shell及Python爬虫实例展示
1.shell爬虫实例:
[root@db01 ~]# vim pa.sh
#!/bin/bash
www_link=http://www.cnblogs.com/clsn/default.html?page=
for i in {1..8}
do
a=`curl ${www_link}${i} 2>/dev/null|grep homepage|grep -v "ImageLink"|awk -F "[><\"]" '{print $7"@"$9}' >>bb.txt`#@为自己
指定的分隔符.这行是获取内容及内容网址
done
egrep -v "pager" bb.txt >ma.txt #将处理后,只剩内容和内容网址的放在一个文件里
b=`sed "s# ##g" ma.txt` #将文件里的空格去掉,因为for循环会将每行的空格前后作为两个变量,而不是一行为一个变量,这个坑花
了我好长时间。
for i in $b
do
c=`echo $i|awk -F @ '{print $1}'` #c=内容网址
d=`echo $i|awk -F @ '{print $2}'` #d=内容
echo "<a href='${c}' target='_blank'>${d}</a> " >>cc.txt #cc.txt为生成a标签的文本
done
爬虫结果显示:归档文件中惨绿少年的爬虫结果
注意:爬取结果放入博客应在a标签后加 的空格符或其他,博客园默认不显示字符串
的空格符或其他,博客园默认不显示字符串
2、
2.1Python爬虫学习
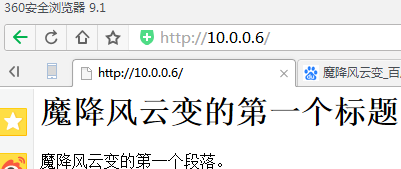
爬取这个网页
import urllib.request
# 网址
url = "http://10.0.0.6/"
# 请求
request = urllib.request.Request(url)
# 爬取结果
response = urllib.request.urlopen(request)
data = response.read()
# 设置解码方式
data = data.decode('utf-8')
# 打印结果
print(data)
结果:
E:\python\python\python.exe C:/python/day2/test.py
<html>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8">
<body>
<h1>魔降风云变的第一个标题</h1>
<p>魔降风云变的第一个段落。</p>
</body>
</html>
print(type(response))
结果:
<class 'http.client.HTTPResponse'>
print(response.geturl())
结果:
http://10.0.0.6/
print(response.info())
结果:
Server: nginx/1.12.
Date: Fri, Mar :: GMT
Content-Type: text/html
Content-Length:
Last-Modified: Fri, Mar :: GMT
Connection: close
ETag: "5a98ff58-b8"
Accept-Ranges: bytes
print(response.getcode())
结果:
2.2爬取网页代码并保存到电脑文件
import urllib.request
# 网址
url = "http://10.0.0.6/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
data = data.decode('utf-8')
# 打印抓取的内容
print(data)
结果:
<html>
<meta http-equiv="Content-Type" content="text/html;charset=utf-8">
<body>
<h1>魔降风云变的第一个标题</h1>
<p>魔降风云变的第一个段落。</p>
</body>
</html>
import urllib.request
# 定义保存函数
def saveFile(data): #------------------------------------------
path = "E:\\content.txt"
f = open(path, 'wb')
f.write(data)
f.close() #------------------------------------------
# 网址
url = "http://10.0.0.6/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/51.0.2704.63 Safari/537.36'}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
# 也可以把爬取的内容保存到文件中
saveFile(data) #******************************************
data = data.decode('utf-8')
# 打印抓取的内容
print(data)
添加保存文件的函数并执行的结果:

# # 打印爬取网页的各类信息
print(type(res))
print(res.geturl())
print(res.info())
print(res.getcode())
结果:
<class 'http.client.HTTPResponse'>
http://10.0.0.6/
Server: nginx/1.12.
Date: Fri, Mar :: GMT
Content-Type: text/html
Content-Length:
Last-Modified: Fri, Mar :: GMT
Connection: close
ETag: "5a98ff58-b8"
Accept-Ranges: bytes
2.3爬取图片
import urllib.request, socket, re, sys, os
# 定义文件保存路径
targetPath = "E:\\"
def saveFile(path):
# 检测当前路径的有效性
if not os.path.isdir(targetPath):
os.mkdir(targetPath) # 设置每个图片的路径
pos = path.rindex('/')
t = os.path.join(targetPath, path[pos + 1:])
return t
# 用if __name__ == '__main__'来判断是否是在直接运行该.py文件
# 网址
url = "http://10.0.0.6/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
print(data)
for link, t in set(re.findall(r'(http:[^s]*?(jpg|png|gif))', str(data))):
print(link)
try:
urllib.request.urlretrieve(link, saveFile(link))
except:
print('失败')
2.31
import urllib.request, socket, re, sys, os
url = "http://10.0.0.6/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
print(req)
print(res)
print(data)
print(str(data))
结果:
<urllib.request.Request object at 0x0000000001ECD9E8>
<http.client.HTTPResponse object at 0x0000000002D1B128>
b'<html>\n<meta http-equiv="Content-Type" content="text/html;charset=utf-8">\n<body>\n<img src="http://10.0.0.6/ma1.png" />\n<img src="http://10.0.0.6/ma2.jpg" />\n<h1>\xe9\xad\x94\xe9\x99\x8d\xe9\xa3\x8e\xe4\xba\x91\xe5\x8f\x98\xe7\x9a\x84\xe7\xac\xac\xe4\xb8\x80\xe4\xb8\xaa\xe6\xa0\x87\xe9\xa2\x98</h1>\n<p>\xe9\xad\x94\xe9\x99\x8d\xe9\xa3\x8e\xe4\xba\x91\xe5\x8f\x98\xe7\x9a\x84\xe7\xac\xac\xe4\xb8\x80\xe4\xb8\xaa\xe6\xae\xb5\xe8\x90\xbd\xe3\x80\x82</p>\n</body>\n</html>\n'
b'<html>\n<meta http-equiv="Content-Type" content="text/html;charset=utf-8">\n<body>\n<img src="http://10.0.0.6/ma1.png" />\n<img src="http://10.0.0.6/ma2.jpg" />\n<h1>\xe9\xad\x94\xe9\x99\x8d\xe9\xa3\x8e\xe4\xba\x91\xe5\x8f\x98\xe7\x9a\x84\xe7\xac\xac\xe4\xb8\x80\xe4\xb8\xaa\xe6\xa0\x87\xe9\xa2\x98</h1>\n<p>\xe9\xad\x94\xe9\x99\x8d\xe9\xa3\x8e\xe4\xba\x91\xe5\x8f\x98\xe7\x9a\x84\xe7\xac\xac\xe4\xb8\x80\xe4\xb8\xaa\xe6\xae\xb5\xe8\x90\xbd\xe3\x80\x82</p>\n</body>\n</html>\n'
2.32
import urllib.request, socket, re, sys, os
url = "http://10.0.0.6/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
for link in set(re.findall(r'(http:[^s]*?(jpg|png|gif))', str(data))):
print(link)
结果:
('http://10.0.0.6/ma2.jpg', 'jpg')
('http://10.0.0.6/ma1.png', 'png')
2.33
for link,t in set(re.findall(r'(http:[^s]*?(jpg|png|gif))', str(data))):
print(link)
结果:
http://10.0.0.6/ma1.png
http://10.0.0.6/ma2.jpg
2.34
import urllib.request, socket, re, sys, os
# 定义文件保存路径
targetPath = "E:\\"
def saveFile(path):
# 检测当前路径的有效性
if not os.path.isdir(targetPath):
os.mkdir(targetPath) # 设置每个图片的路径
pos = path.rindex('/')
t = os.path.join(targetPath, path[pos + 1:])
return t
# 用if __name__ == '__main__'来判断是否是在直接运行该.py文件
# 网址
url = "http://10.0.0.6/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/51.0.2704.63 Safari/537.36'
}
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
data = res.read()
for link,t in set(re.findall(r'(http:[^s]*?(jpg|png|gif))', str(data))):
print(link)
try:
urllib.request.urlretrieve(link, saveFile(link))
except:
print('失败')
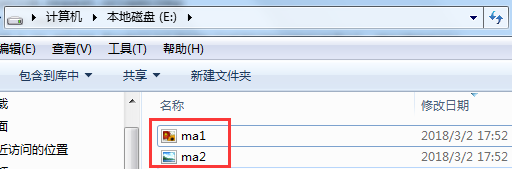
结果:
http://10.0.0.6/ma2.jpg
http://10.0.0.6/ma1.png
2.4登录知乎

参考:http://blog.csdn.net/fly_yr/article/details/51535676
shell及Python爬虫实例展示的更多相关文章
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
- Python 爬虫实例
下面是我写的一个简单爬虫实例 1.定义函数读取html网页的源代码 2.从源代码通过正则表达式挑选出自己需要获取的内容 3.序列中的htm依次写到d盘 #!/usr/bin/python import ...
- Python爬虫实例:糗百
看了下python爬虫用法,正则匹配过滤对应字段,这里进行最强外功:copy大法实践 一开始是直接从参考链接复制粘贴的,发现由于糗百改版导致失败,这里对新版html分析后进行了简单改进,把整理过程记录 ...
- python爬虫实例大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
- python爬虫实例——爬取歌单
学习自<<从零开始学python网络爬虫>> 爬取酷狗歌单,保存入csv文件 直接上源代码:(含注释) import requests #用于请求网页获取网页数据 from b ...
- Python 爬虫实例(爬百度百科词条)
爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成.爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入 ...
- Python爬虫实例(五) requests+flask构建自己的电影库
目标任务:使用requests抓取电影网站信息和下载链接保存到数据库中,然后使用flask做数据展示. 爬取的网站在这里 最终效果如下: 主页: 可以进行搜索:输入水形物语 点击标题进入详情页: 爬虫 ...
随机推荐
- echarts图标相关
图标类型参考地址: http://echarts.baidu.com/echarts2/doc/doc.html 知识点一: 堆叠柱状图与普通柱状图的区别在于: 堆叠柱状图 在series中需要设置 ...
- 《深入理解Spring Cloud与微服务构建》书籍目录
转载请标明出处: https://blog.csdn.net/forezp/article/details/79735542 本文出自方志朋的博客 作者简介 方志朋,毕业于武汉理工大学,CSDN博客专 ...
- 数据恢复顾问(DRA)
(1)DRA介绍 数据恢复顾问(Data Recovery Advise)是一个诊断和修复数据库的工具,DRA能够修复数据文件和(某些环境下)控制文件的损坏,它不提供spfile和logfile的修复 ...
- axios基础用法
概述: 1.axios:一个基于Promise用于浏览器和nodejs的HTTP客户端.本质是对ajax的封装. 特征: 1>从浏览器中创建XMLHttpRequest 2>从node.j ...
- 【HDOJ 1269】迷宫城堡(tarjan模板题)
Problem Description 为了训练小希的方向感,Gardon建立了一座大城堡,里面有N个房间(N<=10000)和M条通道(M<=100000),每个通道都是单向的,就是说若 ...
- vs2017中的scanf_s
在visual studio 2017中格式化输入函数不同于其他c/c++编译器使用scanf,而是使用scanf_s. scanf_s相比较于scanf来说更安全,因为使用scanf_s函数需要有一 ...
- tomcat端口占用后的解决办法【亲测有效】
https://www.cnblogs.com/zhangtan/p/5856573.html 检测正在使用的端口 这里就以win7为例进行讲解. 首先打开cmd,打开的方法很简单,在开始菜单中直 ...
- nigx配置location规则
以下是收集的,对于不是很熟的朋友,配置转发很有帮助 1.location匹配命令和优先级: 优先级: Directives with the = prefix that match the query ...
- reactor模式---事件触发模型
Reactor这个词译成汉语还真没有什么合适的,很多地方叫反应器模式,但更多好像就直接叫reactor模式了,其实我觉着叫应答者模式更好理解一些.通过了解,这个模式更像一个侍卫,一直在等待你的召唤. ...
- iframe中的页面在IE全屏模式下没有滚动条,正常模式有滚动条
这个问题在其他浏览器都不会出现,唯独IE不行,搜遍了百度以及各大论坛网站,都找不到这个问题的解决方案,只好自己整了. 造成这个问题的原因很简单,就是刚开始的滚动条我用的是iframe的滚动条,ifra ...