Python爬取十四万条书籍信息告诉你哪本网络小说更好看
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: TM0831
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
页面分析
首先打开微信读书,往下拉之后可以看到有榜单推荐,而且显示总共有25个榜单,有的榜单只有几百本,有的榜单却有几万本书。 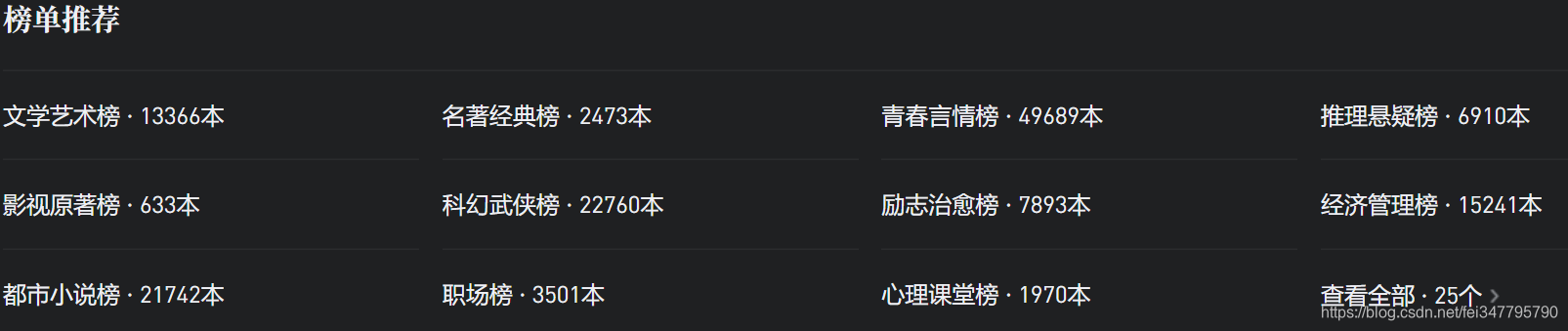 打开“文学艺术榜”,可以看到一页显示了20条书本信息,下拉之后很容易就能发现这些书本信息是通过 AJAX 来加载的。
打开“文学艺术榜”,可以看到一页显示了20条书本信息,下拉之后很容易就能发现这些书本信息是通过 AJAX 来加载的。
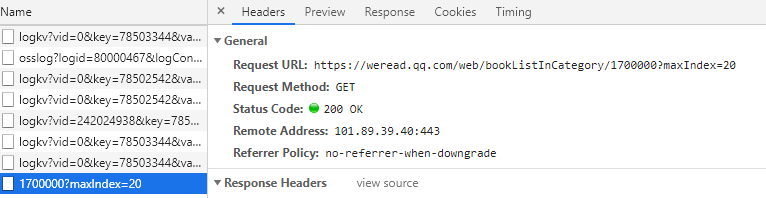
更关键的是,要获取这些书籍信息,只需要得到分类 ID 和参数 maxIndex。不过测试发现,每个分类只会返回50个页面的内容,也就是最多一千条书本信息。那么,如果只有这25个类别的榜单,能得到的数据还是有点少的,所以要怎么得到更多的数据呢?
细心的人可以发现右侧还能选择类别!如下图:
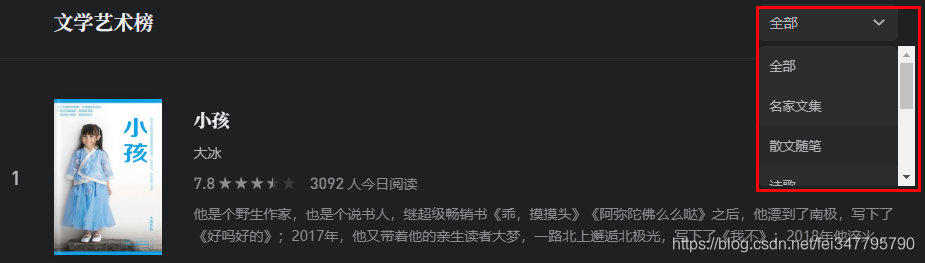
不过,查看这些元素发现里面是没有显示 URL 的,如下图:

但是这也不表示没有办法了,全局搜索一下就能找到了,如下图:
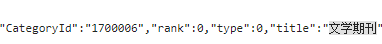
CategoryId 就是这个分类的 ID,也就是 URL 中“bookListInCategory/”后面的内容。至于 maxIndex,可以先设为0,然后发送请求得到这一分类的书本总数“totalCount”,然后根据这个书本总数是否超过一千来设置页数,就能得到这一分类下能够爬取到的所有 URL 了。 爬取步骤 前面经过分析已经知道只要拿到书本分类 ID,就能发送请求得到书本总数,也就能构造该分类下的所有页面的 URL 了。那要怎么得到所有分类呢?前面全局搜索的时候已经搜到了书本分类的 CategoryId 等信息,如下图:
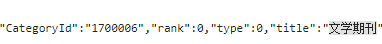
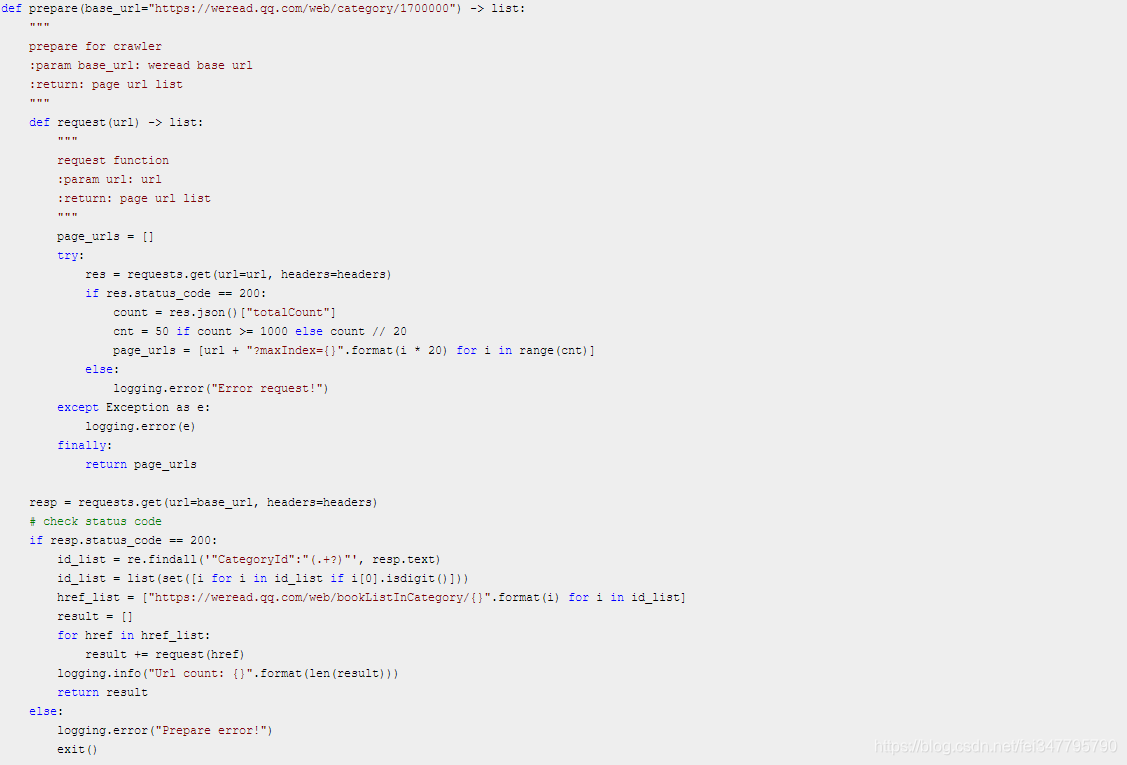
所以只需先请求页面然后用正则匹配 CategoryId 就行了!然后对每个分类发送一次请求,用于获取书本总数,并构造这一分类下的所有 URL。这一部分代码如下:
进行到这一步,后面就很简单了,就是获取请求结果并解析即可。程序运行时打印输出如下:
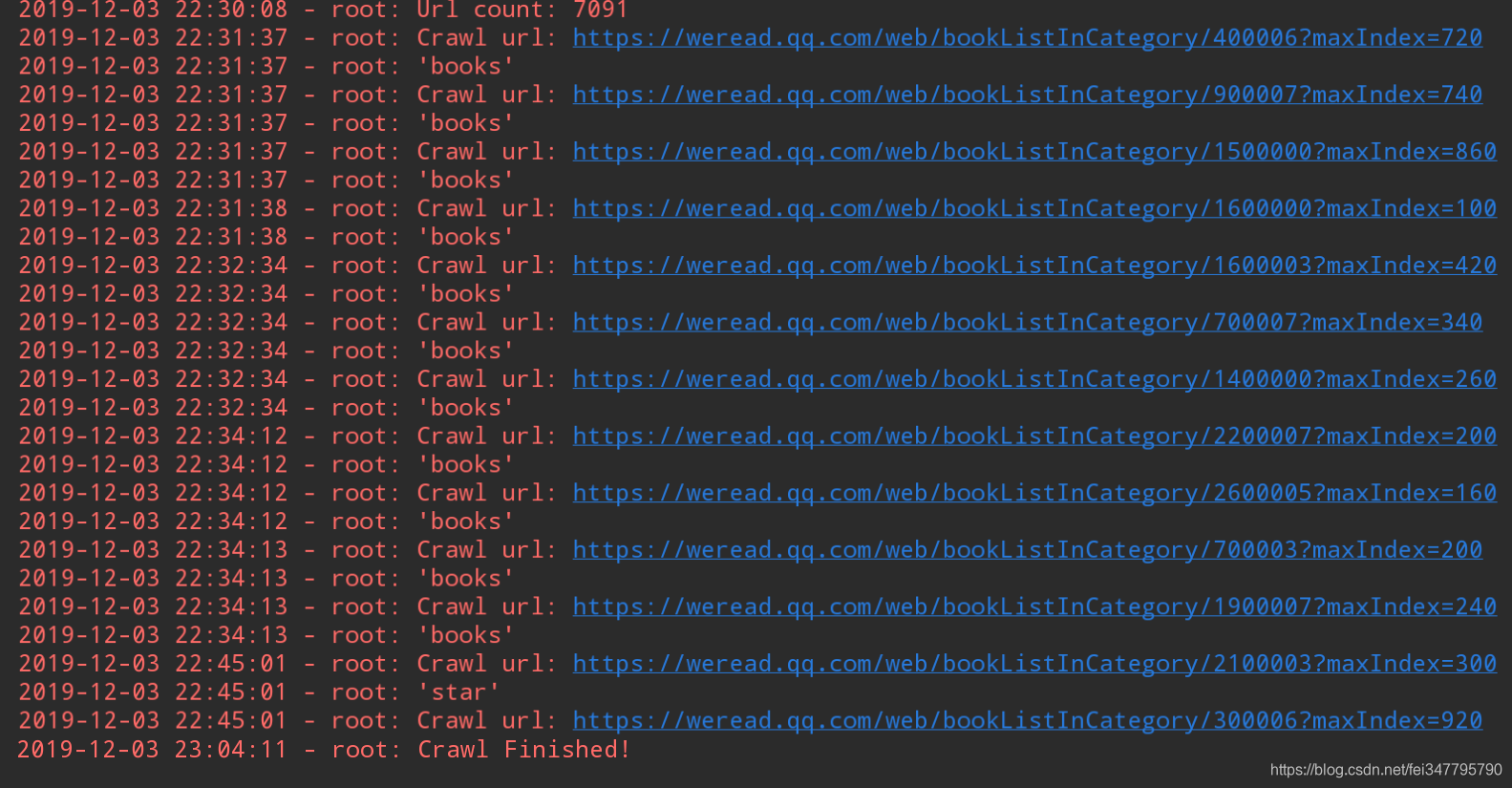
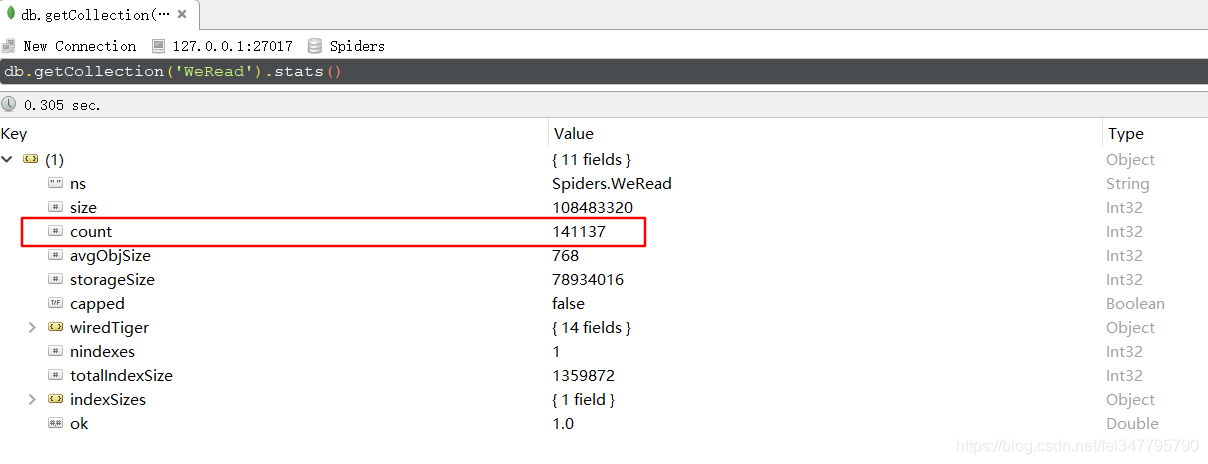
可以看到总链接数有7091条,那么爬到的书本信息有多少条呢?因为我用的是 MongoDB 保存的,所以打开 Robot3T 查看,总共有141137条,结果如下图:
绘图分析
熟悉 Python 的都知道,matplotlib 是 Python 中用的最多的 2D 图形绘图库。不过我在这推荐一个好用的第三方库:pyecharts,这是一个用于生成 Echarts 图表的类库,生成的图表更加精巧,可视化效果更好,不过需要注意的是 pyecharts 的0.5版本和1.0版本使用方法是不同的。下面就是使用这个库生成的横向柱状图了,分别表示评分前十的书籍、阅读量前十的书籍和总阅读量前十的作者: 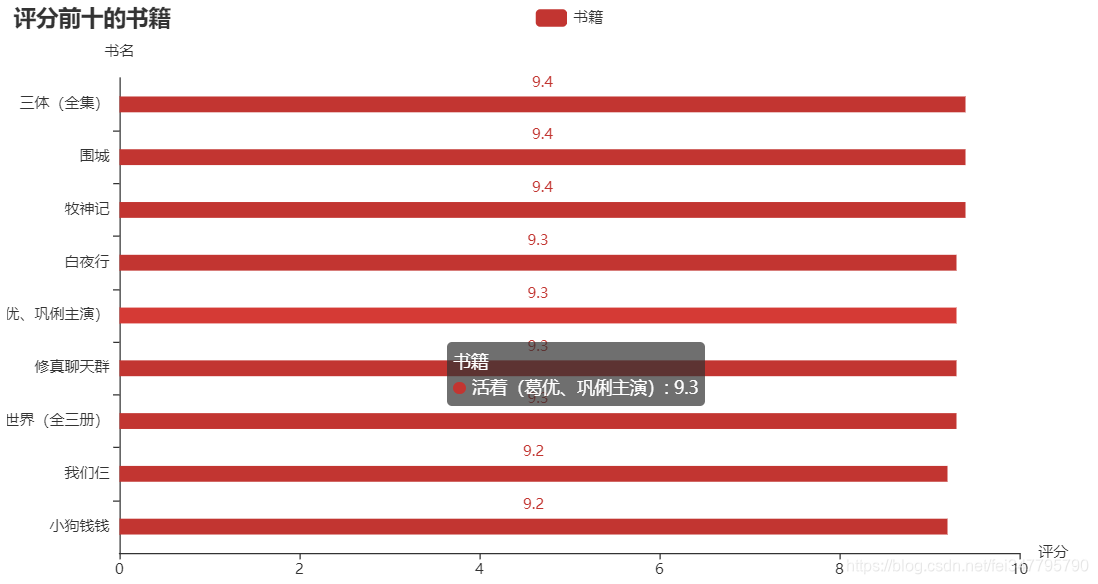
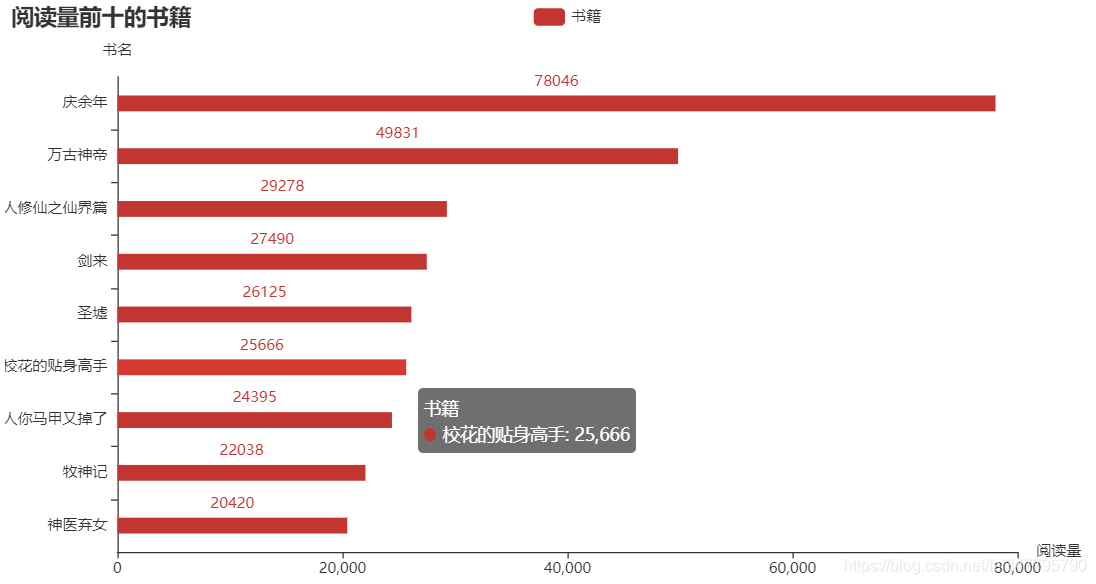
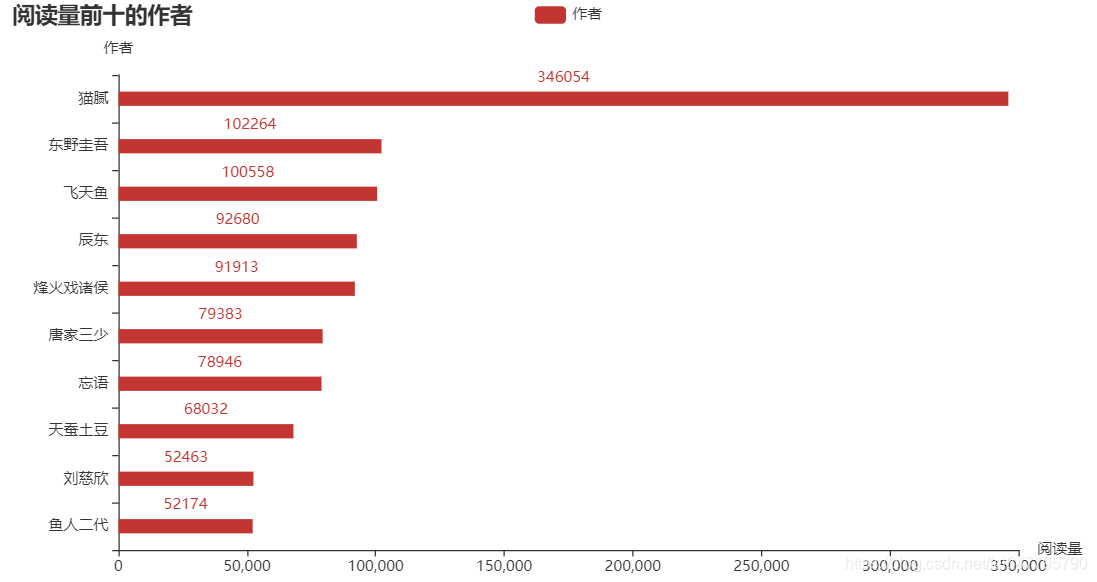
可以发现评分高的书籍阅读量却不一定高,阅读量更多的往往是一些网络小说。为什么好像现在名著都不怎么讨喜,而网络小说却能让更多人着迷呢?个人猜想是小说里的世界可能更加能够满足现在年轻人的幻想吧,现实生活疲惫不堪,就会更加迷恋小说中的“世外桃源”吧。
Python爬取十四万条书籍信息告诉你哪本网络小说更好看的更多相关文章
- 【Python3爬虫】网络小说更好看?十四万条书籍信息告诉你
一.前言简述 因为最近微信读书出了网页版,加上自己也在闲暇的时候看了两本书,不禁好奇什么样的书更受欢迎,哪位作者又更受读者喜欢呢?话不多说,爬一下就能有个了解了. 二.页面分析 首先打开微信读书:ht ...
- steam夏日促销悄然开始,用Python爬取排行榜上的游戏打折信息
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 不知不觉,一年一度如火如荼的steam夏日促销悄然开始了.每年通过大大小小 ...
- (转)Python网络爬虫实战:世纪佳缘爬取近6万条数据
又是一年双十一了,不知道从什么时候开始,双十一从“光棍节”变成了“双十一购物狂欢节”,最后一个属于单身狗的节日也成功被攻陷,成为了情侣们送礼物秀恩爱的节日. 翻着安静到死寂的聊天列表,我忽然惊醒,不行 ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- 全国315个城市,用python爬取肯德基老爷爷的店面信息
我觉得我生活在这世上二十多年里,去过最多的餐厅就是肯德基小时候逢生日必去,现在长大了,肯德基成了我的日常零食下班后从门前路过饿了便会进去点分黄金鸡块或者小吃拼盘早上路过,会买杯咖啡.主要快捷美味且饱腹 ...
- python爬取中国知网部分论文信息
爬取指定主题的论文,并以相关度排序. #!/usr/bin/python3 # -*- coding: utf-8 -*- import requests import linecache impor ...
- 学习Python 能找到工作?1300+条招聘信息告诉你答案
对于python这块有任何不懂的问题可以随时来问我,我对于学习方法,系统学习规划,还有学习效率这些知道一些,希望可以帮助大家少走弯路.当然也会送给大家一份系统性的python资料,文末附有爬虫项目实战 ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- python爬取当当网的书籍信息并保存到csv文件
python爬取当当网的书籍信息并保存到csv文件 依赖的库: requests #用来获取页面内容 BeautifulSoup #opython3不能安装BeautifulSoup,但可以安装Bea ...
随机推荐
- 用了 Lambda 之后,发现可以忘记设计模式了
设计模式是过去的一些好的经验和套路的总结,但是好的语言特性可以让开发者不去考虑这些设计模式.面向对象常见的设计模式有策略模式.模板方法.观察者模式.责任链模式以及工厂模式,使用Lambda表达式(函数 ...
- CBrother脚本10分钟写一个拯救“小霸王服务器”的程序
CBrother脚本语言10分钟写一个拯救“小霸王服务器”的程序 到了一家新公司,接手了一坨c++服务器代码,到处内存泄漏,这服务器没有数据库,挂了后重启一下就好了,公司就这么凑活着用了几年了,定时重 ...
- redis的embstr编码
问题来了 今天在看书籍<Redis设计与实现>的时候,在8.2字符串对象里面写到 如果字符串对象保存的是一个字符串值, 并且这个字符串值的长度大于 39 字节, 那么字符串对象将使用一个简 ...
- Nginx图片防盗链配置
如果我们自己网站内的图片资源被其它网站所盗用,这会增加自己网站的带宽资源,增加很多额外的消耗,而且会对我们系统的稳定性有影响,为了防止自己网站上的图片资源被其它网站所盗用,我们需要给自己的服务器配置防 ...
- SpringBoot整合Thymeleaf表单更新操作
对于表单值回显并更新的逻辑相比大家都已经很熟悉了, 但是我们操作Thymeleaf的话这里就会有一点小坑了, 在要回显值的表单的所有字段上,我们都要加上 th:field,才可以完成回显值更新 或者这 ...
- form表单提交与ajax消息传递
form表单提交与ajax消息传递 1.前后端传输数据编码格式contentType: urlencoded 对应的数据格式:name=xxx&password=666 后端获取数据:requ ...
- ThinkPHP5.x.x各版本实战环境getshell
#这个文章我之前在t00ls已经分享过了 #内容只是对tp5的实战环境下getshell做的记录,中间遇到的一些小问题的突破,没啥技术含量 -5.1.18 http://www.xxxxx.com/? ...
- Python 第一個程序
以默認方式安裝,會將 Python 安裝在目錄 C:\Users\Administrator\AppData\Local\Programs\Python\Python37 下: 有趣的是: 在此目錄下 ...
- CSS绘制三角形和箭头,不用再用图片了
前言 还在用图片制作箭头,三角形,那就太lou了.css可以轻松搞定这一切,而且颜色大小想怎么变就怎么变,还不用担心失真等问题. 先来看看这段代码: /**css*/.d1{ width: 0; he ...
- 压测工具ab
1.安装abyum install httpd-tools 2.使用ab -n 2000 -c 2 http://www.cctv.com-n:总的请求数-c:并发数-k:是否开启长连接 3.结果举例 ...