Stanford公开课《编译原理》学习笔记(2)递归下降法
示例代码托管在:http://www.github.com/dashnowords/blogs
博客园地址:《大史住在大前端》原创博文目录
华为云社区地址:【你要的前端打怪升级指南】
B站地址:【编译原理】
Stanford公开课:【Stanford大学公开课官网】
课程里涉及到的内容讲的还是很清楚的,但个别地方有点脱节,建议课下自己配合经典著作《Compilers-priciples, Techniques and Tools》(也就是大名鼎鼎的龙书)作为补充阅读。
一. Parse阶段
词法分析阶段的任务是将字符串转为Token组,而Parse阶段的目标是将Token变为Parse Tree,本篇只是这部分内容最基础的一部分。
CFG
CFG即context free grammer,定义一种CFG语法规则需要声明如下特征:

- 一组终止符号集,也称为“词法单元”
- 一组非终止符号集,也称为“语法变量”
- 一个开始符号集
- 若干产生式规则(产生式则就是指在当前
CFG的语法下,产生符号->左右两侧可以互相替代)
CFG的基本转换流程如下:
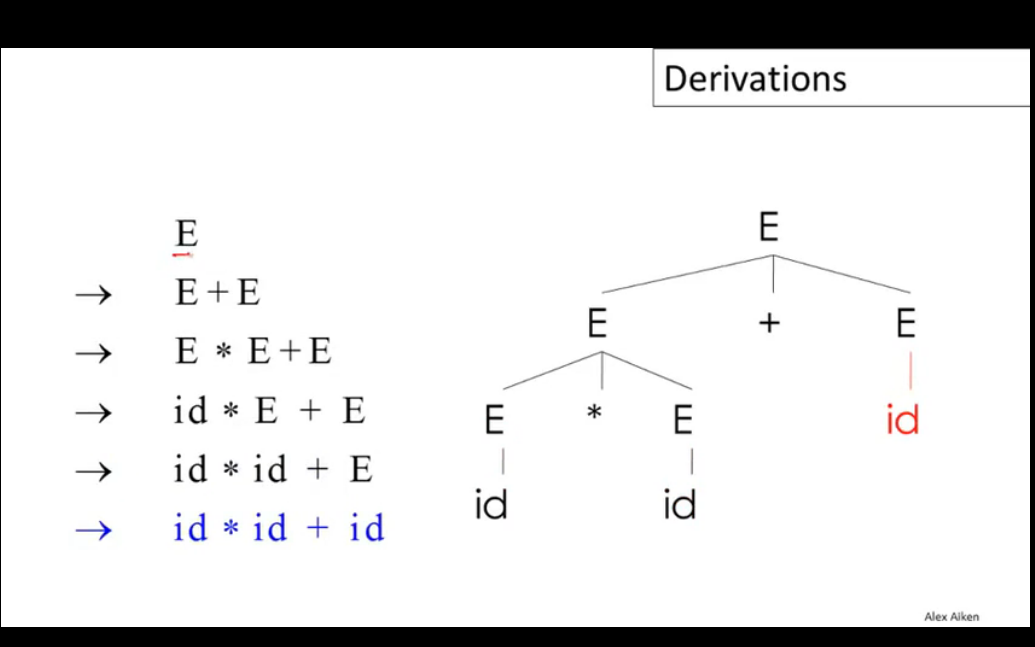
从隶属于开始集S开始,尝试将字符串中的非终止符X替换为终止集的形式(X->Y1Y2...Yn),重复这个步骤直到字符串序列中不再有非终止符。这个过程被称为Derivation(派生),它是一系列变换过程的序列,可以转换为树的形式,树的根节点即为起始集合S中的成员,转换后的每个终止集以子节点的形式挂载在根节点下,这棵生成的树就被称为Parse Tree,可以看出最后的结果实际上就是Parse Tree的叶节点遍历结果。
当需要转换的非终结字符有多个时,需要按照一定的顺序来逐个推导,派生过程可以按照left-most或right-most进行,但有时会得到不同的合法的转换树,通常会通过修改转换集语法或设定优先级来解决。
Recursive Descent(递归下降遍历)
Recursive Descent是一种遍历parse tree的策略,是一种典型的递归回溯算法,从树的根节点开始,逐个尝试当前父节点上记录的非终止字符能够支持的产生规则,并判断其子节点是否符合这样的形式,直到子节点符合某个特定的产生式规则,然后再继续递归进行深度遍历,如果在某个非终止节点上尝试完所有的产生式规则都无法继续向下进行使得子树的叶节点都符合终止符号集,则需要通过回溯到上一节点并尝试父节点的下一个产生式规则,使得循环程序可以继续向后进行。课程里用了很多的数学符号定义和伪代码来描述递归遍历的过程,如果觉得太抽象不好理解可以暂时略过。需要注意左递归文法会使得递归下降遍历进入死循环,在文法设计时应该避免,龙书中也提供了一种通用的拆分方法来解决这个问题。
二. 递归下降遍历
【声明】由于课程中并没有看到从
tokens到parse tree的全貌,只能先逐步消化基础知识。下文的过程只是笔者自己的理解(尤其是逐行分析的形式,因为尚未涉及任何结构性语法,所以通用性还有待考量),仅供参考,也欢迎交流指正。但对于直观理解递归下降法而言是足够的。
2.1 预备知识
本节中使用JavaScript来实现递归下降遍历,目标代码仍是上一篇博文中的示例代码:
var b3 = 2;
a = 1 + ( b3 + 4);
return a;
经过上一节的分词器后可以得到下面的词素序列:
[ 'keywords', 'var' ],
[ 'id', 'b3' ],
[ 'assign', '=' ],
[ 'num', '2' ],
[ 'semicolon', ';' ],
[ 'id', 'a' ],
[ 'assign', '=' ],
[ 'num', '1' ],
[ 'plus', '+' ],
[ 'lparen', '(' ],
[ 'id', 'b3' ],
[ 'plus', '+' ],
[ 'num', '4' ],
[ 'rparen', ')' ],
[ 'semicolon', ';' ],
[ 'keywords', 'return' ],
[ 'id', 'a' ],
[ 'semicolon', ';' ]
语法分析是基于语法规则的,所谓语法规则,通常是指一系列CFG表示的产生式,大多数开发者并不具备设计一套语法规则的能力,此处直接借鉴Mozilla中的Javascript引擎SpiderMonkey中的文法定义来进行基本产生式,由于Javascript语言中涉及的文法非常多,本节只筛选出与目标解析式相关的一部分简化的语法规则(图中标记为蓝色的部分):
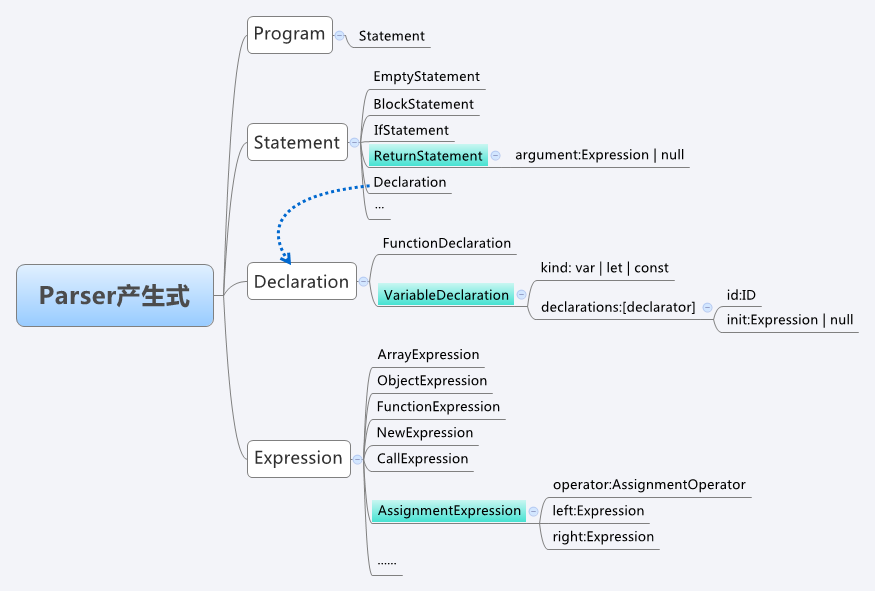
完整的语法规则可以查看【SpiderMonkey_ParserAPI】进行了解。
2.2 多行语句的处理思路
我们把上面的目标解析代码当做是一段Javascript代码,自顶向下分析时,根节点的类型是Program,它可以由多个Statement节点(语句节点)构成,所以本例中进行简化后以semicolon(分号)作为词素批量处理的分界点,每次将两个分号之间的部分读入缓冲区进行分析,由于上例中均为单行语句,所以理解起来比较简单。
在更为复杂的情况中,代码中包含条件语句,循环语句等一些结构化的关键词时可能会存在跨行的语句,此时可以在递归下降之前先对缓冲区的词素队列进行基本的结构分析,如果发现匹配的结构化模式,就从tokens序列中将下一行(或多行)也读入缓冲区,直到缓冲区中的所有tokens放在一起符合了某些特定的结构,再开始进行递归下降。
2.3 简易的文法定义
为方便理解,本例中均使用关键词缩写来表示可能的语法规则集,如果你对Javascript语言有一定了解,它们是非常容易理解的
/**
* 文法定义-生产规则
* Program -> Statement
* P -> S
*
* 语句 -> 块状语句 | if语句 | return语句 | 声明 | 表达式 |......
* Statement -> BlockStatement | IfStatement | ReturnStatement | Declaration | Expression |......
* S -> B | I | R | D | E
*
* B -> { Statement }
*
* I -> if ( ExpressionStatement ) { Statement }
*
* R -> return Expression | null
*
* 声明 -> 函数声明 | 变量声明
* Declaration -> FunctionDeclaration | VariableDeclaration
* D -> F | V
*
* F -> function ID ( SequenceExpression ) { ... }
*
* V -> 'var | let | const' ID [= Expression | Null] ?
*
* 表达式 -> 赋值表达式 | 序列表达式 | 一元运算表达式 | 二元运算表达式 |......
* Expression -> AssignmentExpression | SequenceExpression | UnaryExpression | BinaryExpression | BracketExpression......
* E -> A | Seq | U | BI | BRA |...
*
* A -> E = E //赋值表达式
*
* Seq -> ID,ID,ID//类似形式
*
* //一元表达式
* U -> "-" | "+" | "!" | "~" | "typeof" | "void" | "delete" E
*
* //二元表达式
* BI -> E "==" | "!=" | "===" | "!=="
| "<" | "<=" | ">" | ">="
| "<<" | ">>" | ">>>"
| "+" | "-" | "*" | "/" | "%"
| "|" | "^" | "&" | "in"
| "instanceof" | ".." E
*
* //括号表达式
* BRA -> ( E )
*
* N -> null
*/
需要额外注意的是表达式Expression到赋值表达式AssignmentExpression的产生式,E的判断规则里需要判断A,而A的逻辑里又再次调用了E,这里就是一种左递归,如果不进行任何处理,在代码运行时就会陷入死循环然后爆栈,这也就是前文强调的需要在语法产生式设计时消除左递归的场景。这里并不是说spiderMonkey的parserAPI是错的,因为消除左递归的语法改造只是一种等价形式的转换,是为了防止产生式产生无限递推(或者说程序实现时进入无限递归的死循环)而做的一种形式处理,改造的过程可能只是引入了某个中间集合来消除这种场景的影响,对于最终的语法表意并不会产生影响。
下文示例代码中并没有进行严谨的"左递归消除",而是简单地使用了一个E_集合,与原本的E进行一些微小的差异区分,从而避免了死循环。
2.4 文法产生式的代码转换
下面将上一小节的语法规则进行代码翻译(只包含部分产生式的推导,本例中的完整代码可以从demo或代码仓中获取):
//判断是否为Statement
function S(tokens) {
//把结尾的分号全部去除
while(tokens[tokens.length - 1][0] === TT.semicolon){
tokens.pop();
}
return B(tokens) || I(tokens) || R(tokens) || D(tokens) || E(tokens);
}
//判断是否为BlockStatement B -> { Statement } (本例中并不涉及本方法,故暂不考虑末尾分号和文法递归的情况)
function B(tokens) {
//本例中不涉及,直接返回false
return false;
}
//判断是否为IfStatement I -> if ( ExpressionStatement ) { Statement }
function I(tokens) {
//本例中不涉及,直接返回false
return false;
}
//判断是否为ReturnStatement R -> return Expression | null
function R(tokens) {
return isReturn(tokens[0]) && (E(tokens.slice(1)) || N(tokens.slice(1)[0]));
}
//判断是否为声明语句 Declaration -> FunctionDeclaration | VariableDeclaration
function D(tokens) {
return F(tokens) || V(tokens);
}
//判断是否为函数声明 F -> function ID ( SequenceExpression ) { ... }
function F(tokens) {
//本例中不涉及,直接返回false
return false;
}
//判断是否为变量声明 V -> 'var | let | const' ID [= Expression | Null] ?
function V(tokens) {
//判断为1.单纯的声明 还是 2.带有初始值的声明
if (tokens.length === 2) {
return isVariableDeclarationKeywords(tokens[0]) && tokens[1][0] === TT.id;
}
return isVariableDeclarationKeywords(tokens[0]) && (A(tokens.slice(1))) || N(tokens.slice(1));
}
//....其他代码形式雷同,不再赘述
2.5 逐行解析
解析时默认每次遇到一个分号时表示一个statement的结束,前文已经提及过对于多行语句的处理思路。实现时只需要将tokens序列一点点读进buffer数组并从顶层的S方法启动分析,即可完成自顶向下的推理过程。
/**parser */
function parse(tokens) {
let buffer = nextStatement(tokens);
let flag = true;
while (buffer && flag){
if (!S(buffer)) {
console.log('检测到不符合语法的tokens序列');
flag = false;
}
buffer = nextStatement(tokens);
}
//如果没有出错则提示正确
flag && console.log('检测结束,被检测tokens序列是合法的代码段');
}
//将下一个Statement全部读入缓冲区
function nextStatement(tokens) {
let result = [];
let token;
while(tokens.length) {
token = tokens.shift();
result.push(token);
//如果不是换行符则
if (token[0] === CRLF) {
break;
}
}
return result.length ? result : null;
}
2.6 查看计算过程
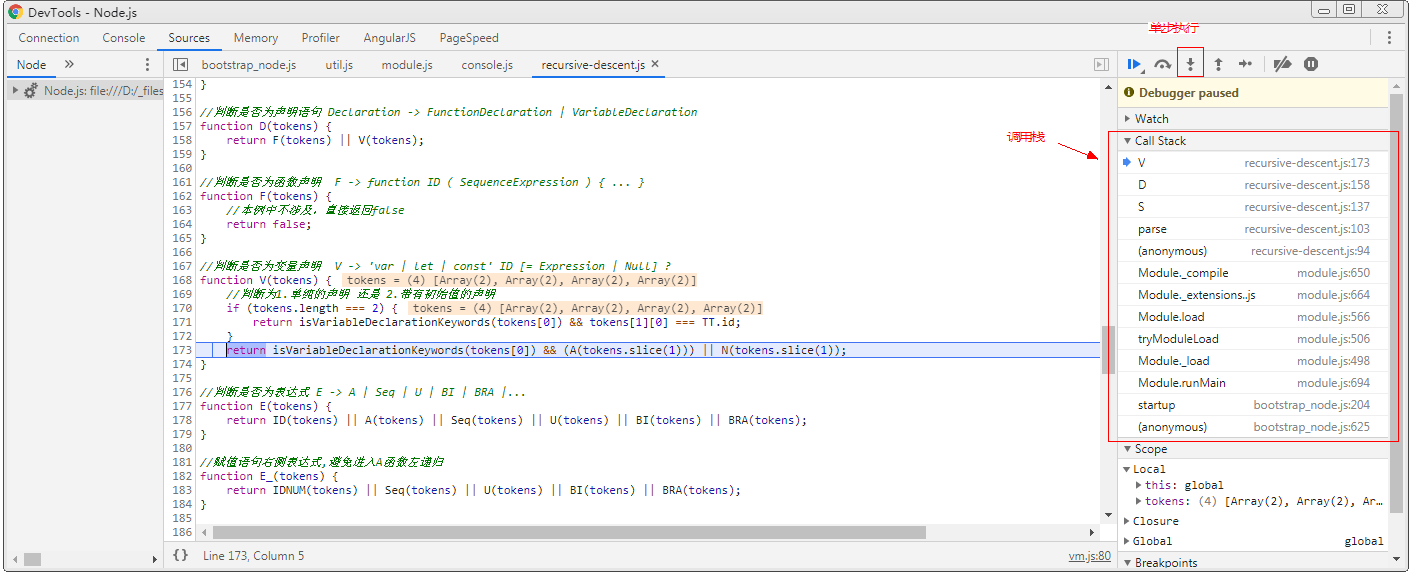
单步执行查看计算过程可以帮助我们更好地理解递归下降法的执行过程:
在demo所在目录下打开命令行,输入:node --inspect-brk recursive-descent.js,然后单步执行就很容易看出代码在执行过程中如何实现递归和回溯:
三.小结
单纯地递归下降法最终的结果只找出了不满足任何语法规则的语句,或是最终所有语句都符合语法规则时给出提示,但并没有得到一个树结构的对象,也没有向下一个环节提供输出,如何在编译过程中与后续环节进行连接还有待探索。
Stanford公开课《编译原理》学习笔记(2)递归下降法的更多相关文章
- 编译原理学习笔记·语法分析(LL(1)分析法/算符优先分析法OPG)及例子详解
语法分析(自顶向下/自底向上) 自顶向下 递归下降分析法 这种带回溯的自顶向下的分析方法实际上是一种穷举的不断试探的过程,分析效率极低,在实际的编译程序中极少使用. LL(1)分析法 又称预测分析法, ...
- Stanford公开课《编译原理》学习笔记(1~4课)
目录 一. 编译的基本流程 二. Lexical Analysis(词法分析阶段) 2.1 Lexical Specification(分词原则) 2.2 Finite Automata (典型分词算 ...
- CNN学习笔记:梯度下降法
CNN学习笔记:梯度下降法 梯度下降法 梯度下降法用于找到使损失函数尽可能小的w和b,如下图所示,J(w,b)损失函数是一个在水平轴w和b上面的曲面,曲面的高度表示了损失函数在某一个点的值
- Unity3D 骨骼动画原理学习笔记
最近研究了一下游戏中模型的骨骼动画的原理,做一个学习笔记,便于大家共同学习探讨. ps:最近改bug改的要死要活,博客写的吭哧吭哧的~ 首先列出学习参考的前人的文章,本文较多的参考了其中的表述: 1. ...
- Java并发之底层实现原理学习笔记
本篇博文将介绍java并发底层的实现原理,我们知道java实现的并发操作最后肯定是由我们的CPU完成的,中间经历了将java源码编译成.class文件,然后进行加载,然后虚拟机执行引擎进行执行,解释为 ...
- TCP/IP协议原理学习笔记
昨天学习了杨宁老师的TCP/IP协议原理第一讲和第二讲,主要介绍了OSI模型,整理如下: OSI是open system innerconnection的简称,即开放式系统互联参考模型,它把网络协议从 ...
- elasticsearch原理学习笔记
https://mp.weixin.qq.com/s/dn1n2FGwG9BNQuJUMVmo7w 感谢,透彻的讲解 整理笔记 请说出 唐诗中 包含 前 的诗句 ...... 其实你都会,只是想不起 ...
- 个人MySQL的事务特性原理学习笔记总结
目录 个人MySQL的事务特性原理笔记总结 一.基础概念 2. 事务控制语句 3. 事务特性 二.原子性 1. 原子性定义 2. 实现 三.持久性 1. 定义 2. 实现 3. redo log存在的 ...
- Jvm工作原理学习笔记(转)
一. JVM的生命周期 1. JVM实例对应了一个独立运行的java程序它是进程级别 a) 启动.启动一个Java程序时,一个JVM实例就产生了,任何一个拥有pub ...
随机推荐
- TK可视化之文件内容查找(升级篇)
升级为带有选择框 分三种查看格式一种是表格查看 一种是文本查看 一种是列表 1.列表查看类 # listbox 显示数据 import tkinter class ListShowData: def ...
- 同步vmware虚拟机和主机的时间
1. 打开虚拟机->设置 2. 选择选项标签页,选中VMware Tools,勾选“将客户机时间与主机同步”
- HDU - 5128The E-pang Palace+暴力枚举,计算几何
第一次写计算几何,ac,感动. 不过感觉自己的代码还可以美化一下. 传送门:http://acm.hdu.edu.cn/showproblem.php?pid=5128 题意: 在一个坐标系中,有n个 ...
- 章节十六、8-ITestResult接口
一.ITestResult:该接口就像一个监听器,能够监听每个方法执行后的状态(是否成功)并将结果返回给我们. package testclasses1; import org.testng.anno ...
- docker 搭建自己的github
github 搭建: 自己搭建一个github网站(仓库) daocloud:公共hub搜索git下载github镜像 docker pull gitlab/gitlab-ce:8.7.0-r ...
- IDEA中输出syso的快捷键设置
1. 2. 3. 4. 5.上图中的第三步会出现警告,那个红色的字,点击Define,选择Java 6.之后点击Apply和OK即可
- BZOJ 刷题总结(持续更新)
本篇博客按照题号排序(带*为推荐题目) 1008 [HNOI2008]越狱 很经典的题了..龟速乘,龟速幂裸题,, 1010 [HNOI2008]玩具装箱toy* 斜率优化 基本算是裸题. 1012 ...
- 深入理解three.js中光源
前言: Three.js 是一个封装了 WebGL 接口的非常好的库,简化了 WebGL 很多细节,降低了学习成本,是当前前端开发者完成3D绘图的得力工具,那么今天我就给大家详细讲解下 Three.j ...
- 用101000张食物图片实现图像识别(数据的获取与处理)-python-tensorflow框架
前段时间,日剧<轮到你了>大火,作为程序员的我,看到了另外一个程序员—二阶堂,他的生活作息,以及饮食规律,让我感同身受,最让我感触的是他做的AI聊天机器人,AI菜品分析机器人,AI罪犯分析 ...
- 关于样式style
今天看到了一个bgcolor和以前看过的background-color,特意查了一下区别 百度是这么说的:background-color是标准CSS属性,bgcolor应该是IE扩展的html元素 ...