Spark比MR快是因为在内存中计算?错!
MapReduce 就像一台又慢又稳的老爷车,虽然距离 MapReduce 面市到现在已经过去了十几年的时间,但它始终没有被淘汰,任由大数据技术日新月异、蓬蓬勃勃、花里胡哨地发展,这个生态圈始终有它的一席之地。
不过 Spark 的到来确实给了 MapReduce 不小的冲击,它比 MapReduce 理论上要快两个数量级,所以近几年不断有人讨论 Spark 是否可以完全替代 MapReduce ,但是为什么说是不断有人讨论呢?因为这些年 Spark 始终是无法完全取代 MapReduce 。
我们今天关注的问题是Spark为什么比 MapReduce 快?如果没有看文章的标题,你是不是会脱口而出:
“因为 Spark 是在内存中计算,而 MapReduce 是基于磁盘。”
这话乍一听没毛病,但是作为一个对技术很严谨的人,这让我忍不住想杠一下,
“那么 MapReduce 计算的时候不需要把数据加载到内存,在内存中计算吗?”
其实要对数据做计算,必然得把数据加载到内存, MapReduce 也不例外,Spark只是在计算模型和调度上做了更多的优化,不需要过多地和磁盘交互。
说到这里不得不提的就是 Spark 的 DAG(有向无环图),这个 DAG 就相当于改进版的 MapReduce,它可以说是由多个 MapReduce 组成,当数据处理流程中存在多个map和多个Reduce操作混合执行时,MapReduce只能提交多个Job执行,而Spark可以只提交一次,在一个任务中完成。
这就导致了 MapReduce 会存在多次耗时的资源申请和资源释放,另外 MapReduce 每次shuffle 操作后,必须写到磁盘,而 Spark 在 shuffle 后不一定落盘,如果Shuffle后的数据是需要反复用到的,则可以cache到内存中,方便迭代时使用,所以Spark对于需要对数据进行反复迭代的操作(比如跑机器学习算法或者有中间结果的复杂计算等)是非常友好的。
这里还有一个误区,很多人会认为 Spark 在计算时的所有过程都是在内存中完成的不用写磁盘,但是实际上不是这样的,在 shuffle 过程中 Spark 同样需要写磁盘,研究过 Sorted-Based Shuffle 的同学对这个写盘操作一定不陌生,如下图。
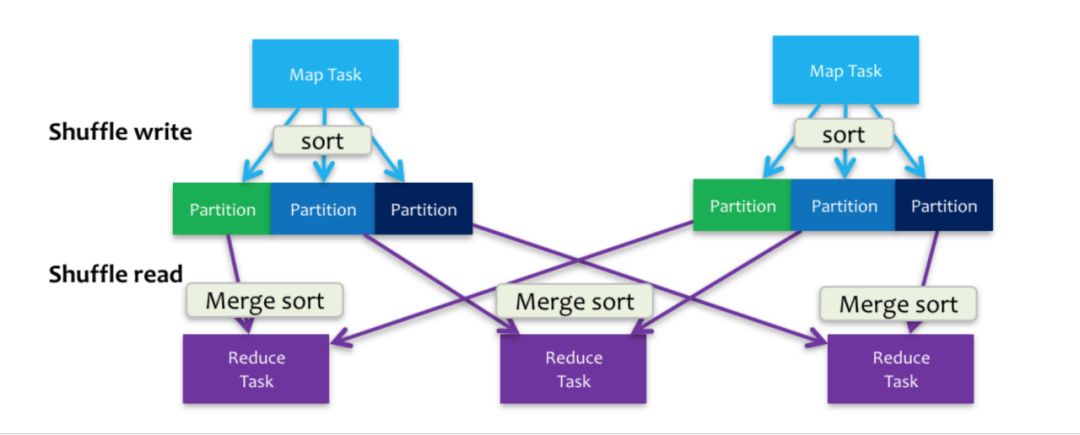
简单地说下,shuffle分成write和read两个阶段,write的过程不仅会写需要发向下一个Stage的数据到磁盘,还需要写一份数据的Index记录下游每个分区获取的数据范围。这里就不详细说了,有兴趣的同学可以去研究下。

另外,刚才提到了Spark尽管比MapReduce快两个数量级但是它始终没有被淘汰,这是因为它在每个阶段都落盘,虽然慢但是可以保证计算过程的稳定性,不会像Spark一样,一旦中间结果太大,内存装不下整个计算任务就崩了,这对于不讲究时效性的后台任务来说无疑是增加了维护成本,所以现在构建数据仓库的主要SQL工具还是Hive(Hive的底层是MapReduce),你见过用SparkSQL来跑数据量大的数仓任务的吗?
看完这篇,希望下次有人问你 Spark 为什么比 MapReduce 快的时候不要再说 Spark 在内存中计算了。
觉得有价值请关注 ▼

Spark比MR快是因为在内存中计算?错!的更多相关文章
- JS获取对象在内存中计算后的样式
通过obj.style的方式只能取得"内联style"的值,对于<style></style>中的css属性值,则无能为力 . 我们可以用obj.curre ...
- 内存中OLTP(Hekaton)里的事务日志记录
在今天的文章里,我想详细讨论下内存中OLTP里的事务日志如何写入事务日志.我们都知道,对于你的内存优化表(Memory Optimized Tables),内存中OLTP提供你2个持久性(durabi ...
- Spark(Python) 从内存中建立 RDD 的例子
Spark(Python) 从内存中建立 RDD 的例子: myData = ["Alice","Carlos","Frank"," ...
- QList介绍(QList比QVector更快,这是由它们在内存中的存储方式决定的。QStringList是在QList的基础上针对字符串提供额外的函数。at()操作比操作符[]更快,因为它不需要深度复制)非常实用
FROM:http://apps.hi.baidu.com/share/detail/33517814 今天做项目时,需要用到QList来存储一组点.为此,我对QList类的说明进行了如下翻译. QL ...
- 使用spark将内存中的数据写入到hive表中
使用spark将内存中的数据写入到hive表中 hive-site.xml <?xml version="1.0" encoding="UTF-8" st ...
- 内存中 OLTP - 常见的工作负荷模式和迁移注意事项(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<In-Memory OLTP – Comm ...
- SQL Server 内存中OLTP内部机制概述(二)
----------------------------我是分割线------------------------------- 本文翻译自微软白皮书<SQL Server In-Memory ...
- C/C++数据在内存中的存储方式
目录 1 内存地址 2 内存空间 在学习C/C++编程语言时,免不了和内存打交道,在计算机中,我们存储有电影,文档,音乐等数据,这些数据在内存中是以什么形式存储的呢?下面做一下简单介绍. 本文是学 ...
- Linux内存中Swap机制(转)
在做监控时,发现内存中有一项Swap space,不是很理解,这里查了一些资料: http://blog.sina.com.cn/s/blog_502d765f0100krph.html 在linux ...
随机推荐
- 吉特日化MES-电子批记录普通样本
在实施吉特日化配料系统的时候,客户希望一键式生成生产过程电子批记录,由于功能的缺失以及部分设备的数据暂时还无法完全采集到,先做一个普通样本的电子批记录格式打印. 电子批记录包含如下几个部分: 1. ...
- 前端中的设计模式 JavaScript
最近再准备秋招,然后顺便把过去空白的设计模式相关概念补一补,这些内容都是从<JavaScript设计模式与开发实践>一书中整理出来的 (1)单例模式 定义:保证一个类仅有一个实例,并提供一 ...
- 【JVM从小白学成大佬】3.深入解析强引用、软引用、弱引用、幻象引用
关于强引用.软引用.弱引用.幻象引用的区别,在很多公司的面试题中经常出现,可能有些小伙伴觉得这个知识点比较冷门,但其实大家在开发中经常用到,如new一个对象的时候就是强引用的应用. 在java语言中, ...
- 常用Feed流架构实现
业务中很多需求都会用到类似feed流的架构. 例如 微信朋友圈 微博 动态 1对N消息. 一般feed流的架构实现有下面几种. 假如现在的业务场景是微博,然后当前的数据情况是: 用户A关注了用户B和C ...
- Asp.NetCore源码学习[1-2]:配置[Option]
Asp.NetCore源码学习[1-2]:配置[Option] 在上一篇文章中,我们知道了可以通过IConfiguration访问到注入的ConfigurationRoot,但是这样只能通过索引器IC ...
- Linux 设置服务开机启动
首先来了解一下 service命令是Redhat Linux兼容的发行版中用来控制系统服务的实用工具,它以启动.停止.重新启动和关闭系统服务,还可以显示所有系统服务的当前状态. service +(自 ...
- 礼盒抖动动画(CocosCreator)
推荐阅读: 我的CSDN 我的博客园 QQ群:704621321 这个月还有一天了,别问我为什么是一天,996,懂吗?项目是做不完了,策划又加新功能,又不能安静的改bug了.又是动画 ...
- MSIL实用指南-数学运算
C#支持的数学运算是加.减.乘.除.取模,它们对应的指令是Add.Sub.Mul.Div.Rem. 这五个运算都需要两个参数,它们的通用步骤1.生成加载左边变量2.生成加载右边变量3.生成运算指令 实 ...
- win命令获取外网ip
win命令: chcp 65001 curl https://ip.cn bat: @echo offchcp 65001 && curl https://ip.cnpause 链接: ...
- Sherlock之Instructions指令介绍(Sherlock Version: 7.2.5.1 64-bit)
指令集总览 1.General 1).Comment:: 注释指令. 2).Image Window: 创建新的图像窗口. True: 取像之后更新图像窗口显示:False: ...