Java8新特性(二)——强大的Stream API
一、强大的Stream API
除了Lambda表达式外,Java8另外一项重大更新便是位于java.util.stream.*下的Stream API
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对 集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。 使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数 据库查询。也可以使用 Stream API 来并行执行操作。简而言之, Stream API 提供了一种高效且易于使用的处理数据的方式。
什么是Stream
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。 “集合讲的是数据,流讲的是计算!
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。
接下来从三个流程讲解Stream的用法:创建——中间操作——终止操作
如何创建Stream
通过Collection集合家族的方法创建流
default Stream stream() : 返回一个顺序流
default Stream parallelStream() : 返回一个并行流
通过数组的静态方法(Arrays.stream())
static Stream stream(T[] array): 返回一个流
通过Stream的静态方法of()
public static Stream of(T... values) : 返回一个流
通过静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
迭代:public static Stream iterate(final T seed, final UnaryOperator f)
生成: public static Stream generate(Supplier s) :
对以上这些方式进行实例演示:
@Test
public void test1() {
// 1.通过集合得到流
List<String> list = new ArrayList<>();
Stream<String> stream = list.stream();
// 2.通过数组
Employee[] emps = new Employee[5];
Stream<Employee> stream1 = Arrays.stream(emps);
// 3.通过Stream的静态方法
Stream<String> stream2 = Stream.of("a", "b", "c");
// 4.通过Stream静态方法创建无限流
Stream<Integer> stream3 = Stream.iterate(0, (x) -> x + 2);
Stream<Double> stream4 = Stream.generate(Math::random);
}
中间操作
多个中间操作可以连接起来形成一个流水线,除非流水 线上触发终止操作,否则中间操作不会执行任何的处理! 而在终止操作时一次性全部处理,称为“惰性求值”。
大致可以分为:筛选与切片、映射、排序

我们依旧i通过示例来了解这几个操作:(结果已经通过测试,不再赘述)
// filter——通过Lambda表达式排除流中某些元素
@Test
public void test2() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小张", 18));
empList.add(new Employee("小明", 19));
empList.add(new Employee("小红", 20));
// 集合创建流
Stream<Employee> empStream = empList.stream().filter((e) -> e.getAge() > 18);
// 终止操作
empStream.forEach(System.out::println);
} // limit——截断流,使流不超过指定数量(与skip互补,暂不演示)
@Test
public void test3() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小张", 18));
empList.add(new Employee("小明", 19));
empList.add(new Employee("小红", 20));
// 注意这种写法
empList.stream().filter((e) -> e.getAge() < 20)
.limit(1)
.forEach(System.out::println);
}
// distinct——通过hashCode()和equals()实现去重
@Test
public void test4() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小张", 18));
empList.add(new Employee("小张", 18));
empList.add(new Employee("小红", 20));
// 去重操作
empList.stream()
.filter((e) -> e.getAge() < 19)
.distinct()
.forEach(System.out::println); }
映射

示例讲解:
// map——接收函数,将每个元素运用到函数上,映射为一个新的元素(flatMap见定义,不再赘述)
@Test
public void test5() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小张", 18));
empList.add(new Employee("小明", 19));
empList.add(new Employee("小红", 20));
// 映射操作,例如提取名字
empList.stream()
.map(Employee::getName)
.forEach(System.out::println); }
排序

示例讲解
// sorted——可以按自然排序(无参)或相应的比较器排序(参数为比较器)
@Test
public void test6() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小明", 18));
empList.add(new Employee("小张", 19));
empList.add(new Employee("小红", 20));
// 注意Employee没有自然排序方式!
empList.stream()
.sorted((e1, e2) -> {
// 若年龄相等,比较姓名
if (e1.getAge().equals(e2.getAge())) {
return e1.getName().compareTo(e2.getName());
}
// 年龄不等,直接比较年龄(加上符号,逆向排序)
return -(e1.getAge().compareTo(e2.getAge()));
})
.forEach(System.out::println); }
终止操作
查找与匹配
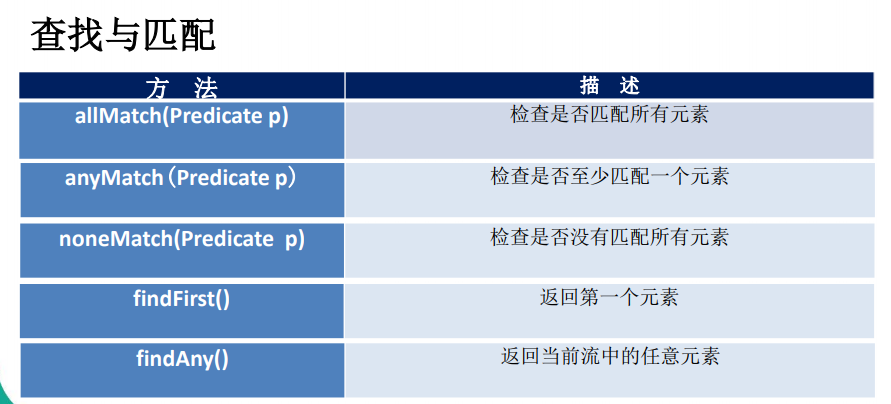
// allMatch——检查是否全部匹配
// anyMatch——是否至少匹配一个
// noneMatch不再赘述
@Test
public void test7() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小明", 18, Status.FREE));
empList.add(new Employee("小张", 19, Status.VOCATION));
empList.add(new Employee("小红", 20, Status.FREE));
// 注意Employee没有自然排序方式!
boolean b1 = empList.stream()
.allMatch((e) -> e.getStatus().equals(Status.FREE));
System.out.println(b1);// false
boolean b2 = empList.stream()
.anyMatch((e) -> e.getStatus().equals(Status.VOCATION));
System.out.println(b2);// true
}
// findFirst——流中第一个元素
// findAny——返回任意元素
@Test
public void test8() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小明", 18, Status.FREE));
empList.add(new Employee("小张", 19, Status.VOCATION));
empList.add(new Employee("小红", 20, Status.FREE));
// 注意Employee没有自然排序方式!
Optional<Employee> op = empList.stream()
.sorted((e1, e2) -> e1.getAge().compareTo(e2.getAge()))
.findFirst();
// Java8中使用Optional来避免空指针,orElse表示若op元素为空,则使用另外元素替代
// op.orElse(new Employee("老王", 20, Status.FREE));
Employee employee = op.get();
System.out.println(employee); Optional<Employee> any = empList.stream()
.filter((e) -> e.getStatus().equals(Status.FREE))
.findAny();
}
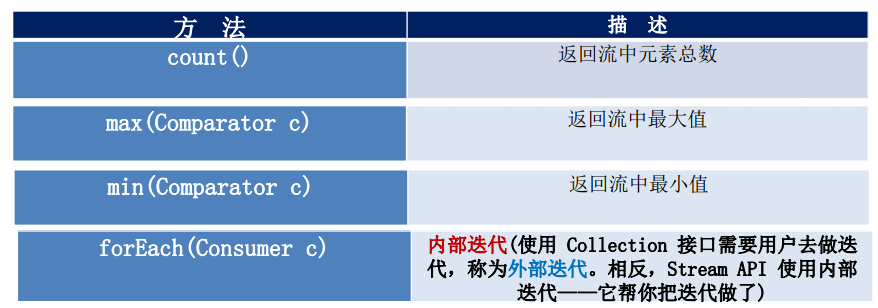
// count、max、min有点类似SQL语句
@Test
public void test9() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小明", 18, Status.FREE));
empList.add(new Employee("小张", 19, Status.VOCATION));
empList.add(new Employee("小红", 20, Status.FREE));
// 这里省略了中间操作
long count = empList.stream()
.count();
Optional<Employee> max = empList.stream()
.max((e1, e2) -> {
if (e1.getAge().equals(e2.getAge())) {
return e1.getName().compareTo(e2.getName());
}
return e1.getAge().compareTo(e2.getAge());
});
Employee employee = max.get();
System.out.println(employee);
// 提取最小的工资数(结合之前的中间操作)
Optional<Integer> min = empList.stream()
.map(Employee::getAge)
.min(Integer::compare);
System.out.println(min.get());
}
// forEach之前已经使用到,不再赘述
规约

示例:
// reduce——将集合中的元素反复结合起来,得到一个值
@Test
public void test10() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小张", 18));
empList.add(new Employee("小明", 19));
empList.add(new Employee("小红", 20)); // 例如,计算所有年龄总和(先将员工信息进行映射,提取age,也就是经典的map-reduce模式)
Integer totalAge = empList.stream()
.map(Employee::getAge)
.reduce(0, (x, y) -> x + y);// 第一个参数是起始值,第二个参数为二元运算的Function
System.out.println(totalAge);
}
收集

Collector 接口中方法的实现决定了如何对流执行收集操作(如收 集到 List、Set、Map)。但是 Collectors 实用类提供了很多静态 方法,可以方便地创建常见收集器实例,
示例
// collect——常见的运用例如提取员工信息中的name,组装成新的集合等操作
@Test
public void test11() {
List<Employee> empList = new ArrayList<>();
empList.add(new Employee("小张", 18));
empList.add(new Employee("小明", 19));
empList.add(new Employee("小红", 20)); List<String> list = empList.stream()
.map(Employee::getName)
.collect(Collectors.toList());// 需要去重,请使用toSet();
list.forEach(System.out::println);
// 需要自定义集合,例如LinedHashSet,可以使用此方式
empList.stream()
.map(Employee::getName)
.collect(Collectors.toCollection(HashSet::new));
}
更多Collectors中的方法(例如couonting,grouping),可以参见下表或者在源码中参考
toList List<T> 把流中元素收集到List
List<Employee> emps= list.stream().collect(Collectors.toList());
toSet Set<T> 把流中元素收集到Set
Set<Employee> emps= list.stream().collect(Collectors.toSet());
toCollection Collection<T> 把流中元素收集到创建的集合
Collection<Employee>emps=list.stream().collect(Collectors.toCollection(ArrayList::new));
counting Long 计算流中元素的个数
long count = list.stream().collect(Collectors.counting());
summingInt Integer 对流中元素的整数属性求和
inttotal=list.stream().collect(Collectors.summingInt(Employee::getSalary));
averagingInt Double 计算流中元素Integer属性的平均
值
doubleavg= list.stream().collect(Collectors.averagingInt(Employee::getSalary));
summarizingInt IntSummaryStatistics 收集流中Integer属性的统计值。
如:平均值
IntSummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getSalary));
joining String 连接流中每个字符串
String str= list.stream().map(Employee::getName).collect(Collectors.joining());
maxBy Optional<T> 根据比较器选择最大值
Optional<Emp>max= list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary)));
minBy Optional<T> 根据比较器选择最小值
Optional<Emp> min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary)));
reducing 归约产生的类型 从一个作为累加器的初始值
开始,利用BinaryOperator与
流中元素逐个结合,从而归
约成单个值
inttotal=list.stream().collect(Collectors.reducing(0, Employee::getSalar, Integer::sum));
collectingAndThen 转换函数返回的类型 包裹另一个收集器,对其结
果转换函数
inthow= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size));
groupingBy Map<K, List<T>> 根据某属性值对流分组,属
性为K,结果为V
Map<Emp.Status, List<Emp>> map= list.stream()
.collect(Collectors.groupingBy(Employee::getStatus));
partitioningBy Map<Boolean, List<T>> 根据true或false进行分区
Map<Boolean,List<Emp>>vd= list.stream().collect(Collectors.partitioningBy(Employee::getManage));
二、并行流与串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分 别处理每个数据块的流。
原理——fork/join框架
采用 “工作窃取”模式(work-stealing): 当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线 程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。
更多fork/join相关的介绍,请参见:http://www.infoq.com/cn/articles/fork-join-introduction
Stream API 可以声明性地通过 parallel() 与 sequential() 在并行流与顺序流之间进行切换。
Long sum = LongStream.rangeClosed(0L, 10000000000L)
.parallel()
.sum();
完整的示例,请参见如下:
package com.atguigu.java8; import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.ForkJoinTask;
import java.util.stream.LongStream; import org.junit.Test; public class TestForkJoin { @Test
public void test1(){
long start = System.currentTimeMillis(); ForkJoinPool pool = new ForkJoinPool();
ForkJoinTask<Long> task = new ForkJoinCalculate(0L, 10000000000L); long sum = pool.invoke(task);
System.out.println(sum); long end = System.currentTimeMillis(); System.out.println("耗费的时间为: " + (end - start)); //112-1953-1988-2654-2647-20663-113808
} @Test
public void test2(){
long start = System.currentTimeMillis(); long sum = 0L; for (long i = 0L; i <= 10000000000L; i++) {
sum += i;
} System.out.println(sum); long end = System.currentTimeMillis(); System.out.println("耗费的时间为: " + (end - start)); //34-3174-3132-4227-4223-31583
} @Test
public void test3(){
long start = System.currentTimeMillis(); Long sum = LongStream.rangeClosed(0L, 10000000000L)
.parallel()
.sum(); System.out.println(sum); long end = System.currentTimeMillis(); System.out.println("耗费的时间为: " + (end - start)); //2061-2053-2086-18926
} }
Java8新特性(二)——强大的Stream API的更多相关文章
- Java8 新特性2——强大的Stream API
强大的Stream API Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找.过滤和映射数据等操作.简而言之,Stream API 提供 ...
- Java8新特性第3章(Stream API)
Stream作为Java8的新特性之一,他与Java IO包中的InputStream和OutputStream完全不是一个概念.Java8中的Stream是对集合功能的一种增强,主要用于对集合对象进 ...
- java8新特性-lambda表达式和stream API的简单使用
一.为什么使用lambda Lambda 是一个 匿名函数,我们可以把 Lambda表达式理解为是 一段可以传递的代码(将代码像数据一样进行传递).可以写出更简洁.更灵活的代码.作为一种更紧凑的代码风 ...
- Java8 新特性之集合操作Stream
Java8 新特性之集合操作Stream Stream简介 Java 8引入了全新的Stream API.这里的Stream和I/O流不同,它更像具有Iterable的集合类,但行为和集合类又有所不同 ...
- Java8 新特性之Stream----java.util.stream
这个包主要提供元素的streams函数操作,比如对collections的map,reduce. 例如: int sum = widgets.stream() .filter(b -> b.ge ...
- Java8新特性时间日期库DateTime API及示例
Java8新特性的功能已经更新了不少篇幅了,今天重点讲解时间日期库中DateTime相关处理.同样的,如果你现在依旧在项目中使用传统Date.Calendar和SimpleDateFormat等API ...
- Java8新特性之方法引用&Stream流
Java8新特性 方法引用 前言 什么是函数式接口 只包含一个抽象方法的接口,称为函数式接口. 可以通过 Lambda 表达式来创建该接口的对象.(若 Lambda 表达式抛出一个受检异常(即:非运行 ...
- Java8新特性(1)—— Stream集合运算流入门学习
废话,写在前面 好久没写博客了,懒了,以后自觉写写博客,每周两三篇吧! 简单记录自己的学习经历,算是对自己的一点小小的督促! Java8的新特性很多,比如流处理在工作中看到很多的地方都在用,是时候扔掉 ...
- JAVA8新特性--集合流操作Stream
原文链接:https://blog.csdn.net/bluuusea/article/details/79967039 Stream类全路径为:java.util.stream.Stream 对St ...
- JDK 8 新特性之函数式编程 → Stream API
开心一刻 今天和朋友们去K歌,看着这群年轻人一个个唱的贼嗨,不禁感慨道:年轻真好啊! 想到自己年轻的时候,那也是拿着麦克风不放的人 现在的我没那激情了,只喜欢坐在角落里,默默的听着他们唱,就连旁边的妹 ...
随机推荐
- git相关操作(githug)
Level 15 restructure 关卡描述 你添加了一些文件到你的仓库,但现在知道你的项目需要进行调整.创建一个新的文件夹命名为“src”,使用git将所有的".html" ...
- Spring3+Struts2+Hibernate4+Mybatis整合的一个maven例子
说明: 1.用了maven去搞这个demo,懒得去导jar包... 2.这个demo用了spring去做Ioc,事务的aop:用了struts2去做“MVC”(没有用到任何UI技术,有点对不起这个MV ...
- 在Hibernate单向一对多关联关系中的org.hibernate.StaleStateException 异常。
具体异常如下: Caused by: org.hibernate.StaleStateException: Batch update returned unexpected row count fro ...
- bzoj1965 [Ahoi2005]洗牌
Description 为了表彰小联为Samuel星球的探险所做出的贡献,小联被邀请参加Samuel星球近距离载人探险活动. 由于Samuel星球相当遥远,科学家们要在飞船中度过相当长的一段时间,小联 ...
- Ajax系列之三:UpdatePanel
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/zhanghongjie0302/article/details/35609691 ...
- 十天精通CSS3
课程地址:http://www.imooc.com/learn/33 第1章 初识CSS3 CSS3课程列出第一站,先带领大家进入CSS3的世界,探索CSS3的魅力! 你做好准备了吗? 第2章 边框 ...
- Django:模板系统
一,常用语法 只需要记两种特殊符号: {{ }}和 {% %} 变量相关的用{{}},逻辑相关的用{%%}. 二,常量 {{ 变量名 }} 变量名由字母数字和下划线组成. 点(.)在模板语言中有特殊 ...
- 【[HAOI2011]Problem c】
好题啊 先考虑一些如何判掉无解的情况 我们开一个桶,存一下每个编号有多少个人必须选,之后做一个后缀和,之后我们扫一遍,如果一旦有一个后缀和\(pre[i]\)超过\(n-i+1\)就不合法了,因为我们 ...
- 【[SDOI2014]旅行】
听说这是动态开点主席树的板子题,但是发现我还不会,于是就来写一写 其实跟主席树一个样子的 这里就是存个板子吧 #include<cstdio> #include<cstring> ...
- Codeforces Round #512 (Div. 2, based on Technocup 2019 Elimination Round 1) C. Vasya and Golden Ticket 【。。。】
任意门:http://codeforces.com/contest/1058/problem/C C. Vasya and Golden Ticket time limit per test 1 se ...