hadoop自定义数据类型
统计某手机数据库的每个手机号的上行数据包数量和下行数据包数量
数据库类型如下:
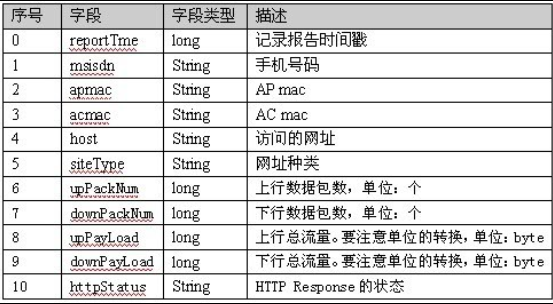
数据库内容如下:
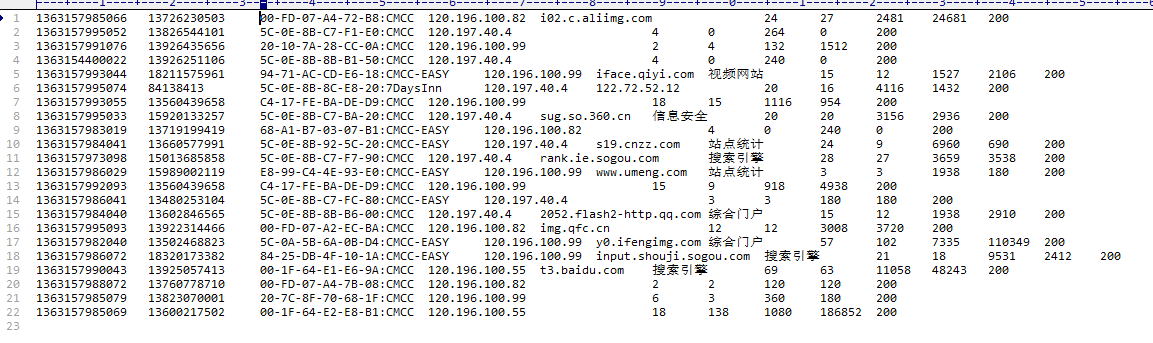
下面自定义类型SimLines,类似于平时编写的model
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException; import org.apache.hadoop.io.Writable; public class SimLines implements Writable { long upPackNum, downPackNum; public SimLines(){
super();
} public SimLines(String upPackNum, String downPackNum) {
super();
this.upPackNum = Long.parseLong(upPackNum);
this.downPackNum = Long.parseLong(downPackNum);
} //反序列化
@Override
public void readFields(DataInput in) throws IOException {
this.upPackNum = in.readLong();
this.downPackNum = in.readLong();
} //序列化
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upPackNum);
out.writeLong(downPackNum);
} public String toString(){
return upPackNum + "\t" + downPackNum;
}
}
注意:write方法中的顺序和readFields中的顺序要相同
其中的空构造方法一定要写,不然会报错或者反序列化步骤不执行。还有toString方法也必须定义,不然最后输的东西会很头疼的,不信你可以试试。
下面是hadoop的功能代码
import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { static final String INPUT_PATH = "F:/Tutorial/Hadoop/TestData/data/HTTP_20130313143750.dat";
static final String OUTPUT_PATH = "hdfs://masters:9000/user/hadoop/output/TestPhone";
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException { //添加以下的代码,就可以联通,不知道咋回事
String path = new File(".").getCanonicalPath();
System.getProperties().put("hadoop.home.dir", path);
new File("./bin").mkdirs();
new File("./bin/winutils.exe").createNewFile(); Configuration conf = new Configuration();
Path outpath = new Path(OUTPUT_PATH); //检测输出路径是否存在,如果存在就删除,否则会报错
FileSystem fileSystem = FileSystem.get(new URI(OUTPUT_PATH), conf);
if(fileSystem.exists(outpath)){
fileSystem.delete(outpath, true);
} Job job = new Job(conf, "SimLines"); FileInputFormat.setInputPaths(job, INPUT_PATH);
FileOutputFormat.setOutputPath(job, outpath); job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(SimLines.class);
job.waitForCompletion(true);
} //输入,map,即拆分过程
static class MyMapper extends Mapper<LongWritable, Text, Text, SimLines>{ protected void map(LongWritable k1, Text v1, Context context)throws IOException, InterruptedException{
String[] splits = v1.toString().split("\t");//按照空格拆分
Text k2 = new Text(splits[1]);
SimLines simLines = new SimLines(splits[6], splits[7]);
context.write(k2, simLines);
}
} //输出,reduce,汇总过程
static class MyReducer extends Reducer<Text, SimLines, Text, SimLines>{
protected void reduce(
Text k2, //输出的内容,即value
Iterable<SimLines> v2s, //是一个longwritable类型的数组,所以用了Iterable这个迭代器,且元素为v2s
org.apache.hadoop.mapreduce.Reducer<Text, SimLines, Text, SimLines>.Context context)
//这里一定设置好,不然输出会变成单个单词,从而没有统计数量
throws IOException, InterruptedException {
//列表求和 初始为0
long upPackNum = 0L, downPackNum = 0L;
for(SimLines simLines:v2s){
upPackNum += simLines.upPackNum;
downPackNum += simLines.downPackNum;
}
SimLines v3 = new SimLines(upPackNum + "", downPackNum + "");
context.write(k2, v3);
}
}
}
这样就ok了,结果如下:
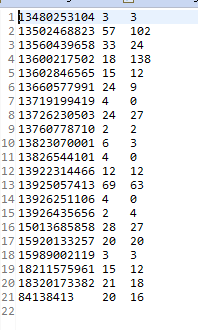
hadoop自定义数据类型的更多相关文章
- hadoop的自定义数据类型和与关系型数据库交互
最近有一个需求就是在建模的时候,有少部分数据是postgres的,只能读取postgres里面的数据到hadoop里面进行建模测试,而不能导出数据到hdfs上去. 读取postgres里面的数据库有两 ...
- Hadoop MapReduce自定义数据类型
一 自定义数据类型的实现 1.继承接口Writable,实现其方法write()和readFields(), 以便该数据能被序列化后完成网络传输或文件输入/输出: 2.如果该数据需要作为主键key使用 ...
- Hadoop-MapReduce之自定义数据类型
以下是自定义的一个数据类型,有两个属性,一个是名称,一个是开始点(可以理解为单词和单词的位置) MR程序就不写了,请看WordCount程序. package cn.genekang.hadoop.m ...
- Hadoop自定义类型处理手机上网日志
job提交源码分析 在eclipse中的写的代码如何提交作业到JobTracker中的哪?(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 con ...
- 通过SQL Server自定义数据类型实现导入数据
写在前面 在看同事写的代码时看到了SQL Server中可以自定义数据类型,而且定义的是DataTable类型的数据类型. 后我想起了以前我们导入数据时要么是循环insert写入,要么是SqlBulk ...
- OSG 自定义数据类型 关键帧动画
OSG 自定义数据类型 关键帧动画 转自:http://blog.csdn.net/zhuyingqingfen/article/details/12651017 /* 1.创建一个AnimManag ...
- Oracle存储过程-自定义数据类型,集合,遍历取值
摘要 Oracle存储过程,自定义数据类型,集合,遍历取值 目录[-] 0.前言 1.Packages 2.Packages bodies 3.输出结果 0.前言 在Oracle的存储过程中,可能会遇 ...
- eclipse 提交作业到JobTracker Hadoop的数据类型要求必须实现Writable接口
问:在eclipse中的写的代码如何提交作业到JobTracker中的哪?答:(1)在eclipse中调用的job.waitForCompletion(true)实际上执行如下方法 connect() ...
- Oracle自定义数据类型 1
原文 oracle 自定义类型 type / create type 一 Oracle中的类型 类型有很多种,主要可以分为以下几类: 1.字符串类型.如:char.nchar.varchar2.nva ...
随机推荐
- RabbitMQ消息中间件极速入门与实战
1:初识RabbitMQ RabbitMQ是一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,RabbitMQ是使用Erlang语言来编写的,并且RabbitMQ是基于AM ...
- 20181009noip HZ EZ两校联考sum(莫队,组合数学)
题面戳这里 思路: noip考莫队???!!! 考场上死活没往这方面想啊!!!数据分治忘写endl50pts滚粗了 这里每个询问都有n,m两个参数 我们可以把它看做常规莫队中的l和r 然后利用组合数的 ...
- React学习(3)——Router路由的使用和页面跳转
React-Router的中文文档可以参照如下链接: http://react-guide.github.io/react-router-cn/docs/Introduction.html 文档中介绍 ...
- 吐血分享:QQ群霸屏技术教程2017(问题篇)
霸屏技术,问题篇后,暂时搁置,尔望后续. 这里针对操作中,经常遇到的问题,做个简单整理. 回忆下,排名流程. 1.建群,品牌产品群,做任何关键词都是品牌产品群,皆因其有独特的优势. 2.拉人,填充群人 ...
- vm 中 centOS 7 固定ip设置
虚拟机中,centOS通过NAT连接,设置固定IP上网. 本地主机 VMware Network Adapter VMnet8 状态信息: 描述: VMware Virtual Ethernet A ...
- 转译符,re模块,random模块
一, 转译符 1.python 中的转译符 正则表达式中的内容在Python中就是字符串 ' \n ' : \ 转移符赋予了这个n一个特殊意义,表示一个换行符 ' \ \ n' : \ \ 表示取 ...
- Linux命令备忘录:quota显示磁盘已使用的空间与限制
quota命令用于显示用户或者工作组的磁盘配额信息.输出信息包括磁盘使用和配额限制. 语法 quota(选项)(参数) 选项 -g:列出群组的磁盘空间限制: -q:简明列表,只列出超过限制的部分: - ...
- 141. 环形链表 LeetCode报错:runtime error: member access within null pointer of type 'struct ListNode'
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode ...
- Python3 利用pip安装BeautifulSoup4模块(Windows版)
一.找到Python3的安装文件夹 二.将路径复制 三.Windows10 打开Windows PowerShell(管理员).Windows 8.8.1.7使用cmd 切换到相应目录 四.此目录下的 ...
- 43-Identity MVC:UI
1-打开之前写的MvcCookieAuthSample项目, 在AccountController新加Register,Login方法 public class AccountController : ...