知识,理解起来比较抽象所以还需要借助一些应用场景,来帮我们理解. ...
- 分布式服务框架 Zookeeper(转)
分布式服务框架 Zookeeper -- 管理分布式环境中的数据 Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题 ...
- 大数据 --> 分布式服务框架Zookeeper
分布式服务框架 Zookeeper Zookeeper系列 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
- 分布式服务框架 Zookeeper(一)介绍
一.概述 ZooKeeper(动物园管理员),顾名思义,是用来管理Hadoop(大象).Hive(蜜蜂).Pig(小猪)的管理员,同时Apache Hbase.Apache Solr.LinkedIn ...
- 分布式服务框架Zookeeper
协议介绍 zookeeper协议分为两种模式 崩溃恢复模式和消息广播模式 崩溃恢复协议是在集群中所选举的leader 宕机或者关闭 等现象出现 follower重新进行选举出新的leader 同时集群 ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据
转自:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/index.html Zookeeper 分布式服务框架是 Apa ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据(转载)
本文转载自:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ Zookeeper 分布式服务框架是 Apache Had ...
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据--转载
原文:http://www.ibm.com/developerworks/cn/opensource/os-cn-zookeeper/ Zookeeper 分布式服务框架是 Apache Hadoop ...
- 【Zookeeper】分布式服务框架 Zookeeper -- 管理分布式环境中的数据
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理 ...
- 【转】分布式服务框架 Zookeeper -- 管理分布式环境中的数据
Zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务.状态同步服务.集群管理.分布式应用配置项的管理 ...
随机推荐
- 【MySQL笔记】Excel数据导入Mysql数据库的实现方法——Navicat
很多公司尤其有点年头的公司,财务业务部门的各种表单都是excel来做的表格,随着互联网的发展各种业务流程都电子化流程化了,再在茫茫多的文档中去查找某一个年份月份的报告是件相当枯燥的事,所以都在想办法将 ...
- JNI概述
JNI是Java Native Interface的缩写,它提供了若干的API实现了Java和其他语言的通信(主要是C&C++). JNI 让你在利用强大 Java 平台的同时,使你仍然可以用 ...
- spark 持久化机制
spark的持久化机制做的相对隐晦一些,没有一个显示的调用入口. 首先通过rdd.persist(newLevel: StorageLevel)对此rdd的StorageLevel进行赋值,同chec ...
- 位图(BitMap)索引
前段时间听同事分享,偶尔讲起Oracle数据库的位图索引,顿时大感兴趣.说来惭愧,在这之前对位图索引一无所知,因此趁此机会写篇博文介绍下位图索引. 1. 案例 有张表名为table的表,由三列组成,分 ...
- Android性能调优篇之探索JVM内存分配
开篇废话 今天我们一起来学习JVM的内存分配,主要目的是为我们Android内存优化打下基础. 一直在想以什么样的方式来呈现这个知识点才能让我们易于理解,最终决定使用方法为:图解+源代码分析. 欢迎访 ...
- 面试题:判断两个字符串是否互为回环变位(Circular Rotaion)
题干: 如果字符串 s 中的字符循环移动任意位置之后能够得到另一个字符串 t,那么 s 就被称为 t 的回环变位(circular rotation). 例如,ACTGACG 就是 TGACG ...
- http://www.oschina.net/code/snippet_12_13918
http://www.oschina.net/code/snippet_12_13918
- springMVC中Restful支持
RESTFul支持 http://localhost:8090/user/doAdd.action?username=tony&age=8 http://localhost:8090/user ...
- Android Studio NDK 新手教程(5)--Java对象的传递与改动
概述 本文主要Java与C++之间的对象传递与取值.包括传递Java对象.返回Java对象.改动Java对象.以及性能对照. 通过JNIEnv完毕数据转换 Java对象是存在于JVM虚拟机中的,而C+ ...
- win下写任务提交给集群
一,复制和删除hdfs中的文件 import org.apache.hadoop.fs.{FileSystem, Path} import org.apache.spark.{SparkConf, S ...