使用 Scrapy 爬取去哪儿网景区信息
Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘、监测和自动化测试。安装使用终端命令 pip install Scrapy 即可。
Scrapy 比较吸引人的地方是:我们可以根据需求对其进行修改,它提供了多种类型的爬虫基类,如:BaseSpider、sitemap 爬虫等,新版本提供了对 web2.0 爬虫的支持。
1 Scrapy 介绍

{kind=link}
1.1 组成
Scrapy Engine(引擎):负责 Spider、ItemPipeline、Downloader、Scheduler 中间的通讯,信号、数据传递等。
Scheduler(调度器):负责接受引擎发送过来的 Request 请求,并按照一定的方式进行整理排列、入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载 Scrapy Engine(引擎) 发送的所有 Requests 请求,并将其获取到的 Responses 交还给 Scrapy Engine(引擎),由引擎交给 Spider 来处理。
Spider(爬虫):负责处理所有 Responses,从中解析提取数据,获取 Item 字段需要的数据,并将需要跟进的 URL 提交给引擎,再次进入 Scheduler(调度器)。
Item Pipeline(管道):负责处理 Spider 中获取到的 Item,并进行后期处理,如:详细解析、过滤、存储等。
Downloader Middlewares(下载中间件):一个可以自定义扩展下载功能的组件,如:设置代理、设置请求头等。
Spider Middlewares(Spider 中间件):一个可以自定扩展和操作引擎和 Spider 中间通信的功能组件,如:自定义 request 请求、过滤 response 等。
总的来说就是:Spider 和 Item Pipeline 需要我们自己实现,Downloader Middlewares 和 Spider Middlewares 我们可以根据需求自定义。
1.2 流程梳理
1)Spider 将需要发送请求的 URL 交给 Scrapy Engine 交给调度器;
2)Scrapy Engine 将请求 URL 转给 Scheduler;
3)Scheduler 对请求进行排序整理等处理后返回给 Scrapy Engine;
4)Scrapy Engine 拿到请求后通过 Middlewares 发送给 Downloader;
5)Downloader 向互联网发送请求,在获取到响应后,又经过 Middlewares 发送给 Scrapy Engine。
6)Scrapy Engine 获取到响应后,返回给 Spider,Spider 处理响应,并从中解析提取数据;
7)Spider 将解析的数据经 Scrapy Engine 交给 Item Pipeline, Item Pipeline 对数据进行后期处理;
8)提取 URL 重新经 Scrapy Engine 交给 Scheduler 进行下一个循环,直到无 URL 请求结束。
1.3 Scrapy 去重机制
Scrapy 提供了对 request 的去重处理,去重类 RFPDupeFilter 在 dupefilters.py 文件中,路径为:Python安装目录\Lib\site-packages\scrapy ,该类里面有个方法 request_seen 方法,源码如下:
def request_seen(self, request):
# 计算 request 的指纹
fp = self.request_fingerprint(request)
# 判断指纹是否已经存在
if fp in self.fingerprints:
# 存在
return True
# 不存在,加入到指纹集合中
self.fingerprints.add(fp)
if self.file:
self.file.write(fp + os.linesep)
它在 Scheduler 接受请求的时候被调用,进而调用 request_fingerprint 方法(为 request 生成一个指纹),源码如下:
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]
在上面代码中我们可以看到
fp = hashlib.sha1()
...
cache[include_headers] = fp.hexdigest()
它为每一个传递过来的 URL 生成一个固定长度的唯一的哈希值。再看一下 __init__ 方法,源码如下:
def __init__(self, path=None, debug=False):
self.file = None
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
我们可以看到里面有 self.fingerprints = set() 这段代码,就是通过 set 集合的特点(set 不允许有重复值)进行去重。
去重通过 dont_filter 参数设置,如图所示

{kind=link}
dont_filter 为 False 开启去重,为 True 不去重。
2 实现过程
制作 Scrapy 爬虫需如下四步:
- 创建项目 :创建一个爬虫项目
- 明确目标 :明确你想要抓取的目标(编写 items.py)
- 制作爬虫 :制作爬虫开始爬取网页(编写 xxspider.py)
- 存储内容 :设计管道存储爬取内容(编写pipelines.py)
我们以爬取去哪儿网北京景区信息为例,如图所示:
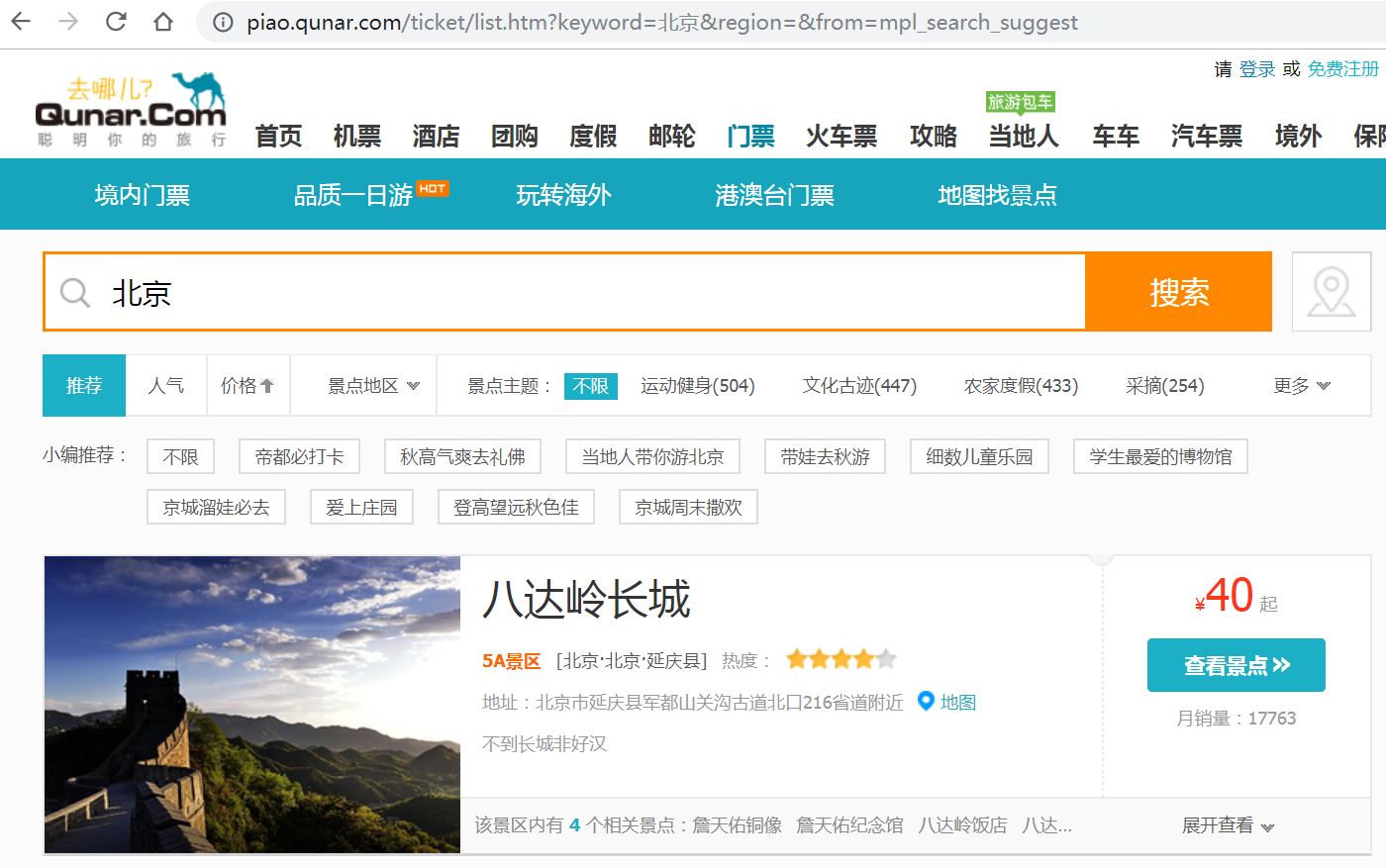
2.1 创建项目
在我们需要新建项目的目录,使用终端命令 scrapy startproject 项目名 创建项目,我创建的目录结构如图所示:
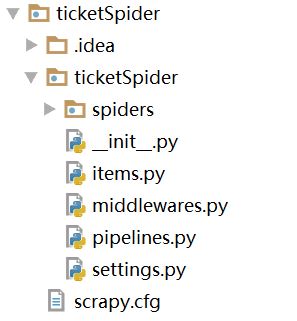
- spiders 存放爬虫的文件
- items.py 定义数据类型
- middleware.py 存放中间件
- piplines.py 存放数据的有关操作
- settings.py 配置文件
- scrapy.cfg 总的控制文件
2.2 定义 Item
Item 是保存爬取数据的容器,使用的方法和字典差不多。我们计划提取的信息包括:area(区域)、sight(景点)、level(等级)、price(价格),在 items.py 定义信息,源码如下:
import scrapy
class TicketspiderItem(scrapy.Item):
area = scrapy.Field()
sight = scrapy.Field()
level = scrapy.Field()
price = scrapy.Field()
pass
2.3 爬虫实现
在 spiders 目录下使用终端命令 scrapy genspider 文件名 要爬取的网址 创建爬虫文件,然后对其修改及编写爬取的具体实现,源码如下:
import scrapy
from ticketSpider.items import TicketspiderItem
class QunarSpider(scrapy.Spider):
name = 'qunar'
allowed_domains = ['piao.qunar.com']
start_urls = ['https://piao.qunar.com/ticket/list.htm?keyword=%E5%8C%97%E4%BA%AC®ion=&from=mpl_search_suggest']
def parse(self, response):
sight_items = response.css('#search-list .sight_item')
for sight_item in sight_items:
item = TicketspiderItem()
item['area'] = sight_item.css('::attr(data-districts)').extract_first()
item['sight'] = sight_item.css('::attr(data-sight-name)').extract_first()
item['level'] = sight_item.css('.level::text').extract_first()
item['price'] = sight_item.css('.sight_item_price em::text').extract_first()
yield item
# 翻页
next_url = response.css('.next::attr(href)').extract_first()
if next_url:
next_url = "https://piao.qunar.com" + next_url
yield scrapy.Request(
next_url,
callback=self.parse
)
简单介绍一下:
- name:爬虫名
- allowed_domains:允许爬取的域名
- atart_urls:爬取网站初始请求的 url(可定义多个)
- parse 方法:解析网页的方法
- response 参数:请求网页后返回的内容
yield
在上面的代码中我们看到有个 yield,简单说一下,yield 是一个关键字,作用和 return 差不多,差别在于 yield 返回的是一个生成器(在 Python 中,一边循环一边计算的机制,称为生成器),它的作用是:有利于减小服务器资源,在列表中所有数据存入内存,而生成器相当于一种方法而不是具体的信息,占用内存小。
爬虫伪装
通常需要对爬虫进行一些伪装,关于爬虫伪装可通过【Python 爬虫(一):爬虫伪装】做一下简单了解,这里我们使用一个最简单的方法处理一下。
- 使用终端命令
pip install scrapy-fake-useragent安装 - 在 settings.py 文件中添加如下代码:
DOWNLOADER_MIDDLEWARES = {
# 关闭默认方法
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
# 开启
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
}
2.4 保存数据
我们将数据保存到本地的 csv 文件中,csv 具体操作可以参考:CSV 文件读写,下面看一下具体实现。
首先,在 pipelines.py 中编写实现,源码如下:
import csv
class TicketspiderPipeline(object):
def __init__(self):
self.f = open('ticker.csv', 'w', encoding='utf-8', newline='')
self.fieldnames = ['area', 'sight', 'level', 'price']
self.writer = csv.DictWriter(self.f, fieldnames=self.fieldnames)
self.writer.writeheader()
def process_item(self, item, spider):
self.writer.writerow(item)
return item
def close(self, spider):
self.f.close()
然后,将 settings.py 文件中如下代码:
ITEM_PIPELINES = {
'ticketSpider.pipelines.TicketspiderPipeline': 300,
}
放开即可。
2.5 运行
我们在 settings.py 的同级目录下创建运行文件,名字自定义,放入如下代码:
from scrapy.cmdline import execute
execute('scrapy crawl 爬虫名'.split())
这个爬虫名就是我们之前在爬虫文件中的 name 属性值,最后在 Pycharm 运行该文件即可。
参考:
http://www.scrapyd.cn/doc/
https://www.liaoxuefeng.com/wiki/897692888725344/923029685138624
完整代码请关注文末公众号,后台回复 qs 获取。
使用 Scrapy 爬取去哪儿网景区信息的更多相关文章
- 使用JAVA爬取去哪儿网入住信息
昨天帮一个商科同学爬取去哪儿网站的所有广州如家快捷酒店的所有入住信息. 就是上面的商务出行 xxx年入住这些东西 然而去哪儿的前端很强,在获取所有如家快捷酒店的时候就遇到了问题. 他显示的酒店列表是j ...
- scrapy爬取全部知乎用户信息
# -*- coding: utf-8 -*- # scrapy爬取全部知乎用户信息 # 1:是否遵守robbots_txt协议改为False # 2: 加入爬取所需的headers: user-ag ...
- 网络爬虫之scrapy爬取某招聘网手机APP发布信息
1 引言 过段时间要开始找新工作了,爬取一些岗位信息来分析一下吧.目前主流的招聘网站包括前程无忧.智联.BOSS直聘.拉勾等等.有段时间时间没爬取手机APP了,这次写一个爬虫爬取前程无忧手机APP岗位 ...
- Python Scrapy 爬取煎蛋网妹子图实例(一)
前面介绍了爬虫框架的一个实例,那个比较简单,这里在介绍一个实例 爬取 煎蛋网 妹子图,遗憾的是 上周煎蛋网还有妹子图了,但是这周妹子图变成了 随手拍, 不过没关系,我们爬图的目的是为了加强实战应用,管 ...
- Python的scrapy之爬取链家网房价信息并保存到本地
因为有在北京租房的打算,于是上网浏览了一下链家网站的房价,想将他们爬取下来,并保存到本地. 先看链家网的源码..房价信息 都保存在 ul 下的li 里面 爬虫结构: 其中封装了一个数据库处理模 ...
- scrapy爬取校花网男神图片保存到本地
爬虫四部曲,本人按自己的步骤来写,可能有很多漏洞,望各位大神指点指点 1.创建项目 scrapy startproject xiaohuawang scrapy.cfg: 项目的配置文件xiaohua ...
- Python Scrapy 爬取煎蛋网妹子图实例(二)
上篇已经介绍了 图片的爬取,后来觉得不太好,每次爬取的图片 都在一个文件下,不方便区分,且数据库中没有爬取的时间标识,不方便后续查看 数据时何时爬取的,所以这里进行了局部修改 修改一:修改爬虫执行方式 ...
- scrapy爬取阳光电影网全站资源
说一下我的爬取过程吧 第一步: 当然是 scrapy startproject + 名字 新建爬虫项目 第二步: scrapy genspider -t crawl +爬虫名字+ 所爬取网站的 ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
随机推荐
- GUI tkinter (Canvas)绘图篇
from tkinter import * root = Tk()root.title("中国象棋棋盘手绘") can = Canvas(root,width = 400, hei ...
- LeetCode初级算法--链表01:反转链表
LeetCode初级算法--链表01:反转链表 搜索微信公众号:'AI-ming3526'或者'计算机视觉这件小事' 获取更多算法.机器学习干货 csdn:https://blog.csdn.net/ ...
- [NOIp2010] luogu P1514 引水入城
跟 zzy, hwx 等人纠结是否回去上蛋疼的董老板的课. 题目描述 如图所示.你有一个 N×MN\times MN×M 的矩阵,水可以从一格流到与它相邻的格子,需要满足起点的海拔严格高于终点海拔.定 ...
- Arduino学习笔记⑤ 模拟IO实验
1.前言 还记得前几个我们都是在讲解数字IO,而其实我们生活中大多数信号都是模拟信号,如声音以及温度变化.在Arduino中,常用0~5v的电压来表示模拟信号. 1.1 模拟输入功能 ...
- Linux配置部署_新手向(五)——Docker的安装与使用
前言 最近还是在考虑Linux下net core的部署问题,还是发现了很多麻烦的问题,这里还是继续把需要使用的东西部署介绍下吧. Docker 其实对于Docker我也是一星半点儿,了解的不够深入,大 ...
- 04 python学习笔记-函数、函数参数和返回值(四)
函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段.函数能提高应用的模块性,和代码的重复利用率.Python提供了许多内建函数,比如print(),我们也可以自己创建函数,这叫做用户自定 ...
- open_basedir限制目录
1.open_basedir介绍 前言:前些日我用lnmp一键安装包出现了open_basedir的问题,因为我把项目目录变了,所以要在的fastcgi.conf下面加上open_basedir的目录 ...
- Android Studio Module 引入aar
1.把aar文件放到module的libs目录下 2.作为lib的module的gradle文件: repositories { flatDir { dirs 'libs' } } dependenc ...
- java架构之路-(MQ专题)RocketMQ从入坑到集群详解
这次我们来说说我们的RocketMQ的安装和参数配置,先来看一下我们RocketMQ的提出和应用场景吧. 早在2009年,阿里巴巴的淘宝第一次提出了双11购物狂欢节,但是在2009年,服务器无法承受到 ...
- C++学习笔记10_输入输出流.文件读写
//从键盘输入到程序,叫标准input:从程序输出到显示器,叫标准output:一并叫标准I/O //文件的输入和输出,叫文件I/O cout<<"hellow word&quo ...