C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)
写在前面的话:
在第一学期做项目的时候用到过相应的知识,觉得挺有趣的,就记录整理了下来,基于C/C++语言
原贴地址:https://helloacm.com/cc-linear-regression-tutorial-using-gradient-descent/
---------------------------------------------------------------前言----------------------------------------------------------------------------------
在机器学习和数据挖掘处理等领域,梯度下降(Gradient Descent)是一种线性的、简单却比较有效的预测算法。它可以基于大量已知数据进行预测, 并可以通过控制误差率来确定误差范围。
--------------------------------------------------------准备------------------------------------------------------------------------
Gradient Descent
回到主题,线性回归算法有很多,但Gradient Descent是最简单的方法之一。对于线性回归,先假设数据满足线性关系,例如:
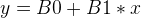
所以,作为线性回归,我们的任务就是找到最合适 B0 和 B1, 使最后的结果Y满足可接受的准确度。作为起步,首先让我们对B0和B1赋值初始值0,如下所示:
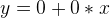
设误差 Error 为 e, 并引入下面几个点做例子:
x y
如果我们计算第一个点的误差,则得到 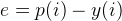 ,其中P(i)为表中的数据值,则 e 结果为 -1。但这只是开始,下面我们可以使用Gradient Descent来更新Y中的系数。这就涉及到数据 / 机器学习, 所谓的 数据 / 机器学习,其实可以大致理解为在相应的函数模型下,通过不停地更新其中系数,使新函数曲线可以拟合原始数据并预测走势的过程。
,其中P(i)为表中的数据值,则 e 结果为 -1。但这只是开始,下面我们可以使用Gradient Descent来更新Y中的系数。这就涉及到数据 / 机器学习, 所谓的 数据 / 机器学习,其实可以大致理解为在相应的函数模型下,通过不停地更新其中系数,使新函数曲线可以拟合原始数据并预测走势的过程。
回到主题,设刚才的初始状态为 t ,那么对于下一个状态 t+1 , B0可表示为 :
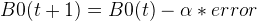
其中 B0(t + 1)是系数的更新版本,为套入下一个点做准备。∂ 是学习率,即为精度,这个我们可以自己设定。∂ 越大,说明每次学习的跨度就越大,预测结果在相应的正确答案两边的摆幅也就越大,所以此情况下学习次数不易过多,否则越摆越离谱。Ps:有次因为∂ 值太大的原因导致结果不精准,结过以为是学习次数不够多,后来等到把2.3的数值摆到10个亿才反应过来是∂出来问题。话说10个亿真是个小目标呢。
言归正传,这里取 ∂ = 0.01,即可得以下式子,B0=0.01.
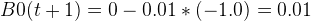 .
.
现在再来看 B1,在 t+1时刻,公式变为:
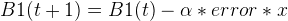
同样赋值,也同样得到:
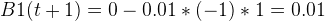
--------------------------------------------------------操作------------------------------------------------------------------------
现在,我们可以重复迭代这种过程到下一个点,再到下下个点,一直到所有点结束,这称为1回(an epoch)。但是我们可以通过反复不停地迭代,来使得到的线性拟合曲线更接近初始数据。比如迭代4回,每回5个点,也就是20次。C / C ++代码如下:
double x[] = {, , , , };
double y[] = {, , , , };
double b0 = ;
double b1 = ;
double alpha = 0.01;
for (int i = ; i < ; i ++) {
int idx = i % ; //5个点
double p = b0 + b1 * x[idx];
double err = p - y[idx];
b0 = b0 - alpha * err;
b1 = b1 - alpha * err * x[idx];
}
把B0、B1还有 误差(Error)的结果打印出来:
B0 = 0.01, B1 = 0.01, err = -
B0 = 0.0397, B1 = 0.0694, err = -2.97
B0 = 0.066527, B1 = 0.176708, err = -2.6827
B0 = 0.0805605, B1 = 0.218808, err = -1.40335
B0 = 0.118814, B1 = 0.410078, err = -3.8254
B0 = 0.123526, B1 = 0.414789, err = -0.471107
B0 = 0.143994, B1 = 0.455727, err = -2.0469
B0 = 0.154325, B1 = 0.497051, err = -1.0331
B0 = 0.157871, B1 = 0.507687, err = -0.354521
B0 = 0.180908, B1 = 0.622872, err = -2.3037
B0 = 0.18287, B1 = 0.624834, err = -0.196221
B0 = 0.198544, B1 = 0.656183, err = -1.56746
B0 = 0.200312, B1 = 0.663252, err = -0.176723
B0 = 0.198411, B1 = 0.65755, err = 0.190068
B0 = 0.213549, B1 = 0.733242, err = -1.51384
B0 = 0.214081, B1 = 0.733774, err = -0.0532087
B0 = 0.227265, B1 = 0.760141, err = -1.31837
B0 = 0.224587, B1 = 0.749428, err = 0.267831
B0 = 0.219858, B1 = 0.735242, err = 0.472871
B0 = 0.230897, B1 = 0.790439, err = -1.10393
怎么样,能发现什么?不容易看出来没关系,我们把点画下来:
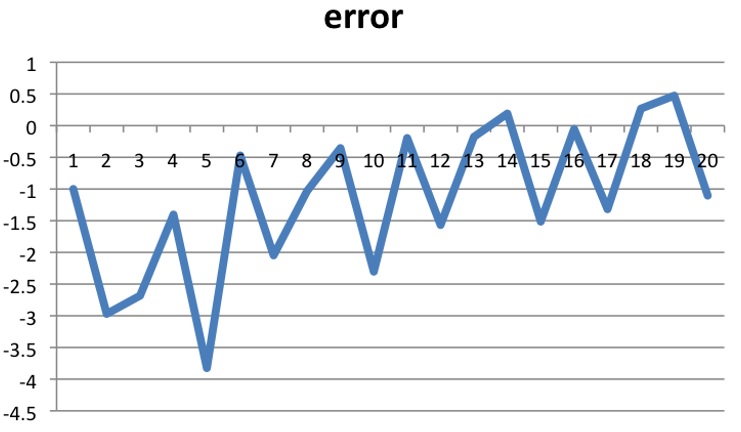
从图中,我们可以看到误差正逐渐变小,所以我们的最终模型也就是第20次的模型:
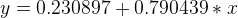
所以最后的曲线拟合结果如下:
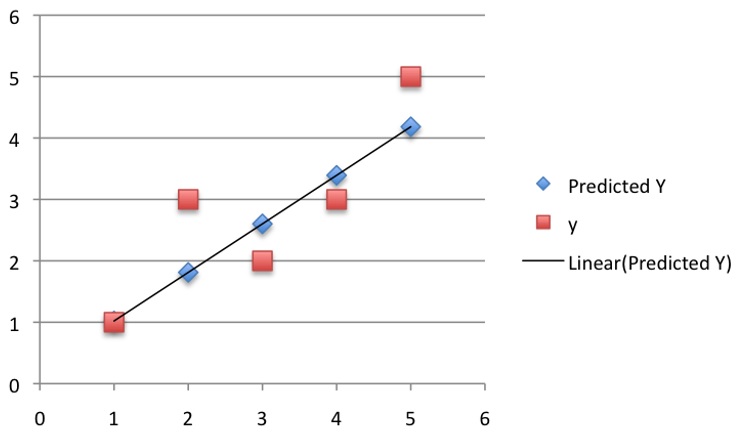
到这里其实不一定死板地局限于20次,也并不是迭代次数越多越好,因为这个过程像一个开口向下的二次函数, 适合的才是最好的。
 因为最合适的点可能就在中间,迭代太多次就跑偏了。解决这个问题可以在源代码里简单地加一个 If () 函数,当误差满足xxx时跳出循环就完事了。
因为最合适的点可能就在中间,迭代太多次就跑偏了。解决这个问题可以在源代码里简单地加一个 If () 函数,当误差满足xxx时跳出循环就完事了。
到这里应该就结束了。但原文章里多算了一次 Root-Mean-Square 值,也就是均方根,常用来分析噪声或者误差,公式如下:
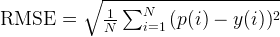 把每个点带入,得到RMSE=0.72。
把每个点带入,得到RMSE=0.72。
--------------------------------------------------------总结------------------------------------------------------------------------
其实Gradient Descent 通常适用于 量非常大且繁琐的数据(不在乎有那么几个因为跑偏而被淘汰的值)。
但如果要求数据足够精确、且数据模型复杂,不适合一次函数模型,那Gradient Descent 并不见得是一个好方法。
C / C ++ 基于梯度下降法的线性回归法(适用于机器学习)的更多相关文章
- Coursera在线学习---第一节.梯度下降法与正规方程法求解模型参数比较
一.梯度下降法 优点:即使特征变量的维度n很大,该方法依然很有效 缺点:1)需要选择学习速率α 2)需要多次迭代 二.正规方程法(Normal Equation) 该方法可以一次性求解参数Θ 优点:1 ...
- [ch04-02] 用梯度下降法解决线性回归问题
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 4.2 梯度下降法 有了上一节的最小二乘法做基准,我们这 ...
- tensorflow实现svm多分类 iris 3分类——本质上在使用梯度下降法求解线性回归(loss是定制的而已)
# Multi-class (Nonlinear) SVM Example # # This function wll illustrate how to # implement the gaussi ...
- tensorflow实现svm iris二分类——本质上在使用梯度下降法求解线性回归(loss是定制的而已)
iris二分类 # Linear Support Vector Machine: Soft Margin # ---------------------------------- # # This f ...
- 机器学习中梯度下降法原理及用其解决线性回归问题的C语言实现
本文讲梯度下降(Gradient Descent)前先看看利用梯度下降法进行监督学习(例如分类.回归等)的一般步骤: 1, 定义损失函数(Loss Function) 2, 信息流forward pr ...
- 最小二乘法 及 梯度下降法 分别对存在多重共线性数据集 进行线性回归 (Python版)
网上对于线性回归的讲解已经很多,这里不再对此概念进行重复,本博客是作者在听吴恩达ML课程时候偶然突发想法,做了两个小实验,第一个实验是采用最小二乘法对数据进行拟合, 第二个实验是采用梯度下降方法对数据 ...
- 梯度下降法实现最简单线性回归问题python实现
梯度下降法是非常常见的优化方法,在神经网络的深度学习中更是必会方法,但是直接从深度学习去实现,会比较复杂.本文试图使用梯度下降来优化最简单的LSR线性回归问题,作为进一步学习的基础. import n ...
- 对数几率回归法(梯度下降法,随机梯度下降与牛顿法)与线性判别法(LDA)
本文主要使用了对数几率回归法与线性判别法(LDA)对数据集(西瓜3.0)进行分类.其中在对数几率回归法中,求解最优权重W时,分别使用梯度下降法,随机梯度下降与牛顿法. 代码如下: #!/usr/bin ...
- 梯度下降法及一元线性回归的python实现
梯度下降法及一元线性回归的python实现 一.梯度下降法形象解释 设想我们处在一座山的半山腰的位置,现在我们需要找到一条最快的下山路径,请问应该怎么走?根据生活经验,我们会用一种十分贪心的策略,即在 ...
随机推荐
- DJango小总结一
views.py def func(request): # 包含所有的请求数据 ... ...
- css 盒模型 文档流 几种清除浮动的方法
盒模型 1.box-sizing: content-box 是普通的默认的一种盒子表现模式 盒子大小为 width + padding + border content-box:此值为其默认值,其 ...
- scss-传递内容块到@mixin
样式块被传递给混入用于放置内的样式.在@content指令的位置,样式被包含进mixin. 内容块被传递到块被定义一个混合的范围进行计算. 下面的例子演示了mixin使用内容块的SCSS代码: @mi ...
- CKEditor的使用
需要配置的功能列表 //class: cke_button( 按钮 ) , ck_combo(下拉) /* 需要配置的功能列表 document:保存(save).新建(newpage).预览(pre ...
- <Android 应用 之路> 简易手电筒
前言 快一个月没有写自己的博客了,由于最近换了工作,换了居住地,所以有一些杂事需要处理,从今天开始恢复正常,不赘述了.进入今天的主题 -– 简易的手电筒. 这个Demo中使用的是比较新的API,M版本 ...
- (四)svn 服务器端的使用之创建工程目录
仓库中存放开发项目代码.文档等,需要创建一个工程目录. 在之前创建的仓库中右键点击: 创建成功 trunk:项目开发代码的主体,是从项目开始直到当前都处于活动的状态,从这里可以获得项目最新的源代码以及 ...
- 成功解决:FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is
问题原因: 包内出错,是h5py包 解决思路: 执行如下操作: pip -- install h5py==2.8.0rc1 注意:如果执行pip install h5py==2.8.0rc1 成功话, ...
- 再学UML-深入浅出UML类图(三)
类与类之间的关系(2) 2. 依赖关系 依赖(Dependency)关系是一种使用关系,特定事物的改变有可能会影响到使用该事物的其他事物,在需要表示一个事物使用另一个事物时使用依赖关系. ...
- KVM虚拟化学习记录
请查看我的有道云笔记: http://note.youdao.com/noteshare?id=ed7308eeb1ee675b406494f4ba042ba4&sub=047FD8C61BA ...
- 如何杀掉一个用户下的所有进程并drop掉这个用户
如何杀掉一个用户下的所有进程并drop掉这个用户 Copy the sample code below into a file named kill_drop_user.sql.Open SQL*Pl ...