为什么每一个爬虫工程师都应该学习 Kafka
这篇文章不会涉及到Kafka 的具体操作,而是告诉你 Kafka 是什么,以及它能在爬虫开发中扮演什么重要角色。
一个简单的需求
假设我们需要写一个微博爬虫,老板给的需求如下:
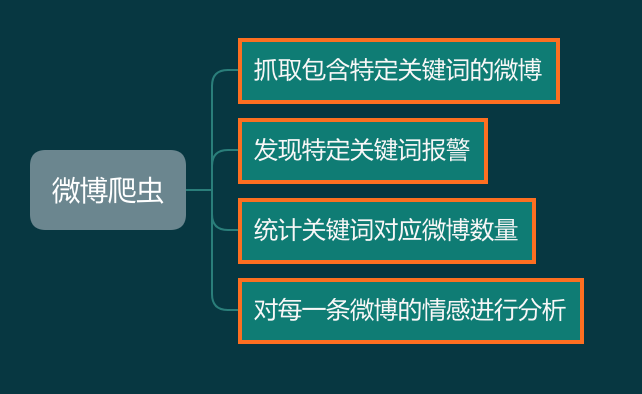
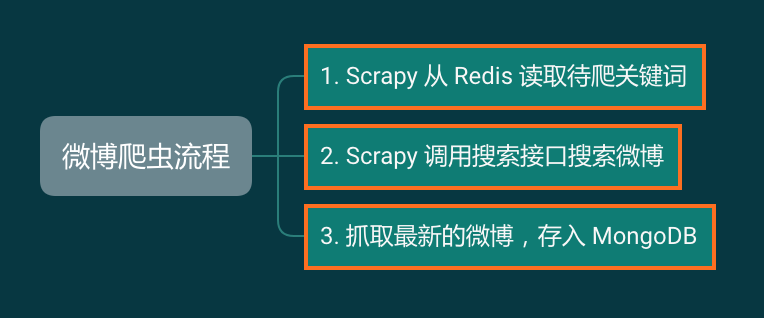
开发爬虫对你来说非常简单,于是三下五除二你就把爬虫开发好了:
接下来开始做报警功能,逻辑也非常简单:

再来看看统计关键词的功能,这个功能背后有一个网页,会实时显示抓取数据量的变化情况,可以显示每分钟、每小时的某个关键词的抓取量。
这个功能对你来说也挺简单,于是你实现了如下逻辑:

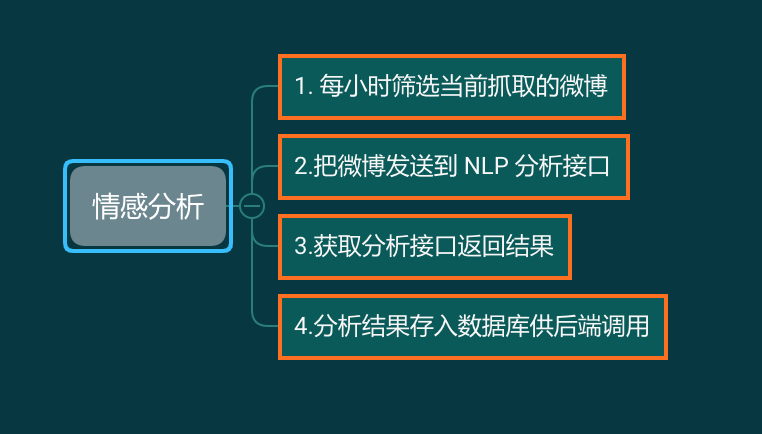
最后一个需求,对微博数据进行情感分析。情感分析的模块有别的部门同事开发,你要做的就是每个小时拉取一批数据,发送到接口,获取返回,然后存入后端需要的数据库:
任务完成,于是你高兴地回家睡觉了。
困难接踵而至
爬虫变慢了
随着老板逐渐增加新的关键词,你发现每一次完整抓取的时间越来越长,一开始是2分钟抓取一轮,后来变成10分钟一轮,然后变成30分钟一轮,接下来变成1小时才能抓取一轮。随着延迟越来越高,你的报警越来越不准确,微博都发出来一小时了,你的报警还没有发出来,因为那一条微博还没有来得及入库。
你的爬虫技术非常好,能绕过所有反爬虫机制,你有无限个代理 IP,于是你轻轻松松就把爬虫提高到了每秒一百万并发。现在只需要1分钟你就能完成全部数据的抓取。这下没问题了吧。
可是报警还是没有发出来。这是怎么回事?
数据库撑不住了
经过排查,你发现了问题。数据抓取量上来了,但是 MongoDB 却无法同时接收那么多的数据写入。数据写入速度远远小于爬取数据,大量的数据堆积在内存中。于是你的服务器爆炸了。
你紧急搭建了100个数据库并编号0-99,对于抓取到的微博,先把每一条微博的 ID对100求余数,然后把数据存入余数对应的 MongoDB 中。每一台 MongoDB 的压力下降到了原来的1%。数据终于可以即时存进数据库里面了。
可是报警还是没有发出来,不仅如此,现在实时抓取量统计功能也不能用了,还有什么问题?
查询来不及了
现在报警程序要遍历100个数据库最近5分钟里面的每一条数据,确认是否有需要报警的内容。但是这个遍历过程就远远超过5分钟。
时间错开了
由于微博的综合搜索功能不是按照时间排序的,那么就会出现这样一种情况,早上10:01发的微博,你在12:02的时候才抓到。
不论你是在报警的时候筛选数据,还是筛选数据推送给 NLP 分析接口,如果你是以微博的发布时间来搜索,那么这一条都会被你直接漏掉——当你在10:05的时候检索10:00-10:05这5分钟发表的微博,由于这一条微博没有抓到,你自然搜索不到。
当你12:05开始检索12:00-12:05的数据时,你搜索的是发布时间为12:00-12:05的数据,于是10:01这条数据虽然是在12:02抓到的,但你也无法筛选出来。
那么是不是可以用抓取时间来搜索呢?例如10:05开始检索在10:00-10:05抓取到的数据,无论它的发布时间是多少,都检索出来。
这样做确实可以保证不漏掉数据,但这样做的代价是你必需保存、检索非常非常多的数据。例如每次抓取,只要发布时间是最近10小时的,都要保存下来。于是报警程序在检索数据时,就需要检索这5分钟入库的,实际上发布时间在10小时内的全部数据。
什么,你说每次保存之前检查一下这条微博是否已经存在,如果存在就不保存?别忘了批量写入时间都不够了,你还准备分一些时间去查询?
脏数据来了
老板突然来跟你说,关键词“篮球”里面有大量的关于 蔡徐坤的内容,所以要你把所有包含蔡徐坤的数据全部删掉。
那么,这个过滤逻辑放在哪里?放在爬虫的 pipelines.py 里面吗?那你要重新部署所有爬虫。今天是过滤蔡徐坤,明天是过滤范层层,后天是过滤王一博,每天增加关键词,你每天都得重新部署爬虫?
那你把关键词放在 Redis 或者 MongoDB 里面,每次插入数据前,读取所有关键词,看微博里面不包含再存。
还是那个问题,插入时间本来就不够了,你还要查数据库?
好,关键词过滤不放在爬虫里面了。你写了一个脚本,每分钟检查一次MongoDB新增的数据,如果发现包含 不需要的关键词,就把他删除。
现在问题来了,删除数据的程序每分钟检查一次,报警程序每5分钟检查一次。中间必定存在某些数据,还没有来得及删除,报警程序就报警了,老板收到报警来看数据,而你的删除程序又在这时把这个脏数据删了。
这下好了,天天报假警,狼来了的故事重演了。
5个问题1个救星
如果你在爬虫开发的过程中遇到过上面的诸多问题,那么,你就应该试一试使用 Kafka。一次性解决上面的所有问题。
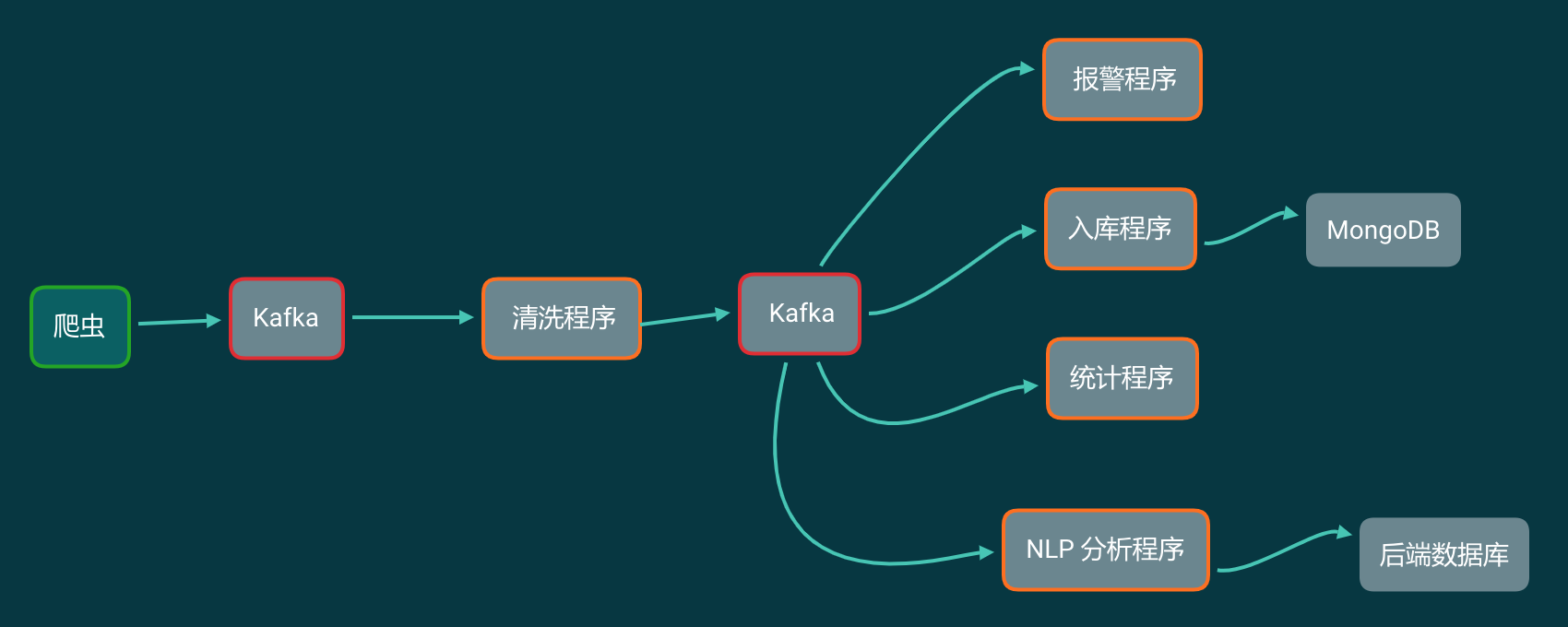
把 Kafka 加入到你的爬虫流程中,那么你的爬虫架构变成了下面这样:
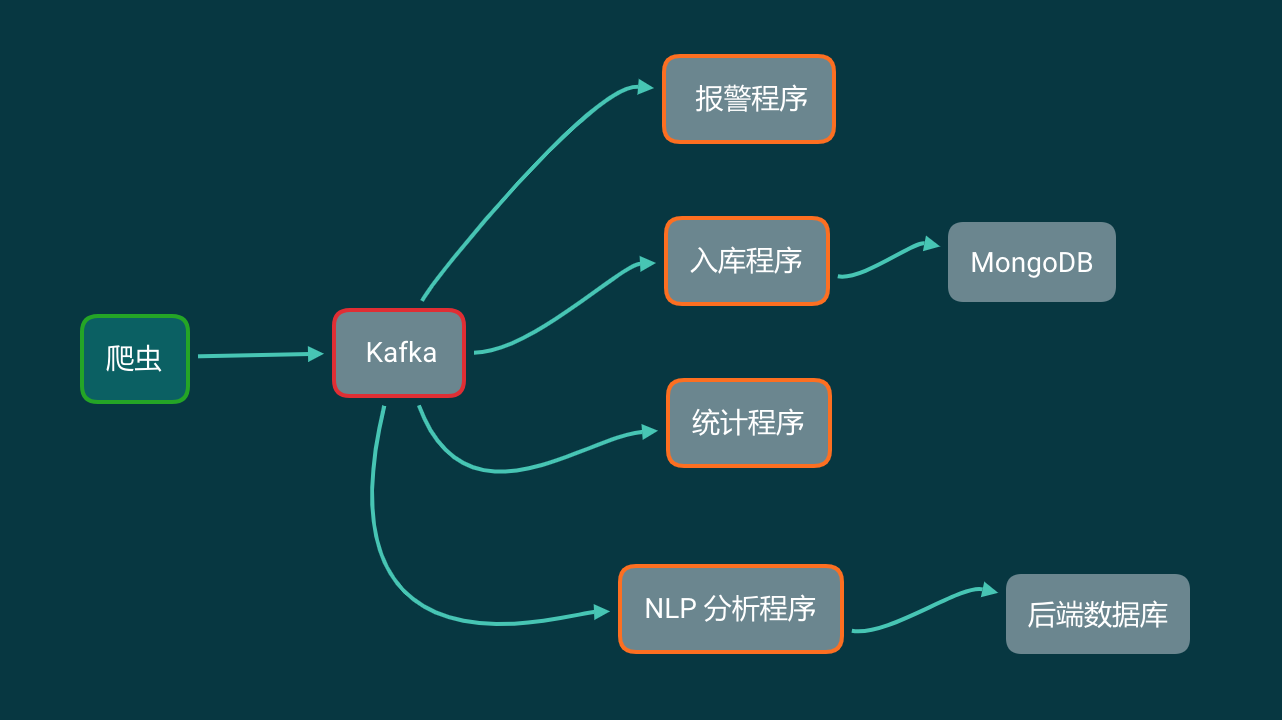
这看起来似乎和数据直接写进 MongoDB 里面,然后各个程序读取 MongoDB 没什么区别啊?那 Kafka 能解决什么问题?
我们来看看,在这个爬虫架构里面,我们将会用到的 Kafka 的特性:
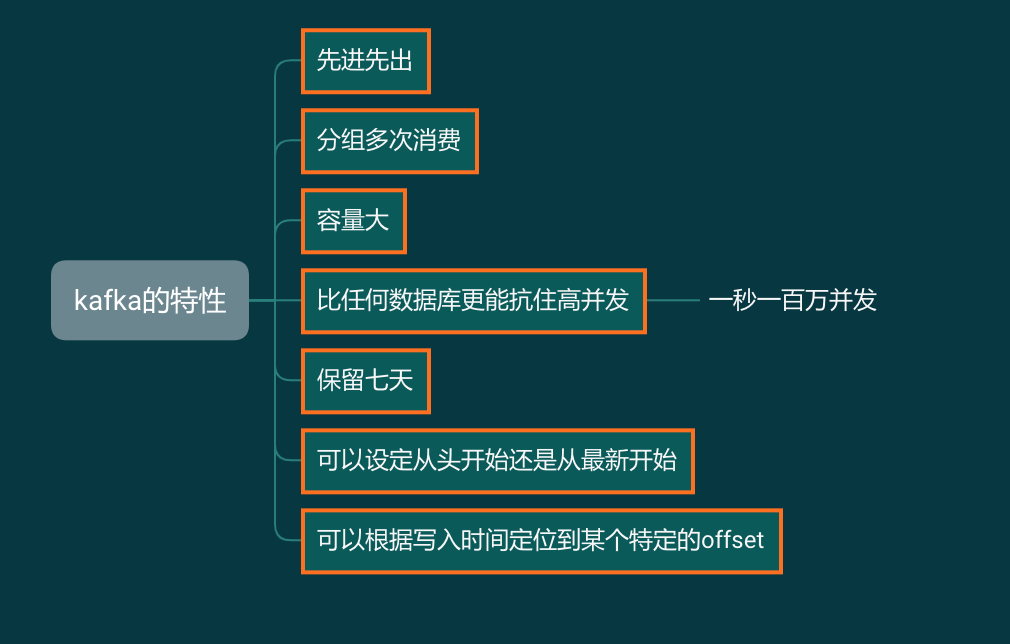
与其说 Kafka 在这个爬虫架构中像 MongoDB,不如说更像 Redis 的列表。
现在来简化一下我们的模型,如果现在爬虫只有一个需求,就是搜索,然后报警。那么我们可以这样设计:
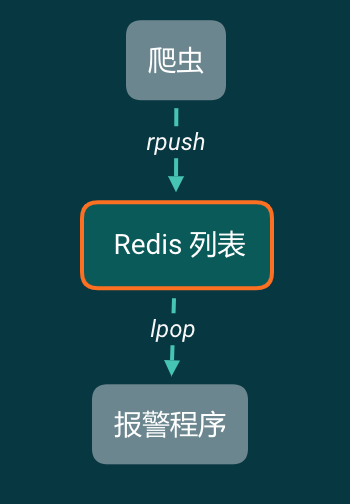
爬虫爬下来的数据,直接塞进 Redis 的列表右侧。报警程序从 Redis 列表左侧一条一条读取。读取一条检视一条,如果包含报警关键词,就报警。然后读取下一条。
这样做有什么好处?
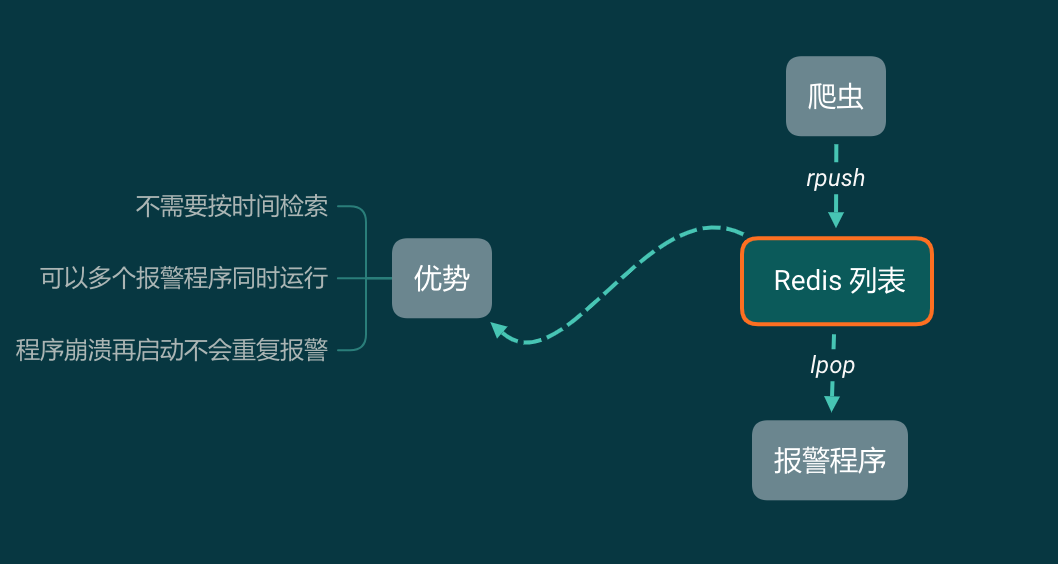
因为报警程序直接从 Redis 里面一条一条读取,不存在按时间搜索数据的过程,所以不会有数据延迟的问题。由于 Redis 是单线程数据库,所以可以同时启动很多个报警程序。由于 lpop 读取一条就删除一条,如果报警程序因为某种原因崩溃了,再把它启动起来即可,它会接着工作,不会重复报警。
但使用 Redis 列表的优势也是劣势:列表中的信息只能消费1次,被弹出了就没有了。
所以如果既需要报警,还需要把数据存入 MongoDB 备份,那么只有一个办法,就是报警程序检查完数据以后,把数据存入 MongoDB。
可我只是一个哨兵,为什么要让我做后勤兵的工作?
一个报警程序,让它做报警的事情就好了,它不应该做储存数据的事情。
而使用 Kafka,它有 Redis 列表的这些好处,但又没有 Redis 列表的弊端!
我们完全可以分别实现4个程序,不同程序之间消费数据的快慢互不影响。但同一个程序,无论是关闭再打开,还是同时运行多次,都不会重复消费。
程序1:报警
从 Kafka 中一条一条读取数据,做报警相关的工作。程序1可以同时启动多个。关了再重新打开也不会重复消费。
程序2:储存原始数据
这个程序从 Kafka 中一条一条读取数据,每凑够1000条就批量写入到 MongoDB 中。这个程序不要求实时储存数据,有延迟也没关系。 存入MongoDB中也只是原始数据存档。一般情况下不会再从 MongoDB 里面读取出来。
程序3:统计
从 Kafka 中读取数据,记录关键词、发布时间。按小时和分钟分别对每个关键词的微博计数。最后把计数结果保存下来。
程序4:情感分析
从 Kafka 中读取每一条数据,凑够一批发送给 NLP 分析接口。拿到结果存入后端数据库中。
如果要清洗数据怎么办
4个需求都解决了,那么如果还是需要你首先移除脏数据,再分析怎么办呢?实际上非常简单,你加一个 Kafka(Topic) 就好了!
大批量通用爬虫
除了上面的微博例子以外,我们再来看看在开发通用爬虫的时候,如何应用 Kafka。
在任何时候,无论是 XPath 提取数据还是解析网站返回的 JSON,都不是爬虫开发的主要工作。爬虫开发的主要工作一直是爬虫的调度和反爬虫的开发。
我们现在写 Scrapy 的时候,处理反爬虫的逻辑和提取数据的逻辑都是写在一个爬虫项目中的,那么在开发的时候实际上很难实现多人协作。
现在我们把网站内容的爬虫和数据提取分开,实现下面这样一个爬虫架构:
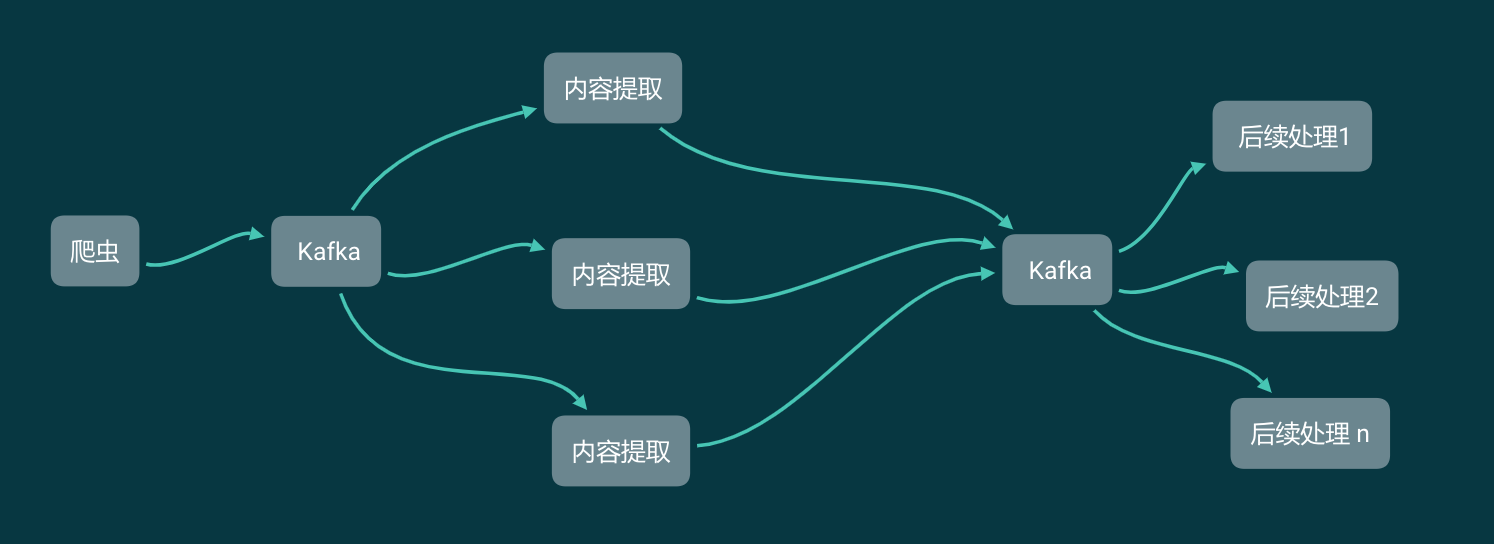
爬虫开发技术好的同学,负责实现绕过反爬虫,获取网站的内容,无论是 HTML 源代码还是接口返回的JSON。拿到以后,直接塞进 Kafka。
爬虫技术相对一般的同学、实习生,需要做的只是从 Kafka 里面获取数据,不需要关心这个数据是来自于 Scrapy 还是 Selenium。他们要做的只是把这些HTML 或者JSON 按照产品要求解析成格式化的数据,然后塞进 Kafka,供后续数据分析的同学继续读取并使用。
如此一来,一个数据小组的工作就分开了,每个人做各自负责的事情,约定好格式,同步开发,互不影响。
为什么是 Kafka 而不是其他
上面描述的功能,实际上有不少 MQ 都能实现。但为什么是 Kafka 而不是其他呢?因为Kafka 集群的性能非常高,在垃圾电脑上搭建的集群能抗住每秒10万并发的数据写入量。而如果选择性能好一些的服务器,每秒100万的数据写入也能轻松应对。
总结
这篇文章通过两个例子介绍了 Kafka 在爬虫开发中的作用。作为一个爬虫工程师,作为我的读者。请一定要掌握 Kafka。
下一篇文章,我们来讲讲如何使用 Kafka。比你在网上看到的教程会更简单,更容易懂。

关注本公众号,回复“爬虫与Kafka”获取本文对应的思维导图原图。
为什么每一个爬虫工程师都应该学习 Kafka的更多相关文章
- python爬虫(2)——编写一个爬虫
一.URL的编码与解码 在python2中包含的urllib和urllib2,都是接受URL请求相关的模块.但是在python3中,却没有urllib2.实际上urllib2的功能在python3中可 ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
- 专业的“python爬虫工程师”需要学习哪些知识?
学到哪种程度 暂且把目标定位初级爬虫工程师,简单列一下吧: (必要部分) 熟悉多线程编程.网络编程.HTTP协议相关 开发过完整爬虫项目(最好有全站爬虫经验,这个下面会说到) 反爬相关,cookie. ...
- (转)我在北京工作这几年 – 一个软件工程师的反省
我于2007年来到北京,在北京工作这些年,先后在NEC.风行.百度几家公司担任软件工程师的职务.NEC是一家具有百年历史的传统日企,在知春路的分公司叫日电电子,我们部门主要从事机顶盒.数字电视上嵌入式 ...
- 爬虫概念与编程学习之如何爬取视频网站页面(用HttpClient)(二)
先看,前一期博客,理清好思路. 爬虫概念与编程学习之如何爬取网页源代码(一) 不多说,直接上代码. 编写代码 运行 <!DOCTYPE html><html><head& ...
- 从零起步 系统入门Python爬虫工程师 ✌✌
从零起步 系统入门Python爬虫工程师 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 大数据时代,python爬虫工程师人才猛增,本课程专为爬虫工程师打造, ...
- 从零起步 系统入门Python爬虫工程师✍✍✍
从零起步 系统入门Python爬虫工程师 爬虫(又被称为网页蜘蛛,网络机器人)就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 原则上,只要是浏览器(客户端) ...
- Python爬虫工程师必学APP数据抓取实战✍✍✍
Python爬虫工程师必学APP数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
- Python爬虫工程师必学——App数据抓取实战
Python爬虫工程师必学 App数据抓取实战 整个课程都看完了,这个课程的分享可以往下看,下面有链接,之前做java开发也做了一些年头,也分享下自己看这个视频的感受,单论单个知识点课程本身没问题,大 ...
随机推荐
- html5 微信真机调试方法vConsole
html5 微信真机调试方法 vConsolehttps://blog.csdn.net/weixin_36934930/article/details/79870240
- pxe批量部署脚本
#!/bin/bash #检查环境 setenforce 0 sed -i 's/=enforce/=disabled/g' /etc/selinux/config systemctl restart ...
- lqb 基础练习 十六进制转八进制 (字符串进行进制转化)
基础练习 十六进制转八进制 时间限制:1.0s 内存限制:512.0MB 问题描述 给定n个十六进制正整数,输出它们对应的八进制数. 输入格式 输入的第一行为一个正整数n (1<=n ...
- Redis单节点数据同步到Redis集群
一:Redis集群环境准备 1:需要先安装好Redis集群环境并配置好集群 192.168.0.113 7001-7003 192.168.0.162 7004-7006 2:检查redis集群 [r ...
- 力扣(LeetCode)学生出勤记录I 个人题解
给定一个字符串来代表一个学生的出勤记录,这个记录仅包含以下三个字符: 'A' : Absent,缺勤 'L' : Late,迟到 'P' : Present,到场 如果一个学生的出勤记录中不超过一个' ...
- 领扣(LeetCode)二叉树的中序遍历 个人题解
给定一个二叉树,返回它的中序 遍历. 示例: 输入: [1,null,2,3] 1 \ 2 / 3 输出: [1,3,2] 进阶: 递归算法很简单,你可以通过迭代算法完成吗? 递归的思路很简单,不再累 ...
- C语言|博客作业04
这个作业属于哪个课程 C语言程序设计II 这个作业的要求在哪里 https://edu.cnblogs.com/campus/zswxy/CST2019-1/homework/9768 我在这个课程的 ...
- django:runserver实现远程访问
如果是在另一台电脑上web访问要用 python manage.py ip:port (一般使用8000)的形式:监听所有ip用0.0.0.0如下: 1 2 3 python manage.py ru ...
- Matplotlib入门简介
Matplotlib是一个用Python实现的绘图库.现在很多机器学习,深度学习教学资料中都用它来绘制函数图形.在学习算法过程中,Matplotlib是一个非常趁手的工具. 一般概念 图形(figur ...
- PHP 模板引擎
PHP模板引擎的由来 ● 为了解决当时混合开发WEB应用出现的一系列问题:代码难维护,代码不可重用,程序员要求知识广等问题 ● 实现后端与前端不完全分离,开发与美工可以分工合作,提高效率 PHP模板引 ...