数据结构丨N叉树
遍历
N叉树的遍历
树的遍历
一棵二叉树可以按照前序、中序、后序或者层序来进行遍历。在这些遍历方法中,前序遍历、后序遍历和层序遍历同样可以运用到N叉树中。
回顾 - 二叉树的遍历
- 前序遍历 - 首先访问根节点,然后遍历左子树,最后遍历右子树;
- 中序遍历 - 首先遍历左子树,然后访问根节点,最后遍历右子树;
- 后序遍历 - 首先遍历左子树,然后遍历右子树,最后访问根节点;
- 层序遍历 - 按照从左到右的顺序,逐层遍历各个节点。
请注意,N叉树的中序遍历没有标准定义,中序遍历只有在二叉树中有明确的定义。尽管我们可以通过几种不同的方法来定义N叉树的中序遍历,但是这些描述都不是特别贴切,并且在实践中也不常用到,所以我们暂且跳过N叉树中序遍历的部分。
把上述关于二叉树遍历转换为N叉树遍历,我们只需把如下表述:
遍历左子树... 遍历右子树...
变为:
对于每个子节点:
通过递归地调用遍历函数来遍历以该子节点为根的子树
我们假设for循环将会按照各个节点在数据结构中的顺序进行遍历:通常按照从左到右的顺序,如下所示。
N叉树遍历示例
我们用如图所示的三叉树来举例说明:
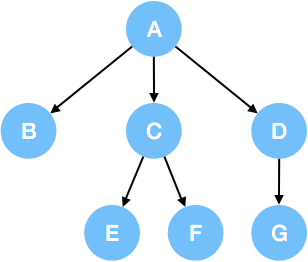
1.前序遍历
在N叉树中,前序遍历指先访问根节点,然后逐个遍历以其子节点为根的子树。
例如,上述三叉树的前序遍历是: A->B->C->E->F->D->G.
2.后序遍历
在N叉树中,后序遍历指前先逐个遍历以根节点的子节点为根的子树,最后访问根节点。
例如,上述三叉树的后序遍历是: B->E->F->C->G->D->A.
3.层序遍历
N叉树的层序遍历与二叉树的一致。通常,当我们在树中进行广度优先搜索时,我们将按层序的顺序进行遍历。
例如,上述三叉树的层序遍历是: A->B->C->D->E->F->G.
练习
接下来,我们将为你提供几道与N叉树相关的习题。
N-ary Tree Preorder Traversal
给定一个 N 叉树,返回其节点值的前序遍历。
例如,给定一个 3叉树 :
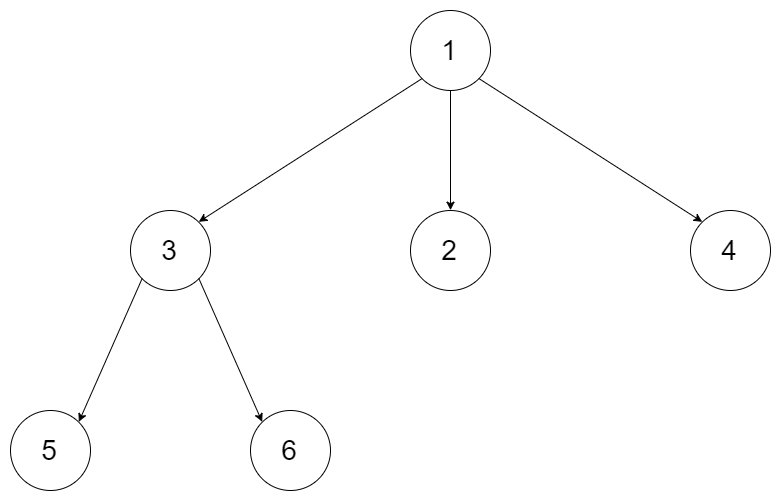
返回其前序遍历: [1,3,5,6,2,4]。
说明: 递归法很简单,你可以使用迭代法完成此题吗?
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
class Node{
public:
int val;
vector<Node*> children;
Node(){}
Node(int _val, vector<Node*>_children){
val = _val;
children = _children;
}
};
/// Recursion
/// Time Complexity: O(n)
/// Space Complexity: O(h)
class SolutionA{
public:
vector<int> preorder(Node* root){
vector<int> res;
dfs(root, res);
return res;
}
private:
void dfs(Node* node, vector<int>& res){
if(!node)
return;
res.push_back(node->val);
for(Node* next: node->children)
dfs(next, res);
}
};
/// Non-Recursion
/// Using stack
/// Time Complexity: O(n)
/// Space Complexity: O(h)
class SolutionB{
public:
vector<int> preorder(Node* root){
vector<int> res;
if(!root)
return res;
stack<Node*> stack;
stack.push(root);
while(!stack.empty()){
Node* cur = stack.top();
stack.pop();
res.push_back(cur->val);
for(vector<Node*>::reverse_iterator iter = cur->children.rbegin();
iter != cur->children.rend(); iter++)
stack.push(*iter);
}
return res;
}
};
int main(){
return 0;
}
N-ary Tree Postorder Traversal
给定一个 N 叉树,返回其节点值的后序遍历。
例如,给定一个 3叉树 :
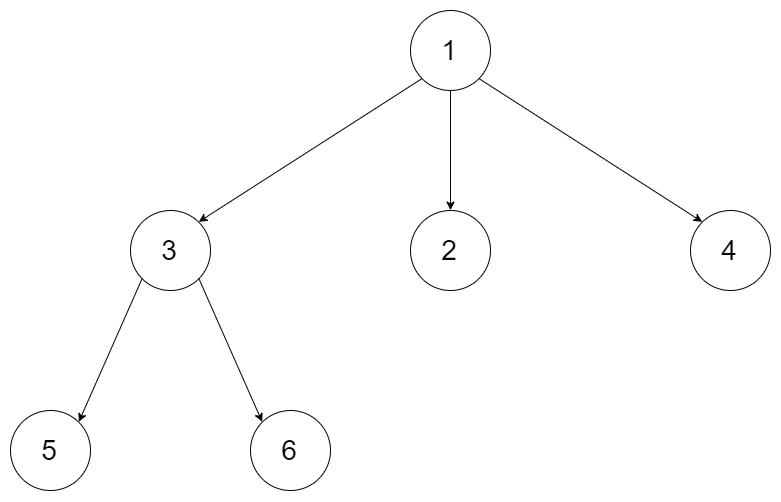
返回其后序遍历: [5,6,3,2,4,1].
说明: 递归法很简单,你可以使用迭代法完成此题吗?
#include <iostream>
#include <vector>
#include <stack>
using namespace std;
class Node{
public:
int val;
vector<Node*> children;
Node(){}
Node(int _val, vector<Node*> _children){
val = _val;
children = _children;
}
};
/// Recursion
/// Time Complexity: O(n)
/// Space Complexity: O(h)
class SolutionA{
public:
vector<int> postorder(Node* root){
vector<int> res;
dfs(root, res);
return res;
}
private:
void dfs(Node* node, vector<int>& res){
if(!node)
return;
for(Node* next: node->children)
dfs(next, res);
res.push_back(node->val);
}
};
/// Non-Recursion
/// Using stack
///
/// Time Complexity: O(n)
/// Space Complexity: O(h)
class SolutionB{
public:
vector<int> postorder(Node* root){
vector<int> res;
if(!root)
return res;
stack<Node*> stack;
stack.push(root);
while(!stack.empty()){
Node* cur = stack.top();
stack.pop();
res.push_back(cur->val);
for(Node* next: cur->children)
stack.push(next);
}
reverse(res.begin(), res.end());
return res;
}
};
int main(){
return 0;
}
N叉树的层序遍历
给定一个 N 叉树,返回其节点值的层序遍历。 (即从左到右,逐层遍历)。
例如,给定一个 3叉树 :
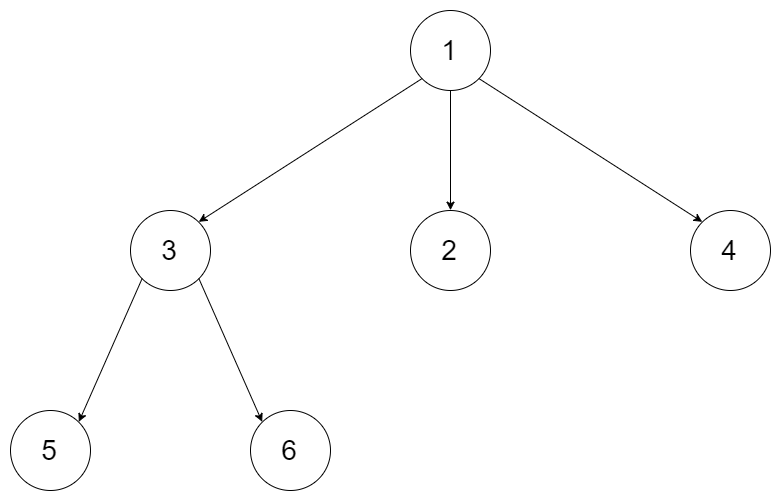
返回其层序遍历:
[
[1],
[3,2,4],
[5,6]
]
说明:
- 树的深度不会超过
1000。 - 树的节点总数不会超过
5000。
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
class Node {
public:
int val = NULL;
vector<Node*> children;
Node() {}
Node(int _val, vector<Node*> _children) {
val = _val;
children = _children;
}
};
/// BFS
/// Store step in the queue
///
/// Time Complexity: O(n)
/// Space Complexity: O(n)
class SolutionA{
public:
vector<vector<int>> levelOrder(Node* root){
vector<vector<int>> res;
if(!root)
return res;
queue<pair<Node*, int>> q;
q.push(make_pair(root, 0));
while(!q.empty()){
Node* cur = q.front().first;
int step = q.front().second;
q.pop();
if(step == res.size())
res.push_back({cur->val});
else
res[step].push_back(cur->val);
for(Node* next: cur->children)
q.push(make_pair(next, step + 1));
}
return res;
}
};
int main(){
return 0;
}
递归
N叉树的经典递归解法
经典递归法
我们在之前的章节中讲过如何运用递归法解决二叉树问题。在这篇文章中,我们着重介绍如何将这个思想引入到N叉树中。
在阅读以下内容之前,请确保你已阅读过 运用递归解决树的问题 这篇文章。
- "自顶向下"的解决方案
"自顶向下"意味着在每个递归层次上,我们首先访问节点以获得一些值,然后在调用递归函数时,将这些值传给其子节点。
一个典型的 "自顶向下" 函数 top_down(root, params) 的工作原理如下:
1. 对于 null 节点返回一个特定值
2. 如果有需要,对当前答案 answer 进行更新 // answer <-- params
3. for each child node root.children[k]:
4. ans[k] = top_down(root.children[k], new_params[k]) // new_params <-- root.val, params
5. 如果有需要,返回答案 answer // answer <-- all ans[k]
- "自底向上"的解决方案
"自底向上" 意味着在每个递归层次上,我们首先为每个子节点递归地调用函数,然后根据返回值和根节点本身的值给出相应结果。
一个典型的 "自底向上" 函数 bottom_up(root) 的工作原理如下:
1.对于 null 节点返回一个特定值
2.for each child node root.children[k]:
3. ans[k] = bottom_up(root.children[k]) // 为每个子节点递归地调用函数
4. 返回答案 answer // answer <- root.val, all ans[k]
Maximum Depth of N-ary Tree
给定一个 N 叉树,找到其最大深度。
最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
例如,给定一个 3叉树 :
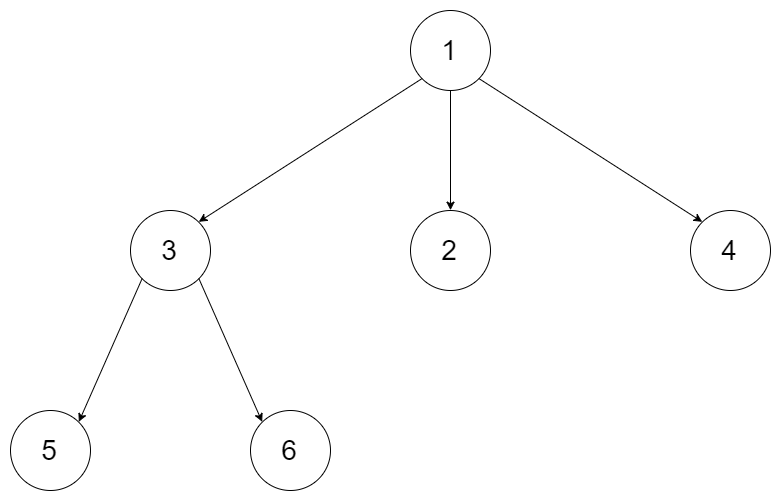
我们应返回其最大深度,3。
说明:
- 树的深度不会超过
1000。 - 树的节点总不会超过
5000。
#include <iostream>
#include <vector>
using namespace std;
/// DFS
/// Time Complexity: O(n)
/// Space Complexity: O(n)
/// Definition for a Node.
class Node{
public:
int val;
vector<Node*> children;
Node(){}
Node(int _val, vector<Node*> _children){
val = _val;
children = _children;
}
};
class Solution{
public:
int maxDepth(Node* root){
if(!root)
return 0;
int res = 1;
for(Node* child: root->children)
res = max(res, 1 + maxDepth(child));
return res;
}
};
int main(){
return 0;
}
小结
这张卡旨在介绍N叉树的基本思想。 实际上,二叉树只是N叉树的一种特殊形式,N叉树相关问题的解决方案与二叉树的解法十分相似。 因此,我们可以把在二叉树中学到的知识扩展到N叉树中。
我们提供了一些经典的N叉树习题,以便进一步帮助你理解本章中N叉树的概念。
数据结构丨N叉树的更多相关文章
- C#数据结构-线索化二叉树
为什么线索化二叉树? 对于二叉树的遍历,我们知道每个节点的前驱与后继,但是这是建立在遍历的基础上,否则我们只知道后续的左右子树.现在我们充分利用二叉树左右子树的空节点,分别指向当前节点的前驱.后继,便 ...
- js:数据结构笔记9--二叉树
树:以分层的方式存储数据:节点:根节点,子节点,父节点,叶子节点(没有任何子节点的节点):层:根节点开始0层: 二叉树:每个节点子节点不超过两个:查找快(比链表),添加,删除快(比数组): BST:二 ...
- 线索化二叉树的构建与先序,中序遍历(C++版)
贴出学习C++数据结构线索化二叉树的过程, 方便和我一样的新手进行测试和学习 同时欢迎各位大神纠正. 不同与普通二叉树的地方会用背景色填充 //BinTreeNode_Thr.h enum Point ...
- ID3算法 决策树 C++实现
人工智能课的实验. 数据结构:多叉树 这个实验我写了好久,开始的时候从数据的读入和表示入手,写到递归建树的部分时遇到了瓶颈,更新样例集和属性集的办法过于繁琐: 于是参考网上的代码后重新写,建立决策树类 ...
- 树形动态规划(树状DP)小结
树状动态规划定义 之所以这样命名树规,是因为树形DP的这一特殊性:没有环,dfs是不会重复,而且具有明显而又严格的层数关系.利用这一特性,我们可以很清晰地根据题目写出一个在树(型结构)上的记忆化搜索的 ...
- 【清北学堂2018-刷题冲刺】Contest 8
Task 1:关联点 [问题描述] ⼆叉树是⼀种常用的数据结构,⼀个⼆叉树或者为空,或者由根节点.左⼦树.右⼦树构成,其中左⼦树和右⼦树都是⼆叉树. 每个节点a 可以存储⼀个值val. 显然,如果 ...
- web(三)html标签
标签的层级特性 闭合的html标签内可以包含一个或多个子标签,因此html的标签是一个多叉树的数据结构,多叉树的根是html标签. 标签的属性描述 每个标签都具备一组公用或当前标签独有的属性,属性的作 ...
- 数据结构与算法系列研究五——树、二叉树、三叉树、平衡排序二叉树AVL
树.二叉树.三叉树.平衡排序二叉树AVL 一.树的定义 树是计算机算法最重要的非线性结构.树中每个数据元素至多有一个直接前驱,但可以有多个直接后继.树是一种以分支关系定义的层次结构. a.树是n ...
- Python Treelib 多叉树 数据结构 中文使用帮助文档
树,对于计算机编程语言来说是一个重要的数据结构.它具有广泛的应用,比如文件系统的分层数据结构和机器学习中的一些算法.这里创建了treelib来提供Python中树数据结构的高效实现. 官方文档:htt ...
随机推荐
- C#连接oracle 数据库查询时输入中文查询不出来,用plsql就可以
查询语句为:select * from Per where khmc like '%李%',其实是字符集的问题. 解决方案:在连接字符串加一个“Unicode=True;”
- 关于SetLocaleInfo()
原文:关于SetLocaleInfo() 此函数用于设置系统的一些本地信息, 非常有用. 比如日期格式为'yyyy/mm/dd'时, 稍微不注意,有些程序语句会报错. 以下资料网络收集: 1. Set ...
- 以太坊(ethereum)开发DApp应用的入门区块链技术教程
概述 对初学者,首先要了解以太坊开发相关的基本概念. 学习以太坊开发的一般前序知识要求,最好对以下技术已经有一些基本了解: 一种面向对象的开发语言,例如:Python,Ruby,Java... 前 ...
- React Native v0.4 发布,用 React 编写移动应用
React Native v0.4 发布,自从 React Native 开源以来,包括超过 12.5k stars,1000 commits,500 issues,380 pull requests ...
- SIP:用Riverbank的SIP创建C++库的Python模块(把自己的C++库包装成Python模块)
我们发现PyQt做的Python版的PyQt是如此好用,如果想把自己的C++库包装成Python模块该如何实现呢? 这里介绍下用SIP包装C++库时值得参考的功能实现: 需要Python模块中实现C+ ...
- 使用SqlSugar封装的数据层基类
首先简单封装了个DbContext public class DbContext { #region 属性字段 private static string _connectionString; /// ...
- ASP.NET Web API 直到我膝盖中了一箭【1】基础篇
蓦然回首,那些年,我竟然一直很二. 小时候,读武侠小说的时候,看到那些猪脚,常常会产生一种代入感,幻想自己也会遭遇某种奇遇,遇到悬崖跳下去是不是有本“武林秘笈”在等着?长大以后也是一样,多少人梦着醒着 ...
- Mysql 自定义HASH索引带来的巨大性能提升
有这样一个业务场景,需要在2个表里比较存在于A表,不存在于B表的数据.表结构如下: T_SETTINGS_BACKUP | CREATE TABLE `T_SETTINGS_BACKUP` ( `FI ...
- Redis EXISTS命令耗时过长case排查
一.背景 redis慢日志分析平台上线后,随便看了一下,发现onestore使用的缓存集群,存在大量的EXISTS命令慢查询的情况: 平均每个EXISTS命令需要13ms,最大耗时近20ms.这个结果 ...
- vue+TS(CLI3)
1.用CLI3创建项目 查看当前CLI的版本,如果没有安装CLI3的 使用npm install --global vue-cli来安装CLI 安装好CLI 可以创建项目了 使用vue create ...