Pro Git - 笔记2
Git Basics
Getting a Git Repository
Initializing a Repository in an Existing Directory
For Linux:
$ cd /home/user/my_project
For Mac OS:
$ cd /Users/user/my_project
For Windows:
$ cd /c/user/my_project
and type:
$ git init
$ git add *.c
$ git add LICENSE
$ git commit -m 'initial project version'
Cloning an Existing Repository
$ git clone https://github.com/libgit2/libgit2
That creates a directory named libgit2, initializes a .git directory inside it, pulls down all the data for that repository, and checks out a working copy of the latest version.
$ git clone https://github.com/libgit2/libgit2 mylibgit
That command does the same thing as the previous one, but the target directory is called mylibgit.
Recording Changes to the Repository
Remember that each file in your working directory can be in one of two states: tracked or untracked. Tracked files are files that were in the last snapshot; they can be unmodified, modified, or staged. In short, tracked files are files that Git knows about.
Untracked files are everything else — any files in your working directory that were not in your last snapshot and are not in your staging area. When you first clone a repository, all of your files will be tracked and unmodified because Git just checked them out and you haven’t edited anything.
As you edit files, Git sees them as modified, because you’ve changed them since your last commit. As you work, you selectively stage these modified files and then commit all those staged changes, and the cycle repeats.
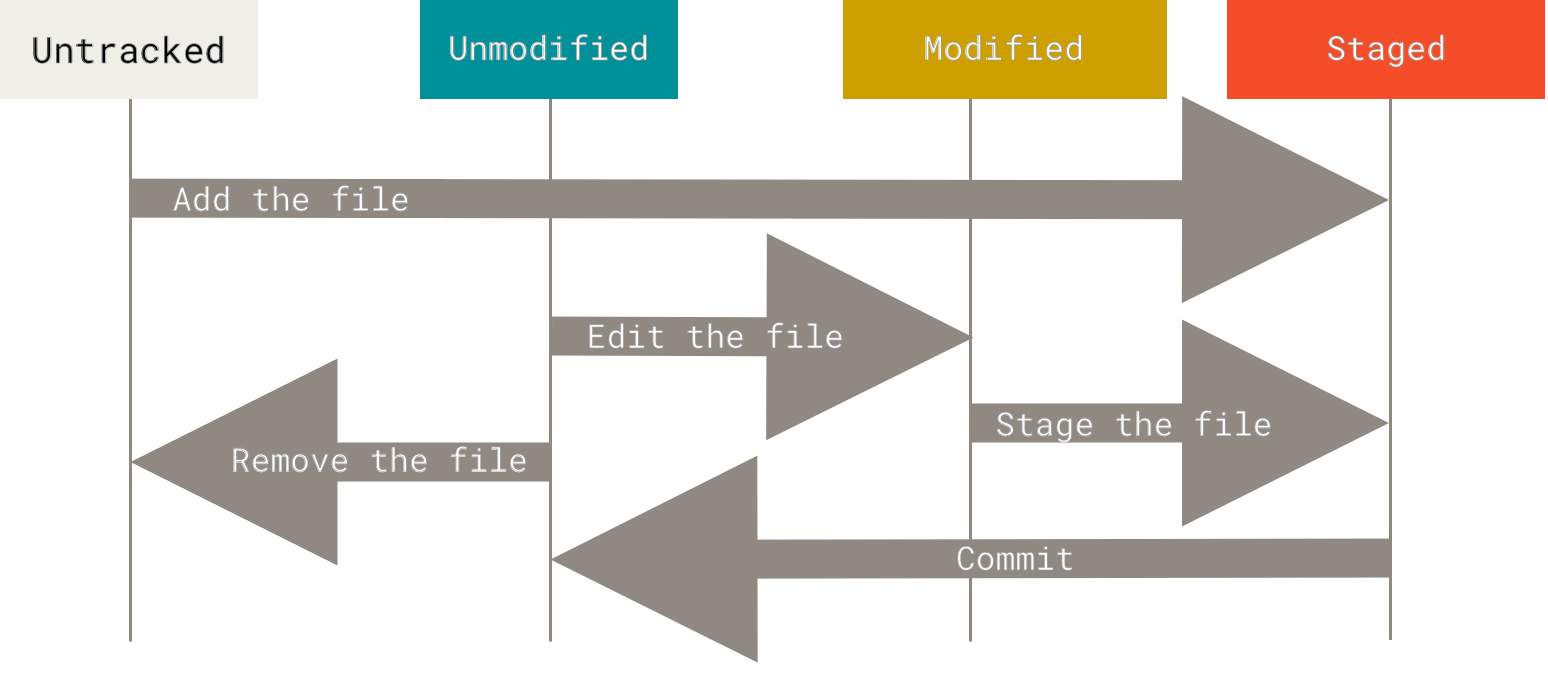
Check the Status of Your Files
If you run this command directly after a clone, you should see something like this:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
nothing to commit, working directory clean
Let’s say you add a new file to your project, a simple README file. If the file didn’t exist before, and you run git status, you see your untracked file like so:
$ echo 'My Project' > README
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Untracked files:
(use "git add <file>..." to include in what will be committed) README nothing added to commit but untracked files present (use "git add" to track)
Tracking New Files
$ git add README
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) new file: README
Staging Modified Files
Let’s change a file that was already tracked. If you change a previously tracked file called CONTRIBUTING.md and then run your git status command again, you get something that looks like this:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) new file: README Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory) modified: CONTRIBUTING.md
$ git add CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) new file: README
modified: CONTRIBUTING.md
Both files are staged and will go into your next commit. At this point, suppose you remember one little change that you want to make in CONTRIBUTING.md before you commit it. You open it again and make that change, and you’re ready to commit. However, let’s run git status one more time:
$ vim CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) new file: README
modified: CONTRIBUTING.md Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory) modified: CONTRIBUTING.md
What the heck? Now CONTRIBUTING.md is listed as both staged and unstaged. How is that possible? It turns out that Git stages a file exactly as it is when you run the git add command. If you commit now, the version of CONTRIBUTING.md as it was when you last ran the git add command is how it will go into the commit, not the version of the file as it looks in your working directory when you run git commit. If you modify a file after you run git add, you have to run git add again to stage the latest version of the file:
$ git add CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) new file: README
modified: CONTRIBUTING.md
Short Status
If you run git status -s or git status --short you get a far more simplified output from the command:
$ git status -s
M README
MM Rakefile
A lib/git.rb
M lib/simplegit.rb
?? LICENSE.txt
New files that aren’t tracked have a ?? next to them, new files that have been added to the staging area have an A, modified files have an M and so on. There are two columns to the output - the left-hand column indicates the status of the staging area and the right-hand column indicates the status of the working tree. So for example in that output, the README file is modified in the working directory but not yet staged, while the lib/simplegit.rb file is modified and staged. The Rakefile was modified, staged and then modified again, so there are changes to it that are both staged and unstaged.
Ignore Files
Here is an example .gitignore file:
$ cat .gitignore
*.[oa]
*~
The first line tells Git to ignore any files ending in “.o” or “.a” — object and archive files that may be the product of building your code.
The second line tells Git to ignore all files whose names end with a tilde (~), which is used by many text editors such as Emacs to mark temporary files.
You may also include a log, tmp, or pid directory; automatically generated documentation; and so on. Setting up a .gitignore file for your new repository before you get going is generally a good idea so you don’t accidentally commit files that you really don’t want in your Git repository.
The rules for the patterns you can put in the .gitignore file are as follows:
Blank lines or lines starting with
#are ignored.Standard glob patterns work, and will be applied recursively throughout the entire working tree.
You can start patterns with a forward slash (
/) to avoid recursivity.You can end patterns with a forward slash (
/) to specify a directory.You can negate a pattern by starting it with an exclamation point (
!).
Glob patterns are like simplified regular expressions that shells use. An asterisk (*) matches zero or more characters; [abc] matches any character inside the brackets (in this case a, b, or c); a question mark (?) matches a single character; and brackets enclosing characters separated by a hyphen ([0-9]) matches any character between them (in this case 0 through 9). You can also use two asterisks to match nested directories; a/**/z would match a/z, a/b/z, a/b/c/z, and so on.
Here is another example .gitignore file:
# ignore all .a files
*.a # but do track lib.a, even though you're ignoring .a files above
!lib.a # only ignore the TODO file in the current directory, not subdir/TODO
/TODO # ignore all files in the build/ directory
build/ # ignore doc/notes.txt, but not doc/server/arch.txt
doc/*.txt # ignore all .pdf files in the doc/ directory and any of its subdirectories
doc/**/*.pdf
View Your Staged and Unstaged Changes
If the git status command is too vague for you — you want to know exactly what you changed, not just which files were changed — you can use the git diff command. You’ll probably use it most often to answer these two questions:
What have you changed but not yet staged?
And what have you staged that you are about to commit?
Although git status answers those questions very generally by listing the file names, git diff shows you the exact lines added and removed — the patch, as it were.
Let’s say you edit and stage the README file again and then edit the CONTRIBUTING.md file without staging it. If you run your git status command, you once again see something like this:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) modified: README Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory) modified: CONTRIBUTING.md
To see what you’ve changed but not yet staged, type git diff with no other arguments:
$ git diff
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8ebb991..643e24f
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -, +, @@ branch directly, things can get messy.
Please include a nice description of your changes when you submit your PR;
if we have to read the whole diff to figure out why you're contributing
in the first place, you're less likely to get feedback and have your change
-merged in.
+merged in. Also, split your changes into comprehensive chunks if your patch is
+longer than a dozen lines. If you are starting to work on a particular area, feel free to submit a PR
that highlights your work in progress (and note in the PR title that it's
That command compares what is in your working directory with what is in your staging area. The result tells you the changes you’ve made that you haven’t yet staged.
If you want to see what you’ve staged that will go into your next commit, you can use git diff --staged. This command compares your staged changes to your last commit:
$ git diff --staged
diff --git a/README b/README
new file mode
index ..03902a1
--- /dev/null
+++ b/README
@@ -, + @@
+My Project
It’s important to note that git diff by itself doesn’t show all changes made since your last commit — only changes that are still unstaged. If you’ve staged all of your changes, git diffwill give you no output.
For another example, if you stage the CONTRIBUTING.md file and then edit it, you can use git diffto see the changes in the file that are staged and the changes that are unstaged. If our environment looks like this:
$ git add CONTRIBUTING.md
$ echo '# test line' >> CONTRIBUTING.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) modified: CONTRIBUTING.md Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory) modified: CONTRIBUTING.md
Now you can use git diff to see what is still unstaged:
$ git diff
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 643e24f..87f08c8
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -, +, @@ at the
## Starter Projects See our [projects list](https://github.com/libgit2/libgit2/blob/development/PROJECTS.md).
+# test line
and git diff --cached to see what you’ve staged so far (--staged and --cached are synonyms):
$ git diff --cached
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 8ebb991..643e24f
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -, +, @@ branch directly, things can get messy.
Please include a nice description of your changes when you submit your PR;
if we have to read the whole diff to figure out why you're contributing
in the first place, you're less likely to get feedback and have your change
-merged in.
+merged in. Also, split your changes into comprehensive chunks if your patch is
+longer than a dozen lines. If you are starting to work on a particular area, feel free to submit a PR
that highlights your work in progress (and note in the PR title that it's
Committing Your Changes
$ git commit
$ git commit -m "Story 182: Fix benchmarks for speed"
[master 463dc4f] Story : Fix benchmarks for speed
files changed, insertions(+)
create mode README
Now you’ve created your first commit! You can see that the commit has given you some output about itself: which branch you committed to (master), what SHA-1 checksum the commit has (463dc4f), how many files were changed, and statistics about lines added and removed in the commit.
Remember that the commit records the snapshot you set up in your staging area. Anything you didn’t stage is still sitting there modified; you can do another commit to add it to your history. Every time you perform a commit, you’re recording a snapshot of your project that you can revert to or compare to later.
Skipping the Staging Area
Git provides a simple shortcut. Adding the -a option to the git commit command makes Git automatically stage every file that is already tracked before doing the commit, letting you skip the git add part:
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory) modified: CONTRIBUTING.md no changes added to commit (use "git add" and/or "git commit -a")
$ git commit -a -m 'added new benchmarks'
[master 83e38c7] added new benchmarks
file changed, insertions(+), deletions(-)
Removing Files
To remove a file from Git, you have to remove it from your tracked files (more accurately, remove it from your staging area) and then commit. The git rm command does that, and also removes the file from your working directory so you don’t see it as an untracked file the next time around.
If you simply remove the file from your working directory, it shows up under the “Changes not staged for commit” (that is, unstaged) area of your git status output:
$ rm PROJECTS.md
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory) deleted: PROJECTS.md no changes added to commit (use "git add" and/or "git commit -a")
Then, if you run git rm, it stages the file’s removal:
$ git rm PROJECTS.md
rm 'PROJECTS.md'
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) deleted: PROJECTS.md
The next time you commit, the file will be gone and no longer tracked. If you modified the file and added it to the staging area already, you must force the removal with the -f option. This is a safety feature to prevent accidental removal of data that hasn’t yet been recorded in a snapshot and that can’t be recovered from Git.
Another useful thing you may want to do is to keep the file in your working tree but remove it from your staging area. In other words, you may want to keep the file on your hard drive but not have Git track it anymore. This is particularly useful if you forgot to add something to your .gitignore file and accidentally staged it, like a large log file or a bunch of .a compiled files. To do this, use the --cached option:
$ git rm --cached README
You can pass files, directories, and file-glob patterns to the git rm command. That means you can do things such as:
$ git rm log/\*.log
This command removes all files that have the .log extension in the log/ directory. Or, you can do something like this:
$ git rm \*~
This command removes all files whose names end with a ~.
Moving Files
Thus it’s a bit confusing that Git has a mv command. If you want to rename a file in Git, you can run something like:
$ git mv file_from file_to
In fact, if you run something like this and look at the status, you’ll see that Git considers it a renamed file:
$ git mv README.md README
$ git status
On branch master
Your branch is up-to-date with 'origin/master'.
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) renamed: README.md -> README
However, this is equivalent to running something like this:
$ mv README.md README
$ git rm README.md
$ git add README
Viewing the Commit History
$ git clone https://github.com/schacon/simplegit-progit
$ git log
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar :: - changed the version number commit 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar :: - removed unnecessary test commit a11bef06a3f659402fe7563abf99ad00de2209e6
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar :: - first commit
One of the more helpful options is -p or --patch, which shows the difference (the patch output) introduced in each commit. You can also limit the number of log entries displayed, such as using -2 to show only the last two entries.
$ git log -p -
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar :: - changed the version number diff --git a/Rakefile b/Rakefile
index a874b73..8f94139
--- a/Rakefile
+++ b/Rakefile
@@ -, +, @@ require 'rake/gempackagetask'
spec = Gem::Specification.new do |s|
s.platform = Gem::Platform::RUBY
s.name = "simplegit"
- s.version = "0.1.0"
+ s.version = "0.1.1"
s.author = "Scott Chacon"
s.email = "schacon@gee-mail.com"
s.summary = "A simple gem for using Git in Ruby code." commit 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar :: - removed unnecessary test diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index a0a60ae..47c6340
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -, +, @@ class SimpleGit
end end
-
-if $ == __FILE__
- git = SimpleGit.new
- puts git.show
-end
if you want to see some abbreviated stats for each commit, you can use the --statoption:
$ git log --stat
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar :: - changed the version number Rakefile | +-
file changed, insertion(+), deletion(-) commit 085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar :: - removed unnecessary test lib/simplegit.rb | -----
file changed, deletions(-) commit a11bef06a3f659402fe7563abf99ad00de2209e6
Author: Scott Chacon <schacon@gee-mail.com>
Date: Sat Mar :: - first commit README | ++++++
Rakefile | +++++++++++++++++++++++
lib/simplegit.rb | +++++++++++++++++++++++++
files changed, insertions(+)
$ git log --pretty=oneline
ca82a6dff817ec66f44342007202690a93763949 changed the version number
085bb3bcb608e1e8451d4b2432f8ecbe6306e7e7 removed unnecessary test
a11bef06a3f659402fe7563abf99ad00de2209e6 first commit
$ git log --pretty=format:"%h - %an, %ar : %s"
ca82a6d - Scott Chacon, years ago : changed the version number
085bb3b - Scott Chacon, years ago : removed unnecessary test
a11bef0 - Scott Chacon, years ago : first commit
You may be wondering what the difference is between author and committer. The author is the person who originally wrote the work, whereas the committer is the person who last applied the work. So, if you send in a patch to a project and one of the core members applies the patch, both of you get credit — you as the author, and the core member as the committer.
The oneline and format options are particularly useful with another log option called --graph. This option adds a nice little ASCII graph showing your branch and merge history:
$ git log --pretty=format:"%h %s" --graph
* 2d3acf9 ignore errors from SIGCHLD on trap
* 5e3ee11 Merge branch 'master' of git://github.com/dustin/grit
|\
| * 420eac9 Added a method for getting the current branch.
* | 30e367c timeout code and tests
* | 5a09431 add timeout protection to grit
* | e1193f8 support for heads with slashes in them
|/
* d6016bc require time for xmlschema
* 11d191e Merge branch 'defunkt' into local
Limits Log Output
the time-limiting options such as --since and --until are very useful. For example, this command gets the list of commits made in the last two weeks:
$ git log --since=.weeks
You can also filter the list to commits that match some search criteria. The --author option allows you to filter on a specific author, and the --grep option lets you search for keywords in the commit messages.
Another really helpful filter is the -S option (colloquially referred to as Git’s “pickaxe” option), which takes a string and shows only those commits that changed the number of occurrences of that string. For instance, if you wanted to find the last commit that added or removed a reference to a specific function, you could call:
$ git log -S function_name
The last really useful option to pass to git log as a filter is a path. If you specify a directory or file name, you can limit the log output to commits that introduced a change to those files. This is always the last option and is generally preceded by double dashes (--) to separate the paths from the options.
$ git log --pretty="%h - %s" --author=gitster --since="2008-10-01" \
--before="2008-11-01" --no-merges -- t/
5610e3b - Fix testcase failure when extended attributes are in use
acd3b9e - Enhance hold_lock_file_for_{update,append}() API
f563754 - demonstrate breakage of detached checkout with symbolic link HEAD
d1a43f2 - reset --hard/read-tree --reset -u: remove unmerged new paths
51a94af - Fix "checkout --track -b newbranch" on detached HEAD
b0ad11e - pull: allow "git pull origin $something:$current_branch" into an unborn branch
Undoing Things
One of the common undos takes place when you commit too early and possibly forget to add some files, or you mess up your commit message. If you want to redo that commit, make the additional changes you forgot, stage them, and commit again using the --amend option:
$ git commit --amend
As an example, if you commit and then realize you forgot to stage the changes in a file you wanted to add to this commit, you can do something like this:
$ git commit -m 'initial commit'
$ git add forgotten_file
$ git commit --amend
Unstaging aStaged File
For example, let’s say you’ve changed two files and want to commit them as two separate changes, but you accidentally type git add * and stage them both. How can you unstage one of the two? The git status command reminds you:
$ git add *
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) renamed: README.md -> README
modified: CONTRIBUTING.md
Right below the “Changes to be committed” text, it says use git reset HEAD <file>... to unstage. So, let’s use that advice to unstage the CONTRIBUTING.md file:
$ git reset HEAD CONTRIBUTING.md
Unstaged changes after reset:
M CONTRIBUTING.md
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) renamed: README.md -> README Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory) modified: CONTRIBUTING.md
The command is a bit strange, but it works. The CONTRIBUTING.md file is modified but once again unstaged.
Unmodifying a Modified File
What if you realize that you don’t want to keep your changes to the CONTRIBUTING.md file? How can you easily unmodify it — revert it back to what it looked like when you last committed (or initially cloned, or however you got it into your working directory)? Luckily, git status tells you how to do that, too. In the last example output, the unstaged area looks like this:
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory) modified: CONTRIBUTING.md
It tells you pretty explicitly how to discard the changes you’ve made. Let’s do what it says:
$ git checkout -- CONTRIBUTING.md
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage) renamed: README.md -> README
Working with Remotes
Showing Your Remotes
$ git clone https://github.com/schacon/ticgit
Cloning into 'ticgit'...
remote: Reusing existing pack: , done.
remote: Total (delta ), reused (delta )
Receiving objects: % (/), 374.35 KiB | 268.00 KiB/s, done.
Resolving deltas: % (/), done.
Checking connectivity... done.
$ cd ticgit
$ git remote
origin
$ git remote -v
origin https://github.com/schacon/ticgit (fetch)
origin https://github.com/schacon/ticgit (push)
If you have more than one remote, the command lists them all. For example, a repository with multiple remotes for working with several collaborators might look something like this.
$ cd grit
$ git remote -v
bakkdoor https://github.com/bakkdoor/grit (fetch)
bakkdoor https://github.com/bakkdoor/grit (push)
cho45 https://github.com/cho45/grit (fetch)
cho45 https://github.com/cho45/grit (push)
defunkt https://github.com/defunkt/grit (fetch)
defunkt https://github.com/defunkt/grit (push)
koke git://github.com/koke/grit.git (fetch)
koke git://github.com/koke/grit.git (push)
origin git@github.com:mojombo/grit.git (fetch)
origin git@github.com:mojombo/grit.git (push)
Adding Remote Repositories
$ git remote
origin
$ git remote add pb https://github.com/paulboone/ticgit
$ git remote -v
origin https://github.com/schacon/ticgit (fetch)
origin https://github.com/schacon/ticgit (push)
pb https://github.com/paulboone/ticgit (fetch)
pb https://github.com/paulboone/ticgit (push)
Now you can use the string pb on the command line in lieu of the whole URL. For example, if you want to fetch all the information that Paul has but that you don’t yet have in your repository, you can run git fetch pb:
$ git fetch pb
remote: Counting objects: , done.
remote: Compressing objects: % (/), done.
remote: Total (delta ), reused (delta )
Unpacking objects: % (/), done.
From https://github.com/paulboone/ticgit
* [new branch] master -> pb/master
* [new branch] ticgit -> pb/ticgit
Paul’s master branch is now accessible locally as pb/master — you can merge it into one of your branches, or you can check out a local branch at that point if you want to inspect it.
Fetching and Pulling from Your Remotes
As you just saw, to get data from your remote projects, you can run:
$ git fetch <remote>
The command goes out to that remote project and pulls down all the data from that remote project that you don’t have yet. After you do this, you should have references to all the branches from that remote, which you can merge in or inspect at any time.
If you clone a repository, the command automatically adds that remote repository under the name “origin”. So, git fetch origin fetches any new work that has been pushed to that server since you cloned (or last fetched from) it. It’s important to note that the git fetch command only downloads the data to your local repository — it doesn’t automatically merge it with any of your work or modify what you’re currently working on. You have to merge it manually into your work when you’re ready.
If your current branch is set up to track a remote branch (see the next section and Git Branchingfor more information), you can use the git pull command to automatically fetch and then merge that remote branch into your current branch. This may be an easier or more comfortable workflow for you; and by default, the git clone command automatically sets up your local master branch to track the remote master branch (or whatever the default branch is called) on the server you cloned from. Running git pull generally fetches data from the server you originally cloned from and automatically tries to merge it into the code you’re currently working on.
Pushing to Your Remotes
$ git push origin master
This command works only if you cloned from a server to which you have write access and if nobody has pushed in the meantime. If you and someone else clone at the same time and they push upstream and then you push upstream, your push will rightly be rejected. You’ll have to fetch their work first and incorporate it into yours before you’ll be allowed to push.
Inspecting a Remote
$ git remote show origin
* remote origin
Fetch URL: https://github.com/schacon/ticgit
Push URL: https://github.com/schacon/ticgit
HEAD branch: master
Remote branches:
master tracked
dev-branch tracked
Local branch configured for 'git pull':
master merges with remote master
Local ref configured for 'git push':
master pushes to master (up to date)
Renaming and Removing Remotes
$ git remote rename pb paul
$ git remote
origin
paul
$ git remote remove paul
$ git remote
origin
Tagging
Like most VCSs, Git has the ability to tag specific points in history as being important. Typically people use this functionality to mark release points (v1.0, and so on).
Listing Your Tags
$ git tag
v0.
v1.
The Git source repo, for instance, contains more than 500 tags. If you’re only interested in looking at the 1.8.5 series, you can run this:
$ git tag -l "v1.8.5*"
v1.8.5
v1.8.5-rc0
v1.8.5-rc1
v1.8.5-rc2
v1.8.5-rc3
v1.8.5.
v1.8.5.
v1.8.5.
v1.8.5.
v1.8.5.
Creating Tags
Git supports two types of tags: lightweight and annotated.
A lightweight tag is very much like a branch that doesn’t change — it’s just a pointer to a specific commit.
Annotated tags, however, are stored as full objects in the Git database. They’re checksummed; contain the tagger name, email, and date; have a tagging message; and can be signed and verified with GNU Privacy Guard (GPG).
Annotated Tags
Creating an annotated tag in Git is simple. The easiest way is to specify -a when you run the tagcommand:
$ git tag -a v1. -m "my version 1.4"
$ git tag
v0.
v1.
v1.
The -m specifies a tagging message, which is stored with the tag. If you don’t specify a message for an annotated tag, Git launches your editor so you can type it in.
You can see the tag data along with the commit that was tagged by using the git showcommand:
$ git show v1.
tag v1.
Tagger: Ben Straub <ben@straub.cc>
Date: Sat May :: - my version 1.4 commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar :: - changed the version number
Lightweight Tags
To create a lightweight tag, don’t supply any of the -a, -s, or -m options, just provide a tag name:
$ git tag v1.-lw
$ git tag
v0.
v1.
v1.
v1.-lw
v1.
This time, if you run git show on the tag, you don’t see the extra tag information. The command just shows the commit:
$ git show v1.-lw
commit ca82a6dff817ec66f44342007202690a93763949
Author: Scott Chacon <schacon@gee-mail.com>
Date: Mon Mar :: - changed the version number
Tagging Later
You can also tag commits after you’ve moved past them. Suppose your commit history looks like this:
$ git log --pretty=oneline
15027957951b64cf874c3557a0f3547bd83b3ff6 Merge branch 'experiment'
a6b4c97498bd301d84096da251c98a07c7723e65 beginning write support
0d52aaab4479697da7686c15f77a3d64d9165190 one more thing
6d52a271eda8725415634dd79daabbc4d9b6008e Merge branch 'experiment'
0b7434d86859cc7b8c3d5e1dddfed66ff742fcbc added a commit function
4682c3261057305bdd616e23b64b0857d832627b added a todo file
166ae0c4d3f420721acbb115cc33848dfcc2121a started write support
9fceb02d0ae598e95dc970b74767f19372d61af8 updated rakefile
964f16d36dfccde844893cac5b347e7b3d44abbc commit the todo
8a5cbc430f1a9c3d00faaeffd07798508422908a updated readme
Now, suppose you forgot to tag the project at v1.2, which was at the “updated rakefile” commit. You can add it after the fact. To tag that commit, you specify the commit checksum (or part of it) at the end of the command:
$ git tag -a v1. 9fceb02
$ git tag
v0.
v1.
v1.
v1.
v1.-lw
v1. $ git show v1.
tag v1.
Tagger: Scott Chacon <schacon@gee-mail.com>
Date: Mon Feb :: - version 1.2
commit 9fceb02d0ae598e95dc970b74767f19372d61af8
Author: Magnus Chacon <mchacon@gee-mail.com>
Date: Sun Apr :: - updated rakefile
...
Sharing Tags
By default, the git push command doesn’t transfer tags to remote servers. You will have to explicitly push tags to a shared server after you have created them. This process is just like sharing remote branches — you can run git push origin <tagname>.
$ git push origin v1.
Counting objects: , done.
Delta compression using up to threads.
Compressing objects: % (/), done.
Writing objects: % (/), 2.05 KiB | bytes/s, done.
Total (delta ), reused (delta )
To git@github.com:schacon/simplegit.git
* [new tag] v1. -> v1.
If you have a lot of tags that you want to push up at once, you can also use the --tags option to the git push command. This will transfer all of your tags to the remote server that are not already there.
$ git push origin --tags
Counting objects: , done.
Writing objects: % (/), bytes | bytes/s, done.
Total (delta ), reused (delta )
To git@github.com:schacon/simplegit.git
* [new tag] v1. -> v1.
* [new tag] v1.-lw -> v1.-lw
Checkint out Tags
If you want to view the versions of files a tag is pointing to, you can do a git checkout, though this puts your repository in “detached HEAD” state, which has some ill side effects:
$ git checkout 2.0.
Note: checking out '2.0.0'. You are in 'detached HEAD' state. You can look around, make experimental
changes and commit them, and you can discard any commits you make in this
state without impacting any branches by performing another checkout. If you want to create a new branch to retain commits you create, you may
do so (now or later) by using -b with the checkout command again. Example: git checkout -b <new-branch> HEAD is now at 99ada87... Merge pull request # from schacon/appendix-final $ git checkout 2.0-beta-0.1
Previous HEAD position was 99ada87... Merge pull request # from schacon/appendix-final
HEAD is now at df3f601... add atlas.json and cover image
In “detached HEAD” state, if you make changes and then create a commit, the tag will stay the same, but your new commit won’t belong to any branch and will be unreachable, except by the exact commit hash. Thus, if you need to make changes — say you’re fixing a bug on an older version, for instance — you will generally want to create a branch:
$ git checkout -b version2 v2.0.0
Switched to a new branch 'version2'
Git Aliases
Git doesn’t automatically infer your command if you type it in partially. If you don’t want to type the entire text of each of the Git commands, you can easily set up an alias for each command using git config. Here are a couple of examples you may want to set up:
$ git config --global alias.co checkout
$ git config --global alias.br branch
$ git config --global alias.ci commit
$ git config --global alias.st status
This means that, for example, instead of typing git commit, you just need to type git ci.
This technique can also be very useful in creating commands that you think should exist. For example, to correct the usability problem you encountered with unstaging a file, you can add your own unstage alias to Git:
$ git config --global alias.unstage 'reset HEAD --'
This makes the following two commands equivalent:
$ git unstage fileA
$ git reset HEAD -- fileA
$ git config --global alias.last 'log -1 HEAD'
$ git last
commit 66938dae3329c7aebe598c2246a8e6af90d04646
Author: Josh Goebel <dreamer3@example.com>
Date: Tue Aug :: + test for current head Signed-off-by: Scott Chacon <schacon@example.com>
However, maybe you want to run an external command, rather than a Git subcommand. In that case, you start the command with a ! character. This is useful if you write your own tools that work with a Git repository. We can demonstrate by aliasing git visual to run gitk:
$ git config --global alias.visual '!gitk'
Summary
Pro Git - 笔记2的更多相关文章
- Pro Git - 笔记3
Git Branching Branches in a Nutshell Branches in a Nutshell let’s assume that you have a directory c ...
- Pro Git - 笔记1
Getting Started About Version Control Local Version Control Systems Centralized Version Control Syst ...
- Pro Git 第一章 起步 读书笔记
Pro Git 笔记 第1章 起步 1.文件的三种状态. 已提交:文件已经保存在本地数据库中了.(commit) 已修改:修改了某个文件,但还没有提交保存.(vim) 已暂存:已经把已修改的文件放在下 ...
- 《Pro Git》笔记3:分支基本操作
<Pro Git>笔记3:Git分支基本操作 分支使多线开发和合并非常容易.Git的分支就是一个指向提交对象的可变指针,极其轻量.Git的默认分支为master. 1.Git数据存储结构和 ...
- 【Tools】Pro Git 一二章读书笔记
记得知乎以前有个问题说:如果用一天的时间学习一门技能,选什么好?里面有个说学会Git是个很不错选择,今天就抽时间感受下Git的魅力吧. Pro Git (Scott Chacon) 读书笔记: ...
- Git Pro读书笔记
本文为Git Pro读书笔记,所有内容均来自Git Pro 1 Git基础 1.1 记录每次更新到仓库 在Git里,文件有4种状态,modified, staged, commited, 还有一种状态 ...
- [Git00] Pro Git 一二章读书笔记
记得知乎以前有个问题说:如果用一天的时间学习一门技能,选什么好?里面有个说学会Git是个很不错选择,今天就抽时间感受下Git的魅力吧. Pro Git (Scott Chacon) 读书笔记: ...
- Pro Git 学习笔记
Pro Git 学习笔记 文档地址:Pro Git原文地址:PRO GIT 学习笔记 git常见命令 1.Git起步 初次运行Git前的配置 用户信息 git config --global user ...
- 《Pro Git》阅读随想
之前做版本管理,我使用最多的是SVN,而且也只是在用一些最常用的操作.最近公司里很多项目都开始上Git,借这个机会,我计划好好学习一下Git的操作和原理,以及蕴含在其中的设计思想.同事推荐了一本< ...
随机推荐
- java容易混淆的的内部类相关概念
关于内部类: 作用: 1. 内部类提供了更好的封装,可以把内部类隐藏在外部类之内,不允许同一个包中的其他类访问该类 2. 内部类的方法可以直接访问外部类的所有数据,包括私有的数据 3. 内部类所实现的 ...
- golang-Tag
Tag 理解 Golang中可以对struct定义Tag 例如: type TestTag struct{ UserName string `json:"name"` Age In ...
- 第一次写C语言小程序,可以初步理解学生成绩管理系统的概念
1 成绩管理系统概述 1.1 管理信息系统的概念 管理信息系统(Management Information Systems,简称MIS),是一个不断发展的新型学科,MIS的定义随着科技的进步也在 ...
- js前台加密,java后端解密
1.前台JS <script type="text/javascript"> $(function() { $(" ...
- shell的命令格式
参考高峻峰 著 循序渐进Linux(第二版) command [options] [arguments] command:表示命令的名称 options:表示命令的选项 arguments:表示命令的 ...
- springMVC-RESTful约束下dispatcher拦截对象优化
警告: No mapping found for HTTP request with URI [/management/fonts/glyphicons-halflings-regular.woff] ...
- linux系统基础之---账号管理(基于centos7.4 1708)
- Java OOP——第二章 继承
1. 继承: ●继承是面向对象的三大特征之一,是JAVA实现代码重用的重要手段之一: ●继承是代码重用的一种方式,将子类共有的属性和行为放到父类中: ●JAVA只支持单继承,即每一个类只有一个父类,继 ...
- vue组件的基本知识点
1. 组件中 is 的特性: 有些 HTML 元素,诸如 <ul>.<ol>.<table> 和 <select>,对于哪些元素可以出现在其内部是有严格 ...
- 652. Find Duplicate Subtrees
/** * Definition for a binary tree node. * struct TreeNode { * int val; * TreeNode *left; * TreeNode ...