机器学习经典算法之K-Means
一、简介
K-Means 是一种非监督学习,解决的是聚类问题。K 代表的是 K 类,Means 代表的是中心,你可以理解这个算法的本质是确定 K 类的中心点,当你找到了这些中心点,也就完成了聚类。
/*请尊重作者劳动成果,转载请标明原文链接:*/
/* https://www.cnblogs.com/jpcflyer/p/11117012.html * /
先请你和我思考一个场景,假设我有 20 支亚洲足球队,想要将它们按照成绩划分成 3 个等级,可以怎样划分?
二、 K-Means 的工作原理
对亚洲足球队的水平,你可能也有自己的判断。比如一流的亚洲球队有谁?你可能会说伊朗或韩国。二流的亚洲球队呢?你可能说是中国。三流的亚洲球队呢?你可能会说越南。
其实这些都是靠我们的经验来划分的,那么伊朗、中国、越南可以说是三个等级的典型代表,也就是我们每个类的中心点。
所以回过头来,如何确定 K 类的中心点?一开始我们是可以随机指派的,当你确认了中心点后,就可以按照距离将其他足球队划分到不同的类别中。
这也就是 K-Means 的中心思想,就是这么简单直接。你可能会问:如果一开始,选择一流球队是中国,二流球队是伊朗,三流球队是韩国,中心点选择错了怎么办?其实不用担心,K-Means 有自我纠正机制,在不断的迭代过程中,会纠正中心点。中心点在整个迭代过程中,并不是唯一的,只是你需要一个初始值,一般算法会随机设置初始的中心点。
好了,那我来把 K-Means 的工作原理给你总结下:
选取 K 个点作为初始的类中心点,这些点一般都是从数据集中随机抽取的;
将每个点分配到最近的类中心点,这样就形成了 K 个类,然后重新计算每个类的中心点;
重复第二步,直到类不发生变化,或者你也可以设置最大迭代次数,这样即使类中心点发生变化,但是只要达到最大迭代次数就会结束。
三、 如何给亚洲球队做聚类
对于机器来说需要数据才能判断类中心点,所以我整理了 2015-2019 年亚洲球队的排名,如下表所示。
我来说明一下数据概况。
其中 2019 年国际足联的世界排名,2015 年亚洲杯排名均为实际排名。2018 年世界杯中,很多球队没有进入到决赛圈,所以只有进入到决赛圈的球队才有实际的排名。如果是亚洲区预选赛 12 强的球队,排名会设置为 40。如果没有进入亚洲区预选赛 12 强,球队排名会设置为 50。

针对上面的排名,我们首先需要做的是数据规范化。 我先把数值都规范化到 [0,1] 的空间中,得到了以下的数值表:

如果我们随机选取中国、日本、韩国为三个类的中心点,我们就需要看下这些球队到中心点的距离。
距离有多种计算的方式,有关距离的计算我在 KNN 算法中也讲到过。 欧氏距离是最常用的距离计算方式,这里我选择欧氏距离作为距离的标准,计算每个队伍分别到中国、日本、韩国的距离,然后根据距离远近来划分。我们看到大部分的队,会和中国队聚类到一起。这里我整理了距离的计算过程,比如中国和中国的欧氏距离为 0,中国和日本的欧式距离为 0.732003。如果按照中国、日本、韩国为 3 个分类的中心点,欧氏距离的计算结果如下表所示:
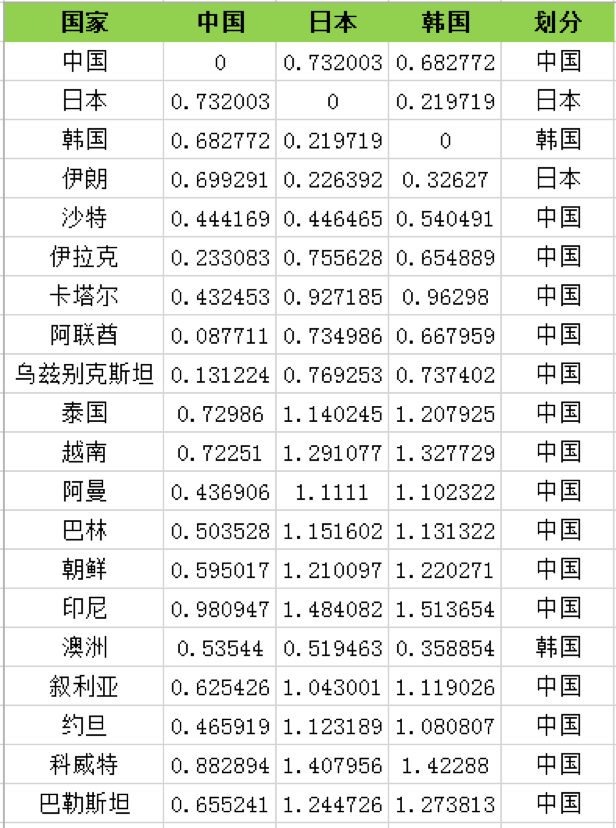
然后我们再重新计算这三个类的中心点,如何计算呢?最简单的方式就是取平均值,然后根据新的中心点按照距离远近重新分配球队的分类,再根据球队的分类更新中心点的位置。计算过程这里不展开,最后一直迭代(重复上述的计算过程:计算中心点和划分分类)到分类不再发生变化,可以得到以下的分类结果:
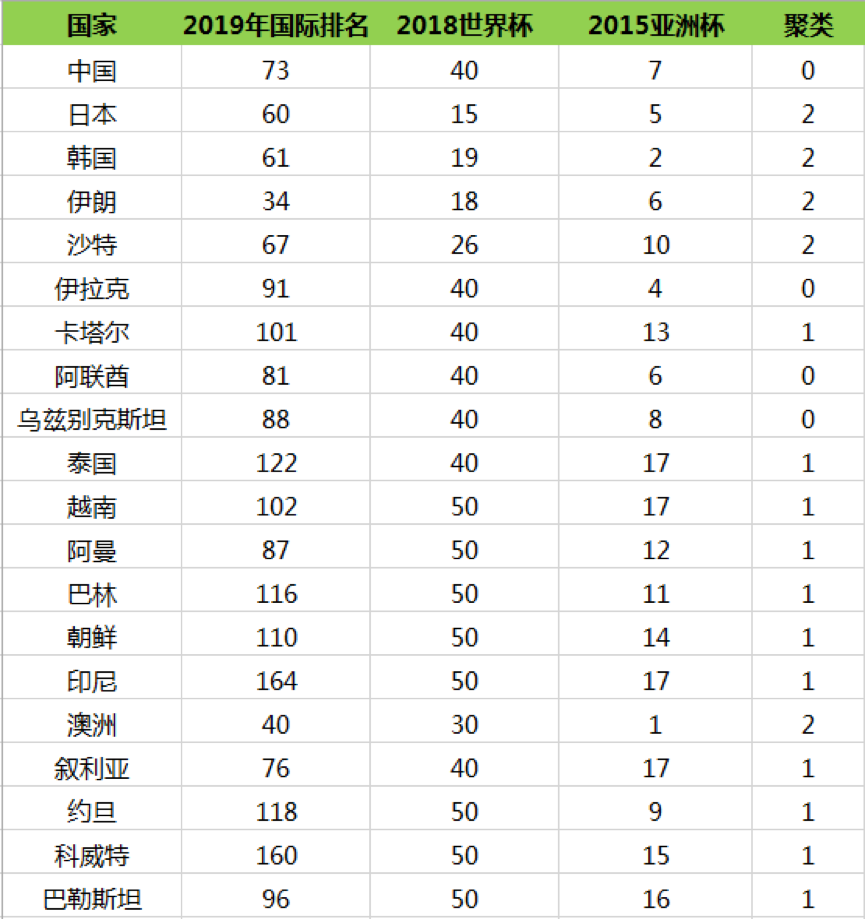
所以我们能看出来第一梯队有日本、韩国、伊朗、沙特、澳洲;第二梯队有中国、伊拉克、阿联酋、乌兹别克斯坦;第三梯队有卡塔尔、泰国、越南、阿曼、巴林、朝鲜、印尼、叙利亚、约旦、科威特和巴勒斯坦。
四、 如何使用 sklearn 中的 K-Means 算法
sklearn 是 Python 的机器学习工具库,如果从功能上来划分,sklearn 可以实现分类、聚类、回归、降维、模型选择和预处理等功能。这里我们使用的是 sklearn 的聚类函数库,因此需要引用工具包,具体代码如下:
from sklearn.cluster import KMeans
当然 K-Means 只是 sklearn.cluster 中的一个聚类库,实际上包括 K-Means 在内,sklearn.cluster 一共提供了 9 种聚类方法,比如 Mean-shift,DBSCAN,Spectral clustering(谱聚类)等。这些聚类方法的原理和 K-Means 不同,这里不做介绍。
我们看下 K-Means 如何创建:
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, precompute_distances='auto', verbose=0, random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
我们能看到在 K-Means 类创建的过程中,有一些主要的参数:
n_clusters : 即 K 值,一般需要多试一些 K 值来保证更好的聚类效果。你可以随机设置一些 K 值,然后选择聚类效果最好的作为最终的 K 值;
max_iter : 最大迭代次数,如果聚类很难收敛的话,设置最大迭代次数可以让我们及时得到反馈结果,否则程序运行时间会非常长;
n_init :初始化中心点的运算次数,默认是 10。程序是否能快速收敛和中心点的选择关系非常大,所以在中心点选择上多花一些时间,来争取整体时间上的快速收敛还是非常值得的。由于每一次中心点都是随机生成的,这样得到的结果就有好有坏,非常不确定,所以要运行 n_init 次, 取其中最好的作为初始的中心点。如果 K 值比较大的时候,你可以适当增大 n_init 这个值;
algorithm :k-means 的实现算法,有“auto” “full”“elkan”三种。一般来说建议直接用默认的"auto"。简单说下这三个取值的区别,如果你选择"full"采用的是传统的 K-Means 算法,“auto”会根据数据的特点自动选择是选择“full”还是“elkan”。我们一般选择默认的取值,即“auto” 。
在创建好 K-Means 类之后,就可以使用它的方法,最常用的是 fit 和 predict 这个两个函数。你可以单独使用 fit 函数和 predict 函数,也可以合并使用 fit_predict 函数。其中 fit(data) 可以对 data 数据进行 k-Means 聚类。 predict(data) 可以针对 data 中的每个样本,计算最近的类。
现在我们要完整地跑一遍 20 支亚洲球队的聚类问题。
# coding: utf-8
from sklearn.cluster import KMeans
from sklearn import preprocessing
import pandas as pd
import numpy as np
# 输入数据
data = pd.read_csv('data.csv', encoding='gbk')
train_x = data[["2019 年国际排名 ","2018 世界杯 ","2015 亚洲杯 "]]
df = pd.DataFrame(train_x)
kmeans = KMeans(n_clusters=3)
# 规范化到 [0,1] 空间
min_max_scaler=preprocessing.MinMaxScaler()
train_x=min_max_scaler.fit_transform(train_x)
# kmeans 算法
kmeans.fit(train_x)
predict_y = kmeans.predict(train_x)
# 合并聚类结果,插入到原数据中
result = pd.concat((data,pd.DataFrame(predict_y)),axis=1)
result.rename({0:u'聚类'},axis=1,inplace=True)
print(result)
运行结果:
国家 2019 年国际排名 2018 世界杯 2015 亚洲杯 聚类 中国 73 40 7 2 日本 60 15 5 0 韩国 61 19 2 0 伊朗 34 18 6 0 沙特 67 26 10 0 伊拉克 91 40 4 2 卡塔尔 101 40 13 1 阿联酋 81 40 6 2 乌兹别克斯坦 88 40 8 2 泰国 122 40 17 1 越南 102 50 17 1 阿曼 87 50 12 1 巴林 116 50 11 1 朝鲜 110 50 14 1 印尼 164 50 17 1 澳洲 40 30 1 0 叙利亚 76 40 17 1 约旦 118 50 9 1 科威特 160 50 15 1 巴勒斯坦 96 50 16 1
搜索关注微信公众号“程序员姜小白”,获取更新精彩内容哦。
机器学习经典算法之K-Means的更多相关文章
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- Python3入门机器学习经典算法与应用
<Python3入门机器学习经典算法与应用> 章节第1章 欢迎来到 Python3 玩转机器学习1-1 什么是机器学习1-2 课程涵盖的内容和理念1-3 课程所使用的主要技术栈第2章 机器 ...
- Python3实现机器学习经典算法(二)KNN实现简单OCR
一.前言 1.ocr概述 OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然 ...
- Python3实现机器学习经典算法(一)KNN
一.KNN概述 K-(最)近邻算法KNN(k-Nearest Neighbor)是数据挖掘分类技术中最简单的方法之一.它具有精度高.对异常值不敏感的优点,适合用来处理离散的数值型数据,但是它具有 非常 ...
- 机器学习经典算法具体解释及Python实现--线性回归(Linear Regression)算法
(一)认识回归 回归是统计学中最有力的工具之中的一个. 机器学习监督学习算法分为分类算法和回归算法两种,事实上就是依据类别标签分布类型为离散型.连续性而定义的. 顾名思义.分类算法用于离散型分布预測, ...
- Python3入门机器学习经典算法与应用☝☝☝
Python3入门机器学习经典算法与应用 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 使用新版python3语言和流行的scikit-learn框架,算法与 ...
- Python3实现机器学习经典算法(三)ID3决策树
一.ID3决策树概述 ID3决策树是另一种非常重要的用来处理分类问题的结构,它形似一个嵌套N层的IF…ELSE结构,但是它的判断标准不再是一个关系表达式,而是对应的模块的信息增益.它通过信息增益的大小 ...
- Python3实现机器学习经典算法(四)C4.5决策树
一.C4.5决策树概述 C4.5决策树是ID3决策树的改进算法,它解决了ID3决策树无法处理连续型数据的问题以及ID3决策树在使用信息增益划分数据集的时候倾向于选择属性分支更多的属性的问题.它的大部分 ...
- Python3入门机器学习经典算法与应用✍✍✍
Python3入门机器学习经典算法与应用 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大家看的 ...
随机推荐
- Android显示gif格式图片
大家知道,在Android中使用ImageView来显示gif格式的图片,我们无法得到gif格式图片该有的效果,它只会停在第一帧上,而不会继续.这时只能看到一张静态的图片,这里我们可以使用个简单的方法 ...
- 微信公众平台消息接口开发(24)图片识别之人脸识别API
微信公众平台开发模式 微信 公众平台 消息接口 开发模式 企业微信公众平台 图片识别 人脸识别 API 作者:方倍工作室 原文:http://www.cnblogs.com/txw1958/archi ...
- 机器学习: Tensor Flow +CNN 做笑脸识别
Tensor Flow 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数 ...
- python 教程 第一章、 简介
第一章. 简介 官方介绍: Python是一种简单易学,功能强大的编程语言,它有高效率的高层数据结构,简单而有效地实现面向对象编程.Python简洁的语法和对动态输入的支持,再加上解释性语言的本质,使 ...
- Entity framework 配置文件,实现类,测试类
配置文件信息App.config: 数据库IP地址为192.168.2.186 ,数据库名为 Eleven-Six , 用户名 123456,密码654321 <?xml version=&qu ...
- ABP框架——单表实体流程
实体实体配置文件菜单本地化语言:xml文件权限配置领域服务应用层CRUDDTOSPA路由:app.js视图生成:.html,.js
- Go 语言如果按这样改进,能不能火过 Java?
据 InfoWorld 消息,为改进 Go 语言的开发工具,Go 可能会获得自己的语言服务器,类似于 Microsoft 和 Red Hat 的语言服务器协议. 消息是从 Go 语言开发者的讨论组中流 ...
- 利用最小二乘法拟合任意次函数曲线(C#)
原文:利用最小二乘法拟合任意次函数曲线(C#) ///<summary> ///用最小二乘法拟合二元多次曲线 ///</summary> ///< ...
- 如何获取app配置文件内容
App.config: <appSettings> <add key="FCPConnection" value="Data Source=192.16 ...
- C# 实现系统关机、注销、重启、休眠、挂起
原文:C# 实现系统关机.注销.重启.休眠.挂起 核心代码如下: using System; using System.Text; using System.Diagnostics; using Sy ...