EM算法和高斯混合模型GMM介绍
EM算法
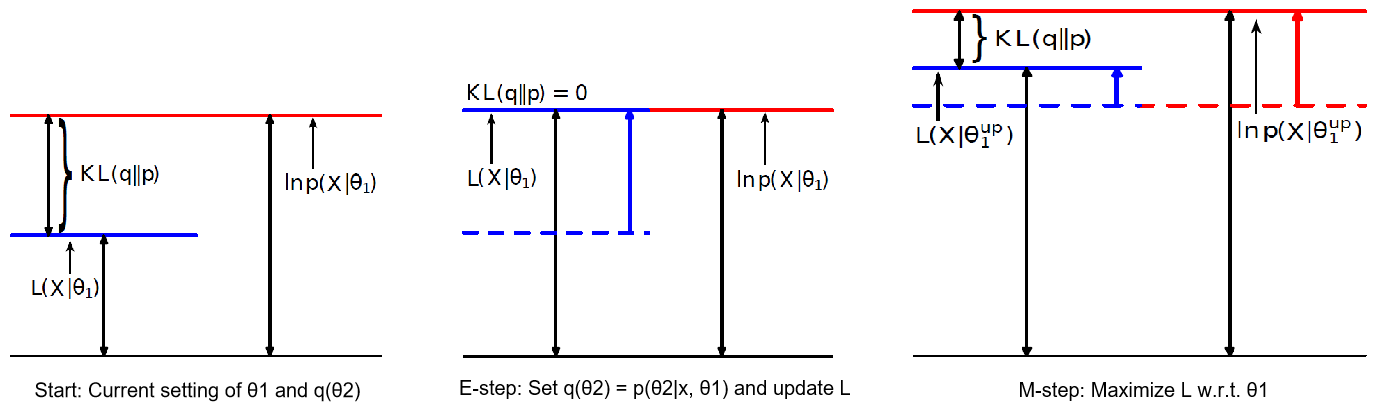
EM算法主要用于求概率密度函数参数的最大似然估计,将问题$\arg \max _{\theta_{1}} \sum_{i=1}^{n} \ln p\left(x_{i} | \theta_{1}\right)$转换为更加易于计算的$\sum_{i=1}^{n} \ln p\left(x_{i}, \theta_{2} | \theta_{1}\right)$,其中$\theta_2$可以取任意的先验分布$q(\theta_2)$。EM算法的推导过程如下:$$\begin{aligned} \ln p\left(x | \theta_{1}\right) &=\int q\left(\theta_{2}\right) \ln p\left(x | \theta_{1}\right) d \theta_{2}=\int q\left(\theta_{2}\right) \ln \frac{p\left(x, \theta_{2} | \theta_{1}\right)}{p\left(\theta_{2} | x, \theta_{1}\right)} d \theta_{2}=\int q\left(\theta_{2}\right) \ln \frac{p\left(x, \theta_{2} | \theta_{1}\right) q\left(\theta_{2}\right)}{p\left(\theta_{2} | x, \theta_{1}\right) q\left(\theta_{2}\right)} d \theta_{2} \\ &=\underbrace{\int q\left(\theta_{2}\right) \ln \frac{p\left(x, \theta_{2} | \theta_{1}\right)}{q\left(\theta_{2}\right)} d \theta_{2}}_{\text { define this to }\mathcal{L}\left(x,\theta_1\right)}+\underbrace{\int q\left(\theta_{2}\right) \ln \frac{q\left(\theta_{2}\right)}{p\left(\theta_{2} | x, \theta_{1}\right)} d \theta_{2}}_{\text { Kullback-Leibler divergence }} \end{aligned}$$利用凸函数的性质,$\text{KL divergence}=E\left[-\ln \frac{p\left(\theta_{2} | x, \theta_{1}\right)}{q\left(\theta_{2}\right)}\right]\geq{-\ln{E\left[\frac{p\left(\theta_{2} | x, \theta_{1}\right)}{q\left(\theta_{2}\right)}\right]}}=-\ln{1}=0$,当且仅当$q\left(\theta_{2}\right)=p\left(\theta_{2} | x, \theta_{1}\right)$时$\text{KL divergence}$取值为0。
基于以上推导,EM算法的计算流程如下:
给定初始值$\theta_1^{(0)}$,按以下步骤迭代至收敛(以第t+1步为例):
- E-step: 令$q_{t}\left(\theta_{2}\right)=p\left(\theta_{2} | x, \theta_{1}^{(t)}\right)$,则$\mathcal{L}_{t}\left(x, \theta_{1}\right)=\int q_{t}\left(\theta_{2}\right) \ln p\left(x, \theta_{2} | \theta_{1}\right) d \theta_{2}-\underbrace{\int q_{t}\left(\theta_{2}\right) \ln q_{t}\left(\theta_{2}\right) d \theta_{2}}_{\text { can ignore this term }}$
- M-step: 令$\theta_{1}^{(t+1)}=\arg \max _{\theta_{1}} \mathcal{L}_{t}\left(x, \theta_{1}\right)$
算法解释:
$$
\begin{aligned} \ln p\left(x | \theta_{1}^{(t)}\right) &=\mathcal{L}_{t}\left(x, \theta_{1}^{(t)}\right)+\underbrace{K L\left(q_t\left(\theta_{2}\right) \| p\left(\theta_{2} | x_{1}, \theta_{1}^{(t)}\right)\right)}_{=0 \text { by setting } q=p}\quad \leftarrow \text { E-step } \\ & \leq \mathcal{L}_{t}\left(x, \theta_{1}^{(t+1)}\right) \quad \leftarrow \text { M-step } \\ & \leq \mathcal{L}_{t}\left(x, \theta_{1}^{(t+1)}\right)+\underbrace{K L\left(q_{t}\left(\theta_{2}\right) \| p\left(\theta_{2} | x_{1}, \theta_{1}^{(t+1)}\right)\right)}_{>0 \text { because } q \neq p} \\ &=\ln p\left(x | \theta_{1}^{(t+1)}\right)\end{aligned}
$$
高斯混合模型GMM
高斯混合模型是一个用于聚类的概率模型,对于数据$\vec{x}_1,\vec{x}_2,\cdots,\vec{x}_n$中的任一数据$\vec{x}_i$,$c_i$表示$\vec{x}_i$被分配到了第$c_i$个簇中,并且$c_i\in\{1,2,\cdots,K\}$。模型定义如下:
- Prior cluster assignment: $c_{i} \stackrel{\text { iid }}{\sim}$ Discrete $(\vec{\pi}) \Rightarrow \operatorname{Prob}\left(c_{i}=k | \vec{\pi}\right)=\pi_{k}$
- Generate observation: $\vec{x}_i \sim N\left(\vec{\mu}_{c_{i}}, \Sigma_{c_{i}}\right)$
模型需要求解的就是先验概率$\vec{\pi}=(\pi_1,\pi_2,\cdots,\pi_K)$,各簇高斯分布的均值$\{\vec{\mu}_1,\vec{\mu}_2,\cdots,\vec{\mu}_K\}$以及协方差矩阵$\{\Sigma_1,\Sigma_2,\cdots,\Sigma_K\}$这些量。为了求解这些量,使用最大似然估计,定义需最大化的目标函数为
$$\sum_{i=1}^{n} \ln p\left(\vec{x}_{i} | \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)\text{, where }\boldsymbol{\mu}=\{\vec{\mu}_1,\vec{\mu}_2,\cdots,\vec{\mu}_K\}\text{ and }\boldsymbol{\Sigma}=\{\Sigma_1,\Sigma_2,\cdots,\Sigma_K\}$$
利用EM算法求解上式的最大值,将上式写为$$\sum_{i=1}^{n} \ln p\left(\vec{x}_{i} | \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)=\sum_{i=1}^{n} \underbrace{\sum_{k=1}^{K} q\left(c_{i}=k\right) \ln \frac{p\left(\vec{x}_{i}, c_{i}=k | \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)}{q\left(c_{i}=k\right)}}_{\mathcal{L}}+\sum_{i=1}^n\underbrace{\sum_{k=1}^{K} q\left(c_{i}=k\right) \ln \frac{q\left(c_{i}=k\right)}{p\left(c_{i}=k | \vec{x}_{i}, \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)}}_{\text{KL divergence}}$$
- E-step: 根据贝叶斯法则,令$q_t\left(c_{i}=k\right)=p\left(c_{i}=k | \vec{x}_{i}, \vec{\pi}^{(t)}, \mu^{(t)}, \Sigma^{(t)}\right)\propto p\left(c_{i}=k | \vec{\pi}^{(t)}\right) p\left(\vec{x}_{i} | c_{i}=k, \boldsymbol{\mu}^{(t)}, \boldsymbol{\Sigma}^{(t)}\right)$,容易看出$$q_t\left(c_{i}=k\right)=\frac{\pi_{k}^{(t)} N\left(\vec{x}_{i} | \vec{\mu}_{k}^{(t)}, \Sigma_{k}^{(t)}\right)}{\sum_{j} \pi_{j}^{(t)} N\left(\vec{x}_{i} | \vec{\mu}_{j}^{(t)}, \Sigma_{j}^{(t)}\right)}$$
- M-step: $$\arg\max_{\vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}}\sum_{i=1}^{n} \sum_{k=1}^{K} q_t\left(c_{i}=k\right)\ln p\left(\vec{x}_{i}, c_{i}=k | \vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}\right)=\arg\max_{\vec{\pi}, \boldsymbol{\mu}, \boldsymbol{\Sigma}}\sum_{i=1}^{n} \sum_{k=1}^{K} q_t\left(c_{i}=k\right)\left[\ln \pi_k+\ln N\left(\vec{x}_{i} | \vec{\mu}_{k}, \Sigma_{k}\right)\right]$$可以得出$\pi_{k}^{(t+1)}=\frac{\sum_{i=1}^{n}q_t\left(c_i=k\right)}{\sum_{j=1}^{K}\sum_{i=1}^{n}q_t\left(c_i=j\right)}=\frac{\sum_{i=1}^{n}q_t\left(c_i=k\right)}{n}, \quad\vec{\mu}_{k}^{(t+1)}=\frac{\sum_{i=1}^{n} q_t\left(c_i=k\right) \vec{x}_{i}}{\sum_{i=1}^{n}q_t\left(c_i=k\right)}, \quad \Sigma_{k}^{(t+1)}=\frac{ \sum_{i=1}^{n} q_t\left(c_i=k\right)\left(\vec{x_{i}}-\vec{\mu}_{k}^{(t+1)}\right)\left(\vec{x}_{i}-\vec{\mu}_{k}^{(t+1)}\right)^{T}}{\sum_{i=1}^{n}q_t\left(c_i=k\right)}$
EM算法和高斯混合模型GMM介绍的更多相关文章
- 斯坦福大学机器学习,EM算法求解高斯混合模型
斯坦福大学机器学习,EM算法求解高斯混合模型.一种高斯混合模型算法的改进方法---将聚类算法与传统高斯混合模型结合起来的建模方法, 并同时提出的运用距离加权的矢量量化方法获取初始值,并采用衡量相似度的 ...
- EM 算法求解高斯混合模型python实现
注:本文是对<统计学习方法>EM算法的一个简单总结. 1. 什么是EM算法? 引用书上的话: 概率模型有时既含有观测变量,又含有隐变量或者潜在变量.如果概率模型的变量都是观测变量,可以直接 ...
- 统计学习方法c++实现之八 EM算法与高斯混合模型
EM算法与高斯混合模型 前言 EM算法是一种用于含有隐变量的概率模型参数的极大似然估计的迭代算法.如果给定的概率模型的变量都是可观测变量,那么给定观测数据后,就可以根据极大似然估计来求出模型的参数,比 ...
- 机器学习算法总结(六)——EM算法与高斯混合模型
极大似然估计是利用已知的样本结果,去反推最有可能(最大概率)导致这样结果的参数值,也就是在给定的观测变量下去估计参数值.然而现实中可能存在这样的问题,除了观测变量之外,还存在着未知的隐变量,因为变量未 ...
- 机器学习第三课(EM算法和高斯混合模型)
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一.说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值. ...
- EM算法求高斯混合模型參数预计——Python实现
EM算法一般表述: 当有部分数据缺失或者无法观察到时,EM算法提供了一个高效的迭代程序用来计算这些数据的最大似然预计.在每一步迭代分为两个步骤:期望(Expectation)步骤和最大化( ...
- 贝叶斯来理解高斯混合模型GMM
最近学习基础算法<统计学习方法>,看到利用EM算法估计高斯混合模型(GMM)的时候,发现利用贝叶斯的来理解高斯混合模型的应用其实非常合适. 首先,假设对于贝叶斯比较熟悉,对高斯分布也熟悉. ...
- 6. EM算法-高斯混合模型GMM+Lasso详细代码实现
1. 前言 我们之前有介绍过4. EM算法-高斯混合模型GMM详细代码实现,在那片博文里面把GMM说涉及到的过程,可能会遇到的问题,基本讲了.今天我们升级下,主要一起解析下EM算法中GMM(搞事混合模 ...
- 5. EM算法-高斯混合模型GMM+Lasso
1. EM算法-数学基础 2. EM算法-原理详解 3. EM算法-高斯混合模型GMM 4. EM算法-GMM代码实现 5. EM算法-高斯混合模型+Lasso 1. 前言 前面几篇博文对EM算法和G ...
随机推荐
- NoSQL数据库兴起
前言 近几年NoSQL数据库兴起,各种新的产品层出不穷,在此学习下NoSQL的基本理论,并认识下常见的NoSQL数据库. 一 NoSQL数据库兴起的原因 随着大数据技术兴起和Web2.0时代的到来.传 ...
- CentOS 7 使用 HP 打印机
通常 hp 打印机应该是直接就能用的,但 centos 7 就一直遇到 printing job stopped 的情况.查看 http://localhost:631/printers/ 并没什么用 ...
- GRPC Oauth IdentityServer4
Server端 StartUp类: using System; using System.Collections.Generic; using System.Linq; using System.Th ...
- c#零碎知识随笔
1. 字符串转换日期: DateTime.ParseExact(item.Attribute("event-timestamp").Value,"dd.MM.yyyy H ...
- Java内部类你真的会吗?
一.四种内部类 1.1.成员内部类 成员内部类是最普通的内部类,它的定义为位于另一个类的内部,形如下面的形式: public class OuterAndInnerClass { public sta ...
- 9.16考试 第一题 X国的军队题解
这道题总体来看还是比较满意的.连想带打不超过半个小时,打了不到当时基本读懂后就感觉是贪心,但贪什么很重要,当时一开始想的是贪心死亡人数,从小到大搞,然后自己造了几个小数据,还好WA了,然后又列了一个式 ...
- Sending Operations to Multiple Threads_翻译
The speed and efficiency of a long-running, data-intensive operation often improves when you split i ...
- .NET多线程之Thread、Task、ThreadPool、Timer
下表为多线程操作常见对象: 对象 方法/属性 描述 用途 用法 性能 Thread(线程) Start 启动线程,启动后线程处于System.Threading.ThreadState.Running ...
- 关于MarkDownPad2安装遇到的一些问题
关于MarkdownPad MarkdownPad是Windows下的一个多功能Markdown编辑器.即时看到你的Markdown文件,当你创建它们的时候,看起来就像是在HTML中的一样.当您输入时 ...
- SpringBoot之SpringApplication Explain
SpringApplication Explain The SpringApplication class provides a convenient way to bootstrap a Sprin ...