利用calibre抓取新闻
Adding your favorite news website
calibre has a powerful, flexible and easy-to-use framework for downloading news from the Internet and converting it into an ebook. The following will show you, by means of examples, how to get news from various websites.
To gain an understanding of how to use the framework, follow the examples in the order listed below:
Completely automatic fetching
If your news source is simple enough, calibre may well be able to fetch it completely automatically, all you need to do is provide the URL. calibre gathers all the information needed to download a news source into a recipe. In order to tell calibre about a news source, you have to create a recipe for it. Let’s see some examples:
portfolio.com
portfolio.com is the website for Condé Nast Portfolio, a business related magazine. In order to download articles from the magazine and convert them to ebooks, we rely on the RSS feeds of portfolio.com. A list of such feeds is available at http://www.portfolio.com/rss/.
Lets pick a couple of feeds that look interesting:
- Business Travel: http://feeds.portfolio.com/portfolio/businesstravel
- Tech Observer: http://feeds.portfolio.com/portfolio/thetechobserver
I got the URLs by clicking the little orange RSS icon next to each feed name. To make calibre download the feeds and convert them into an ebook, you should right click the Fetch news button and then the Add a custom news source menu item. A dialog similar to that shown below should open up.
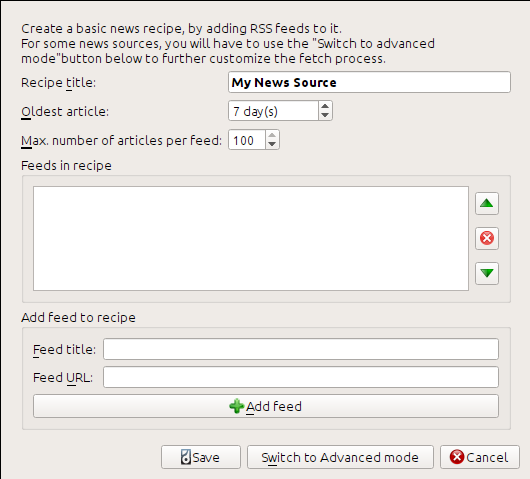
First enter Portfolio into the Recipe title field. This will be the title of the ebook that will be created from the articles in the above feeds.
The next two fields (Oldest article and Max. number of articles) allow you some control over how many articles should be downloaded from each feed, and they are pretty self explanatory.
To add the feeds to the recipe, enter the feed title and the feed URL and click the Add feed button. Once you have added both feeds, simply click the Add/update recipe button and you’re done! Close the dialog.
To test your new recipe, click the Fetch news button and in the Custom news sources sub-menu click Portfolio. After a couple of minutes, the newly downloaded Portfolio ebook will appear in the main library view (if you have your reader connected, it will be put onto the reader instead of into the library). Select it and hit the View button to read!
The reason this worked so well, with so little effort is that portfolio.com provides full-content RSS feeds, i.e., the article content is embedded in the feed itself. For most news sources that provide news in this fashion, with full-content feeds, you don’t need any more effort to convert them to ebooks. Now we will look at a news source that does not provide full content feeds. In such feeds, the full article is a webpage and the feed only contains a link to the webpage with a short summary of the article.
bbc.co.uk
Lets try the following two feeds from The BBC:
Follow the procedure outlined in portfolio.com to create a recipe for The BBC (using the feeds above). Looking at the downloaded ebook, we see that calibre has done a creditable job of extracting only the content you care about from each article’s webpage. However, the extraction process is not perfect. Sometimes it leaves in undesirable content like menus and navigation aids or it removes content that should have been left alone, like article headings. In order, to have perfect content extraction, we will need to customize the fetch process, as described in the next section.
Customizing the fetch process
When you want to perfect the download process, or download content from a particularly complex website, you can avail yourself of all the power and flexibility of the recipe framework. In order to do that, in the Add custom news sources dialog, simply click the Switch to Advanced mode button.
The easiest and often most productive customization is to use the print version of the online articles. The print version typically has much less cruft and translates much more smoothly to an ebook. Let’s try to use the print version of the articles from The BBC.
Using the print version of bbc.co.uk
The first step is to look at the ebook we downloaded previously from bbc.co.uk. At the end of each article, in the ebook is a little blurb telling you where the article was downloaded from. Copy and paste that URL into a browser. Now on the article webpage look for a link that points to the “Printable version”. Click it to see the print version of the article. It looks much neater! Now compare the two URLs. For me they were:
So it looks like to get the print version, we need to prefix every article URL with:
newsvote.bbc.co.uk/mpapps/pagetools/print/
Now in the Advanced Mode of the Custom news sources dialog, you should see something like (remember to select The BBC recipe before switching to advanced mode):
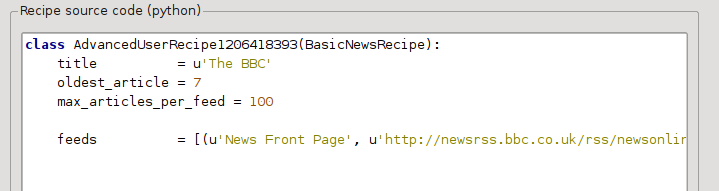
You can see that the fields from the Basic mode have been translated to python code in a straightforward manner. We need to add instructions to this recipe to use the print version of the articles. All that’s needed is to add the following two lines:
def print_version(self, url):
return url.replace('http://', 'http://newsvote.bbc.co.uk/mpapps/pagetools/print/')
This is python, so indentation is important. After you’ve added the lines, it should look like:
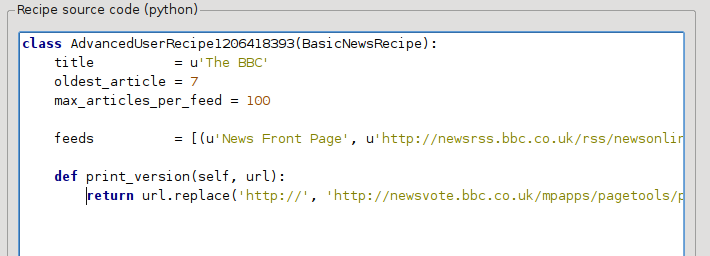
In the above, def print_version(self, url) defines a method that is called by calibre for every article. url is the URL of the original article. What print_version does is take that url and replace it with the new URL that points to the print version of the article. To learn about python see the tutorial.
Now, click the Add/update recipe button and your changes will be saved. Re-download the ebook. You should have a much improved ebook. One of the problems with the new version is that the fonts on the print version webpage are too small. This is automatically fixed when converting to an ebook, but even after the fixing process, the font size of the menus and navigation bar to become too large relative to the article text. To fix this, we will do some more customization, in the next section.
Replacing article styles
In the previous section, we saw that the font size for articles from the print version of The BBC was too small. In most websites, The BBC included, this font size is set by means of CSS stylesheets. We can disable the fetching of such stylesheets by adding the line:
no_stylesheets = True
The recipe now looks like:
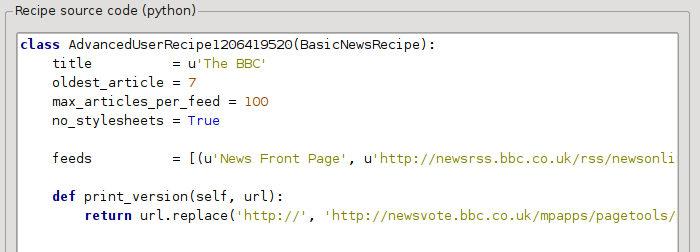
The new version looks pretty good. If you’re a perfectionist, you’ll want to read the next section, which deals with actually modifying the downloaded content.
Slicing and dicing
calibre contains very powerful and flexible abilities when it comes to manipulating downloaded content. To show off a couple of these, let’s look at our old friend the The BBC recipe again. Looking at the source code (HTML) of a couple of articles (print version), we see that they have a footer that contains no useful information, contained in
<div class="footer">
...
</div>
This can be removed by adding:
remove_tags = [dict(name='div', attrs={'class':'footer'})]
to the recipe. Finally, lets replace some of the CSS that we disabled earlier, with our own CSS that is suitable for conversion to an ebook:
extra_css = '.headline {font-size: x-large;} \n .fact { padding-top: 10pt }'
With these additions, our recipe has become “production quality”, indeed it is very close to the actual recipe used by calibre for the BBC, shown below:
##
## Title: BBC News, Sport, and Blog Calibre Recipe
## Contact: mattst - jmstanfield@gmail.com
##
## License: GNU General Public License v3 - http://www.gnu.org/copyleft/gpl.html
## Copyright: mattst - jmstanfield@gmail.com
##
## Written: November 2011
## Last Edited: 2011-11-19
## __license__ = 'GNU General Public License v3 - http://www.gnu.org/copyleft/gpl.html'
__copyright__ = 'mattst - jmstanfield@gmail.com' '''
BBC News, Sport, and Blog Calibre Recipe
''' # Import the regular expressions module.
import re # Import the BasicNewsRecipe class which this class extends.
from calibre.web.feeds.recipes import BasicNewsRecipe class BBCNewsSportBlog(BasicNewsRecipe): #
# **** IMPORTANT USERS READ ME ****
#
# First select the feeds you want then scroll down below the feeds list
# and select the values you want for the other user preferences, like
# oldest_article and such like.
#
#
# Select the BBC rss feeds which you want in your ebook.
# Selected feed have NO '#' at their start, de-selected feeds begin with a '#'.
#
# Eg. ("News Home", "http://feeds.bbci.co.uk/... - include feed.
# Eg. #("News Home", "http://feeds.bbci.co.uk/... - do not include feed.
#
# There are 68 feeds below which constitute the bulk of the available rss
# feeds on the BBC web site. These include 5 blogs by editors and
# correspondants, 16 sports feeds, 15 'sub' regional feeds (Eg. North West
# Wales, Scotland Business), and 7 Welsh language feeds.
#
# Some of the feeds are low volume (Eg. blogs), or very low volume (Eg. Click)
# so if "oldest_article = 1.5" (only articles published in the last 36 hours)
# you may get some 'empty feeds' which will not then be included in the ebook.
#
# The 15 feeds currently selected below are simply my default ones.
#
# Note: With all 68 feeds selected, oldest_article set to 2,
# max_articles_per_feed set to 100, and simultaneous_downloads set to 10,
# the ebook creation took 29 minutes on my speedy 100 mbps net connection,
# fairly high-end desktop PC running Linux (Ubuntu Lucid-Lynx).
# More realistically with 15 feeds selected, oldest_article set to 1.5,
# max_articles_per_feed set to 100, and simultaneous_downloads set to 20,
# it took 6 minutes. If that's too slow increase 'simultaneous_downloads'.
#
# Select / de-select the feeds you want in your ebook.
#
feeds = [
("News Home", "http://feeds.bbci.co.uk/news/rss.xml"),
("UK", "http://feeds.bbci.co.uk/news/uk/rss.xml"),
("World", "http://feeds.bbci.co.uk/news/world/rss.xml"),
#("England", "http://feeds.bbci.co.uk/news/england/rss.xml"),
#("Scotland", "http://feeds.bbci.co.uk/news/scotland/rss.xml"),
#("Wales", "http://feeds.bbci.co.uk/news/wales/rss.xml"),
#("N. Ireland", "http://feeds.bbci.co.uk/news/northern_ireland/rss.xml"),
#("Africa", "http://feeds.bbci.co.uk/news/world/africa/rss.xml"),
#("Asia", "http://feeds.bbci.co.uk/news/world/asia/rss.xml"),
#("Europe", "http://feeds.bbci.co.uk/news/world/europe/rss.xml"),
#("Latin America", "http://feeds.bbci.co.uk/news/world/latin_america/rss.xml"),
#("Middle East", "http://feeds.bbci.co.uk/news/world/middle_east/rss.xml"),
("US & Canada", "http://feeds.bbci.co.uk/news/world/us_and_canada/rss.xml"),
("Politics", "http://feeds.bbci.co.uk/news/politics/rss.xml"),
("Science/Environment", "http://feeds.bbci.co.uk/news/science_and_environment/rss.xml"),
("Technology", "http://feeds.bbci.co.uk/news/technology/rss.xml"),
("Magazine", "http://feeds.bbci.co.uk/news/magazine/rss.xml"),
("Entertainment/Arts", "http://feeds.bbci.co.uk/news/entertainment_and_arts/rss.xml"),
#("Health", "http://feeds.bbci.co.uk/news/health/rss.xml"),
#("Education/Family", "http://feeds.bbci.co.uk/news/education/rss.xml"),
("Business", "http://feeds.bbci.co.uk/news/business/rss.xml"),
("Special Reports", "http://feeds.bbci.co.uk/news/special_reports/rss.xml"),
("Also in the News", "http://feeds.bbci.co.uk/news/also_in_the_news/rss.xml"),
#("Newsbeat", "http://www.bbc.co.uk/newsbeat/rss.xml"),
#("Click", "http://newsrss.bbc.co.uk/rss/newsonline_uk_edition/programmes/click_online/rss.xml"),
("Blog: Nick Robinson (Political Editor)", "http://feeds.bbci.co.uk/news/correspondents/nickrobinson/rss.sxml"),
#("Blog: Mark D'Arcy (Parliamentary Correspondent)", "http://feeds.bbci.co.uk/news/correspondents/markdarcy/rss.sxml"),
#("Blog: Robert Peston (Business Editor)", "http://feeds.bbci.co.uk/news/correspondents/robertpeston/rss.sxml"),
#("Blog: Stephanie Flanders (Economics Editor)", "http://feeds.bbci.co.uk/news/correspondents/stephanieflanders/rss.sxml"),
("Blog: Rory Cellan-Jones (Technology correspondent)", "http://feeds.bbci.co.uk/news/correspondents/rorycellanjones/rss.sxml"),
("Sport Front Page", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/front_page/rss.xml"),
#("Football", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/football/rss.xml"),
#("Cricket", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/cricket/rss.xml"),
#("Rugby Union", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/rugby_union/rss.xml"),
#("Rugby League", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/rugby_league/rss.xml"),
#("Tennis", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/tennis/rss.xml"),
#("Golf", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/golf/rss.xml"),
#("Motorsport", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/motorsport/rss.xml"),
#("Boxing", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/boxing/rss.xml"),
#("Athletics", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/athletics/rss.xml"),
#("Snooker", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/other_sports/snooker/rss.xml"),
#("Horse Racing", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/other_sports/horse_racing/rss.xml"),
#("Cycling", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/other_sports/cycling/rss.xml"),
#("Disability Sport", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/other_sports/disability_sport/rss.xml"),
#("Other Sport", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/other_sports/rss.xml"),
#("Olympics 2012", "http://newsrss.bbc.co.uk/rss/sportonline_uk_edition/other_sports/olympics_2012/rss.xml"),
#("N. Ireland Politics", "http://feeds.bbci.co.uk/news/northern_ireland/northern_ireland_politics/rss.xml"),
#("Scotland Politics", "http://feeds.bbci.co.uk/news/scotland/scotland_politics/rss.xml"),
#("Scotland Business", "http://feeds.bbci.co.uk/news/scotland/scotland_business/rss.xml"),
#("E. Scotland, Edinburgh & Fife", "http://feeds.bbci.co.uk/news/scotland/edinburgh_east_and_fife/rss.xml"),
#("W. Scotland & Glasgow", "http://feeds.bbci.co.uk/news/scotland/glasgow_and_west/rss.xml"),
#("Highlands & Islands", "http://feeds.bbci.co.uk/news/scotland/highlands_and_islands/rss.xml"),
#("NE. Scotland, Orkney & Shetland", "http://feeds.bbci.co.uk/news/scotland/north_east_orkney_and_shetland/rss.xml"),
#("South Scotland", "http://feeds.bbci.co.uk/news/scotland/south_scotland/rss.xml"),
#("Central Scotland & Tayside", "http://feeds.bbci.co.uk/news/scotland/tayside_and_central/rss.xml"),
#("Wales Politics", "http://feeds.bbci.co.uk/news/wales/wales_politics/rss.xml"),
#("NW. Wales", "http://feeds.bbci.co.uk/news/wales/north_west_wales/rss.xml"),
#("NE. Wales", "http://feeds.bbci.co.uk/news/wales/north_east_wales/rss.xml"),
#("Mid. Wales", "http://feeds.bbci.co.uk/news/wales/mid_wales/rss.xml"),
#("SW. Wales", "http://feeds.bbci.co.uk/news/wales/south_west_wales/rss.xml"),
#("SE. Wales", "http://feeds.bbci.co.uk/news/wales/south_east_wales/rss.xml"),
#("Newyddion - News in Welsh", "http://feeds.bbci.co.uk/newyddion/rss.xml"),
#("Gwleidyddiaeth", "http://feeds.bbci.co.uk/newyddion/gwleidyddiaeth/rss.xml"),
#("Gogledd-Ddwyrain", "http://feeds.bbci.co.uk/newyddion/gogledd-ddwyrain/rss.xml"),
#("Gogledd-Orllewin", "http://feeds.bbci.co.uk/newyddion/gogledd-orllewin/rss.xml"),
#("Canolbarth", "http://feeds.bbci.co.uk/newyddion/canolbarth/rss.xml"),
#("De-Ddwyrain", "http://feeds.bbci.co.uk/newyddion/de-ddwyrain/rss.xml"),
#("De-Orllewin", "http://feeds.bbci.co.uk/newyddion/de-orllewin/rss.xml"),
] # **** SELECT YOUR USER PREFERENCES **** # Title to use for the ebook.
#
title = 'BBC News' # A brief description for the ebook.
#
description = u'BBC web site ebook created using rss feeds.' # The max number of articles which may be downloaded from each feed.
# I've never seen more than about 70 articles in a single feed in the
# BBC feeds.
#
max_articles_per_feed = 100 # The max age of articles which may be downloaded from each feed. This is
# specified in days - note fractions of days are allowed, Eg. 2.5 (2 and a
# half days). My default of 1.5 days is the last 36 hours, the point at
# which I've decided 'news' becomes 'old news', but be warned this is not
# so good for the blogs, technology, magazine, etc., and sports feeds.
# You may wish to extend this to 2-5 but watch out ebook creation time will
# increase as well. Setting this to 30 will get everything (AFAICT) as long
# as max_articles_per_feed remains set high (except for 'Click' which is
# v. low volume and its currently oldest article is 4th Feb 2011).
#
oldest_article = 1.5 # Number of simultaneous downloads. 20 is consistantly working fine on the
# BBC News feeds with no problems. Speeds things up from the defualt of 5.
# If you have a lot of feeds and/or have increased oldest_article above 2
# then you may wish to try increasing simultaneous_downloads to 25-30,
# Or, of course, if you are in a hurry. [I've not tried beyond 20.]
#
simultaneous_downloads = 20 # Timeout for fetching files from the server in seconds. The default of
# 120 seconds, seems somewhat excessive.
#
timeout = 30 # The format string for the date shown on the ebook's first page.
# List of all values: http://docs.python.org/library/time.html
# Default in news.py has a leading space so that's mirrored here.
# As with 'feeds' select/de-select by adding/removing the initial '#',
# only one timefmt should be selected, here's a few to choose from.
#
timefmt = ' [%a, %d %b %Y]' # [Fri, 14 Nov 2011] (Calibre default)
#timefmt = ' [%a, %d %b %Y %H:%M]' # [Fri, 14 Nov 2011 18:30]
#timefmt = ' [%a, %d %b %Y %I:%M %p]' # [Fri, 14 Nov 2011 06:30 PM]
#timefmt = ' [%d %b %Y]' # [14 Nov 2011]
#timefmt = ' [%d %b %Y %H:%M]' # [14 Nov 2011 18.30]
#timefmt = ' [%Y-%m-%d]' # [2011-11-14]
#timefmt = ' [%Y-%m-%d-%H-%M]' # [2011-11-14-18-30] #
# **** IMPORTANT ****
#
# DO NOT EDIT BELOW HERE UNLESS YOU KNOW WHAT YOU ARE DOING.
#
# DO NOT EDIT BELOW HERE UNLESS YOU KNOW WHAT YOU ARE DOING.
#
# I MEAN IT, YES I DO, ABSOLUTELY, AT YOU OWN RISK. :)
#
# **** IMPORTANT ****
# # Author of this recipe.
__author__ = 'mattst' # Specify English as the language of the RSS feeds (ISO-639 code).
language = 'en_GB' # Set tags.
tags = 'news, sport, blog' # Set publisher and publication type.
publisher = 'BBC'
publication_type = 'newspaper' # Disable stylesheets from site.
no_stylesheets = True # Specifies an override encoding for sites that have an incorrect charset
# specified. Default of 'None' says to auto-detect. Some other BBC recipes
# use 'utf8', which works fine (so use that if necessary) but auto-detecting
# with None is working fine, so stick with that for robustness.
encoding = None # Sets whether a feed has full articles embedded in it. The BBC feeds do not.
use_embedded_content = False # Removes empty feeds - why keep them!?
remove_empty_feeds = True # Create a custom title which fits nicely in the Kindle title list.
# Requires "import time" above class declaration, and replacing
# title with custom_title in conversion_options (right column only).
# Example of string below: "BBC News - 14 Nov 2011"
#
# custom_title = "BBC News - " + time.strftime('%d %b %Y') '''
# Conversion options for advanced users, but don't forget to comment out the
# current conversion_options below. Avoid setting 'linearize_tables' as that
# plays havoc with the 'old style' table based pages.
#
conversion_options = { 'title' : title,
'comments' : description,
'tags' : tags,
'language' : language,
'publisher' : publisher,
'authors' : publisher,
'smarten_punctuation' : True
}
''' conversion_options = { 'smarten_punctuation' : True } # Specify extra CSS - overrides ALL other CSS (IE. Added last).
extra_css = 'body { font-family: verdana, helvetica, sans-serif; } \
.introduction, .first { font-weight: bold; } \
.cross-head { font-weight: bold; font-size: 125%; } \
.cap, .caption { display: block; font-size: 80%; font-style: italic; } \
.cap, .caption, .caption img, .caption span { display: block; text-align: center; margin: 5px auto; } \
.byl, .byd, .byline img, .byline-name, .byline-title, .author-name, .author-position, \
.correspondent-portrait img, .byline-lead-in, .name, .bbc-role { display: block; \
text-align: center; font-size: 80%; font-style: italic; margin: 1px auto; } \
.story-date, .published { font-size: 80%; } \
table { width: 100%; } \
td img { display: block; margin: 5px auto; } \
ul { padding-top: 10px; } \
ol { padding-top: 10px; } \
li { padding-top: 5px; padding-bottom: 5px; } \
h1 { text-align: center; font-size: 175%; font-weight: bold; } \
h2 { text-align: center; font-size: 150%; font-weight: bold; } \
h3 { text-align: center; font-size: 125%; font-weight: bold; } \
h4, h5, h6 { text-align: center; font-size: 100%; font-weight: bold; }' # Remove various tag attributes to improve the look of the ebook pages.
remove_attributes = [ 'border', 'cellspacing', 'align', 'cellpadding', 'colspan',
'valign', 'vspace', 'hspace', 'alt', 'width', 'height' ] # Remove the (admittedly rarely used) line breaks, "<br />", which sometimes
# cause a section of the ebook to start in an unsightly fashion or, more
# frequently, a "<br />" will muck up the formatting of a correspondant's byline.
# "<br />" and "<br clear/>" are far more frequently used on the table formatted
# style of pages, and really spoil the look of the ebook pages.
preprocess_regexps = [(re.compile(r'<br[ ]*/>', re.IGNORECASE), lambda m: ''),
(re.compile(r'<br[ ]*clear.*/>', re.IGNORECASE), lambda m: '')] # Create regular expressions for tag keeping and removal to make the matches more
# robust against minor changes and errors in the HTML, Eg. double spaces, leading
# and trailing spaces, missing hyphens, and such like.
# Python regular expression ('re' class) page: http://docs.python.org/library/re.html # ***************************************
# Regular expressions for keep_only_tags:
# *************************************** # The BBC News HTML pages use variants of 'storybody' to denote the section of a HTML
# page which contains the main text of the article. Match storybody variants: 'storybody',
# 'story-body', 'story body','storybody ', etc.
storybody_reg_exp = '^.*story[_ -]*body.*$' # The BBC sport and 'newsbeat' (features) HTML pages use 'blq_content' to hold the title
# and published date. This is one level above the usual news pages which have the title
# and date within 'story-body'. This is annoying since 'blq_content' must also be kept,
# resulting in a lot of extra things to be removed by remove_tags.
blq_content_reg_exp = '^.*blq[_ -]*content.*$' # The BBC has an alternative page design structure, which I suspect is an out-of-date
# design but which is still used in some articles, Eg. 'Click' (technology), 'FastTrack'
# (travel), and in some sport pages. These alternative pages are table based (which is
# why I think they are an out-of-date design) and account for -I'm guesstimaking- less
# than 1% of all articles. They use a table class 'storycontent' to hold the article
# and like blq_content (above) have required lots of extra removal by remove_tags.
story_content_reg_exp = '^.*story[_ -]*content.*$' # Keep the sections of the HTML which match the list below. The HTML page created by
# Calibre will fill <body> with those sections which are matched. Note that the
# blq_content_reg_exp must be listed before storybody_reg_exp in keep_only_tags due to
# it being the parent of storybody_reg_exp, that is to say the div class/id 'story-body'
# will be inside div class/id 'blq_content' in the HTML (if 'blq_content' is there at
# all). If they are the other way around in keep_only_tags then blq_content_reg_exp
# will end up being discarded.
keep_only_tags = [ dict(name='table', attrs={'class':re.compile(story_content_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(blq_content_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'id':re.compile(blq_content_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(storybody_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'id':re.compile(storybody_reg_exp, re.IGNORECASE)}) ] # ************************************
# Regular expressions for remove_tags:
# ************************************ # Regular expression to remove share-help and variant tags. The share-help class
# is used by the site for a variety of 'sharing' type links, Eg. Facebook, delicious,
# twitter, email. Removed to avoid page clutter.
share_help_reg_exp = '^.*share[_ -]*help.*$' # Regular expression to remove embedded-hyper and variant tags. This class is used to
# display links to other BBC News articles on the same/similar subject.
embedded_hyper_reg_exp = '^.*embed*ed[_ -]*hyper.*$' # Regular expression to remove hypertabs and variant tags. This class is used to
# display a tab bar at the top of an article which allows the user to switch to
# an article (viewed on the same page) providing further info., 'in depth' analysis,
# an editorial, a correspondant's blog entry, and such like. The ability to handle
# a tab bar of this nature is currently beyond the scope of this recipe and
# possibly of Calibre itself (not sure about that - TO DO - check!).
hypertabs_reg_exp = '^.*hyper[_ -]*tabs.*$' # Regular expression to remove story-feature and variant tags. Eg. 'story-feature',
# 'story-feature related narrow', 'story-feature wide', 'story-feature narrow'.
# This class is used to add additional info. boxes, or small lists, outside of
# the main story. TO DO: Work out a way to incorporate these neatly.
story_feature_reg_exp = '^.*story[_ -]*feature.*$' # Regular expression to remove video and variant tags, Eg. 'videoInStoryB',
# 'videoInStoryC'. This class is used to embed video.
video_reg_exp = '^.*video.*$' # Regular expression to remove audio and variant tags, Eg. 'audioInStoryD'.
# This class is used to embed audio.
audio_reg_exp = '^.*audio.*$' # Regular expression to remove pictureGallery and variant tags, Eg. 'pictureGallery'.
# This class is used to embed a photo slideshow. See also 'slideshow' below.
picture_gallery_reg_exp = '^.*picture.*$' # Regular expression to remove slideshow and variant tags, Eg. 'dslideshow-enclosure'.
# This class is used to embed a slideshow (not necessarily photo) but both
# 'slideshow' and 'pictureGallery' are used for slideshows.
slideshow_reg_exp = '^.*slide[_ -]*show.*$' # Regular expression to remove social-links and variant tags. This class is used to
# display links to a BBC bloggers main page, used in various columnist's blogs
# (Eg. Nick Robinson, Robert Preston).
social_links_reg_exp = '^.*social[_ -]*links.*$' # Regular expression to remove quote and (multi) variant tags, Eg. 'quote',
# 'endquote', 'quote-credit', 'quote-credit-title', etc. These are usually
# removed by 'story-feature' removal (as they are usually within them), but
# not always. The quotation removed is always (AFAICT) in the article text
# as well but a 2nd copy is placed in a quote tag to draw attention to it.
# The quote class tags may or may not appear in div's.
quote_reg_exp = '^.*quote.*$' # Regular expression to remove hidden and variant tags, Eg. 'hidden'.
# The purpose of these is unclear, they seem to be an internal link to a
# section within the article, but the text of the link (Eg. 'Continue reading
# the main story') never seems to be displayed anyway. Removed to avoid clutter.
# The hidden class tags may or may not appear in div's.
hidden_reg_exp = '^.*hidden.*$' # Regular expression to remove comment and variant tags, Eg. 'comment-introduction'.
# Used on the site to display text about registered users entering comments.
comment_reg_exp = '^.*comment.*$' # Regular expression to remove form and variant tags, Eg. 'comment-form'.
# Used on the site to allow registered BBC users to fill in forms, typically
# for entering comments about an article.
form_reg_exp = '^.*form.*$' # Extra things to remove due to the addition of 'blq_content' in keep_only_tags. #<div class="story-actions"> Used on sports pages for 'email' and 'print'.
story_actions_reg_exp = '^.*story[_ -]*actions.*$' #<div class="bookmark-list"> Used on sports pages instead of 'share-help' (for
# social networking links).
bookmark_list_reg_exp = '^.*bookmark[_ -]*list.*$' #<div id="secondary-content" class="content-group">
# NOTE: Don't remove class="content-group" that is needed.
# Used on sports pages to link to 'similar stories'.
secondary_content_reg_exp = '^.*secondary[_ -]*content.*$' #<div id="featured-content" class="content-group">
# NOTE: Don't remove class="content-group" that is needed.
# Used on sports pages to link to pages like 'tables', 'fixtures', etc.
featured_content_reg_exp = '^.*featured[_ -]*content.*$' #<div id="navigation">
# Used on sports pages to link to pages like 'tables', 'fixtures', etc.
# Used sometimes instead of "featured-content" above.
navigation_reg_exp = '^.*navigation.*$' #<a class="skip" href="#blq-container-inner">Skip to top</a>
# Used on sports pages to link to the top of the page.
skip_reg_exp = '^.*skip.*$' # Extra things to remove due to the addition of 'storycontent' in keep_only_tags,
# which are the alterative table design based pages. The purpose of some of these
# is not entirely clear from the pages (which are a total mess!). # Remove mapping based tags, Eg. <map id="world_map">
# The dynamic maps don't seem to work during ebook creation. TO DO: Investigate.
map_reg_exp = '^.*map.*$' # Remove social bookmarking variation, called 'socialBookMarks'.
social_bookmarks_reg_exp = '^.*social[_ -]*bookmarks.*$' # Remove page navigation tools, like 'search', 'email', 'print', called 'blq-mast'.
blq_mast_reg_exp = '^.*blq[_ -]*mast.*$' # Remove 'sharesb', I think this is a generic 'sharing' class. It seems to appear
# alongside 'socialBookMarks' whenever that appears. I am removing it as well
# under the assumption that it can appear alone as well.
sharesb_reg_exp = '^.*sharesb.*$' # Remove class 'o'. The worst named user created css class of all time. The creator
# should immediately be fired. I've seen it used to hold nothing at all but with
# 20 or so empty lines in it. Also to hold a single link to another article.
# Whatever it was designed to do it is not wanted by this recipe. Exact match only.
o_reg_exp = '^o$' # Remove 'promotopbg' and 'promobottombg', link lists. Have decided to
# use two reg expressions to make removing this (and variants) robust.
promo_top_reg_exp = '^.*promotopbg.*$'
promo_bottom_reg_exp = '^.*promobottombg.*$' # Remove 'nlp', provides heading for link lists. Requires an exact match due to
# risk of matching those letters in something needed, unless I see a variation
# of 'nlp' used at a later date.
nlp_reg_exp = '^nlp$' # Remove 'mva', provides embedded floating content of various types. Variant 'mvb'
# has also now been seen. Requires an exact match of 'mva' or 'mvb' due to risk of
# matching those letters in something needed.
mva_or_mvb_reg_exp = '^mv[ab]$' # Remove 'mvtb', seems to be page navigation tools, like 'blq-mast'.
mvtb_reg_exp = '^mvtb$' # Remove 'blq-toplink', class to provide a link to the top of the page.
blq_toplink_reg_exp = '^.*blq[_ -]*top[_ -]*link.*$' # Remove 'products and services' links, Eg. desktop tools, alerts, and so on.
# Eg. class="servicev4 ukfs_services" - what a mess of a name. Have decided to
# use two reg expressions to make removing this (and variants) robust.
prods_services_01_reg_exp = '^.*servicev4.*$'
prods_services_02_reg_exp = '^.*ukfs[_ -]*services.*$' # Remove -what I think is- some kind of navigation tools helper class, though I am
# not sure, it's called: 'blq-rst blq-new-nav'. What I do know is it pops up
# frequently and it is not wanted. Have decided to use two reg expressions to make
# removing this (and variants) robust.
blq_misc_01_reg_exp = '^.*blq[_ -]*rst.*$'
blq_misc_02_reg_exp = '^.*blq[_ -]*new[_ -]*nav.*$' # Remove 'puffbox' - this may only appear inside 'storyextra', so it may not
# need removing - I have no clue what it does other than it contains links.
# Whatever it is - it is not part of the article and is not wanted.
puffbox_reg_exp = '^.*puffbox.*$' # Remove 'sibtbg' and 'sibtbgf' - some kind of table formatting classes.
sibtbg_reg_exp = '^.*sibtbg.*$' # Remove 'storyextra' - links to relevant articles and external sites.
storyextra_reg_exp = '^.*story[_ -]*extra.*$' remove_tags = [ dict(name='div', attrs={'class':re.compile(story_feature_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(share_help_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(embedded_hyper_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(hypertabs_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(video_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(audio_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(picture_gallery_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(slideshow_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(quote_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(hidden_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(comment_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(story_actions_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(bookmark_list_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'id':re.compile(secondary_content_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'id':re.compile(featured_content_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'id':re.compile(navigation_reg_exp, re.IGNORECASE)}),
dict(name='form', attrs={'id':re.compile(form_reg_exp, re.IGNORECASE)}),
dict(attrs={'class':re.compile(quote_reg_exp, re.IGNORECASE)}),
dict(attrs={'class':re.compile(hidden_reg_exp, re.IGNORECASE)}),
dict(attrs={'class':re.compile(social_links_reg_exp, re.IGNORECASE)}),
dict(attrs={'class':re.compile(comment_reg_exp, re.IGNORECASE)}),
dict(attrs={'class':re.compile(skip_reg_exp, re.IGNORECASE)}),
dict(name='map', attrs={'id':re.compile(map_reg_exp, re.IGNORECASE)}),
dict(name='map', attrs={'name':re.compile(map_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'id':re.compile(social_bookmarks_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'id':re.compile(blq_mast_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(sharesb_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(o_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(promo_top_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(promo_bottom_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(nlp_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(mva_or_mvb_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(mvtb_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(blq_toplink_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(prods_services_01_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(prods_services_02_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(blq_misc_01_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(blq_misc_02_reg_exp, re.IGNORECASE)}),
dict(name='div', attrs={'class':re.compile(puffbox_reg_exp, re.IGNORECASE)}),
dict(attrs={'class':re.compile(sibtbg_reg_exp, re.IGNORECASE)}),
dict(attrs={'class':re.compile(storyextra_reg_exp, re.IGNORECASE)})
] # Uses url to create and return the 'printer friendly' version of the url.
# In other words the 'print this page' address of the page.
#
# There are 3 types of urls used in the BBC site's rss feeds. There is just
# 1 type for the standard news while there are 2 used for sports feed urls.
# Note: Sports urls are linked from regular news feeds (Eg. 'News Home') when
# there is a major story of interest to 'everyone'. So even if no BBC sports
# feeds are added to 'feeds' the logic of this method is still needed to avoid
# blank / missing / empty articles which have an index title and then no body.
def print_version(self, url): # Handle sports page urls type 01:
if (url.find("go/rss/-/sport1/") != -1):
temp_url = url.replace("go/rss/-/", "") # Handle sports page urls type 02:
elif (url.find("go/rss/int/news/-/sport1/") != -1):
temp_url = url.replace("go/rss/int/news/-/", "") # Handle regular news page urls:
else:
temp_url = url.replace("go/rss/int/news/-/", "") # Always add "?print=true" to the end of the url.
print_url = temp_url + "?print=true" return print_url # Remove articles in feeds based on a string in the article title or url.
#
# Code logic written by: Starson17 - posted in: "Recipes - Re-usable code"
# thread, in post with title: "Remove articles from feed", see url:
# http://www.mobileread.com/forums/showpost.php?p=1165462&postcount=6
# Many thanks and all credit to Starson17.
#
# Starson17's code has obviously been altered to suite my requirements.
def parse_feeds(self): # Call parent's method.
feeds = BasicNewsRecipe.parse_feeds(self) # Loop through all feeds.
for feed in feeds: # Loop through all articles in feed.
for article in feed.articles[:]: # Match key words and remove article if there's a match. # Most BBC rss feed video only 'articles' use upper case 'VIDEO'
# as a title prefix. Just match upper case 'VIDEO', so that
# articles like 'Video game banned' won't be matched and removed.
if 'VIDEO' in article.title:
feed.articles.remove(article) # Most BBC rss feed audio only 'articles' use upper case 'AUDIO'
# as a title prefix. Just match upper case 'AUDIO', so that
# articles like 'Hi-Def audio...' won't be matched and removed.
elif 'AUDIO' in article.title:
feed.articles.remove(article) # Most BBC rss feed photo slideshow 'articles' use 'In Pictures',
# 'In pictures', and 'in pictures', somewhere in their title.
# Match any case of that phrase.
elif 'IN PICTURES' in article.title.upper():
feed.articles.remove(article) # As above, but user contributed pictures. Match any case.
elif 'YOUR PICTURES' in article.title.upper():
feed.articles.remove(article) # 'Sportsday Live' are articles which contain a constantly and
# dynamically updated 'running commentary' during a live sporting
# event. Match any case.
elif 'SPORTSDAY LIVE' in article.title.upper():
feed.articles.remove(article) # Sometimes 'Sportsday Live' (above) becomes 'Live - Sport Name'.
# These are being matched below using 'Live - ' because removing all
# articles with 'live' in their titles would remove some articles
# that are in fact not live sports pages. Match any case.
elif 'LIVE - ' in article.title.upper():
feed.articles.remove(article) # 'Quiz of the week' is a Flash player weekly news quiz. Match only
# the 'Quiz of the' part in anticipation of monthly and yearly
# variants. Match any case.
elif 'QUIZ OF THE' in article.title.upper():
feed.articles.remove(article) # Remove articles with 'scorecards' in the url. These are BBC sports
# pages which just display a cricket scorecard. The pages have a mass
# of table and css entries to display the scorecards nicely. Probably
# could make them work with this recipe, but might take a whole day
# of work to sort out all the css - basically a formatting nightmare.
elif 'scorecards' in article.url:
feed.articles.remove(article) return feeds # End of class and file.
This recipe explores only the tip of the iceberg when it comes to the power of calibre. To explore more of the abilities of calibre we’ll examine a more complex real life example in the next section.
Real life example
A reasonably complex real life example that exposes more of the API of BasicNewsRecipe is the recipe for The New York Times
import string, re
from calibre import strftime
from calibre.web.feeds.recipes import BasicNewsRecipe
from calibre.ebooks.BeautifulSoup import BeautifulSoup class NYTimes(BasicNewsRecipe): title = 'The New York Times'
__author__ = 'Kovid Goyal'
description = 'Daily news from the New York Times'
timefmt = ' [%a, %d %b, %Y]'
needs_subscription = True
remove_tags_before = dict(id='article')
remove_tags_after = dict(id='article')
remove_tags = [dict(attrs={'class':['articleTools', 'post-tools', 'side_tool', 'nextArticleLink clearfix']}),
dict(id=['footer', 'toolsRight', 'articleInline', 'navigation', 'archive', 'side_search', 'blog_sidebar', 'side_tool', 'side_index']),
dict(name=['script', 'noscript', 'style'])]
encoding = 'cp1252'
no_stylesheets = True
extra_css = 'h1 {font: sans-serif large;}\n.byline {font:monospace;}' def get_browser(self):
br = BasicNewsRecipe.get_browser()
if self.username is not None and self.password is not None:
br.open('http://www.nytimes.com/auth/login')
br.select_form(name='login')
br['USERID'] = self.username
br['PASSWORD'] = self.password
br.submit()
return br def parse_index(self):
soup = self.index_to_soup('http://www.nytimes.com/pages/todayspaper/index.html') def feed_title(div):
return ''.join(div.findAll(text=True, recursive=False)).strip() articles = {}
key = None
ans = []
for div in soup.findAll(True,
attrs={'class':['section-headline', 'story', 'story headline']}): if div['class'] == 'section-headline':
key = string.capwords(feed_title(div))
articles[key] = []
ans.append(key) elif div['class'] in ['story', 'story headline']:
a = div.find('a', href=True)
if not a:
continue
url = re.sub(r'\?.*', '', a['href'])
url += '?pagewanted=all'
title = self.tag_to_string(a, use_alt=True).strip()
description = ''
pubdate = strftime('%a, %d %b')
summary = div.find(True, attrs={'class':'summary'})
if summary:
description = self.tag_to_string(summary, use_alt=False) feed = key if key is not None else 'Uncategorized'
if not articles.has_key(feed):
articles[feed] = []
if not 'podcasts' in url:
articles[feed].append(
dict(title=title, url=url, date=pubdate,
description=description,
content=''))
ans = self.sort_index_by(ans, {'The Front Page':-1, 'Dining In, Dining Out':1, 'Obituaries':2})
ans = [(key, articles[key]) for key in ans if articles.has_key(key)]
return ans def preprocess_html(self, soup):
refresh = soup.find('meta', {'http-equiv':'refresh'})
if refresh is None:
return soup
content = refresh.get('content').partition('=')[2]
raw = self.browser.open('http://www.nytimes.com'+content).read()
return BeautifulSoup(raw.decode('cp1252', 'replace'))
We see several new features in this recipe. First, we have:
timefmt = ' [%a, %d %b, %Y]'
This sets the displayed time on the front page of the created ebook to be in the format, Day, Day_Number Month, Year. See timefmt.
Then we see a group of directives to cleanup the downloaded HTML:
remove_tags_before = dict(name='h1')
remove_tags_after = dict(id='footer')
remove_tags = ...
These remove everything before the first <h1> tag and everything after the first tag whose id is footer. See remove_tags, remove_tags_before, remove_tags_after.
The next interesting feature is:
needs_subscription = True
...
def get_browser(self):
...
needs_subscription = True tells calibre that this recipe needs a username and password in order to access the content. This causes, calibre to ask for a username and password whenever you try to use this recipe. The code in calibre.web.feeds.news.BasicNewsRecipe.get_browser() actually does the login into the NYT website. Once logged in, calibre will use the same, logged in, browser instance to fetch all content. See mechanize to understand the code in get_browser.
The next new feature is the calibre.web.feeds.news.BasicNewsRecipe.parse_index() method. Its job is to go to http://www.nytimes.com/pages/todayspaper/index.html and fetch the list of articles that appear in todays paper. While more complex than simply using RSS, the recipe creates an ebook that corresponds very closely to the days paper. parse_index makes heavy use of BeautifulSoup to parse the daily paper webpage.
The final new feature is the calibre.web.feeds.news.BasicNewsRecipe.preprocess_html() method. It can be used to perform arbitrary transformations on every downloaded HTML page. Here it is used to bypass the ads that the nytimes shows you before each article.
Tips for developing new recipes
The best way to develop new recipes is to use the command line interface. Create the recipe using your favorite python editor and save it to a file say myrecipe.recipe. The .recipe extension is required. You can download content using this recipe with the command:
ebook-convert myrecipe.recipe .epub --test -vv --debug-pipeline debug
The command ebook-convert will download all the webpages and save them to the EPUB file myrecipe.epub. The -vv makes ebook-convert spit out a lot of information about what it is doing. The --test makes it download only a couple of articles from at most two feeds. In addition, ebook-convert will put the downloaded HTML into the debug/input directory, where debug is the directory you specified in the --debug-pipeline option.
Once the download is complete, you can look at the downloaded HTML by opening the file debug/input/index.html in a browser. Once you’re satisfied that the download and preprocessing is happening correctly, you can generate ebooks in different formats as shown below:
ebook-convert myrecipe.recipe myrecipe.epub
ebook-convert myrecipe.recipe myrecipe.mobi
...
If you’re satisfied with your recipe, and you feel there is enough demand to justify its inclusion into the set of built-in recipes, post your recipe in the calibre recipes forum to share it with other calibre users.
Note
On OS X, the ebook-convert command will not be available by default. Go to Preferences->Miscellaneous and click the install command line tools button to make it available.
See also
- ebook-convert
- The command line interface for all ebook conversion.
Further reading
To learn more about writing advanced recipes using some of the facilities, available in BasicNewsRecipe you should consult the following sources:
- API Documentation
- Documentation of the BasicNewsRecipe class and all its important methods and fields.
- BasicNewsRecipe
- The source code of BasicNewsRecipe
- Built-in recipes
- The source code for the built-in recipes that come with calibre
- The calibre recipes forum
- Lots of knowledgeable calibre recipe writers hang out here.
利用calibre抓取新闻的更多相关文章
- 利用BeautifulSoup抓取新浪网页新闻的内容
第一次写的小爬虫,python确实功能很强大,二十来行的代码抓取内容并存储为一个txt文本 直接上代码 #coding = 'utf-8' import requests from bs4 impor ...
- 使用轻量级JAVA 爬虫Gecco工具抓取新闻DEMO
写在前面 最近看到Gecoo爬虫工具,感觉比较简单好用,所有写个DEMO测试一下,抓取网站 http://zj.zjol.com.cn/home.html,主要抓取新闻的标题和发布时间做为抓取测试对象 ...
- 利用Crowbar抓取网页异步加载的内容 [Python俱乐部]
利用Crowbar抓取网页异步加载的内容 [Python俱乐部] 利用Crowbar抓取网页异步加载的内容 在做 Web 信息提取.数据挖掘的过程中,一个关键步骤就是网页源代码的获取.但是出于各种原因 ...
- 利用Fiddler抓取websocket包
一.利用fiddler抓取websockt包 打开Fiddler,点开菜单栏的Rules,选择Customize Rules... 这时会打开CustomRules.js文件,在class Handl ...
- Python爬虫实战八之利用Selenium抓取淘宝匿名旺旺
更新 其实本文的初衷是为了获取淘宝的非匿名旺旺,在淘宝详情页的最下方有相关评论,含有非匿名旺旺号,快一年了淘宝都没有修复这个. 可就在今天,淘宝把所有的账号设置成了匿名显示,SO,获取非匿名旺旺号已经 ...
- 利用wireshark抓取远程linux上的数据包
原文发表在我的博客主页,转载请注明出处. 前言 因为出差,前后准备总结了一周多,所以博客有所搁置.出差真是累人的活计,不过确实可以学习到很多东西,跟着老板学习做人,学习交流的技巧.入正题~ wires ...
- 对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App)
对比使用Charles和Fiddler两个工具及利用Charles抓取https数据(App) 实验目的:对比使用Charles和Fiddler两个工具 实验对象:车易通App,易销通App 实验结果 ...
- 利用wget 抓取 网站网页 包括css背景图片
利用wget 抓取 网站网页 包括css背景图片 wget是一款非常优秀的http/ftp下载工具,它功能强大,而且几乎所有的unix系统上都有.不过用它来dump比较现代的网站会有一个问题:不支持c ...
- 利用scrapy抓取网易新闻并将其存储在mongoDB
好久没有写爬虫了,写一个scrapy的小爬爬来抓取网易新闻,代码原型是github上的一个爬虫,近期也看了一点mongoDB.顺便小用一下.体验一下NoSQL是什么感觉.言归正传啊.scrapy爬虫主 ...
随机推荐
- Gitlab简单使用指南
原文链接 一.在gitlab的网站创建一个project 定一个项目名,选定相关的项目设置,private,public等 项目创建成功后,得到项目git@XXX.git的地址,可用于将project ...
- css3响应式布局设计——回顾
响应式设计是在不同设备下分辨率不同显示的样式就不同. media 属性用于为不同的媒体类型规定不同的样式.根绝浏览器的宽度和高度重新渲染页面. 语法: @media mediatype and | n ...
- v-if和v-show的区别以及callback回调函数的体会
今天总结一下最近一周碰到的一些问题 一.v-if和v-show的区别 v-show用的是css属性中的display="block/none",元素被隐藏了但是节点还在页面中,但是 ...
- #leetcode刷题之路1-两数之和
给定两个整数,被除数 dividend 和除数 divisor.将两数相除,要求不使用乘法.除法和 mod 运算符.返回被除数 dividend 除以除数 divisor 得到的商. 示例 1:输入: ...
- PHP大数组,大文件的处理
[原文来自于转载, 但他的结论不太正确, 尤其对foreach的判断这块上, 我拎过来进行修理 ] 在做数据统计时,难免会遇到大数组,而处理大数据经常会发生内存溢出,这篇文章中,我们聊聊如何处 ...
- Linux的开山篇
一.Linux的学习方向 1.2Linux运维工程师 1.2.2Linux嵌入式开发工程师 1.2.3在Linux下做各种程序开发 javaEE 大数据 Python PHP C/ ...
- MySQL传输表空间使用方法
1.目标端创建同样的表结构 CREATE TABLE `test` ( `id` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHAR ...
- android发布帖子类技术
最近练习一些关于发布帖子的技术,说来也简单,就学了一点皮毛吧!好了,下面就上代码吧! 首先设计服务器的访问类,大家都知道现在东西都要联网的嘛! JSONParser的类: public class J ...
- Linux运维常用命令-linux服务器代维常用到的维护命令
1.删除0字节文件find -type f -size 0 -exec rm -rf {} ; 2.查看进程按内存从大到小排列ps -e -o "%C : %p : %z : %a& ...
- clear()、sync()、ignore()
#include <iostream> using namespace std; int main() { int a; cin>>a; cout<<cin.rds ...