(一)分布式数据库tidb-简介
因为数据磁盘问题,最近进行了更换库,所以决定写关于这方面的专题的博客,博客信息参考的官方文档。
一、分布式数据库使用背景
随着互联网的飞速发展,业务量可能在短短的时间内爆发式地增长,对应的数据量可能快速地从几百 GB 涨到几百个 TB,传统的单机数据库提供的服务,在系统的可扩展性、性价比方面已经不再适用。比如MySQL数据库,缺点是没法做到水平扩展。MySQL 要想能做到水平扩展,唯一的方法就业务层的分库分表或者使用中间件等方案。但是,这些中间层方案也有很大局限性,执行计划不是最优,分布式事务,跨节点 join,扩容复杂等。
二、分布式数据库TiDB简介
TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。。
TiDB 具备如下特性:
- 高度兼容 MySQL
大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移。
- 水平弹性扩展
通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻松应对高并发、海量数据场景。
- 分布式事务
TiDB 100% 支持标准的 ACID 事务。
- 真正金融级高可用
相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动恢复 (auto-failover),无需人工介入。
- 一站式 HTAP 解决方案
TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解决方案,一份存储同时处理 OLTP & OLAP,无需传统繁琐的 ETL 过程。
- 云原生 SQL 数据库
TiDB 是为云而设计的数据库,支持公有云、私有云和混合云,使部署、配置和维护变得十分简单。
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
三、TiDB整体架构
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。
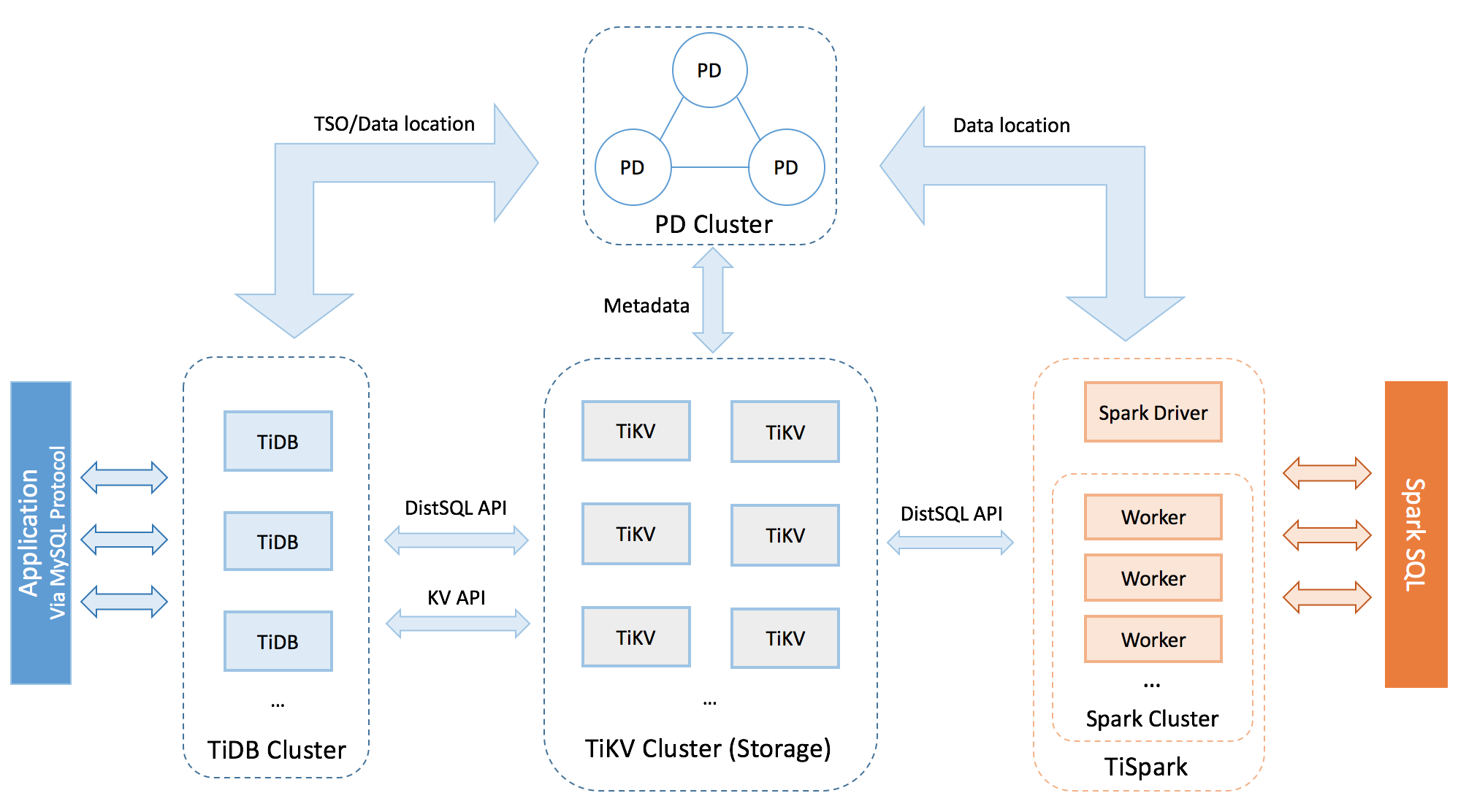
TiDB 集群主要分为三个组件:
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region(区域),每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
四、核心特性
- 水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力和存储能力。TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。所以在业务的早期,可以只部署少量的服务实例,随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
- 高可用
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。
五、TiDB原理与实现
TiDB 架构是 SQL 层和 KV 存储层分离,相当于 InnoDB 插件存储引擎与 MySQL 的关系。从下图可以看出整个系统是高度分层的,最底层选用了当前比较流行的存储引擎 RocksDB,RockDB 性能很好但是是单机的,为了保证高可用所以写多份,上层使用 Raft 协议来保证单机失效后数据不丢失不出错。保证有了比较安全的 KV 存储的基础上再去构建多版本,再去构建分布式事务,这样就构成了存储层 TiKV。有了TiKV,TiDB 层只需要实现 SQL 层,再加上 MySQL 协议的支持,应用程序就能像访问 MySQL 那样去访问 TiDB 了。

(一)分布式数据库tidb-简介的更多相关文章
- 【Hadoop】一、分布式数据库HBase简介
1.分布式数据库特点 说到数据库,我们最熟悉的是类似于mysql这样的关系型数据库,称为RDBMS.关系型数据库作为一种数据存储和数据检索的关键技术,它支持SQL语言的结构化查询,但是它天生不是为 ...
- 分布式数据库TiDB的部署
转自:https://my.oschina.net/Kenyon/blog/908370 一.环境 CentOS Linux release 7.3.1611 (Core)172.26.11.91 ...
- NewSQL分布式数据库,例如TIDB用K/V的底层逻辑
内容参考 对分布式对定义参考这篇文章: 微服务都想用,先把分布式和微服务之间的关系说清楚 对分布式架构中心或无中心对比参考这篇文章: 分布式存储单主.多主和无中心架构的特征与趋势 对HDFS对内部机制 ...
- 新一代数据库TiDB在美团的实践
1. 背景和现状 近几年,基于MySQL构建的传统关系型数据库服务,已经很难支撑美团业务的爆发式增长,这就促使我们去探索更合理的数据存储方案和实践新的运维方式.而随着分布式数据库大放异彩,美团DBA团 ...
- 【TIDB】1、TiDb简介
一 TiDb简介 TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式 HTAP (Hybrid Transactional and Analyti ...
- 云时代的分布式数据库:阿里分布式数据库服务DRDS
发表于2015-07-15 21:47| 10943次阅读| 来源<程序员>杂志| 27 条评论| 作者王晶昱 <程序员>杂志数据库DRDS分布式沈询 摘要:伴随着系统性能.成 ...
- 怎样打造一个分布式数据库——rocksDB, raft, mvcc,本质上是为了解决跨数据中心的复制
摘自:http://www.infoq.com/cn/articles/how-to-build-a-distributed-database?utm_campaign=rightbar_v2& ...
- net Core 使用MyCat分布式数据库,实现读写分离
net Core 使用MyCat分布式数据库,实现读写分离 目录索引 [无私分享:ASP.NET CORE 项目实战]目录索引 简介 MyCat2.0版本很快就发布了,关于MyCat的动态和一些问题, ...
- Amoeba是一个类似MySQL Proxy的分布式数据库中间代理层软件,是由陈思儒开发的一个开源的java项目
http://www.cnblogs.com/xiaocen/p/3736095.html amoeba实现mysql读写分离 application shang 2年前 (2013-03-28) ...
随机推荐
- 对vue中nextTick()的理解及使用场景说明
异步更新队列: 首先我们要对vue的数据更新有一定理解: vue是依靠数据驱动视图更新的,该更新的过程是异步的. 即:当侦听到你的数据发生变化时, Vue将开启一个队列(该队列被Vue官方称为异步更新 ...
- American daily English notes (enlarged edition): A review
Life English is the most pragmatic kind of English when one wants to associate with foreigner friend ...
- Spark 系列(八)—— Spark SQL 之 DataFrame 和 Dataset
一.Spark SQL简介 Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据.它具有以下特点: 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 Da ...
- Netty基础系列(4) --堆外内存与零拷贝详解
前言 到目前为止,我们知道Nio当中有三个最最核心的组件,分别是:Selelctor,Channel,Buffer.在Netty基础系列(3) --彻底理解NIO 这一篇文章中只是进行了大致的介绍. ...
- 8.12 day31 进程间通信 Queue队列使用 生产者消费者模型 线程理论 创建及对象属性方法 线程互斥锁 守护线程
进程补充 进程通信 要想实现进程间通信,可以用管道或者队列 队列比管道更好用(队列自带管道和锁) 管道和队列的共同特点:数据只有一份,取完就没了 无法重复获取用一份数据 队列特点:先进先出 堆栈特点: ...
- win10 将硬盘工作模式由IDE调整到AHCI模式
第1步:重启进入安全模式 1)点击“开始”按钮 进入设置 2)进入“更新和安全”,“恢复-高级启动”,点击“立即高级启动”, 依次选择“疑难解答”-“高级选项”-“启动设置”-点击“重启” 第2步:进 ...
- 100天搞定机器学习|Day36用有趣的方式解释梯度下降算法
本文为3Blue1Brown神经网络课程讲解第二部分<Gradient descent, how neural networks learn >的学习笔记,观看地址:www.bilibil ...
- 并发编程 Semaphore的使用和详解
类Semaphore的基本使用 Semaphore的作用:限制线程并发的数量 课外话题[多线程的同步概念]:其实就是排着队去执行一个任务,执行任务是一个一个的执行,这样的优点是有助于程序逻辑的正确性, ...
- Nacos(三):Nacos与OpenFeign的对接使用
前言 上篇文章中,简单介绍了如何在SpringCloud项目中接入Nacos作为注册中心,其中服务消费者是通过RestTemplate+Ribbon的方式来进行服务调用的. 实际上在日常项目中服务间调 ...
- Selenium+java - PageFactory设计模式
前言 上一小节我们已经学习了Page Object设计模式,优势很明显,能更好的体现java的面向对象思想和封装特性.但同时也存在一些不足之处,那就是随着这种模式使用,随着元素定位获取,元素定位与页面 ...