论文阅读 | Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
简述
在文本语义相似度等句子对的回归任务上,BERT , RoBERTa 拿到sota。
但是,它要求两个句子都被输入到网络中,从而导致巨大开销:从10000个句子集合中找到最相似的sentence-pair需要进行大约5000万个推理计算(约65小时)。
BERT不适合语义相似度搜索,也不适合非监督任务,比如聚类。
解决聚类和语义搜索的一种常见方法是将每个句子映射到一个向量空间,使得语义相似的句子很接近。
于是,也有人尝试向BERT输入单句,得到固定大小的sentene embedding。最常用的方法是,平均BERT输出层或使用第一个token([CLS]的token)的输出。但这却产生了非常不好的sentence embedding,常常还不如averaging GloVe embeddings。
本文提出:Sentence-BERT(SBERT),对预训练的BERT进行修改:使用Siamese和三级(triplet)网络结构来获得语义上有意义的句子embedding->可以生成定长的sentence embedding,使用余弦相似度或Manhatten/Euclidean距离等进行比较找到语义相似的句子。
SBERT保证准确性的同时,可将上述提到的BERT/RoBERTa的65小时减少到5s。(计算余弦相似度大概0.01s)
除了语义相似度搜索,也可用来clustering搜索。
作者在NLI data中fine-tune SBERT,用时不到20分钟。
SBERT
pooling策略:
MEAN策略:使用CLS-token的输出,对所有输出向量取mean。
MAX策略:使用CLS-token的输出,对所有输出向量计算max-over-time。
C
目标函数:
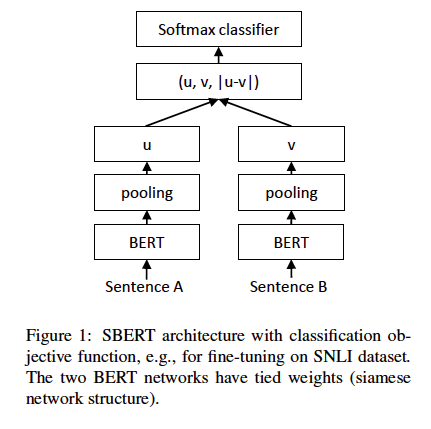
分类:
计算sentence embeedings u 和 v的element-wise差值并乘以权重:
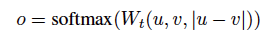
其中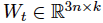 ,n是sentence embedding的纬度,k是label的数量。
,n是sentence embedding的纬度,k是label的数量。
loss:交叉熵
如图1:
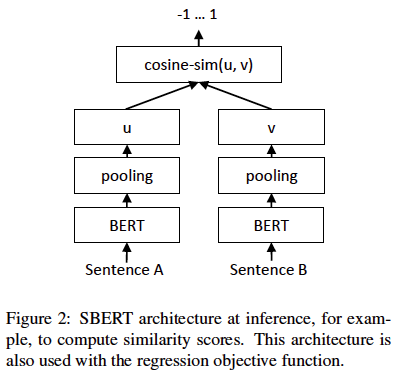
回归:
计算两个sentence embedding(u & v)的余弦相似度。
loss:均方误差
如图2:
Triplet:
输入:anchor sentence a,positive sentence p, negative sentence n
loss的目的是让a和p之间的距离小于a和n之间的距离:

Sa Sp Sn 分别是 a p n 的sentence embedding。|| · || 是距离测度,ε是margin。对于距离测度,可以用Euclidean距离。实验时,作者将ε设置为1。
实验时,作者用3-way softmax分类目标函数fine-tune SBERT了一个epoch。pooling策略为MEAN。
接下来就是一系列的实验结果表格,结论是效果不错。
消融学习:
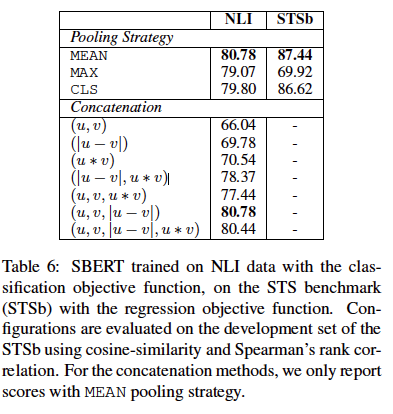
pooling策略影响小,连接方式影响大。
论文阅读 | Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks的更多相关文章
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 深度学习论文翻译解析(五):Siamese Neural Networks for One-shot Image Recognition
论文标题:Siamese Neural Networks for One-shot Image Recognition 论文作者: Gregory Koch Richard Zemel Rusla ...
- 论文阅读笔记: Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks
论文概况 Multi-Perspective Sentence Similarity Modeling with Convolution Neural Networks是处理比较两个句子相似度的问题, ...
- 论文阅读 Continuous-Time Dynamic Network Embeddings
1 Continuous-Time Dynamic Network Embeddings Abstract 描述一种将时间信息纳入网络嵌入的通用框架,该框架提出了从CTDG中学习时间相关嵌入 Co ...
- 论文阅读:Learning Attention-based Embeddings for Relation Prediction in Knowledge Graphs(2019 ACL)
基于Attention的知识图谱关系预测 论文地址 Abstract 关于知识库完成的研究(也称为关系预测)的任务越来越受关注.多项最新研究表明,基于卷积神经网络(CNN)的模型会生成更丰富,更具表达 ...
- 论文阅读 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks
6 Predicting Dynamic Embedding Trajectory in Temporal Interaction Networks link:https://arxiv.org/ab ...
- 论文阅读笔记四十一:Very Deep Convolutional Networks For Large-Scale Image Recongnition(VGG ICLR2015)
论文原址:https://arxiv.org/abs/1409.1556 代码原址:https://github.com/machrisaa/tensorflow-vgg 摘要 本文主要分析卷积网络的 ...
- 论文阅读笔记三十八:Deformable Convolutional Networks(ECCV2017)
论文源址:https://arxiv.org/abs/1703.06211 开源项目:https://github.com/msracver/Deformable-ConvNets 摘要 卷积神经网络 ...
- 论文阅读笔记六十五:Enhanced Deep Residual Networks for Single Image Super-Resolution(CVPR2017)
论文原址:https://arxiv.org/abs/1707.02921 代码: https://github.com/LimBee/NTIRE2017 摘要 以DNN进行超分辨的研究比较流行,其中 ...
随机推荐
- 0911作业-if while循环小练习
输入姑娘的年龄后,进行以下判断: 如果姑娘小于18岁,打印"不接受未成年" 如果姑娘大于18岁小于25岁,打印"心动表白" 如果姑娘大于25岁小于45岁,打印& ...
- [LINQ2Dapper]最完整Dapper To Linq框架(四)---Linq和SQL并行使用
目录 [LINQ2Dapper]最完整Dapper To Linq框架(一)---基础查询 [LINQ2Dapper]最完整Dapper To Linq框架(二)---动态化查询 [LINQ2Dapp ...
- Java基础 ArrayList源码分析 JDK1.8
一.概述 本篇文章记录通过阅读JDK1.8 ArrayList源码,结合自身理解分析其实现原理. ArrayList容器类的使用频率十分频繁,它具有以下特性: 其本质是一个数组,因此它是有序集合 通过 ...
- sqlite修改表、表字段等与sql server的不同之处
sqlite中只支持 ALTER TABLE 命令的 RENAME TABLE 和 ADD COLUMN. 其他类型的 ALTER TABLE 操作如 DROP COLUMN,ALTER COLUMN ...
- Appium+python自动化(四十)-Appium自动化测试框架综合实践 - 代码实现(超详解)
1.简介 今天我们紧接着上一篇继续分享Appium自动化测试框架综合实践 - 代码实现.由于时间的关系,宏哥这里用代码给小伙伴演示两个模块:注册和登录. 2.业务模块封装 因为现在各种APP的层出不群 ...
- hdu 1233 还是畅通工程 (prim, kruskal)
还是畅通工程Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Total Submi ...
- go中的关键字-defer
1. defer的使用 defer 延迟调用.我们先来看一下,有defer关键字的代码执行顺序: func main() { defer func() { fmt.Println("1号输出 ...
- 领扣(LeetCode)删除注释 个人题解
给一个 C++ 程序,删除程序中的注释.这个程序source是一个数组,其中source[i]表示第i行源码. 这表示每行源码由\n分隔. 在 C++ 中有两种注释风格,行内注释和块注释. 字符串// ...
- Future模式的学习以及JDK内置Future模式的源码分析
并发程序设计之Future模式 一).使用Future模式的原因 当某一段程序提交了一个请求,期待得到一个答复,但服务程序对这个请求的处理可能很慢,在单线程的环境中,调用函数是同步的,必须等到服务程序 ...
- pwnable.kr第二天
3.bof 这题就是简单的数组越界覆盖,直接用gdb 调试出偏移就ok from pwn import * context.log_level='debug' payload='A'*52+p32(0 ...