程序员的算法课(16)-B+树在数据库索引中的作用
前文讲了二叉树和多路树,二叉树的性能很好,像AVL树、红黑树都是很优秀的结构,那么在数据库索引中,并没有采用二叉树这种结构,这是为什么呢?因为,有性能更好的树来做搜索!目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。
一、B-树和B+树回顾
1.B-树
B-tree(多路搜索树)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。按照翻译,B 通常认为是Balance的简称。这个数据结构一般用于数据库的索引,综合效率较高。
B-树每个节点都存储key和data,所有节点组成这棵树,并且叶子节点指针为null。
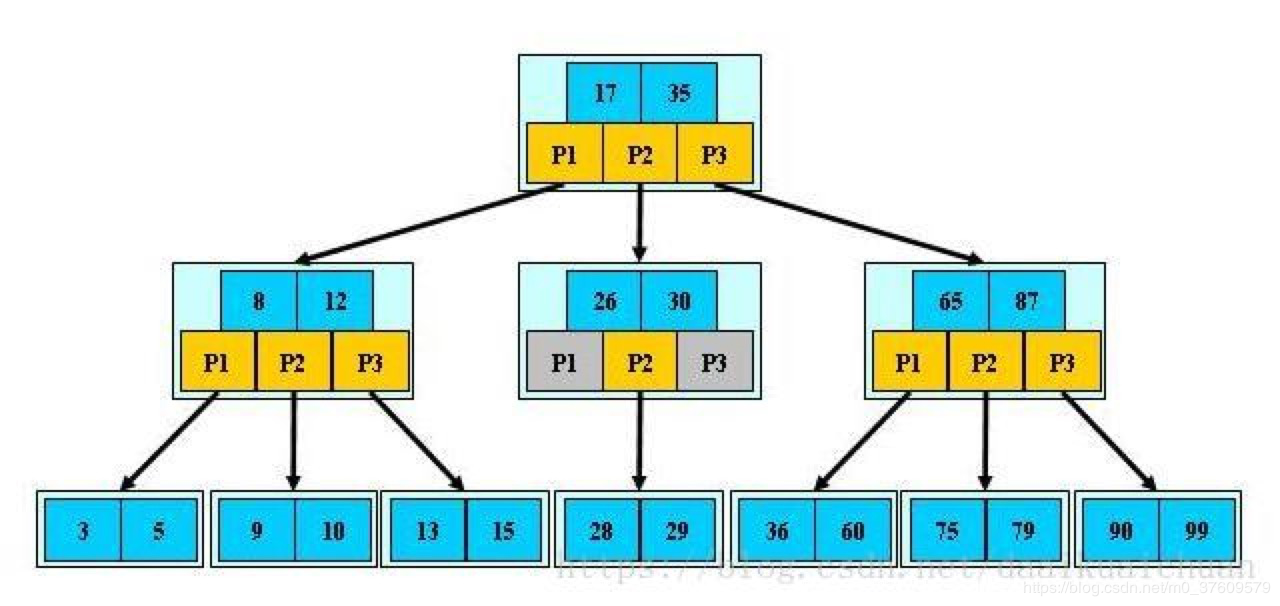
B-树的特征:
- 根节点至少有两个孩子
- 每个非根节点有[ ,M]个孩;
- 每个非根节点有[ -1,M-1]个关键字,并且以升序排列
- key[i]和key[i+1]之间的孩子节点的值介于key[i]、key[i+1]之间
- 所有的叶子节点都在同一层
B-树的优势:
B树的优势在于多路查找,这便是优于红黑树的具体原因,大家想一想,B-树每个结点有多个key,而红黑树每个结点有一个key,那么随着数据的不断增多,红黑树的高度不断增加,效率不断降低,而B树的高度一般都很低,为甚?因为B树一个结点可以放N个key,,只有都满了才分裂一次!B树为什么会分裂呢? 因为随着数据的增多,一个结点的key满了,为了保持B树的特性,就会产生分裂,就像红黑树和AVL树为了保持树的性质需要进行旋转是一样一样的!
2.B+树
B+树是B-树的变体,也是一种多路搜索树,其定义基本与B树相同。B+树上的叶子结点存储关键字以及相应记录的地址,叶子结点以上各层作为索引使用。
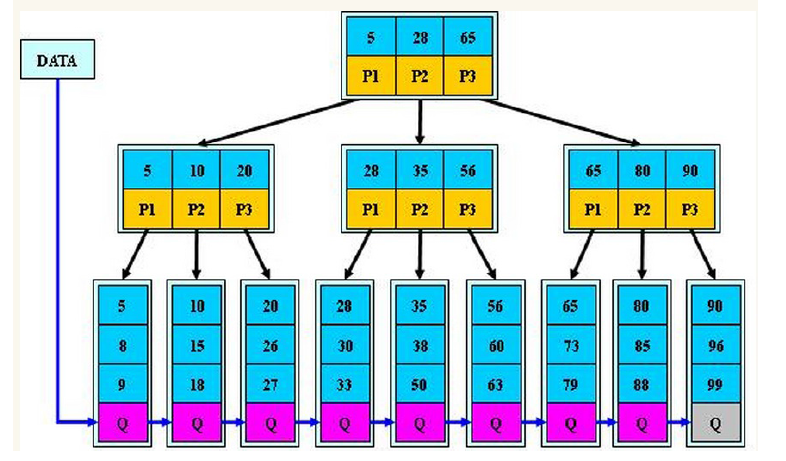
B+树:只有叶子节点存储data,叶子节点包含了这棵树的所有键值,叶子节点不存储指针。
B+树的特征:
- 所有关键字都出现在叶子结点的链表中(稠密索引),且链表中的关键字恰好是有序的;
- 不可能在非叶子结点命中;
- 非叶子结点相当于是叶子结点的索引(稀疏索引),叶子结点相当于是存储(关键字)数据的数据层;
- 更适合文件索引系统;
B+Tree与B-树的不同:
- 每个节点的指针上限为2d而不是2d+1;
- 内节点不存储data,只存储key,即所有关键字都在叶子结点出现;
- 叶子节点不存储指针,而是为所有叶子结点增加一个链指针。
B+树的优势:
在B+树上增加了顺序访问指针,也就是每个叶子节点增加一个指向相邻叶子节点的指针,这样一棵树成了数据库系统实现索引的首选数据结构。 原因有很多,最主要的是这棵树矮胖,一般来说,索引很大,往往以索引文件的形式存储的磁盘上,索引查找时产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的时间复杂度。树高度越小,I/O次数越少。 那为什么是B+树而不是B树呢,因为它内节点不存储data,这样一个节点就可以存储更多的key。
二、索引搜索速度的决定性因素是什么?
因为数据库的大部分数据都是存在磁盘上面的,一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的时间复杂度。树高度越小,I/O次数越少。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。
二叉树的高度过深进行多次磁盘IO,导致查询效率低下,而B树和B+树树中每个结点最多含有m个孩子,所以相对二叉树,B-树和B+树的高度比较低,显得又矮又胖!
三、MySQL中的存储引擎
在MySQL中,最常用的两个存储引擎是MyISAM和InnoDB,它们是MySQL的两代搜索引擎。
它们对索引的实现方式不同,MyISAM data存的是数据地址,索引和数据分开的。InnoDB data存的是数据本身,索引也是数据。
索引分为主索引和辅助索引:一般以主键为索引的叫做主索引,而以其他键为索引的叫做辅助索引。
四、MyISAM利用B+树实现
主索引:
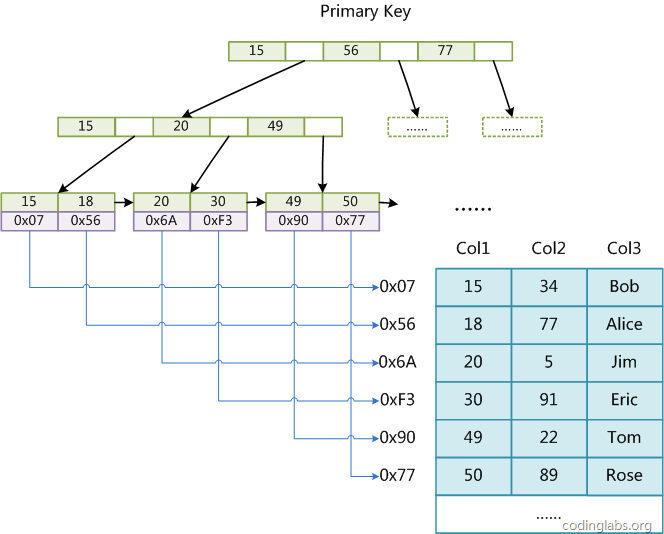
由上图可以看出,col1是主键,而叶子结点存储的数据是一个地址,通过地址找到数据。
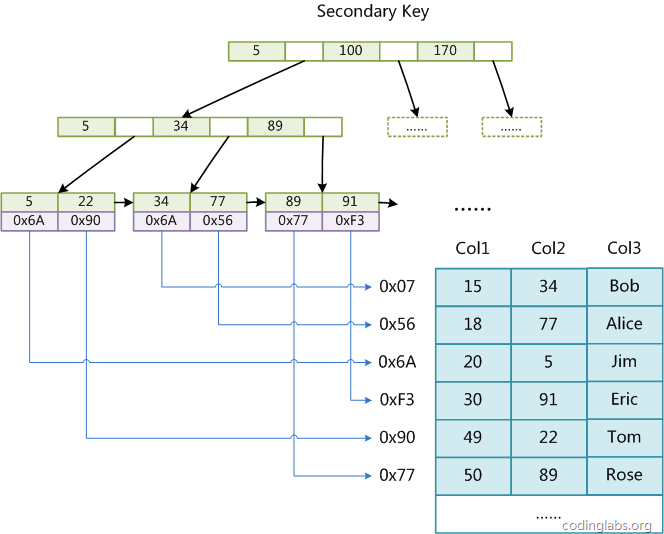
辅助索引(和主索引不同的是辅助索引的key是可以重复的) :
五、InnoDB利用B+树实现
主索引:
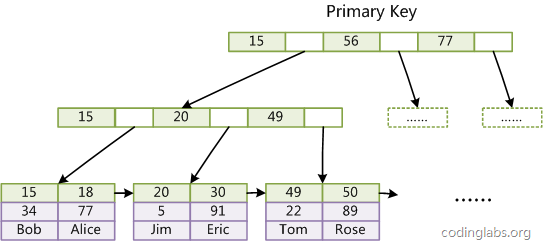
注意,和MyISAM不同的是叶子结点的数据域保存的是全部数据。
辅助索引:
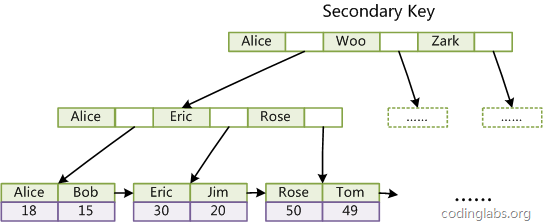
仔细看辅助索引和主索引的区别,辅助索引的叶子结点保存的是主键;这就是MyISAM和InnoDB最大的不同。
六、InnoDB到底比MyISAM好在哪里?
既然MyISAM和InnoDB是MySQL的两代引擎,肯定会有一个提升,而InnoDB是最新一代,那么它到底优在哪里?
试想,MyISAM和InnoDB都是以B+树为基础实现的,相对于B树的不同其实前面已经讲过,即数据域和结点分离;
而MyISAM更是索引和文件分离,B+树的叶子结点的数据域存放的是文件内容的地址,主索引和辅助索引的B+树都是如此,那么如果我改变了一个地址,是不是所有的索引树都得改变,正如前面我们讲的在磁盘上频繁的读写操作是效率很低的,而这块又不适用局部原理,因为逻辑上相邻的结点,物理上不一定相邻,那么这样就会造成效率上的降低;
于是乎,InnoDB就产生了,它让除了主索引以外的辅助索引的叶子结点的数据域都保存主键,先通过辅助索引找到主键,然后通过主键找到叶子结点的所有数据,听起来貌似很麻烦,遍历了两棵树,但是,这样如果有了修改的话,改变的只是主索引,其它辅助缩印都不用动,而且,数据库中的树的每一个结点的key可不是咱们给的那么少,试想如果一个结点有1024个key,那么高度为2的B+树都有1024*1024个key,所以一般树的高度都很低,所以,遍历树的消耗几乎忽略不计!
七、总结
1.为什么使用B+树?
- 文件很大,不可能全部存储在内存中,故要存储到磁盘上
- 索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数(为什么使用B-/+Tree,还跟磁盘存取原理有关,具体看下边分析)
- 局部性原理与磁盘预读,预读的长度一般为页(page)的整倍数,(在许多操作系统中,页得大小通常为4k)
- 数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样 每个节点只需要一次I/O 就可以完全载入,(由于节点中有两个数组,所以地址连续)。而红黑树这种结构, h 明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性。
2.为什么B+树比B树更适合做索引?
B+树磁盘读写代价更低
B+的内部结点并没有指向关键字具体信息的指针,即内部节点不存储数据。因此其内部结点相对B 树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
B+-树的查询效率更加稳定
由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
3.MySQL两种索引MyISAM和InnoDB的区别
- MyISAM是非事务安全的,而InnoDB是事务安全的
- MyISAM锁的粒度是表级的,而InnoDB支持行级锁
- MyISAM支持全文类型索引,而InnoDB不支持全文索引
- MyISAM相对简单,效率上要优于InnoDB,小型应用可以考虑使用MyISAM
- MyISAM表保存成文件形式,跨平台使用更加方便
- MyISAM管理非事务表,提供高速存储和检索以及全文搜索能力,如果在应用中执行大量select操作可选择
- InnoDB用于事务处理,具有ACID事务支持等特性,如果在应用中执行大量insert和update操作,可选择。
我的微信公众号:架构真经(id:gentoo666),分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。每日更新哦!

参考资料:
程序员的算法课(16)-B+树在数据库索引中的作用的更多相关文章
- B树在数据库索引中的应用剖析
引言 关于数据库索引,google一个oracle index,mysql index总 有大量的结果,其中很多的使用方法推荐,**索引之n条经典建议云云.笔者认为,较之借鉴,在搞清楚了自己的需求的基 ...
- 程序员的算法课(20)-常用的图算法:最小生成树(MST)
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- 程序员的算法课(14)-Hash算法-对海量url判重
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- 程序员的算法课(18)-常用的图算法:广度优先(BFS)
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- 程序员的算法课(17)-常用的图算法:深度优先(DFS)
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- 程序员的算法课(3)-递归(recursion)算法
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- 程序员的算法课(19)-常用的图算法:最短路径(Shortest Path)
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- 程序员的算法课(11)-KMP算法
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- 程序员的算法课(6)-最长公共子序列(LCS)
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
随机推荐
- TensorFlow Object Detection API中的Faster R-CNN /SSD模型参数调整
关于TensorFlow Object Detection API配置,可以参考之前的文章https://becominghuman.ai/tensorflow-object-detection-ap ...
- 爬虫基本库的使用---urllib库
使用urllib---Python内置的HTTP请求模块 urllib包含模块:request模块.error模块.parse模块.robotparser模块 发送请求 使用 urllib 的 req ...
- [2018-01-12] jquery获取当前元素的兄弟元素
$('#id').siblings() 当前元素所有的兄弟节点$('#id').prev() 当前元素前一个兄弟节点$('#id').prevaAll() 当前元素之前所有的兄弟节点$('#id'). ...
- MAC配置JAVA环境变量
一.下载安装文件 地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html jdk-8u144-macosx-x64. ...
- Spring Boot 2.x实战之StateMachine
本文首发于个人网站:Spring Boot 2.x实战之StateMachine Spring StateMachine是一个状态机框架,在Spring框架项目中,开发者可以通过简单的配置就能获得一个 ...
- 小白学 Python(18):基础文件操作
人生苦短,我选Python 前文传送门 小白学 Python(1):开篇 小白学 Python(2):基础数据类型(上) 小白学 Python(3):基础数据类型(下) 小白学 Python(4):变 ...
- scss新手使用指南
还在用死的css写样式吗?那可太麻烦了,各种长串选择器不说,还有各种继承权重有时候还有可能不生效 我的小程序项目也结束了,是时候总结一下scss语法了,毕竟用起来更加方便而且还能精简一点代码,好处多多 ...
- ie浏览器兼容性的入门解决方案
IE浏览器的兼容性素来是令人头疼的问题,大名鼎鼎的FUCK-IE不是浪得虚名的. 这里使用的解决方案是HACK,具体原理就是针对不同的浏览器写不同的HTML.CSS样式,从而使各种浏览器达到一致的渲染 ...
- python学习之【第十四篇】:Python中的装饰器
1.什么是装饰器? 器即函数 装饰即修饰,意指为其他函数添加新功能 装饰器定义:本质就是函数,功能是为其他函数添加新功能 2.遵循的原则 装饰器必须遵循以下两个原则: 不修改被装饰函数的源代码(开放封 ...
- getchar()用法 【转】
1.从缓冲区读走一个字符,相当于清除缓冲区 2.前面的scanf()在读取输入时会在缓冲区中留下一个字符'\n'(输入完s[i]的值后按回车键所致),所以如果不在此加一个getchar()把这个回车符 ...