初探内核之《Linux内核设计与实现》笔记下
定时器和时间管理
系统中有很多与时间相关的程序(比如定期执行的任务,某一时间执行的任务,推迟一段时间执行的任务),因此,时间的管理对于linux来说非常重要。
主要内容:
- 系统时间
- 定时器
- 定时器相关概念
- 定时器执行流程
- 实现程序延迟的方法
- 定时器和延迟的例子
1. 系统时间
系统中管理的时间有2种:实际时间和定时器。
1.1 实际时间
实际时间就是现实中钟表上显示的时间,其实内核中并不常用这个时间,主要是用户空间的程序有时需要获取当前时间,所以内核中也管理着这个时间。实际时间的获取是在开机后,内核初始化时从RTC读取的。内核读取这个时间后就将其放入内核中的 xtime 变量中,并且在系统的运行中不断更新这个值。
注:RTC就是实时时钟的缩写,它是用来存放系统时间的设备。一般和BIOS一样,由主板上的电池供电的,所以即使关机也可将时间保存。
实际时间存放的变量 xtime 在文件 kernel/time/timekeeping.c中。
/* 按照16位对齐,其实就是2个long型的数据 */
struct timespec xtime __attribute__ ((aligned (16))); /* timespec结构体的定义如下, 参考 <linux/time.h> */
struct timespec {
__kernel_time_t tv_sec; /* seconds */
long tv_nsec; /* nanoseconds */
}; /* _kernel_time_t 定义如下 */
typedef long __kernel_time_t;
系统读写 xtime 时用的就是顺序锁。
/* 写入 xtime 参考 do_sometimeofday 方法 */
int do_settimeofday(struct timespec *tv)
{
/* 省略 。。。。 */
write_seqlock_irqsave(&xtime_lock, flags); /* 获取写锁 */
/* 更新 xtime */
write_sequnlock_irqrestore(&xtime_lock, flags); /* 释放写锁 */
/* 省略 。。。。 */
return 0;
} /* 读取 xtime 参考 do_gettimeofday 方法 */
void do_gettimeofday(struct timeval *tv)
{
struct timespec now; getnstimeofday(&now); /* 就是在这个方法中获取读锁,并读取 xtime */
tv->tv_sec = now.tv_sec;
tv->tv_usec = now.tv_nsec/1000;
} void getnstimeofday(struct timespec *ts)
{
/* 省略 。。。。 */ /* 顺序锁中读锁来循环获取 xtime,直至读取过程中 xtime 没有被改变过 */
do {
seq = read_seqbegin(&xtime_lock); *ts = xtime;
nsecs = timekeeping_get_ns(); /* If arch requires, add in gettimeoffset() */
nsecs += arch_gettimeoffset(); } while (read_seqretry(&xtime_lock, seq));
/* 省略 。。。。 */
}
上述场景中,写锁必须要优先于读锁(因为 xtime 必须及时更新),而且写锁的使用者很少(一般只有系统定期更新xtime的线程需要持有这个锁)。
这正是 顺序锁的应用场景。
1.2 定时器
定时器是内核中主要使用的时间管理方法,通过定时器,可以有效的调度程序的执行。
动态定时器是内核中使用比较多的定时器,下面重点讨论的也是动态定时器。
2. 定时器
内核中的定时器有2种,静态定时器和动态定时器。静态定时器一般执行了一些周期性的固定工作:
- 更新系统运行时间
- 更新实际时间
- 在SMP系统上,平衡各个处理器上的运行队列
- 检查当前进程是否用尽了自己的时间片,如果用尽,需要重新调度。
- 更新资源消耗和处理器时间统计值
动态定时器顾名思义,是在需要时(一般是推迟程序执行)动态创建的定时器,使用后销毁(一般都是只用一次)。一般我们在内核代码中使用的定时器基本都是动态定时器,下面重点讨论动态定时器相关的概念和使用方法。
3. 定时器相关概念
定时器的使用中,下面3个概念非常重要:
- HZ
- jiffies
- 时间中断处理程序
3.1 HZ
节拍率(HZ)是时钟中断的频率,表示的一秒内时钟中断的次数。比如 HZ=100 表示一秒内触发100次时钟中断程序。HZ的值一般与体系结构有关,x86 体系结构一般定义为 100,参考文件 include/asm-generic/param.h
HZ值的大小的设置过程其实就是平衡 精度和性能 的过程,并不是HZ值越高越好。
|
HZ值 |
优势 |
劣势 |
| 高HZ | 时钟中断程序运行的更加频繁,依赖时间执行的程序更加精确, 对资源消耗和系统运行时间的统计更加精确。 |
时钟中断执行的频繁,增加系统负担 时钟中断占用的CPU时间过多 |
此外,有一点需要注意,内核中使用的HZ可能和用户空间中定义的HZ值不一致,为了避免用户空间取得错误的时间,内核中也定义了 USER_HZ,即用户空间使用的HZ值。一般来说,USER_HZ 和 HZ 都是相差整数倍,内核中通过函数 jiffies_to_clock_t 来将内核来将内核中的 jiffies转为 用户空间 jiffies
/* 参见文件: kernel/time.c *
//*
* Convert jiffies/jiffies_64 to clock_t and back.
*/
clock_t jiffies_to_clock_t(unsigned long x)
{
#if (TICK_NSEC % (NSEC_PER_SEC / USER_HZ)) == 0
# if HZ < USER_HZ
return x * (USER_HZ / HZ);
# else
return x / (HZ / USER_HZ);
# endif
#else
return div_u64((u64)x * TICK_NSEC, NSEC_PER_SEC / USER_HZ);
#endif
}
EXPORT_SYMBOL(jiffies_to_clock_t);
3.2 jiffies
jiffies用来记录自系统启动以来产生的总节拍数。比如系统启动了 N 秒,那么 jiffies就为 N×HZ
jiffies的相关定义参考头文件 <linux/jiffies.h> include/linux/jiffies.h
/* 64bit和32bit的jiffies定义如下 */
extern u64 __jiffy_data jiffies_64;
extern unsigned long volatile __jiffy_data jiffies;
使用定时器时一般都是以jiffies为单位来延迟程序执行的,比如延迟5个节拍后执行的话,执行时间就是 jiffies+5
32位的jiffies的最大值为 2^32-1,在使用时有可能会出现回绕的问题。
比如下面的代码:
unsigned long timeout = jiffies + HZ/2; /* 设置超时时间为 0.5秒 */ while (timeout < jiffies)
{
/* 还没有超时,继续执行任务 */
} /* 执行超时后的任务 */
正常情况下,上面的代码没有问题。当jiffies接近最大值的时候,就会出现回绕问题。
由于是unsinged long类型,所以jiffies达到最大值后会变成0然后再逐渐变大,如下图所示:

所以在上述的循环代码中,会出现如下情况:

- 循环中第一次比较时,jiffies = J1,没有超时
- 循环中第二次比较时,jiffies = J2,实际已经超时了,但是由于jiffies超过的最大值后又从0开始,所以J2远远小于timeout
- while循环会执行很长时间(> 2^32-1 个节拍)不会结束,几乎相当于死循环了
为了回避回扰的问题,可以使用<linux/jiffies.h>头文件中提供的 time_after,time_before等宏
#define time_after(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(b) - (long)(a) < 0))
#define time_before(a,b) time_after(b,a) #define time_after_eq(a,b) \
(typecheck(unsigned long, a) && \
typecheck(unsigned long, b) && \
((long)(a) - (long)(b) >= 0))
#define time_before_eq(a,b) time_after_eq(b,a)
上述代码的原理其实就是将 unsigned long 类型转换为 long 类型来避免回扰带来的错误,
long 类型超过最大值时变化趋势如下:

long 型的数据的回绕会出现在 2^31-1 变为 -2^32 的时候,如下图所示:

- 第一次比较时,jiffies = J1,没有超时
- 第二次比较时,jiffies = J2,一般 J2 是负数
理论上 (long)timeout - (long)J2 = 正数 - 负数 = 正数(result)
但是,这个正数(result)一般会大于 2^31 - 1,所以long型的result又发生了一次回绕,变成了负数。
除非timeout和J2之间的间隔 > 2^32 个节拍,result的值才会为正数(注1)。
注1:result的值为正数时,必须是在result的值 小于 2^31-1 的情况下,大于 2^31-1 会发生回绕。

上图中 X + Y 表示timeout 和 J2之间经过的节拍数。result 小于 2^31-1 ,也就是 timeout - J2 < 2^31 – 1,timeout 和 -J2 表示的节拍数如上图所示。(因为J2是负数,所有-J2表示上图所示范围的值)因为 timeout + X + Y - J2 = 2^31-1 + 2^32所以 timeout - J2 < 2^31 - 1 时, X + Y > 2^32也就是说,当timeout和J2之间经过至少 2^32 个节拍后,result才可能变为正数。timeout和J2之间相差这么多节拍是不可能的(不信可以用HZ将这些节拍换算成秒就知道了。。。)
利用time_after宏就可以巧妙的避免回绕带来的超时判断问题,将之前的代码改成如下代码即可:
unsigned long timeout = jiffies + HZ/2; /* 设置超时时间为 0.5秒 */ while (time_after(jiffies, timeout))
{
/* 还没有超时,继续执行任务 */
} /* 执行超时后的任务 */
3.3 时钟中断处理程序
时钟中断处理程序作为系统定时器而注册到内核中,体系结构的不同,可能时钟中断处理程序中处理的内容不同。
但是以下这些基本的工作都会执行:
- 获得 xtime_lock 锁,以便对访问 jiffies_64 和墙上时间 xtime 进行保护
- 需要时应答或重新设置系统时钟
- 周期性的使用墙上时间更新实时时钟
- 调用 tick_periodic()
tick_periodic函数位于: kernel/time/tick-common.c 中
static void tick_periodic(int cpu)
{
if (tick_do_timer_cpu == cpu) {
write_seqlock(&xtime_lock); /* Keep track of the next tick event */
tick_next_period = ktime_add(tick_next_period, tick_period); do_timer(1);
write_sequnlock(&xtime_lock);
} update_process_times(user_mode(get_irq_regs()));
profile_tick(CPU_PROFILING);
}
其中最重要的是 do_timer 和 update_process_times 函数。
我了解的步骤进行了简单的注释。
void do_timer(unsigned long ticks)
{
/* jiffies_64 增加指定ticks */
jiffies_64 += ticks;
/* 更新实际时间 */
update_wall_time();
/* 更新系统的平均负载值 */
calc_global_load();
} void update_process_times(int user_tick)
{
struct task_struct *p = current;
int cpu = smp_processor_id(); /* 更新当前进程占用CPU的时间 */
account_process_tick(p, user_tick);
/* 同时触发软中断,处理所有到期的定时器 */
run_local_timers();
rcu_check_callbacks(cpu, user_tick);
printk_tick();
/* 减少当前进程的时间片数 */
scheduler_tick();
run_posix_cpu_timers(p);
}
4. 定时器执行流程
这里讨论的定时器执行流程是动态定时器的执行流程。
4.1 定时器的定义
定时器在内核中用一个链表来保存的,链表的每个节点都是一个定时器。
参见头文件 <linux/timer.h>
struct timer_list {
struct list_head entry;
unsigned long expires;
void (*function)(unsigned long);
unsigned long data;
struct tvec_base *base;
#ifdef CONFIG_TIMER_STATS
void *start_site;
char start_comm[16];
int start_pid;
#endif
#ifdef CONFIG_LOCKDEP
struct lockdep_map lockdep_map;
#endif
};
通过加入条件编译的参数,可以追加一些调试信息。
4.2 定时器的生命周期
一个动态定时器的生命周期中,一般会经过下面的几个步骤:

1. 初始化定时器:
struct timer_list my_timer; /* 定义定时器 */
init_timer(&my_timer); /* 初始化定时器 */
2. 填充定时器:
my_timer.expires = jiffies + delay; /* 定义超时的节拍数 */
my_timer.data = 0; /* 给定时器函数传入的参数 */
my_timer.function = my_function; /* 定时器超时时,执行的自定义函数 */ /* 从定时器结构体中,我们可以看出这个函数的原型应该如下所示: */
void my_function(unsigned long data);
3. 激活定时器和修改定时器:
激活定时器之后才会被触发,否则定时器不会执行。
修改定时器主要是修改定时器的延迟时间,修改定时器后,不管原先定时器有没有被激活,都会处于激活状态。
填充定时器结构之后,可以只激活定时器,也可以只修改定时器,也可以激活定时器后再修改定时器。
所以填充定时器结构和触发定时器之间的步骤,也就是虚线框中的步骤是不确定的。
add_timer(&my_timer); /* 激活定时器 */
mod_timer(&my_timer, jiffies + new_delay); /* 修改定时器,设置新的延迟时间 */
4. 触发定时器:
每次时钟中断处理程序会检查已经激活的定时器是否超时,如果超时就执行定时器结构中的自定义函数。
5. 删除定时器:
激活和未被激活的定时器都可以被删除,已经超时的定时器会自动删除,不用特意去删除。
/*
* 删除激活的定时器时,此函数返回1
* 删除未激活的定时器时,此函数返回0
*/
del_timer(&my_timer);
在多核处理器上用 del_timer 函数删除定时器时,可能在删除时正好另一个CPU核上的时钟中断处理程序正在执行这个定时器,于是就形成了竞争条件。
为了避免竞争条件,建议使用 del_timer_sync 函数来删除定时器。
del_timer_sync 函数会等待其他处理器上的定时器处理程序全部结束后,才删除指定的定时器。
/*
* 和del_timer 不同,del_timer_sync 不能在中断上下文中执行
*/
del_timer_sync(&my_timer);
5. 实现程序延迟的方法
内核中有个利用定时器实现延迟的函数 schedule_timeout
这个函数会将当前的任务睡眠到指定时间后唤醒,所以等待时不会占用CPU时间。
/* 将任务设置为可中断睡眠状态 */
set_current_state(TASK_INTERRUPTIBLE); /* 小睡一会儿,“s“秒后唤醒 */
schedule_timeout(s*HZ);
查看 schedule_timeout 函数的实现方法,可以看出是如何使用定时器的。
signed long __sched schedule_timeout(signed long timeout)
{
/* 定义一个定时器 */
struct timer_list timer;
unsigned long expire; switch (timeout)
{
case MAX_SCHEDULE_TIMEOUT:
/*
* These two special cases are useful to be comfortable
* in the caller. Nothing more. We could take
* MAX_SCHEDULE_TIMEOUT from one of the negative value
* but I' d like to return a valid offset (>=0) to allow
* the caller to do everything it want with the retval.
*/
schedule();
goto out;
default:
/*
* Another bit of PARANOID. Note that the retval will be
* 0 since no piece of kernel is supposed to do a check
* for a negative retval of schedule_timeout() (since it
* should never happens anyway). You just have the printk()
* that will tell you if something is gone wrong and where.
*/
if (timeout < 0) {
printk(KERN_ERR "schedule_timeout: wrong timeout "
"value %lx\n", timeout);
dump_stack();
current->state = TASK_RUNNING;
goto out;
}
} /* 设置超时时间 */
expire = timeout + jiffies; /* 初始化定时器,超时处理函数是 process_timeout,后面再补充说明一下这个函数 */
setup_timer_on_stack(&timer, process_timeout, (unsigned long)current);
/* 修改定时器,同时会激活定时器 */
__mod_timer(&timer, expire, false, TIMER_NOT_PINNED);
/* 将本任务睡眠,调度其他任务 */
schedule();
/* 删除定时器,其实就是 del_timer_sync 的宏
del_singleshot_timer_sync(&timer); /* Remove the timer from the object tracker */
destroy_timer_on_stack(&timer); timeout = expire - jiffies; out:
return timeout < 0 ? 0 : timeout;
}
EXPORT_SYMBOL(schedule_timeout); /*
* 超时处理函数 process_timeout 里面只有一步操作,唤醒当前任务。
* process_timeout 的参数其实就是 当前任务的地址
*/
static void process_timeout(unsigned long __data)
{
wake_up_process((struct task_struct *)__data);
}
schedule_timeout 一般用于延迟时间较长的程序。
这里的延迟时间较长是对于计算机而言的,其实也就是延迟大于 1 个节拍(jiffies)。
对于某些极其短暂的延迟,比如只有1ms,甚至1us,1ns的延迟,必须使用特殊的延迟方法。
1s = 1000ms = 1000000us = 1000000000ns (1秒=1000毫秒=1000000微秒=1000000000纳秒)
假设 HZ=100,那么 1个节拍的时间间隔是 1/100秒,大概10ms左右。
所以对于那些极其短暂的延迟,schedule_timeout 函数是无法使用的。
好在内核对于这些短暂,精确的延迟要求也提供了相应的宏。
/* 具体实现参见 include/linux/delay.h
* 以及 arch/x86/include/asm/delay.h
*/
#define mdelay(n) ...
#define udelay(n) ...
#define ndelay(n) ...
通过这些宏,可以简单的实现延迟,比如延迟 5ns,只需 ndelay(5); 即可。
这些短延迟的实现原理并不复杂,
首先,内核在启动时就计算出了当前处理器1秒能执行多少次循环,即 loops_per_jiffy
(loops_per_jiffy 的计算方法参见 init/main.c 文件中的 calibrate_delay 方法)。
然后算出延迟 5ns 需要循环多少次,执行那么多次空循环即可达到延迟的效果。
loops_per_jiffy 的值可以在启动信息中看到:
[root@vbox ~]# dmesg | grep delay
Calibrating delay loop (skipped), value calculated using timer frequency.. 6387.58 BogoMIPS (lpj=3193792)
我的虚拟机中看到 (lpj=3193792)
6. 定时器和延迟的例子
下面的例子测试了短延迟,自定义定时器以及 schedule_timeout 的使用:
#include <linux/sched.h>
#include <linux/timer.h>
#include <linux/jiffies.h>
#include <asm/param.h>
#include <linux/delay.h>
#include "kn_common.h" MODULE_LICENSE("Dual BSD/GPL"); static void test_short_delay(void);
static void test_delay(void);
static void test_schedule_timeout(void);
static void my_delay_function(unsigned long); static int testdelay_init(void)
{
printk(KERN_ALERT "HZ in current system: %dHz\n", HZ); /* test short delay */
test_short_delay(); /* test delay */
test_delay(); /* test schedule timeout */
test_schedule_timeout(); return 0;
} static void testdelay_exit(void)
{
printk(KERN_ALERT "*************************\n");
print_current_time(0);
printk(KERN_ALERT "testdelay is exited!\n");
printk(KERN_ALERT "*************************\n");
} static void test_short_delay()
{
printk(KERN_ALERT "jiffies [b e f o r e] short delay: %lu", jiffies);
ndelay(5);
printk(KERN_ALERT "jiffies [a f t e r] short delay: %lu", jiffies);
} static void test_delay()
{
/* 初始化定时器 */
struct timer_list my_timer;
init_timer(&my_timer); /* 填充定时器 */
my_timer.expires = jiffies + 1*HZ; /* 2秒后超时函数执行 */
my_timer.data = jiffies;
my_timer.function = my_delay_function; /* 激活定时器 */
add_timer(&my_timer);
} static void my_delay_function(unsigned long data)
{
printk(KERN_ALERT "This is my delay function start......\n");
printk(KERN_ALERT "The jiffies when init timer: %lu\n", data);
printk(KERN_ALERT "The jiffies when timer is running: %lu\n", jiffies);
printk(KERN_ALERT "This is my delay function end........\n");
} static void test_schedule_timeout()
{
printk(KERN_ALERT "This sample start at : %lu", jiffies); /* 睡眠2秒 */
set_current_state(TASK_INTERRUPTIBLE);
printk(KERN_ALERT "sleep 2s ....\n");
schedule_timeout(2*HZ); printk(KERN_ALERT "This sample end at : %lu", jiffies);
} module_init(testdelay_init);
module_exit(testdelay_exit);
其中用到的 kn_common.h 和 kn_common.c 参见上文
Makefile如下:
# must complile on customize kernel
obj-m += mydelay.o
mydelay-objs := testdelay.o kn_common.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
执行测试命令及查看结果的方法如下:(我的测试系统是 CentOS 6.3 x64)
[root@vbox wzh]# make
[root@vbox wzh]# insmod mydelay.ko
[root@vbox wzh]# rmmod mydelay.ko
[root@vbox wzh]# dmesg | tail -14
HZ in current system: 1000Hz
jiffies [b e f o r e] short delay: 4296079617
jiffies [a f t e r] short delay: 4296079617
This sample start at : 4296079619
sleep 2s ....
This is my delay function start......
The jiffies when init timer: 4296079619
The jiffies when timer is running: 4296080621
This is my delay function end........
This sample end at : 4296081622
*************************
2019-9-25 23:7:20
testdelay is exited!
*************************
结果说明:
1. 短延迟只延迟了 5ns,所以执行前后的jiffies是一样的。
jiffies [b e f o r e] short delay: 4296079617
jiffies [a f t e r] short delay: 4296079617
2. 自定义定时器延迟了1秒后执行自定义函数,由于我的系统 HZ=1000,所以jiffies应该相差1000
The jiffies when init timer: 4296079619
The jiffies when timer is running: 4296080621
实际上jiffies相差了 1002,多了2个节拍
3. schedule_timeout 延迟了2秒,jiffies应该相差 2000
This sample start at : 4296079619
This sample end at : 4296081622
实际上jiffies相差了 2003,多了3个节拍,以上结果也说明了定时器的延迟并不是那么精确,差了2,3个节拍其实就是误差2,3毫秒(因为HZ=1000),如果HZ=100的话,一个节拍是10毫秒,那么定时器的误差可能就发现不了了(误差只有2,3毫秒,没有超多1个节拍)。
内存管理
内核的内存使用不像用户空间那样随意,内核的内存出现错误时也只有靠自己来解决(用户空间的内存错误可以抛给内核来解决)。所有内核的内存管理必须要简洁而且高效。
主要内容:
- 内存的管理单元
- 获取内存的方法
- 获取高端内存
- 内核内存的分配方式
- 总结
1. 内存的管理单元
内存最基本的管理单元是页,同时按照内存地址的大小,大致分为3个区。
1.1 页
页的大小与体系结构有关,在 x86 结构中一般是 4KB或者8KB。
可以通过 getconf 命令来查看系统的page的大小:
[wangyubin@localhost ]$ getconf -a | grep -i 'page' PAGESIZE 4096
PAGE_SIZE 4096
_AVPHYS_PAGES 637406
_PHYS_PAGES 2012863
以上的 PAGESIZE 就是当前机器页大小,即 4KB
页的结构体头文件是: <linux/mm_types.h> 位置:include/linux/mm_types.h
/*
* 页中包含的成员非常多,还包含了一些联合体
* 其中有些字段我暂时还不清楚含义,以后再补上。。。
*/
struct page {
unsigned long flags; /* 存放页的状态,各种状态参见<linux/page-flags.h> */
atomic_t _count; /* 页的引用计数 */
union {
atomic_t _mapcount; /* 已经映射到mms的pte的个数 */
struct { /* 用于slab层 */
u16 inuse;
u16 objects;
};
};
union {
struct {
unsigned long private; /* 此page作为私有数据时,指向私有数据 */
struct address_space *mapping; /* 此page作为页缓存时,指向关联的address_space */
};
#if USE_SPLIT_PTLOCKS
spinlock_t ptl;
#endif
struct kmem_cache *slab; /* 指向slab层 */
struct page *first_page; /* 尾部复合页中的第一个页 */
};
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* SLUB: freelist req. slab lock */
};
struct list_head lru; /* 将页关联起来的链表项 */
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* 页的虚拟地址 */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_WANT_PAGE_DEBUG_FLAGS
unsigned long debug_flags; /* Use atomic bitops on this */
#endif #ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
};
物理内存的每个页都有一个对应的 page 结构,看似会在管理上浪费很多内存,其实细细算来并没有多少。
比如上面的page结构体,每个字段都算4个字节的话,总共40多个字节。(union结构只算一个字段)
那么对于一个页大小 4KB 的 4G内存来说,一个有 4*1024*1024 / 4 = 1048576 个page,
一个page 算40个字节,在管理内存上共消耗内存 40MB左右。
如果页的大小是 8KB 的话,消耗的内存只有 20MB 左右。相对于 4GB 来说并不算很多。
1.2 区
页是内存管理的最小单元,但是并不是所有的页对于内核都一样。
内核将内存按地址的顺序分成了不同的区,有的硬件只能访问有专门的区。
内核中分的区定义在头文件 <linux/mmzone.h> 位置:include/linux/mmzone.h
内存区的种类参见 enum zone_type 中的定义。
内存区的结构体定义也在 <linux/mmzone.h> 中。
具体参考其中 struct zone 的定义。
其实一般主要关注的区只有3个:
|
区 |
描述 |
物理内存 |
| ZONE_DMA | DMA使用的页 | <16MB |
| ZONE_NORMAL | 正常可寻址的页 | 16~896MB |
| ZONE_HIGHMEM | 动态映射的页 | >896MB |
某些硬件只能直接访问内存地址,不支持内存映射,对于这些硬件内核会分配 ZONE_DMA 区的内存。
某些硬件的内存寻址范围很广,比虚拟寻址范围还要大的多,那么就会用到 ZONE_HIGHMEM 区的内存,
对于 ZONE_HIGHMEM 区的内存,后面还会讨论。
对于大部分的内存申请,只要用 ZONE_NORMAL 区的内存即可。
2. 获取内存的方法
内核中提供了多种获取内存的方法,了解各种方法的特点,可以恰当的将其用于合适的场景。
2.1 按页获取 - 最原始的方法,用于底层获取内存的方式
以下分配内存的方法参见:<linux/gfp.h>
|
方法 |
描述 |
| alloc_page(gfp_mask) | 只分配一页,返回指向页结构的指针 |
| alloc_pages(gfp_mask, order) | 分配 2^order 个页,返回指向第一页页结构的指针 |
| __get_free_page(gfp_mask) | 只分配一页,返回指向其逻辑地址的指针 |
| __get_free_pages(gfp_mask, order) | 分配 2^order 个页,返回指向第一页逻辑地址的指针 |
| get_zeroed_page(gfp_mask) | 只分配一页,让其内容填充为0,返回指向其逻辑地址的指针 |
alloc** 方法和 get** 方法的区别在于,一个返回的是内存的物理地址,一个返回内存物理地址映射后的逻辑地址。
如果无须直接操作物理页结构体的话,一般使用 get** 方法。
相应的释放内存的函数如下:也是在 <linux/gfp.h> 中定义的
extern void __free_pages(struct page *page, unsigned int order);
extern void free_pages(unsigned long addr, unsigned int order);
extern void free_hot_page(struct page *page);
在请求内存时,参数中有个 gfp_mask 标志,这个标志是控制分配内存时必须遵守的一些规则。
gfp_mask 标志有3类:(所有的 GFP 标志都在 <linux/gfp.h> 中定义)
- 行为标志 :控制分配内存时,分配器的一些行为
- 区标志 :控制内存分配在那个区(ZONE_DMA, ZONE_NORMAL, ZONE_HIGHMEM 之类)
- 类型标志 :由上面2种标志组合而成的一些常用的场景
行为标志主要有以下几种:
|
行为标志 |
描述 |
| __GFP_WAIT | 分配器可以睡眠 |
| __GFP_HIGH | 分配器可以访问紧急事件缓冲池 |
| __GFP_IO | 分配器可以启动磁盘I/O |
| __GFP_FS | 分配器可以启动文件系统I/O |
| __GFP_COLD | 分配器应该使用高速缓存中快要淘汰出去的页 |
| __GFP_NOWARN | 分配器将不打印失败警告 |
| __GFP_REPEAT | 分配器在分配失败时重复进行分配,但是这次分配还存在失败的可能 |
| __GFP_NOFALL | 分配器将无限的重复进行分配。分配不能失败 |
| __GFP_NORETRY | 分配器在分配失败时不会重新分配 |
| __GFP_NO_GROW | 由slab层内部使用 |
| __GFP_COMP | 添加混合页元数据,在 hugetlb 的代码内部使用 |
区标志主要以下3种:
|
区标志 |
描述 |
| __GFP_DMA | 从 ZONE_DMA 分配 |
| __GFP_DMA32 | 只在 ZONE_DMA32 分配 (注1) |
| __GFP_HIGHMEM | 从 ZONE_HIGHMEM 或者 ZONE_NORMAL 分配 (注2) |
注1:ZONE_DMA32 和 ZONE_DMA 类似,该区包含的页也可以进行DMA操作。
唯一不同的地方在于,ZONE_DMA32 区的页只能被32位设备访问。
注2:优先从 ZONE_HIGHMEM 分配,如果 ZONE_HIGHMEM 没有多余的页则从 ZONE_NORMAL 分配。
类型标志是编程中最常用的,在使用标志时,应首先看看类型标志中是否有合适的,如果没有,再去自己组合 行为标志和区标志。
|
类型标志 |
实际标志 |
描述 |
| GFP_ATOMIC | __GFP_HIGH | 这个标志用在中断处理程序,下半部,持有自旋锁以及其他不能睡眠的地方 |
| GFP_NOWAIT | 0 | 与 GFP_ATOMIC 类似,不同之处在于,调用不会退给紧急内存池。 这就增加了内存分配失败的可能性 |
| GFP_NOIO | __GFP_WAIT | 这种分配可以阻塞,但不会启动磁盘I/O。 这个标志在不能引发更多磁盘I/O时能阻塞I/O代码,可能会导致递归 |
| GFP_NOFS | (__GFP_WAIT | __GFP_IO) | 这种分配在必要时可能阻塞,也可能启动磁盘I/O,但不会启动文件系统操作。 这个标志在你不能再启动另一个文件系统的操作时,用在文件系统部分的代码中 |
| GFP_KERNEL | (__GFP_WAIT | __GFP_IO | __GFP_FS ) | 这是常规的分配方式,可能会阻塞。这个标志在睡眠安全时用在进程上下文代码中。 为了获得调用者所需的内存,内核会尽力而为。这个标志应当为首选标志 |
| GFP_USER | (__GFP_WAIT | __GFP_IO | __GFP_FS ) | 这是常规的分配方式,可能会阻塞。用于为用户空间进程分配内存时 |
| GFP_HIGHUSER | (__GFP_WAIT | __GFP_IO | __GFP_FS )|__GFP_HIGHMEM) | 从 ZONE_HIGHMEM 进行分配,可能会阻塞。用于为用户空间进程分配内存 |
| GFP_DMA | __GFP_DMA | 从 ZONE_DMA 进行分配。需要获取能供DMA使用的内存的设备驱动程序使用这个标志 通常与以上的某个标志组合在一起使用。 |
以上各种类型标志的使用场景总结:
|
场景 |
相应标志 |
| 进程上下文,可以睡眠 | 使用 GFP_KERNEL |
| 进程上下文,不可以睡眠 | 使用 GFP_ATOMIC,在睡眠之前或之后以 GFP_KERNEL 执行内存分配 |
| 中断处理程序 | 使用 GFP_ATOMIC |
| 软中断 | 使用 GFP_ATOMIC |
| tasklet | 使用 GFP_ATOMIC |
| 需要用于DMA的内存,可以睡眠 | 使用 (GFP_DMA|GFP_KERNEL) |
| 需要用于DMA的内存,不可以睡眠 | 使用 (GFP_DMA|GFP_ATOMIC),或者在睡眠之前执行内存分配 |
2.2 按字节获取 - 用的最多的获取方法
这种内存分配方法是平时使用比较多的,主要有2种分配方法:kmalloc()和vmalloc()
kmalloc的定义在 <linux/slab_def.h> 中
/**
* @size - 申请分配的字节数
* @flags - 上面讨论的各种 gfp_mask
*/
static __always_inline void *kmalloc(size_t size, gfp_t flags)
#+end_src vmalloc的定义在 mm/vmalloc.c 中
#+begin_src C
/**
* @size - 申请分配的字节数
*/
void *vmalloc(unsigned long size)
kmalloc 和 vmalloc 区别在于:
- kmalloc 分配的内存物理地址是连续的,虚拟地址也是连续的
- vmalloc 分配的内存物理地址是不连续的,虚拟地址是连续的
因此在使用中,用的较多的还是 kmalloc,因为kmalloc 的性能较好。
因为kmalloc的物理地址和虚拟地址之间的映射比较简单,只需要将物理地址的第一页和虚拟地址的第一页关联起来即可。
而vmalloc由于物理地址是不连续的,所以要将物理地址的每一页都和虚拟地址关联起来才行。
kmalloc 和 vmalloc 所对应的释放内存的方法分别为:
void kfree(const void *)
void vfree(const void *)
2.3 slab层获取 - 效率最高的获取方法
频繁的分配/释放内存必然导致系统性能的下降,所以有必要为频繁分配/释放的对象内心建立缓存。
而且,如果能为每个处理器建立专用的高速缓存,还可以避免 SMP锁带来的性能损耗。
2.3.1 slab层实现原理
linux中的高速缓存是用所谓 slab 层来实现的,slab层即内核中管理高速缓存的机制。
整个slab层的原理如下:
- 可以在内存中建立各种对象的高速缓存(比如进程描述相关的结构 task_struct 的高速缓存)
- 除了针对特定对象的高速缓存以外,也有通用对象的高速缓存
- 每个高速缓存中包含多个 slab,slab用于管理缓存的对象
- slab中包含多个缓存的对象,物理上由一页或多个连续的页组成
高速缓存->slab->缓存对象之间的关系如下图:
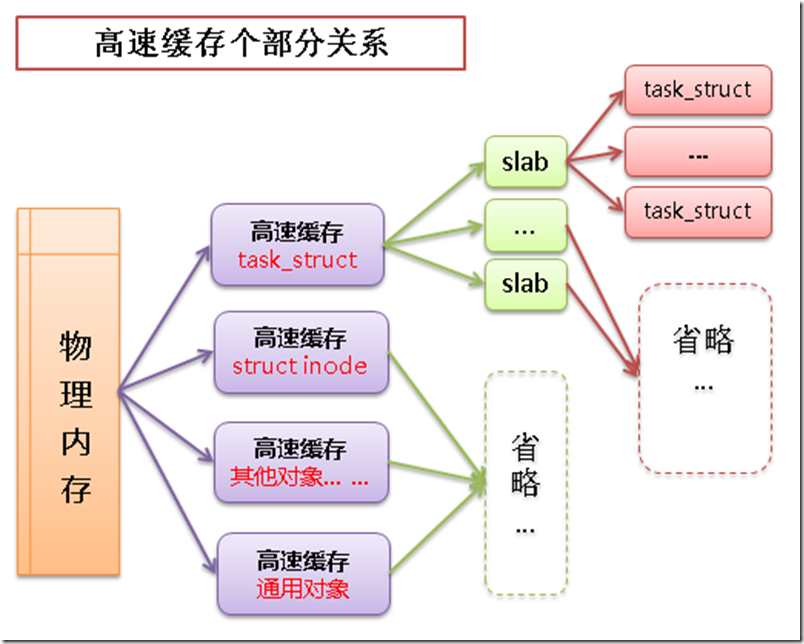
2.3.2 slab层的应用
slab结构体的定义参见:mm/slab.c
struct slab {
struct list_head list; /* 存放缓存对象,这个链表有 满,部分满,空 3种状态 */
unsigned long colouroff; /* slab 着色的偏移量 */
void *s_mem; /* 在 slab 中的第一个对象 */
unsigned int inuse; /* slab 中已分配的对象数 */
kmem_bufctl_t free; /* 第一个空闲对象(如果有的话) */
unsigned short nodeid; /* 应该是在 NUMA 环境下使用 */
};
slab层的应用主要有四个方法:
- 高速缓存的创建
- 从高速缓存中分配对象
- 向高速缓存释放对象
- 高速缓存的销毁
/**
* 创建高速缓存
* 参见文件: mm/slab.c
* 这个函数的注释很详细,这里就不多说了。
*/
struct kmem_cache *
kmem_cache_create (const char *name, size_t size, size_t align,
unsigned long flags, void (*ctor)(void *)) /**
* 从高速缓存中分配对象也很简单
* 函数参见文件:mm/slab.c
* @cachep - 指向高速缓存指针
* @flags - 之前讨论的 gfp_mask 标志,只有在高速缓存中所有slab都没有空闲对象时,
* 需要申请新的空间时,这个标志才会起作用。
*
* 分配成功时,返回指向对象的指针
*/
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags) /**
* 向高速缓存释放对象
* @cachep - 指向高速缓存指针
* @objp - 要释放的对象的指针
*/
void kmem_cache_free(struct kmem_cache *cachep, void *objp) /**
* 销毁高速缓存
* @cachep - 指向高速缓存指针
*/
void kmem_cache_destroy(struct kmem_cache *cachep)
我做了创建高速缓存的例子,来尝试使用上面的几个函数。
测试代码如下:
#include <linux/slab.h>
#include <linux/slab_def.h>
#include "kn_common.h" MODULE_LICENSE("Dual BSD/GPL"); #define MYSLAB "testslab" static struct kmem_cache *myslab; /* 申请内存时调用的构造函数 */
static void ctor(void* obj)
{
printk(KERN_ALERT "constructor is running....\n");
} struct student
{
int id;
char* name;
}; static void print_student(struct student *); static int testslab_init(void)
{
struct student *stu1, *stu2; /* 建立slab高速缓存,名称就是宏 MYSLAB */
myslab = kmem_cache_create(MYSLAB,
sizeof(struct student),
0,
0,
ctor); /* 高速缓存中分配2个对象 */
printk(KERN_ALERT "alloc one student....\n");
stu1 = (struct student*)kmem_cache_alloc(myslab, GFP_KERNEL);
stu1->id = 1;
stu1->name = "wyb1";
print_student(stu1); printk(KERN_ALERT "alloc one student....\n");
stu2 = (struct student*)kmem_cache_alloc(myslab, GFP_KERNEL);
stu2->id = 2;
stu2->name = "wyb2";
print_student(stu2); /* 释放高速缓存中的对象 */
printk(KERN_ALERT "free one student....\n");
kmem_cache_free(myslab, stu1); printk(KERN_ALERT "free one student....\n");
kmem_cache_free(myslab, stu2); /* 执行完后查看 /proc/slabinfo 文件中是否有名称为 “testslab”的缓存 */
return 0;
} static void testslab_exit(void)
{
/* 删除建立的高速缓存 */
printk(KERN_ALERT "*************************\n");
print_current_time(0);
kmem_cache_destroy(myslab);
printk(KERN_ALERT "testslab is exited!\n");
printk(KERN_ALERT "*************************\n"); /* 执行完后查看 /proc/slabinfo 文件中是否有名称为 “testslab”的缓存 */
} static void print_student(struct student *stu)
{
if (stu != NULL)
{
printk(KERN_ALERT "**********student info***********\n");
printk(KERN_ALERT "student id is: %d\n", stu->id);
printk(KERN_ALERT "student name is: %s\n", stu->name);
printk(KERN_ALERT "*********************************\n");
}
else
printk(KERN_ALERT "the student info is null!!\n");
} module_init(testslab_init);
module_exit(testslab_exit);
Makefile文件如下:
# must complile on customize kernel
obj-m += myslab.o
myslab-objs := testslab.o kn_common.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
执行测试代码:(我是在 ubuntu x64 上实验的)
[root@vbox wzh]# make
[root@vbox wzh]# insmod myslab.ko
[root@vbox wzh]# dmesg | tail -220
# 可以看到第一次申请内存时,系统一次分配很多内存用于缓存(构造函数执行了多次)
[root@vbox wzh]# cat /proc/slabinfo | grep test #查看我们建立的缓存名在不在系统中
testslab 0 0 16 202 1 : tunables 120 60 0 : slabdata 0 0 0
[root@vbox wzh]# rmmod myslab.ko #卸载内核模块
[root@vbox wzh]# cat /proc/slabinfo | grep test #我们的缓存名已经不在系统中了
3. 获取高端内存
高端内存就是之前提到的 ZONE_HIGHMEM 区的内存。
在x86体系结构中,这个区的内存不能映射到内核地址空间上,也就是没有逻辑地址,
为了使用 ZONE_HIGHMEM 区的内存,内核提供了永久映射和临时映射2种手段:
3.1 永久映射
永久映射的函数是可以睡眠的,所以只能用在进程上下文中。
/* 将 ZONE_HIGHMEM 区的一个page永久的映射到内核地址空间
* 返回值即为这个page对应的逻辑地址
*/
static inline void *kmap(struct page *page) /* 允许永久映射的数量是有限的,所以不需要高端内存时,应该及时的解除映射 */
static inline void kunmap(struct page *page)
3.2 临时映射
临时映射不会阻塞,也禁止了内核抢占,所以可以用在中断上下文和其他不能重新调度的地方。
/**
* 将 ZONE_HIGHMEM 区的一个page临时映射到内核地址空间
* 其中的 km_type 表示映射的目的,
* enum kn_type 的定义参见:<asm/kmap_types.h>
*/
static inline void *kmap_atomic(struct page *page, enum km_type idx) /* 相应的解除映射是个宏 */
#define kunmap_atomic(addr, idx) do { pagefault_enable(); } while (0)
以上的函数都在 <linux/highmem.h> 中定义的。
4. 内核内存的分配方式
内核的内存分配和用户空间的内存分配相比有着更多的限制条件,同时也有着更高的性能要求。
下面讨论2个和用户空间不同的内存分配方式。
4.1 内核栈上的静态分配
用户空间中一般不用担心栈上的内存不足,也不用担心内存的管理问题(比如内存越界之类的),即使出了异常也有内核来保证系统的正常运行。而在内核空间则完全不一样,不仅栈空间有限,而且为了管理的效率和尽量减少问题的发生,内核栈一般都是小而且固定的。在x86体系结构中,内核栈的大小一般就是1页或2页,即 4KB ~ 8KB内核栈可以在编译内核时通过配置选项将内核栈配置为1页,配置为1页的好处是分配时比较简单,只有一页,不存在内存碎片的情况,因为一页是本就是分配的最小单位。当有中断发生时,如果共享内核栈,中断程序和被中断程序共享一个内核栈会可能导致空间不足,于是,每个进程除了有个内核栈之外,还有一个中断栈,中断栈一般也就1页大小。
查看当前系统内核栈大小的方法:
[xxxxx@localhost ~]$ ulimit -a | grep 'stack'
stack size (kbytes, -s) 8192
4.2 按CPU分配
与单CPU环境不同,SMP环境下的并行是真正的并行。单CPU环境是宏观并行,微观串行。
真正并行时,会有更多的并发问题。
假定有如下场景:
void* p; if (p == NULL)
{
/* 对 P 进行相应的操作,最终 P 不是NULL了 */
}
else
{
/* P 不是NULL,继续对 P 进行相应的操作 */
}
在上述场景下,可能会有以下的执行流程:
- 刚开始 p == NULL
- 线程A 执行到 [if (p == NULL)] ,刚进入 if 内的代码时被线程B 抢占
由于线程A 还没有执行 if 内的代码,所以 p 仍然是 NULL - 线程B 抢占到CPU后开始执行,执行到 [if (p == NULL)]时, 发现 p 是 NULL,执行 if 内的代码
- 线程B 执行完后,线程A 重新被调度,继续执行 if 的代码
其实此时由于线程B 已经执行完,p 已经不是 NULL了,线程A 可能会破坏线程B 已经完成的处理,导致数据不一致
在单CPU环境下,上述情况无需加锁,只需在 if 处理之前禁止内核抢占,在 else 处理之后恢复内核抢占即可。
而在SMP环境下,上述情况必须加锁,因为禁止内核抢占只能禁止当前CPU的抢占,其他的CPU仍然调度线程B 来抢占线程A 的执行
SMP环境下加锁过多的话,会严重影响并行的效率,如果是自旋锁的话,还会浪费其他CPU的执行时间。
所以内核中才有了按CPU分配数据的接口。
按CPU分配数据之后,每个CPU自己的数据不会被其他CPU访问,虽然浪费了一点内存,但是会使系统更加的简洁高效。
4.2.1 按CPU分配的优势
按CPU来分配数据主要有2个优点:
- 最直接的效果就是减少了对数据的锁,提高了系统的性能
- 由于每个CPU有自己的数据,所以处理器切换时可以大大减少缓存失效的几率 (*注1)
注1:如果一个处理器操作某个数据,而这个数据在另一个处理器的缓存中时,那么存放这个数据的那个
处理器必须清理或刷新自己的缓存。持续的缓存失效成为缓存抖动,对系统性能影响很大。
4.2.2 编译时分配
可以在编译时就定义分配给每个CPU的变量,其分配的接口参见:<linux/percpu-defs.h>
/* 给每个CPU声明一个类型为 type,名称为 name 的变量 */
DECLARE_PER_CPU(type, name)
/* 给每个CPU定义一个类型为 type,名称为 name 的变量 */
DEFINE_PER_CPU(type, name)
注意上面两个宏,一个是声明,一个是定义。
其实也就是 DECLARE_PER_CPU 中多了个 extern 的关键字
分配好变量后,就可以在代码中使用这个变量 name 了。
DEFINE_PER_CPU(int, name); /* 为每个CPU定义一个 int 类型的name变量 */ get_cpu_var(name)++; /* 当前处理器上的name变量 +1 */
put_cpu_var(name); /* 完成对name的操作后,激活当前处理器的内核抢占 */
通过 get_cpu_var 和 put_cpu_var 的代码,我们可以发现其中有禁止和激活内核抢占的函数。
相关代码在 <linux/percpu.h> 中
#define get_cpu_var(var) (*({ \
extern int simple_identifier_##var(void); \
preempt_disable();/* 这句就是禁止当前处理器上的内核抢占 */ \
&__get_cpu_var(var); }))
#define put_cpu_var(var) preempt_enable() /* 这句就是激活当前处理器上的内核抢占 */
4.2.3 运行时分配
除了像上面那样静态的给每个CPU分配数据,还可以以指针的方式在运行时给每个CPU分配数据。
动态分配参见:<linux/percpu.h>
/* 给每个处理器分配一个 size 字节大小的对象,对象的偏移量是 align */
extern void *__alloc_percpu(size_t size, size_t align);
/* 释放所有处理器上已分配的变量 __pdata */
extern void free_percpu(void *__pdata); /* 还有一个宏,是按对象类型 type 来给每个CPU分配数据的,
* 其实本质上还是调用了 __alloc_percpu 函数 */
#define alloc_percpu(type) (type *)__alloc_percpu(sizeof(type), \
__alignof__(type))
动态分配的一个使用例子如下:
void *percpu_ptr;
unsigned long *foo; percpu_ptr = alloc_percpu(unsigned long);
if (!percpu_ptr)
/* 内存分配错误 */ foo = get_cpu_var(percpu_ptr);
/* 操作foo ... */
put_cpu_var(percpu_ptr);
5. 总结
在众多的内存分配函数中,如何选择合适的内存分配函数很重要,下面总结了一些选择的原则:
|
应用场景 |
分配函数选择 |
| 如果需要物理上连续的页 | 选择低级页分配器或者 kmalloc 函数 |
| 如果kmalloc分配是可以睡眠 | 指定 GFP_KERNEL 标志 |
| 如果kmalloc分配是不能睡眠 | 指定 GFP_ATOMIC 标志 |
| 如果不需要物理上连续的页 | vmalloc 函数 (vmalloc 的性能不如 kmalloc) |
| 如果需要高端内存 | alloc_pages 函数获取 page 的地址,在用 kmap 之类的函数进行映射 |
| 如果频繁撤销/创建教导的数据结构 | 建立slab高速缓存 |
虚拟文件系统
虚拟文件系统(VFS)是linux内核和具体I/O设备之间的封装的一层共通访问接口,通过这层接口,linux内核可以以同一的方式访问各种I/O设备。
虚拟文件系统本身是linux内核的一部分,是纯软件的东西,并不需要任何硬件的支持。
主要内容:
- 虚拟文件系统的作用
- 虚拟文件系统的4个主要对象
- 文件系统相关的数据结构
- 进程相关的数据结构
- 小结
1. 虚拟文件系统的作用
虚拟文件系统(VFS)是linux内核和存储设备之间的抽象层,主要有以下好处。
- 简化了应用程序的开发:应用通过统一的系统调用访问各种存储介质
- 简化了新文件系统加入内核的过程:新文件系统只要实现VFS的各个接口即可,不需要修改内核部分
2. 虚拟文件系统的4个主要对象
虚拟文件中的4个主要对象,具体每个对象的含义参见如下的详细介绍。
2.1 超级块
超级块(super_block)主要存储文件系统相关的信息,这是个针对文件系统级别的概念。
它一般存储在磁盘的特定扇区中,但是对于那些基于内存的文件系统(比如proc,sysfs),超级块是在使用时创建在内存中的。
超级块的定义在:<linux/fs.h>
/*
* 超级块结构中定义的字段非常多,
* 这里只介绍一些重要的属性
*/
struct super_block {
struct list_head s_list; /* 指向所有超级块的链表 */
const struct super_operations *s_op; /* 超级块方法 */
struct dentry *s_root; /* 目录挂载点 */
struct mutex s_lock; /* 超级块信号量 */
int s_count; /* 超级块引用计数 */ struct list_head s_inodes; /* inode链表 */
struct mtd_info *s_mtd; /* 存储磁盘信息 */
fmode_t s_mode; /* 安装权限 */
}; /*
* 其中的 s_op 中定义了超级块的操作方法
* 这里只介绍一些相对重要的函数
*/
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb); /* 创建和初始化一个索引节点对象 */
void (*destroy_inode)(struct inode *); /* 释放给定的索引节点 */ void (*dirty_inode) (struct inode *); /* VFS在索引节点被修改时会调用这个函数 */
int (*write_inode) (struct inode *, int); /* 将索引节点写入磁盘,wait表示写操作是否需要同步 */
void (*drop_inode) (struct inode *); /* 最后一个指向索引节点的引用被删除后,VFS会调用这个函数 */
void (*delete_inode) (struct inode *); /* 从磁盘上删除指定的索引节点 */
void (*put_super) (struct super_block *); /* 卸载文件系统时由VFS调用,用来释放超级块 */
void (*write_super) (struct super_block *); /* 用给定的超级块更新磁盘上的超级块 */
int (*sync_fs)(struct super_block *sb, int wait); /* 使文件系统中的数据与磁盘上的数据同步 */
int (*statfs) (struct dentry *, struct kstatfs *); /* VFS调用该函数获取文件系统状态 */
int (*remount_fs) (struct super_block *, int *, char *); /* 指定新的安装选项重新安装文件系统时,VFS会调用该函数 */
void (*clear_inode) (struct inode *); /* VFS调用该函数释放索引节点,并清空包含相关数据的所有页面 */
void (*umount_begin) (struct super_block *); /* VFS调用该函数中断安装操作 */
};
2.2 索引节点
索引节点是VFS中的核心概念,它包含内核在操作文件或目录时需要的全部信息。一个索引节点代表文件系统中的一个文件(这里的文件不仅是指我们平时所认为的普通的文件,还包括目录,特殊设备文件等等)。索引节点和超级块一样是实际存储在磁盘上的,当被应用程序访问到时才会在内存中创建。
索引节点定义在:<linux/fs.h>
/*
* 索引节点结构中定义的字段非常多,
* 这里只介绍一些重要的属性
*/
struct inode {
struct hlist_node i_hash; /* 散列表,用于快速查找inode */
struct list_head i_list; /* 索引节点链表 */
struct list_head i_sb_list; /* 超级块链表超级块 */
struct list_head i_dentry; /* 目录项链表 */
unsigned long i_ino; /* 节点号 */
atomic_t i_count; /* 引用计数 */
unsigned int i_nlink; /* 硬链接数 */
uid_t i_uid; /* 使用者id */
gid_t i_gid; /* 使用组id */
struct timespec i_atime; /* 最后访问时间 */
struct timespec i_mtime; /* 最后修改时间 */
struct timespec i_ctime; /* 最后改变时间 */
const struct inode_operations *i_op; /* 索引节点操作函数 */
const struct file_operations *i_fop; /* 缺省的索引节点操作 */
struct super_block *i_sb; /* 相关的超级块 */
struct address_space *i_mapping; /* 相关的地址映射 */
struct address_space i_data; /* 设备地址映射 */
unsigned int i_flags; /* 文件系统标志 */
void *i_private; /* fs 私有指针 */
}; /*
* 其中的 i_op 中定义了索引节点的操作方法
* 这里只介绍一些相对重要的函数
*/
struct inode_operations {
/* 为dentry对象创造一个新的索引节点 */
int (*create) (struct inode *,struct dentry *,int, struct nameidata *);
/* 在特定文件夹中寻找索引节点,该索引节点要对应于dentry中给出的文件名 */
struct dentry * (*lookup) (struct inode *,struct dentry *, struct nameidata *);
/* 创建硬链接 */
int (*link) (struct dentry *,struct inode *,struct dentry *);
/* 从一个符号链接查找它指向的索引节点 */
void * (*follow_link) (struct dentry *, struct nameidata *);
/* 在 follow_link调用之后,该函数由VFS调用进行清除工作 */
void (*put_link) (struct dentry *, struct nameidata *, void *);
/* 该函数由VFS调用,用于修改文件的大小 */
void (*truncate) (struct inode *);
};
2.3 目录项
和超级块和索引节点不同,目录项并不是实际存在于磁盘上的。
在使用的时候在内存中创建目录项对象,其实通过索引节点已经可以定位到指定的文件,
但是索引节点对象的属性非常多,在查找,比较文件时,直接用索引节点效率不高,所以引入了目录项的概念。
路径中的每个部分都是一个目录项,比如路径: /mnt/cdrom/foo/bar 其中包含5个目录项,/ mnt cdrom foo bar
每个目录项对象都有3种状态:被使用,未使用和负状态
- 被使用:对应一个有效的索引节点,并且该对象由一个或多个使用者
- 未使用:对应一个有效的索引节点,但是VFS当前并没有使用这个目录项
- 负状态:没有对应的有效索引节点(可能索引节点被删除或者路径不存在了)
目录项的目的就是提高文件查找,比较的效率,所以访问过的目录项都会缓存在slab中。
slab中缓存的名称一般就是 dentry,可以通过如下命令查看:
[wuzhihang@localhost kernel]$ sudo cat /proc/slabinfo | grep dentry
dentry 212545 212625 192 21 1 : tunables 0 0 0 : slabdata 10125 10125 0
目录项定义在:<linux/dcache.h>
/* 目录项对象结构 */
struct dentry {
atomic_t d_count; /* 使用计数 */
unsigned int d_flags; /* 目录项标识 */
spinlock_t d_lock; /* 单目录项锁 */
int d_mounted; /* 是否登录点的目录项 */
struct inode *d_inode; /* 相关联的索引节点 */
struct hlist_node d_hash; /* 散列表 */
struct dentry *d_parent; /* 父目录的目录项对象 */
struct qstr d_name; /* 目录项名称 */
struct list_head d_lru; /* 未使用的链表 */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* 子目录链表 */
struct list_head d_alias; /* 索引节点别名链表 */
unsigned long d_time; /* 重置时间 */
const struct dentry_operations *d_op; /* 目录项操作相关函数 */
struct super_block *d_sb; /* 文件的超级块 */
void *d_fsdata; /* 文件系统特有数据 */ unsigned char d_iname[DNAME_INLINE_LEN_MIN]; /* 短文件名 */
}; /* 目录项相关操作函数 */
struct dentry_operations {
/* 该函数判断目录项对象是否有效。VFS准备从dcache中使用一个目录项时会调用这个函数 */
int (*d_revalidate)(struct dentry *, struct nameidata *);
/* 为目录项对象生成hash值 */
int (*d_hash) (struct dentry *, struct qstr *);
/* 比较 qstr 类型的2个文件名 */
int (*d_compare) (struct dentry *, struct qstr *, struct qstr *);
/* 当目录项对象的 d_count 为0时,VFS调用这个函数 */
int (*d_delete)(struct dentry *);
/* 当目录项对象将要被释放时,VFS调用该函数 */
void (*d_release)(struct dentry *);
/* 当目录项对象丢失其索引节点时(也就是磁盘索引节点被删除了),VFS会调用该函数 */
void (*d_iput)(struct dentry *, struct inode *);
char *(*d_dname)(struct dentry *, char *, int);
};
2.4 文件对象
文件对象表示进程已打开的文件,从用户角度来看,我们在代码中操作的就是一个文件对象。
文件对象反过来指向一个目录项对象(目录项反过来指向一个索引节点)
其实只有目录项对象才表示一个已打开的实际文件,虽然一个文件对应的文件对象不是唯一的,但其对应的索引节点和目录项对象却是唯一的。
文件对象的定义在: <linux/fs.h>
/*
* 文件对象结构中定义的字段非常多,
* 这里只介绍一些重要的属性
*/
struct file {
union {
struct list_head fu_list; /* 文件对象链表 */
struct rcu_head fu_rcuhead; /* 释放之后的RCU链表 */
} f_u;
struct path f_path; /* 包含的目录项 */
const struct file_operations *f_op; /* 文件操作函数 */
atomic_long_t f_count; /* 文件对象引用计数 */
}; /*
* 其中的 f_op 中定义了文件对象的操作方法
* 这里只介绍一些相对重要的函数
*/
struct file_operations {
/* 用于更新偏移量指针,由系统调用lleek()调用它 */
loff_t (*llseek) (struct file *, loff_t, int);
/* 由系统调用read()调用它 */
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
/* 由系统调用write()调用它 */
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
/* 由系统调用 aio_read() 调用它 */
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
/* 由系统调用 aio_write() 调用它 */
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
/* 将给定文件映射到指定的地址空间上,由系统调用 mmap 调用它 */
int (*mmap) (struct file *, struct vm_area_struct *);
/* 创建一个新的文件对象,并将它和相应的索引节点对象关联起来 */
int (*open) (struct inode *, struct file *);
/* 当已打开文件的引用计数减少时,VFS调用该函数 */
int (*flush) (struct file *, fl_owner_t id);
};
2.5 四个对象之间关系图
上面分别介绍了4种对象分别的属性和方法,下面用图来展示这4个对象的和VFS之间关系以及4个对象之间的关系。(这个图是根据我自己的理解画出来的,如果由错误请帮忙指出,谢谢!)


3. 文件系统相关的数据结构
处理上面4个主要的对象之外,VFS中还有2个专门针对文件系统的2个对象,
- struct file_system_type: 用来描述文件系统的类型(比如ext3,ntfs等等)
- struct vfsmount : 描述一个安装文件系统的实例
file_system_type 结构体位于:<linux/fs.h>
struct file_system_type {
const char *name; /* 文件系统名称 */
int fs_flags; /* 文件系统类型标志 */
/* 从磁盘中读取超级块,并且在文件系统被安装时,在内存中组装超级块对象 */
int (*get_sb) (struct file_system_type *, int,
const char *, void *, struct vfsmount *);
/* 终止访问超级块 */
void (*kill_sb) (struct super_block *);
struct module *owner; /* 文件系统模块 */
struct file_system_type * next; /* 链表中下一个文件系统类型 */
struct list_head fs_supers; /* 超级块对象链表 */
/* 下面都是运行时的锁 */
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
struct lock_class_key i_alloc_sem_key;
};
每种文件系统,不管由多少个实例安装到系统中,还是根本没有安装到系统中,都只有一个 file_system_type 结构。
当文件系统被实际安装时,会在安装点创建一个 vfsmount 结构体。
结构体代表文件系统的实例,也就是文件系统被安装几次,就会创建几个 vfsmount
vfsmount 的定义参见:<linux/mount.h>
struct vfsmount {
struct list_head mnt_hash; /* 散列表 */
struct vfsmount *mnt_parent; /* 父文件系统,也就是要挂载到哪个文件系统 */
struct dentry *mnt_mountpoint; /* 安装点的目录项 */
struct dentry *mnt_root; /* 该文件系统的根目录项 */
struct super_block *mnt_sb; /* 该文件系统的超级块 */
struct list_head mnt_mounts; /* 子文件系统链表 */
struct list_head mnt_child; /* 子文件系统链表 */
int mnt_flags; /* 安装标志 */
/* 4 bytes hole on 64bits arches */
const char *mnt_devname; /* 设备文件名 e.g. /dev/dsk/hda1 */
struct list_head mnt_list; /* 描述符链表 */
struct list_head mnt_expire; /* 到期链表的入口 */
struct list_head mnt_share; /* 共享安装链表的入口 */
struct list_head mnt_slave_list;/* 从安装链表 */
struct list_head mnt_slave; /* 从安装链表的入口 */
struct vfsmount *mnt_master; /* 从安装链表的主人 */
struct mnt_namespace *mnt_ns; /* 相关的命名空间 */
int mnt_id; /* 安装标识符 */
int mnt_group_id; /* 组标识符 */
/*
* We put mnt_count & mnt_expiry_mark at the end of struct vfsmount
* to let these frequently modified fields in a separate cache line
* (so that reads of mnt_flags wont ping-pong on SMP machines)
*/
atomic_t mnt_count; /* 使用计数 */
int mnt_expiry_mark; /* 如果标记为到期,则为 True */
int mnt_pinned; /* "钉住"进程计数 */
int mnt_ghosts; /* "镜像"引用计数 */
#ifdef CONFIG_SMP
int *mnt_writers; /* 写者引用计数 */
#else
int mnt_writers; /* 写者引用计数 */
#endif
};
4. 进程相关的数据结构
以上介绍的都是在内核角度看到的 VFS 各个结构,所以结构体中包含的属性非常多。
而从进程的角度来看的话,大多数时候并不需要那么多的属性,所有VFS通过以下3个结构体和进程紧密联系在一起。
- struct files_struct :由进程描述符中的 files 目录项指向,所有与单个进程相关的信息(比如打开的文件和文件描述符)都包含在其中。
- struct fs_struct :由进程描述符中的 fs 域指向,包含文件系统和进程相关的信息。
- struct mmt_namespace :由进程描述符中的 mmt_namespace 域指向。
struct files_struct 位于:<linux/fdtable.h>
struct files_struct {
atomic_t count; /* 使用计数 */
struct fdtable *fdt; /* 指向其他fd表的指针 */
struct fdtable fdtab;/* 基 fd 表 */
spinlock_t file_lock ____cacheline_aligned_in_smp; /* 单个文件的锁 */
int next_fd; /* 缓存下一个可用的fd */
struct embedded_fd_set close_on_exec_init; /* exec()时关闭的文件描述符链表 */
struct embedded_fd_set open_fds_init; /* 打开的文件描述符链表 */
struct file * fd_array[NR_OPEN_DEFAULT]; /* 缺省的文件对象数组 */
};
struct fs_struct 位于:<linux/fs_struct.h>
struct fs_struct {
int users; /* 用户数目 */
rwlock_t lock; /* 保护结构体的读写锁 */
int umask; /* 掩码 */
int in_exec; /* 当前正在执行的文件 */
struct path root, pwd; /* 根目录路径和当前工作目录路径 */
};
struct mmt_namespace 位于:<linux/mmt_namespace.h>
但是在2.6内核之后似乎没有这个结构体了,而是用 struct nsproxy 来代替。
以下是 struct task_struct 结构体中关于文件系统的3个属性。
struct task_struct 的定义位于:<linux/sched.h>
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespaces */
struct nsproxy *nsproxy;
5. 小结
VFS 统一了文件系统的实现框架,使得在linux上实现新文件系统的工作变得简单。
目前linux内核中已经支持60多种文件系统,具体支持的文件系统可以查看 内核源码 fs 文件夹下的内容。
块I/O层
主要内容:
- 块设备简介
- 内核访问块设备的方法
- 内核I/O调度程序
1. 块设备简介
I/O设备主要有2类:
- 字符设备:只能顺序读写设备中的内容,比如 串口设备,键盘
- 块设备:能够随机读写设备中的内容,比如 硬盘,U盘
字符设备由于只能顺序访问,所以应用场景也不多,这篇文章主要讨论块设备。
块设备是随机访问的,所以块设备在不同的应用场景中存在很大的优化空间。
块设备中最重要的一个概念就是块设备的最小寻址单元。
块设备的最小寻址单元就是扇区,扇区的大小是2的整数倍,一般是 512字节。
扇区是物理上的最小寻址单元,而逻辑上的最小寻址单元是块。
为了便于文件系统管理,块的大小一般是扇区的整数倍,并且小于等于页的大小。
查看扇区和I/O块的方法:
[wuzhihang@localhost]$ sudo fdisk -l WARNING: GPT (GUID Partition Table) detected on '/dev/sda'! The util fdisk doesn't support GPT. Use GNU Parted. Disk /dev/sda: 500.1 GB, 500107862016 bytes, 976773168 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 4096 bytes / 4096 bytes
Disk identifier: 0x00000000
上面的 Sector size 就是扇区的值,I/O size就是 块的值
从上面显示的结果,我们发现有个奇怪的地方,扇区的大小有2个值,逻辑大小是 512字节,而物理大小却是 4096字节。
其实逻辑大小 512字节是为了兼容以前的软件应用,而实际物理大小 4096字节是由于硬盘空间越来越大导致的。
具体的来龙去脉请参考:4KB扇区的原因
2. 内核访问块设备的方法
内核通过文件系统访问块设备时,需要先把块读入到内存中。所以文件系统为了管理块设备,必须管理[块]和内存页之间的映射。
内核中有2种方法来管理 [块] 和内存页之间的映射。
- 缓冲区和缓冲区头
- bio
2.1 缓冲区和缓冲区头
每个 [块] 都是一个缓冲区,同时对每个 [块] 都定义一个缓冲区头来描述它。
由于 [块] 的大小是小于内存页的大小的,所以每个内存页会包含一个或者多个 [块]
缓冲区头定义在 <linux/buffer_head.h>: include/linux/buffer_head.h
struct buffer_head {
unsigned long b_state; /* 表示缓冲区状态 */
struct buffer_head *b_this_page;/* 当前页中缓冲区 */
struct page *b_page; /* 当前缓冲区所在内存页 */
sector_t b_blocknr; /* 起始块号 */
size_t b_size; /* buffer在内存中的大小 */
char *b_data; /* 块映射在内存页中的数据 */
struct block_device *b_bdev; /* 关联的块设备 */
bh_end_io_t *b_end_io; /* I/O完成方法 */
void *b_private; /* 保留的 I/O 完成方法 */
struct list_head b_assoc_buffers; /* 关联的其他缓冲区 */
struct address_space *b_assoc_map; /* 相关的地址空间 */
atomic_t b_count; /* 引用计数 */
};
整个 buffer_head 结构体中的字段是减少过的,以前的内核中字段更多。
各个字段的含义通过注释都很明了,只有 b_state 字段比较复杂,它涵盖了缓冲区可能的各种状态。
enum bh_state_bits {
BH_Uptodate, /* 包含可用数据 */
BH_Dirty, /* 该缓冲区是脏的(说明缓冲的内容比磁盘中的内容新,需要回写磁盘) */
BH_Lock, /* 该缓冲区正在被I/O使用,锁住以防止并发访问 */
BH_Req, /* 该缓冲区有I/O请求操作 */
BH_Uptodate_Lock,/* 由内存页中的第一个缓冲区使用,使得该页中的其他缓冲区 */
BH_Mapped, /* 该缓冲区是映射到磁盘块的可用缓冲区 */
BH_New, /* 缓冲区是通过 get_block() 刚刚映射的,尚且不能访问 */
BH_Async_Read, /* 该缓冲区正通过 end_buffer_async_read() 被异步I/O读操作使用 */
BH_Async_Write, /* 该缓冲区正通过 end_buffer_async_read() 被异步I/O写操作使用 */
BH_Delay, /* 缓冲区还未和磁盘关联 */
BH_Boundary, /* 该缓冲区处于连续块区的边界,下一个块不在连续 */
BH_Write_EIO, /* 该缓冲区在写的时候遇到 I/O 错误 */
BH_Ordered, /* 顺序写 */
BH_Eopnotsupp, /* 该缓冲区发生 “不被支持” 错误 */
BH_Unwritten, /* 该缓冲区在磁盘上的位置已经被申请,但还有实际写入数据 */
BH_Quiet, /* 该缓冲区禁止错误 */
BH_PrivateStart,/* 不是表示状态,分配给其他实体的私有数据区的第一个bit */
};
在2.6之前的内核中,主要就是通过缓冲区头来管理 [块] 和内存之间的映射的。
用缓冲区头来管理内核的 I/O 操作主要存在以下2个弊端,所以在2.6开始的内核中,缓冲区头的作用大大降低了。
- 弊端 1
对内核而言,操作内存页是最为简便和高效的,所以如果通过缓冲区头来操作的话(缓冲区 即[块]在内存中映射,可能比页面要小),效率低下。
而且每个 [块] 对应一个缓冲区头的话,导致内存的利用率降低(缓冲区头包含的字段非常多)
- 弊端 2
每个缓冲区头只能表示一个 [块],所以内核在处理大数据时,会分解为对一个个小的 [块] 的操作,造成不必要的负担和空间浪费。
2.2 bio
bio结构体的出现就是为了改善上面缓冲区头的2个弊端,它表示了一次 I/O 操作所涉及到的所有内存页。
/*
* I/O 操作的主要单元,针对 I/O块和更低级的层 (ie drivers and
* stacking drivers)
*/
struct bio {
sector_t bi_sector; /* 磁盘上相关扇区 */
struct bio *bi_next; /* 请求列表 */
struct block_device *bi_bdev; /* 相关的块设备 */
unsigned long bi_flags; /* 状态和命令标志 */
unsigned long bi_rw; /* 读还是写 */ unsigned short bi_vcnt; /* bio_vecs的数目 */
unsigned short bi_idx; /* bio_io_vect的当前索引 */ /* Number of segments in this BIO after
* physical address coalescing is performed.
* 结合后的片段数目
*/
unsigned int bi_phys_segments; unsigned int bi_size; /* 剩余 I/O 计数 */ /*
* To keep track of the max segment size, we account for the
* sizes of the first and last mergeable segments in this bio.
* 第一个和最后一个可合并的段的大小
*/
unsigned int bi_seg_front_size;
unsigned int bi_seg_back_size; unsigned int bi_max_vecs; /* bio_vecs数目上限 */
unsigned int bi_comp_cpu; /* 结束CPU */ atomic_t bi_cnt; /* 使用计数 */
struct bio_vec *bi_io_vec; /* bio_vec 链表 */
bio_end_io_t *bi_end_io; /* I/O 完成方法 */
void *bi_private; /* bio结构体创建者的私有方法 */
#if defined(CONFIG_BLK_DEV_INTEGRITY)
struct bio_integrity_payload *bi_integrity; /* data integrity */
#endif
bio_destructor_t *bi_destructor; /* bio撤销方法 */
/*
* We can inline a number of vecs at the end of the bio, to avoid
* double allocations for a small number of bio_vecs. This member
* MUST obviously be kept at the very end of the bio.
* 内嵌在结构体末尾的 bio 向量,主要为了防止出现二次申请少量的 bio_vecs
*/
struct bio_vec bi_inline_vecs[0];
};
几个重要字段说明:
- bio 结构体表示正在执行的 I/O 操作相关的信息。
- bio_io_vec 链表表示当前 I/O 操作涉及到的内存页
- bio_vec 结构体表示 I/O 操作使用的片段
- bi_vcnt bi_io_vec链表中bi_vec的个数
- bi_idx 当前的 bi_vec片段,通过 bi_vcnt(总数)和 bi_idx(当前数),就可以跟踪当前 I/O 操作的进度
bio_vec 结构体很简单,定义如下:
struct bio_vec {
struct page *bv_page; /* 对应的物理页 */
unsigned int bv_len; /* 缓冲区大小 */
unsigned int bv_offset; /* 缓冲区开始的位置 */
};
每个 bio_vec 都是对应一个页面,从而保证内核能够方便高效的完成 I/O 操作

2.3 2种方法的对比
缓冲区头和bio并不是相互矛盾的,bio只是缓冲区头的一种改善,将以前缓冲区头完成的一部分工作移到bio中来完成。
bio中对应的是内存中的一个个页,而缓冲区头对应的是磁盘中的一个块。
对内核来说,配合使用bio和缓冲区头 比 只使用缓冲区头更加的方便高效。
bio相当于在缓冲区上又封装了一层,使得内核在 I/O操作时只要针对一个或多个内存页即可,不用再去管理磁盘块的部分。
使用bio结构体还有以下好处:
- bio结构体很容易处理高端内存,因为它处理的是内存页而不是直接指针
- bio结构体既可以代表普通页I/O,也可以代表直接I/O
- bio结构体便于执行分散-集中(矢量化的)块I/O操作,操作中的数据可以取自多个物理页面
3. 内核I/O调度程序
缓冲区头和bio都是内核处理一个具体I/O操作时涉及的概念。但是内核除了要完成I/O操作以外,还要调度好所有I/O操作请求,尽量确保每个请求能有个合理的响应时间。
下面就是目前内核中已有的一些 I/O 调度算法。
3.1 linus电梯
为了保证磁盘寻址的效率,一般会尽量让磁头向一个方向移动,等到头了再反过来移动,这样可以缩短所有请求的磁盘寻址总时间。
磁头的移动有点类似于电梯,所有这个 I/O 调度算法也叫电梯调度。
linux中的第一个电梯调度算法就是 linus本人所写的,所有也叫做 linus 电梯。
linus电梯调度主要是对I/O请求进行合并和排序。
当一个新请求加入I/O请求队列时,可能会发生以下4种操作:
- 如果队列中已存在一个对相邻磁盘扇区操作的请求,那么新请求将和这个已存在的请求合并成一个请求
- 如果队列中存在一个驻留时间过长的请求,那么新请求之间查到队列尾部,防止旧的请求发生饥饿
- 如果队列中已扇区方向为序存在合适的插入位置,那么新请求将被插入该位置,保证队列中的请求是以被访问磁盘物理位置为序进行排列的
- 如果队列中不存在合适的请求插入位置,请求将被插入到队列尾部
linus电梯调度程序在2.6版的内核中被其他调度程序所取代了。
3.2 最终期限I/O调度
linus电梯调度主要考虑了系统的全局吞吐量,对于个别的I/O请求,还是有可能造成饥饿现象。而且读写请求的响应时间要求也是不一样的,一般来说,写请求的响应时间要求不高,写请求可以和提交它的应用程序异步执行,但是读请求一般和提交它的应用程序时同步执行,应用程序等获取到读的数据后才会接着往下执行。因此在 linus 电梯调度程序中,还可能造成 写-饥饿-读(wirtes-starving-reads)这种特殊问题。为了尽量公平的对待所有请求,同时尽量保证读请求的响应时间,提出了最终期限I/O调度算法。最终期限I/O调度 算法给每个请求设置了超时时间,默认情况下,读请求的超时时间500ms,写请求的超时时间是5s但一个新请求加入到I/O请求队列时,最终期限I/O调度和linus电梯调度相比,多出了以下操作:
- 新请求加入到 排序队列(order-FIFO),加入的方法类似 linus电梯新请求加入的方法
- 根据新请求的类型,将其加入 读队列(read-FIFO) 或者写队列(wirte-FIFO) 的尾部(读写队列是按加入时间排序的,所以新请求都是加到尾部)
- 调度程序首先判断 读,写队列头的请求是否超时,如果超时,从读,写队列头取出请求,加入到派发队列(dispatch-FIFO)
- 如果没有超时请求,从 排序队列(order-FIFO)头取出一个请求加入到 派发队列(dispatch-FIFO)
- 派发队列(dispatch-FIFO)按顺序将请求提交到磁盘驱动,完成I/O操作
最终期限I/O调度 算法也不能严格保证响应时间,但是它可以保证不会发生请求在明显超时的情况下仍得不到执行。最终期限I/O调度 的实现参见: block/deadline-iosched.c
3.3 预测I/O调度
最终期限I/O调度算法优先考虑读请求的响应时间,但系统处于写操作繁重的状态时,会大大降低系统的吞吐量。因为读请求的超时时间比较短,所以每次有读请求时,都会打断写请求,让磁盘寻址到读的位置,完成读操作后再回来继续写。这种做法保证读请求的响应速度,却损害了系统的全局吞吐量(磁头先去读再回来写,发生了2次寻址操作)预测I/O调度算法是为了解决上述问题而提出的,它是基于最终期限I/O调度算法的。但有一个新请求加入到I/O请求队列时,预测I/O调度与最终期限I/O调度相比,多了以下操作:
- 新的读请求提交后,并不立即进行请求处理,而是有意等待片刻(默认是6ms)
- 等待期间如果有其他对磁盘相邻位置进行读操作的读请求加入,会立刻处理这些读请求
- 等待期间如果没有其他读请求加入,那么等待时间相当于浪费掉
- 等待时间结束后,继续执行以前剩下的请求
预测I/O调度算法中最重要的是保证等待期间不要浪费,也就是提高预测的准确性,
目前这种预测是依靠一系列的启发和统计工作,预测I/O调度程序会跟踪并统计每个应用程序的I/O操作习惯,以便正确预测应用程序的读写行为。
如果预测的准确率足够高,那么预测I/O调度和最终期限I/O调度相比,既能提高读请求的响应时间,又能提高系统吞吐量。
预测I/O调度的实现参见: block/as-iosched.c
注:预测I/O调度是linux内核中缺省的调度程序。
3.4 完全公正的排队I/O调度
完全公正的排队(Complete Fair Queuing, CFQ)I/O调度 是为专有工作负荷设计的,它和之前提到的I/O调度有根本的不同。
CFQ I/O调度 算法中,每个进程都有自己的I/O队列,
CFQ I/O调度程序以时间片轮转调度队列,从每个队列中选取一定的请求数(默认4个),然后进行下一轮调度。
CFQ I/O调度在进程级提供了公平,它的实现位于: block/cfq-iosched.c
3.5 空操作的I/O调度
空操作(noop)I/O调度几乎不做什么事情,这也是它这样命名的原因。
空操作I/O调度只做一件事情,当有新的请求到来时,把它与任一相邻的请求合并。
空操作I/O调度主要用于闪存卡之类的块设备,这类设备没有磁头,没有寻址的负担。
空操作I/O调度的实现位于: block/noop-iosched.c
3.6 I/O调度程序的选择
2.6内核中内置了上面4种I/O调度,可以在启动时通过命令行选项 elevator=xxx 来启用任何一种。
elevator选项参数如下:
|
参数 |
I/O调度程序 |
| as | 预测 |
| cfq | 完全公正排队 |
| deadline | 最终期限 |
| noop | 空操作 |
如果启动预测I/O调度,启动的命令行参数中加上 elevator=as
进程地址空间(kernel 2.6.32.60)
进程地址空间也就是每个进程所使用的内存,内核对进程地址空间的管理,也就是对用户态程序的内存管理。
主要内容:
- 地址空间(mm_struct)
- 虚拟内存区域(VMA)
- 地址空间和页表
1. 地址空间(mm_struct)
地址空间就是每个进程所能访问的内存地址范围。
这个地址范围不是真实的,是虚拟地址的范围,有时甚至会超过实际物理内存的大小。
现代的操作系统中进程都是在保护模式下运行的,地址空间其实是操作系统给进程用的一段连续的虚拟内存空间。
地址空间最终会通过页表映射到物理内存上,因为内核操作的是物理内存。
虽然地址空间的范围很大,但是进程也不一定有权限访问全部的地址空间(一般都是只能访问地址空间中的一些地址区间),
进程能够访问的那些地址区间也称为 内存区域。
进程如果访问了有效内存区域以外的内容就会报 “段错误” 信息。
内存区域中主要包含以下信息:
- - 代码段(text section),即可执行文件代码的内存映射
- - 数据段(data section),即可执行文件的已初始化全局变量的内存映射
- - bss段的零页(页面信息全是0值),即未初始化全局变量的内存映射
- - 进程用户空间栈的零页内存映射
- - 进程使用的C库或者动态链接库等共享库的代码段,数据段和bss段的内存映射
- - 任何内存映射文件
- - 任何共享内存段
- - 任何匿名内存映射,比如由 malloc() 分配的内存
注:bss是 block started by symbol 的缩写。
linux中内存相关的概念稍微整理了一下,供参考:
|
英文 |
含义 |
| SIZE | 进程映射的内存大小,这不是进程实际使用的内存大小 |
| RSS(Resident set size) | 实际驻留在“内存”中的内存大小,不包含已经交换出去的内存 |
| SHARE | RSS中与其他进程共享的内存大小 |
| VMSIZE | 进程占用的总地址空间,包含没有映射到内存中的页 |
| Private RSS | 仅由进程单独占用的RSS,也就是进程实际占用的内存 |
1.1 mm_struct介绍
linux中的地址空间是用 mm_struct 来表示的。
下面对其中一些关键的属性进行了注释,有些属性我也不是很了解......
struct mm_struct {
struct vm_area_struct * mmap; /* [内存区域]链表 */
struct rb_root mm_rb; /* [内存区域]红黑树 */
struct vm_area_struct * mmap_cache; /* 最近一次访问的[内存区域] */
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags); /* 获取指定区间内一个还未映射的地址,出错时返回错误码 */
void (*unmap_area) (struct mm_struct *mm, unsigned long addr); /* 取消地址 addr 的映射 */
unsigned long mmap_base; /* 地址空间中可以用来映射的首地址 */
unsigned long task_size; /* 进程的虚拟地址空间大小 */
unsigned long cached_hole_size; /* 如果不空的话,就是 free_area_cache 后最大的空洞 */
unsigned long free_area_cache; /* 地址空间的第一个空洞 */
pgd_t * pgd; /* 页全局目录 */
atomic_t mm_users; /* 使用地址空间的用户数 */
atomic_t mm_count; /* 实际使用地址空间的计数, (users count as 1) */
int map_count; /* [内存区域]个数 */
struct rw_semaphore mmap_sem; /* 内存区域信号量 */
spinlock_t page_table_lock; /* 页表锁 */
struct list_head mmlist; /* 所有地址空间形成的链表 */
/* Special counters, in some configurations protected by the
* page_table_lock, in other configurations by being atomic.
*/
mm_counter_t _file_rss;
mm_counter_t _anon_rss;
unsigned long hiwater_rss; /* High-watermark of RSS usage */
unsigned long hiwater_vm; /* High-water virtual memory usage */
unsigned long total_vm, locked_vm, shared_vm, exec_vm;
unsigned long stack_vm, reserved_vm, def_flags, nr_ptes;
unsigned long start_code, end_code, start_data, end_data; /* 代码段,数据段的开始和结束地址 */
unsigned long start_brk, brk, start_stack; /* 堆的首地址,尾地址,进程栈首地址 */
unsigned long arg_start, arg_end, env_start, env_end; /* 命令行参数,环境变量首地址,尾地址 */
unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */
struct linux_binfmt *binfmt;
cpumask_t cpu_vm_mask;
/* Architecture-specific MM context */
mm_context_t context;
/* Swap token stuff */
/*
* Last value of global fault stamp as seen by this process.
* In other words, this value gives an indication of how long
* it has been since this task got the token.
* Look at mm/thrash.c
*/
unsigned int faultstamp;
unsigned int token_priority;
unsigned int last_interval;
unsigned long flags; /* Must use atomic bitops to access the bits */
struct core_state *core_state; /* coredumping support */
#ifdef CONFIG_AIO
spinlock_t ioctx_lock;
struct hlist_head ioctx_list;
#endif
#ifdef CONFIG_MM_OWNER
/*
* "owner" points to a task that is regarded as the canonical
* user/owner of this mm. All of the following must be true in
* order for it to be changed:
*
* current == mm->owner
* current->mm != mm
* new_owner->mm == mm
* new_owner->alloc_lock is held
*/
struct task_struct *owner;
#endif
#ifdef CONFIG_PROC_FS
/* store ref to file /proc/<pid>/exe symlink points to */
struct file *exe_file;
unsigned long num_exe_file_vmas;
#endif
#ifdef CONFIG_MMU_NOTIFIER
struct mmu_notifier_mm *mmu_notifier_mm;
#endif
};
补充说明1: 上面的属性中,mm_users 和 mm_count 很容易混淆,这里特别说明一下:(下面的内容有网上查找的,也有我自己理解的)
mm_users 比较好理解,就是 mm_struct 被用户空间进程(线程)引用的次数。
如果进程A中创建了3个新线程,那么 进程A(这时候叫线程A也可以)对应的 mm_struct 中的 mm_users = 4
补充一点,linux中进程和线程几乎没有什么区别,就是看它是否共享进程地址空间,共享进程地址空间就是线程,反之就是进程。
所以,如果子进程和父进程共享了进程地址空间,那么父子进程都可以看做线程。如果父子进程没有共享进程地址空间,就是2个进程
mm_count 则稍微有点绕人,其实它记录就是 mm_struct 实际的引用计数。
简单点说,当 mm_users=0 时,并不一定能释放此 mm_struct,只有当 mm_count=0 时,才可以确定释放此 mm_struct
从上面的解释可以看出,可能引用 mm_struct 的并不只是用户空间的进程(线程)
当 mm_users>0 时, mm_count 会增加1, 表示有用户空间进程(线程)在使用 mm_struct。不管使用 mm_struct 的用户进程(线程)有几个, mm_count 都只是增加1。
也就是说,如果只有1个进程使用 mm_struct,那么 mm_users=1,mm_count也是 1。
如果有9个线程在使用 mm_struct,那么 mm_users=9,而 mm_count 仍然为 1。
那么 mm_count 什么情况下会大于 1呢?
当有内核线程使用 mm_struct 时,mm_count 才会再增加 1。
内核线程为何会使用用户空间的 mm_struct 是有其他原因的,这个后面再阐述。这里先知道内核线程使用 mm_struct 时也会导致 mm_count 增加 1。
在下面这种情况下,mm_count 就很有必要了:
- - 进程A启动,并申请了一个 mm_struct,此时 mm_users=1, mm_count=1
- - 进程A中新建了2个线程,此时 mm_users=3, mm_count=1
- - 内核调度发生,进程A及相关线程都被挂起,一个内核线程B 使用了进程A 申请的 mm_struct,此时 mm_users=3, mm_count=2
- - CPU的另一个core调度了进程A及其线程,并且执行完了进程A及其线程的所有操作,也就是进程A退出了。此时 mm_users=0, mm_count=1
- 在这里就看出 mm_count 的用处了,如果只有 mm_users 的话,这里 mm_users=0 就会释放 mm_struct,从而有可能导致 内核线程B 异常。
- - 内核线程B 执行完成后退出,这时 mm_users=0,mm_count=0,可以安全释放 mm_struct 了
补充说明2:为何内核线程会使用用户空间的 mm_struct?
对Linux来说,用户进程和内核线程都是task_struct的实例,
唯一的区别是内核线程是没有进程地址空间的(内核线程使用的内核地址空间),内核线程的mm描述符是NULL,即内核线程的tsk->mm域是空(NULL)。
内核调度程序在进程上下文的时候,会根据tsk->mm判断即将调度的进程是用户进程还是内核线程。
但是虽然内核线程不用访问用户进程地址空间,但是仍然需要页表来访问内核自己的空间。
而任何用户进程来说,他们的内核空间都是100%相同的,所以内核会借用上一个被调用的用户进程的mm_struct中的页表来访问内核地址,这个mm_struct就记录在active_mm。
简而言之就是,对于内核线程,tsk->mm == NULL表示自己内核线程的身份,而tsk->active_mm是借用上一个用户进程的mm_struct,用mm_struct的页表来访问内核空间。
对于用户进程,tsk->mm == tsk->active_mm。
补充说明3:除了 mm_users 和 mm_count 之外,还有 mmap 和 mm_rb 需要说明以下:
其实 mmap 和 mm_rb 都是保存此 进程地址空间中所有的内存区域(VMA)的,前者是以链表形式存放,后者以红黑树形式存放。
用2种数据结构组织同一种数据是为了便于对VMA进行高效的操作。
1.2 mm_struct操作
1. 分配进程地址空间
参考 kernel/fork.c 中的宏 allocate_mm
#define allocate_mm() (kmem_cache_alloc(mm_cachep, GFP_KERNEL))
#define free_mm(mm) (kmem_cache_free(mm_cachep, (mm)))
其实分配进程地址空间时,都是从slab高速缓存中分配的,可以通过 /proc/slabinfo 查看 mm_struct 的高速缓存
# cat /proc/slabinfo | grep mm_struct
mm_struct 35 45 1408 5 2 : tunables 24 12 8 : slabdata 9 9 0
2. 撤销进程地址空间
参考 kernel/exit.c 中的 exit_mm() 函数
该函数会调用 mmput() 函数减少 mm_users 的值,
当 mm_users=0 时,调用 mmdropo() 函数, 减少 mm_count 的值,
如果 mm_count=0,那么调用 free_mm 宏,将 mm_struct 还给 slab高速缓存
3. 查看进程占用的内存:
cat /proc/<PID>/maps
或者
pmap PID
2. 虚拟内存区域(VMA)
内存区域在linux中也被称为虚拟内存区域(VMA),它其实就是进程地址空间上一段连续的内存范围。
2.1 VMA介绍
VMA的定义也在 <linux/mm_types.h> 中
struct vm_area_struct {
struct mm_struct * vm_mm; /* 相关的 mm_struct 结构体 */
unsigned long vm_start; /* 内存区域首地址 */
unsigned long vm_end; /* 内存区域尾地址 */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev; /* VMA链表 */
pgprot_t vm_page_prot; /* 访问控制权限 */
unsigned long vm_flags; /* 标志 */
struct rb_node vm_rb; /* 树上的VMA节点 */
/*
* For areas with an address space and backing store,
* linkage into the address_space->i_mmap prio tree, or
* linkage to the list of like vmas hanging off its node, or
* linkage of vma in the address_space->i_mmap_nonlinear list.
*/
union {
struct {
struct list_head list;
void *parent; /* aligns with prio_tree_node parent */
struct vm_area_struct *head;
} vm_set;
struct raw_prio_tree_node prio_tree_node;
} shared;
/*
* A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma
* list, after a COW of one of the file pages. A MAP_SHARED vma
* can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack
* or brk vma (with NULL file) can only be in an anon_vma list.
*/
struct list_head anon_vma_node; /* Serialized by anon_vma->lock */
struct anon_vma *anon_vma; /* Serialized by page_table_lock */
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE
units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
unsigned long vm_truncate_count;/* truncate_count or restart_addr */
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
};
这个结构体各个字段的英文注释都比较详细,就不一一翻译了。
上述属性中的 vm_flags 标识了此VM 对 VMA和页面的影响:
vm_flags 的宏定义参见 <linux/mm.h>
|
标志 |
对VMA及其页面的影响 |
| VM_READ | 页面可读取 |
| VM_WRITE | 页面可写 |
| VM_EXEC | 页面可执行 |
| VM_SHARED | 页面可共享 |
| VM_MAYREAD | VM_READ 标志可被设置 |
| VM_MAYWRITER | VM_WRITE 标志可被设置 |
| VM_MAYEXEC | VM_EXEC 标志可被设置 |
| VM_MAYSHARE | VM_SHARE 标志可被设置 |
| VM_GROWSDOWN | 区域可向下增长 |
| VM_GROWSUP | 区域可向上增长 |
| VM_SHM | 区域可用作共享内存 |
| VM_DENYWRITE | 区域映射一个不可写文件 |
| VM_EXECUTABLE | 区域映射一个可执行文件 |
| VM_LOCKED | 区域中的页面被锁定 |
| VM_IO | 区域映射设备I/O空间 |
| VM_SEQ_READ | 页面可能会被连续访问 |
| VM_RAND_READ | 页面可能会被随机访问 |
| VM_DONTCOPY | 区域不能在 fork() 时被拷贝 |
| VM_DONTEXPAND | 区域不能通过 mremap() 增加 |
| VM_RESERVED | 区域不能被换出 |
| VM_ACCOUNT | 该区域时一个记账 VM 对象 |
| VM_HUGETLB | 区域使用了 hugetlb 页面 |
| VM_NONLINEAR | 该区域是非线性映射的 |
2.2 VMA操作
vm_area_struct 结构体定义中有个 vm_ops 属性,其中定义了内核操作 VMA 的方法
/*
* These are the virtual MM functions - opening of an area, closing and
* unmapping it (needed to keep files on disk up-to-date etc), pointer
* to the functions called when a no-page or a wp-page exception occurs.
*/
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area); /* 指定内存区域加入到一个地址空间时,该函数被调用 */
void (*close)(struct vm_area_struct * area); /* 指定内存区域从一个地址空间删除时,该函数被调用 */
int (*fault)(struct vm_area_struct *vma, struct vm_fault *vmf); /* 当没有出现在物理页面中的内存被访问时,该函数被调用 */ /* 当一个之前只读的页面变为可写时,该函数被调用,
* 如果此函数出错,将导致一个 SIGBUS 信号 */
int (*page_mkwrite)(struct vm_area_struct *vma, struct vm_fault *vmf); /* 当 get_user_pages() 调用失败时, 该函数被 access_process_vm() 函数调用 */
int (*access)(struct vm_area_struct *vma, unsigned long addr,
void *buf, int len, int write);
#ifdef CONFIG_NUMA
/*
* set_policy() op must add a reference to any non-NULL @new mempolicy
* to hold the policy upon return. Caller should pass NULL @new to
* remove a policy and fall back to surrounding context--i.e. do not
* install a MPOL_DEFAULT policy, nor the task or system default
* mempolicy.
*/
int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new); /*
* get_policy() op must add reference [mpol_get()] to any policy at
* (vma,addr) marked as MPOL_SHARED. The shared policy infrastructure
* in mm/mempolicy.c will do this automatically.
* get_policy() must NOT add a ref if the policy at (vma,addr) is not
* marked as MPOL_SHARED. vma policies are protected by the mmap_sem.
* If no [shared/vma] mempolicy exists at the addr, get_policy() op
* must return NULL--i.e., do not "fallback" to task or system default
* policy.
*/
struct mempolicy *(*get_policy)(struct vm_area_struct *vma,
unsigned long addr);
int (*migrate)(struct vm_area_struct *vma, const nodemask_t *from,
const nodemask_t *to, unsigned long flags);
#endif
};
除了以上的操作之外,还有一些辅助函数来方便内核操作内存区域。
这些辅助函数都可以在 <linux/mm.h> 中找到
1. 查找地址空间
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
extern struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr);
extern struct vm_area_struct * find_vma_prev(struct mm_struct * mm, unsigned long addr,
struct vm_area_struct **pprev); /* Look up the first VMA which intersects the interval start_addr..end_addr-1,
NULL if none. Assume start_addr < end_addr. */
static inline struct vm_area_struct * find_vma_intersection(struct mm_struct * mm, unsigned long start_addr, unsigned long end_addr)
{
struct vm_area_struct * vma = find_vma(mm,start_addr); if (vma && end_addr <= vma->vm_start)
vma = NULL;
return vma;
}
2. 创建地址区间
static inline unsigned long do_mmap(struct file *file, unsigned long addr,
unsigned long len, unsigned long prot,
unsigned long flag, unsigned long offset)
{
unsigned long ret = -EINVAL;
if ((offset + PAGE_ALIGN(len)) < offset)
goto out;
if (!(offset & ~PAGE_MASK))
ret = do_mmap_pgoff(file, addr, len, prot, flag, offset >> PAGE_SHIFT);
out:
return ret;
}
3. 删除地址区间
extern int do_munmap(struct mm_struct *, unsigned long, size_t);
3. 地址空间和页表
地址空间中的地址都是虚拟内存中的地址,而CPU需要操作的是物理内存,所以需要一个将虚拟地址映射到物理地址的机制。
这个机制就是页表,linux中使用3级页面来完成虚拟地址到物理地址的转换。
1. PGD - 全局页目录,包含一个 pgd_t 类型数组,多数体系结构中 pgd_t 类型就是一个无符号长整型
2. PMD - 中间页目录,它是个 pmd_t 类型数组
3. PTE - 简称页表,包含一个 pte_t 类型的页表项,该页表项指向物理页面
虚拟地址 - 页表 - 物理地址的关系如下图:

页高速缓存和页回写
主要内容:
- 缓存简介
- 页高速缓存
- 页回写
1. 缓存简介
在编程中,缓存是很常见也很有效的一种提高程序性能的机制。
linux内核也不例外,为了提高I/O性能,也引入了缓存机制,即将一部分磁盘上的数据缓存到内存中。
1.1 原理
之所以通过缓存能提高I/O性能是基于以下2个重要的原理:
- CPU访问内存的速度远远大于访问磁盘的速度(访问速度差距不是一般的大,差好几个数量级)
- 数据一旦被访问,就有可能在短期内再次被访问(临时局部原理)
1.2 策略
缓存的创建和读取没什么好说的,无非就是检查缓存是否存在要创建或者要读取的内容。
但是写缓存和缓存回收就需要好好考虑了,这里面涉及到「缓存内容」和「磁盘内容」同步的问题。
1.2.1 「写缓存」常见的有3种策略
- 不缓存(nowrite) :: 也就是不缓存写操作,当对缓存中的数据进行写操作时,直接写入磁盘,同时使此数据的缓存失效
- 写透缓存(write-through) :: 写数据时同时更新磁盘和缓存
- 回写(copy-write or write-behind) :: 写数据时直接写到缓存,由另外的进程(回写进程)在合适的时候将数据同步到磁盘
3种策略的优缺点如下:
|
策略 |
复杂度 |
性能 |
| 不缓存 | 简单 | 缓存只用于读,对于写操作较多的I/O,性能反而会下降 |
| 写透缓存 | 简单 | 提升了读性能,写性能反而有些下降(除了写磁盘,还要写缓存) |
| 回写 | 复杂 | 读写的性能都有提高(目前内核中采用的方法) |
1.2.2 「缓存回收」的策略
- 最近最少使用(LRU) :: 每个缓存数据都有个时间戳,保存最近被访问的时间。回收缓存时首先回收时间戳较旧的数据。
- 双链策略(LRU/2) :: 基于LRU的改善策略。具体参见下面的补充说明
补充说明(双链策略):
双链策略其实就是 LRU(Least Recently Used) 算法的改进版。
它通过2个链表(活跃链表和非活跃链表)来模拟LRU的过程,目的是为了提高页面回收的性能。
页面回收动作发生时,从非活跃链表的尾部开始回收页面。
双链策略的关键就是页面如何在2个链表之间移动的。
双链策略中,每个页面都有2个标志位,分别为
PG_active - 标志页面是否活跃,也就是表示此页面是否要移动到活跃链表
PG_referenced - 表示页面是否被进程访问到
页面移动的流程如下:
- 当页面第一次被被访问时,PG_active 置为1,加入到活动链表
- 当页面再次被访问时,PG_referenced 置为1,此时如果页面在非活动链表,则将其移动到活动链表,并将PG_active置为1,PG_referenced 置为0
- 系统中 daemon 会定时扫描活动链表,定时将页面的 PG_referenced 位置为0
- 系统中 daemon 定时检查页面的 PG_referenced,如果 PG_referenced=0,那么将此页面的 PG_active 置为0,同时将页面移动到非活动链表
2. 页高速缓存
故名思义,页高速缓存中缓存的最小单元就是内存页。
但是此内存页对应的数据不仅仅是文件系统的数据,可以是任何基于页的对象,包括各种类型的文件和内存映射。
2.1 简介
页高速缓存缓存的是具体的物理页面,与前面章节中提到的虚拟内存空间(vm_area_struct)不同,假设有进程创建了多个 vm_area_struct 都指向同一个文件,
那么这个 vm_area_struct 对应的 页高速缓存只有一份。
也就是磁盘上的文件缓存到内存后,它的虚拟内存地址可以有多个,但是物理内存地址却只能有一个。
为了有效提高I/O性能,页高速缓存要需要满足以下条件:
- 能够快速检索需要的内存页是否存在
- 能够快速定位 脏页面(也就是被写过,但还没有同步到磁盘上的数据)
- 页高速缓存被并发访问时,尽量减少并发锁带来的性能损失
下面通过分析内核中的相应的结构体,来了解内核是如何提高 I/O性能的。
2.2 实现
实现页高速缓存的最重要的结构体要算是 address_space ,在 <linux/fs.h> 中
struct address_space {
struct inode *host; /* 拥有此 address_space 的inode对象 */
struct radix_tree_root page_tree; /* 包含全部页面的 radix 树 */
spinlock_t tree_lock; /* 保护 radix 树的自旋锁 */
unsigned int i_mmap_writable;/* VM_SHARED 计数 */
struct prio_tree_root i_mmap; /* 私有映射链表的树 */
struct list_head i_mmap_nonlinear;/* VM_NONLINEAR 链表 */
spinlock_t i_mmap_lock; /* 保护 i_map 的自旋锁 */
unsigned int truncate_count; /* 截断计数 */
unsigned long nrpages; /* 总页数 */
pgoff_t writeback_index;/* 回写的起始偏移 */
const struct address_space_operations *a_ops; /* address_space 的操作表 */
unsigned long flags; /* gfp_mask 掩码与错误标识 */
struct backing_dev_info *backing_dev_info; /* 预读信息 */
spinlock_t private_lock; /* 私有 address_space 自旋锁 */
struct list_head private_list; /* 私有 address_space 链表 */
struct address_space *assoc_mapping; /* 缓冲 */
struct mutex unmap_mutex; /* 保护未映射页的 mutux 锁 */
} __attribute__((aligned(sizeof(long))));
补充说明:
- inode - 如果 address_space 是由不带inode的文件系统中的文件映射的话,此字段为 null
- page_tree - 这个树结构很重要,它保证了页高速缓存中数据能被快速检索到,脏页面能够快速定位。
- i_mmap - 根据 vm_area_struct,能够快速的找到关联的缓存文件(即 address_space),前面提到过, address_space 和 vm_area_struct 是 一对多的关系。
- 其他字段主要是提供各种锁和辅助功能
此外,对于这里出现的一种新的数据结构 radix 树,进行简要的说明。
radix树通过long型的位操作来查询各个节点, 存储效率高,并且可以快速查询。
linux中 radix树相关的内容参见: include/linux/radix-tree.h 和 lib/radix-tree.c
下面根据我自己的理解,简单的说明一下radix树结构及原理。
2.2.1 首先是 radix树节点的定义
/* 源码参照 lib/radix-tree.c */
struct radix_tree_node {
unsigned int height; /* radix树的高度 */
unsigned int count; /* 当前节点的子节点数目 */
struct rcu_head rcu_head; /* RCU 回调函数链表 */
void *slots[RADIX_TREE_MAP_SIZE]; /* 节点中的slot数组 */
unsigned long tags[RADIX_TREE_MAX_TAGS][RADIX_TREE_TAG_LONGS]; /* slot标签 */
};
弄清楚 radix_tree_node 中各个字段的含义,也就差不多知道 radix树是怎么一回事了。
- height 表示的整个 radix树的高度(即叶子节点到树根的高度), 不是当前节点到树根的高度
- count 这个比较好理解,表示当前节点的子节点个数,叶子节点的 count=0
- rcu_head RCU发生时触发的回调函数链表
- slots 每个slot对应一个子节点(叶子节点)
- tags 标记子节点是否 dirty 或者 wirteback
2.2.2 每个叶子节点指向文件内相应偏移所对应的缓存页
比如下图表示 0x000000 至 0x11111111 的偏移范围,树的高度为4 (图是网上找的,不是自己画的)

2.2.3 radix tree 的叶子节点都对应一个二进制的整数,不是字符串,所以进行比较的时候非常快
其实叶子节点的值就是地址空间的值(一般是long型)
3. 页回写
由于目前linux内核中对于「写缓存」采用的是第3种策略,所以回写的时机就显得非常重要,回写太频繁影响性能,回写太少容易造成数据丢失。
3.1 简介
linux 页高速缓存中的回写是由内核中的一个线程(flusher 线程)来完成的,flusher 线程在以下3种情况发生时,触发回写操作。
1. 当空闲内存低于一个阀值时
空闲内存不足时,需要释放一部分缓存,由于只有不脏的页面才能被释放,所以要把脏页面都回写到磁盘,使其变成干净的页面。
2. 当脏页在内存中驻留时间超过一个阀值时
确保脏页面不会无限期的驻留在内存中,从而减少了数据丢失的风险。
3. 当用户进程调用 sync() 和 fsync() 系统调用时
给用户提供一种强制回写的方法,应对回写要求严格的场景。
页回写中涉及的一些阀值可以在 /proc/sys/vm 中找到
下表中列出的是与 pdflush(flusher 线程的一种实现) 相关的一些阀值
|
阀值 |
描述 |
| dirty_background_ratio | 占全部内存的百分比,当内存中的空闲页达到这个比例时,pdflush线程开始回写脏页 |
| dirty_expire_interval | 该数值以百分之一秒为单位,它描述超时多久的数据将被周期性执行的pdflush线程写出 |
| dirty_ratio | 占全部内存的百分比,当一个进程产生的脏页达到这个比例时,就开始被写出 |
| dirty_writeback_interval | 该数值以百分之一秒未单位,它描述pdflush线程的运行频率 |
| laptop_mode | 一个布尔值,用于控制膝上型计算机模式 |
3.2 实现
flusher线程的实现方法随着内核的发展也在不断的变化着。下面介绍几种在内核发展中出现的比较典型的实现方法。
1. 膝上型计算机模式
这种模式的意图是将硬盘转动的机械行为最小化,允许硬盘尽可能长时间的停滞,以此延长电池供电时间。
该模式通过 /proc/sys/vm/laptop_mode 文件来设置。(0 - 关闭该模式 1 - 开启该模式)
2. bdflush 和 kupdated (2.6版本前 flusher 线程的实现方法)
bdflush 内核线程在后台运行,系统中只有一个 bdflush 线程,当内存消耗到特定阀值以下时,bdflush 线程被唤醒
kupdated 周期性的运行,写回脏页。
bdflush 存在的问题:
整个系统仅仅只有一个 bdflush 线程,当系统回写任务较重时,bdflush 线程可能会阻塞在某个磁盘的I/O上,
导致其他磁盘的I/O回写操作不能及时执行。
3. pdflush (2.6版本引入)
pdflush 线程数目是动态的,取决于系统的I/O负载。它是面向系统中所有磁盘的全局任务的。
pdflush 存在的问题:
pdflush的数目是动态的,一定程度上缓解了 bdflush 的问题。但是由于 pdflush 是面向所有磁盘的,
所以有可能出现多个 pdflush 线程全部阻塞在某个拥塞的磁盘上,同样导致其他磁盘的I/O回写不能及时执行。
4. flusher线程 (2.6.32版本后引入)
flusher线程改善了上面出现的问题:
首先,flusher 线程的数目不是唯一的,这就避免了 bdflush 线程的问题
其次,flusher 线程不是面向所有磁盘的,而是每个 flusher 线程对应一个磁盘,这就避免了 pdflush 线程的问题
设备与模块
主要内容:
- 设备类型
- 内核模块
- 内核对象
- sysfs
- 总结
1. 设备类型
linux中主要由3种类型的设备,分别是:
|
设备类型 |
代表设备 |
特点 |
访问方式 |
| 块设备 | 硬盘,光盘 | 随机访问设备中的内容 | 一般都是把设备挂载为文件系统后再访问 |
| 字符设备 | 键盘,打印机 | 只能顺序访问(一个一个字符或者一个一个字节) | 一般不挂载,直接和设备交互 |
| 网络设备 | 网卡 | 打破了Unix "所有东西都是文件" 的设计原则 | 通过套接字API来访问 |
除了以上3种典型的设备之外,其实Linux中还有一些其他的设备类型,其中见的较多的应该算是"伪设备"。
所谓"伪设备",其实就是一些虚拟的设备,仅提供访问内核功能而已,没有物理设备与之关联。
典型的"伪设备"就是 /dev/random(内核随机数发生器), /dev/null(空设备), /dev/zero(零设备), /dev/full(满设备)
2. 内核模块
Linux内核是模块化组成的,内核中的模块可以按需加载,从而保证内核启动时不用加载所有的模块,即减少了内核的大小,也提高了效率。
通过编写内核模块来给内核增加功能或者接口是个很好的方式(既不用重新编译内核,也方便调试和删除)。
2.1 内核模块示例
内核模块可以带参数也可以不带参数,不带参数的内核模块比较简单。
我之前的几篇随笔中用于测试的例子都是用不带参数的内核模块来实验的。
2.1.1. 无参数的内核模块
。。。。。。
2.1.2. 带参数的内核模块
构造带参数的内核模块其实也不难,内核中已经提供了简单的框架来给我们声明参数。
1. module_param(name, type, perm) : 定义一个模块参数
+ 参数 name :: 既是用户可见的参数名,也是模块中存放模块参数的变量名
+ 参数 type :: 参数的类型(byte, short, int, uint, long, ulong, charp, bool...) byte型存放在char变量中,bool型存放在int变量中
+ 参数 perm :: 指定模块在 sysfs 文件系统中对应的文件权限(关于 sysfs 的内容后面介绍)
static int stu_id = 0; // 默认id
module_param(stu_id, int, 0644);
2. module_param_named(name, variable, type, perm) : 定义一个模块参数,并且参数对内对外的名称不一样
+ 参数 name :: 用户可见的参数名
+ 参数 variable :: 模块中存放模块参数的变量名
+ 参数 type和perm :: 同 module_param 中的 type 和 perm
static char* stu_name_in = "default name"; // 默认名字
module_param_named(stu_name_out, stu_name_in ,charp, 0644);
/* stu_name_out 是对用户开放的名称
* stu_name_in 是内核模块内部使用的名称
*/
3. module_param_string(name, string, len, perm) : 拷贝字符串到指定的字符数组
+ 参数 name :: 用户可见的参数名
+ 参数 string :: 模块中存放模块参数的变量名
+ 参数 len :: string 参数的缓冲区长度
+ 参数 perm :: 同 module_param 中的 perm
static char str_in[BUF_LEN];
module_param_string(str_out, str_in, BUF_LEN, 0);
/* perm=0 表示完全禁止 sysfs 项 */
4. module_param_array(name, type, nump, perm) : 定义数组类型的模块参数
+ 参数 name :: 同 module_param 中的 name
+ 参数 type :: 同 module_param 中的 type
+ 参数 nump :: 整型指针,存放数组的长度
+ 参数 perm :: 同 module_param 中的 perm
#define MAX_ARR_LEN 5
static int arr_len;
static int arr_in[MAX_ARR_LEN];
module_param_array(arr_in, int, &arr_len, 0644);
5. module_param_array_named(name, array, type, nump, perm) : 定义数组类型的模块参数,并且数组参数对内对外的名称不一样
+ 参数 name :: 数组参数对外的名称
+ 参数 array :: 数组参数对内的名称
+ 参数 type,nump,perm :: 同 module_param_array 中的 type,nump,perm
#define MAX_ARR_LEN 5
static int arr_len;
static int arr_in[MAX_ARR_LEN];
module_param_array_named(arr_out, arr_in, int, &arr_len, 0644);
6. 参数描述宏
可以通过 MODULE_PARM_DESC() 来给内核模块的参数添加一些描述信息。
这些描述信息在编译完内核模块后,可以通过 modinfo 命令查看。
static int stu_id = 0; // 默认id
module_param(stu_id, int, 0644);
MODULE_PARM_DESC(stu_id, "学生ID,默认为 0"); // 这句就是描述内核模块参数 stu_id 的语句
7. 带参数的内核模块的示例
示例代码:test_paramed_km.c
定义了3个内核模块参数,分别是 int型,char*型,数组型的。
#include<linux/init.h>
#include<linux/module.h>
#include<linux/kernel.h> MODULE_LICENSE("Dual BSD/GPL"); struct student
{
int id;
char* name;
};
static void print_student(struct student*); static int stu_id = 0; // 默认id
module_param(stu_id, int, 0644);
MODULE_PARM_DESC(stu_id, "学生ID,默认为 0"); static char* stu_name_in = "default name"; // 默认名字
module_param_named(stu_name_out, stu_name_in ,charp, 0644);
MODULE_PARM_DESC(stu_name, "学生姓名,默认为 default name"); #define MAX_ARR_LEN 5
static int arr_len;
static int arr_in[MAX_ARR_LEN];
module_param_array_named(arr_out, arr_in, int, &arr_len, 0644);
MODULE_PARM_DESC(arr_in, "数组参数,默认为空"); static int test_paramed_km_init(void)
{
struct student* stu1;
int i; /* 进入内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "test_paramed_km is inited!\n");
printk(KERN_ALERT "*************************\n");
// 根据参数生成 struct student 信息
// 如果没有参数就用默认参数
printk(KERN_ALERT "alloc one student....\n");
stu1 = kmalloc(sizeof(*stu1), GFP_KERNEL);
stu1->id = stu_id;
stu1->name = stu_name_in;
print_student(stu1); // 模块数组
for (i = 0; i < arr_len; ++i) {
printk(KERN_ALERT "arr_value[%d]: %d\n", i, arr_in[i]);
} return 0;
} static void test_paramed_km_exit(void)
{
/* 退出内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "test_paramed_km is exited!\n");
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "\n\n\n\n\n");
} static void print_student(struct student *stu)
{
if (stu != NULL)
{
printk(KERN_ALERT "**********student info***********\n");
printk(KERN_ALERT "student id is: %d\n", stu->id);
printk(KERN_ALERT "student name is: %s\n", stu->name);
printk(KERN_ALERT "*********************************\n");
}
else
printk(KERN_ALERT "the student info is null!!\n");
} module_init(test_paramed_km_init);
module_exit(test_paramed_km_exit);
上面的示例对应的 Makefile 如下:
# must complile on customize kernel
obj-m += paramed_km.o
paramed_km-objs := test_paramed_km.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
内核模块运行方法:(我的运行环境是 ubuntu x86_64)
[root@vbox wzh]# uname -r
2.6.32-279.el6.x86_64
[root@vbox wzh]# ll
total 8
-rw-r--r-- 1 root root 538 Dec 1 19:37 Makefile
-rw-r--r-- 1 root root 2155 Dec 1 19:37 test_paramed_km.c
[root@vbox wzh]# make <-- 编译内核
make -C /usr/src/kernels/2.6.32-279.el6.x86_64 M=/root/chap17 modules
make[1]: Entering directory `/usr/src/kernels/2.6.32-279.el6.x86_64'
CC [M] /root/wzh/test_paramed_km.o
LD [M] /root/wzh/paramed_km.o
Building modules, stage 2.
MODPOST 1 modules
CC /root/wzh/paramed_km.mod.o
LD [M] /root/wzh/paramed_km.ko.unsigned
NO SIGN [M] /root/wzh/paramed_km.ko
make[1]: Leaving directory `/usr/src/kernels/2.6.32-279.el6.x86_64'
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
[root@vbox wzh]# ll <-- 编译内核后,多了 paramed_km.ko 文件
total 124
-rw-r--r-- 1 root root 538 Dec 1 19:37 Makefile
-rw-r--r-- 1 root root 118352 Dec 1 19:37 paramed_km.ko
-rw-r--r-- 1 root root 2155 Dec 1 19:37 test_paramed_km.c <-- 通过 modinfo 命令可以查看对内核模块参数的注释
[root@vbox wzh]# modinfo paramed_km.ko
filename: paramed_km.ko
license: Dual BSD/GPL
srcversion: C52F97687B033738742800D
depends:
vermagic: 2.6.32-279.el6.x86_64 SMP mod_unload modversions
parm: stu_id:学生ID,默认为 0 (int)
parm: stu_name_out:charp
parm: stu_name_in:学生姓名,默认为 default name
parm: arr_out:array of int
parm: arr_in:数组参数,默认为空 <-- 3 个参数都是默认的
[root@vbox wzh]# insmod paramed_km.ko
[root@vbox wzh]# rmmod paramed_km.ko
[root@vbox wzh]# dmesg | tail -16 <-- 结果中显示2个默认参数,第3个数组参数默认为空,所以不显示
*************************
test_paramed_km is inited!
*************************
alloc one student....
**********student info***********
student id is: 0
student name is: default name
*********************************
*************************
test_paramed_km is exited!
************************* <-- 3 个参数都被设置
[root@vbox wzh]# insmod paramed_km.ko stu_id=100 stu_name_out=myname arr_out=1,2,3,4,5
[root@vbox wzh]# rmmod paramed_km.ko
[root@vbox wzh]# dmesg | tail -21
*************************
test_paramed_km is inited!
*************************
alloc one student....
**********student info***********
student id is: 100
student name is: myname
*********************************
arr_value[0]: 1
arr_value[1]: 2
arr_value[2]: 3
arr_value[3]: 4
arr_value[4]: 5
*************************
test_paramed_km is exited!
*************************
2.2 内核模块的位置
2.2.1. 内核代码外
上面的例子,以及之前博客中内核模块的例子都是把模块代码放在内核之外来运行的。
2.2.2. 内核代码中
内核模块的代码也可以直接放到内核代码树中。
如果你开发了一种驱动,并且希望被加入到内核中,那么,可以在编写驱动的时候就将完成此驱动功能的内核模块加到内核代码树中 driver 的相应位置。
将内核模块加入内核代码树中之后,不需要另外写 Makefile,修改内核代码树中的已有的 Makefile 就行。
比如,写了一个某种字符设备相关的驱动,可以把它加到内核代码的 /drivers/char 下,同时修改 /drivers/char下的Makefie,仿照里面已有的内容,增加新驱动的编译相关内容即可。
之后,在编译内核的时候会将新的驱动以内核模块的方式编译出来。
2.3 内核模块相关操作
2.3.1. 模块安装
make modules_install <-- 把随内核编译出来的模块安装到合适的目录中( /lib/modules/version/kernel )
2.3.2. 模块依赖性
linux中自动生产模块依赖性的命令:
depmod <-- 产生内核依赖关系信息
depmod -A <-- 只为新模块生成依赖信息(速度更快)
2.3.3. 模块的载入
内核模块实验时已经用过:
insmod module.ko <-- 推荐使用以下的命令, 自动加载依赖的模块
modprobe module [module parameters]
2.3.4. 模块的卸载
内核模块实验时已经用过:
rmmod module.ko <-- 推荐使用以下的命令, 自动卸载依赖的模块
modprobe -r module
2.3.5. 模块导出符号表
内核模块被载入后,就动态的加载到内核中,为了能让其他内核模块使用其功能,需要将其中函数导出。
内核模块中导出函数的方法:
EXPORT_SYMBOL(函数名) <-- 接在要导出的函数后面即可
EXPORT_SYMBOL_GPL(函数名) <-- 和EXPORT_SYMBOL一样,区别在于只对标记为GPL协议的模块可见
内核模块导出符号表 示例:
+ 首先编写一个导出函数的模块 module_A: test_module_A.c
#include<linux/init.h>
#include<linux/module.h>
#include<linux/kernel.h> MODULE_LICENSE("Dual BSD/GPL"); static int test_export_A_init(void)
{
/* 进入内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "ENTRY test_export_A!\n");
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "\n\n\n\n\n");
return 0;
} static void test_export_A_exit(void)
{
/* 退出内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "EXIT test_export_A!\n");
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "\n\n\n\n\n");
} /* 要导出的函数 */
int export_add10(int param)
{
printk(KERN_ALERT "param from other module is : %d\n", param);
return param + 10;
}
EXPORT_SYMBOL(export_add10); module_init(test_export_A_init);
module_exit(test_export_A_exit);
test_module_A.c 的 Makefile
# must complile on customize kernel
obj-m += export_A.o
export_A-objs := test_export_A.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
+ 再编写一个内核模块 module_B,使用 module_A 导出的函数 : test_module_B.c
#include<linux/init.h>
#include<linux/module.h>
#include<linux/kernel.h> MODULE_LICENSE("Dual BSD/GPL"); extern int export_add10(int); // 这个函数是 module_A 中实现的 static int test_export_B_init(void)
{
/* 进入内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "ENTRY test_export_B!\n");
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "\n\n\n\n\n"); /* 调用 module_A 导出的函数 */
printk(KERN_ALERT "result from test_export_A: %d\n", export_add10(100)); return 0;
} static void test_export_B_exit(void)
{
/* 退出内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "EXIT test_export_B!\n");
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "\n\n\n\n\n");
} module_init(test_export_B_init);
module_exit(test_export_B_exit);
test_module_B.c 的 Makefile
# must complile on customize kernel
obj-m += export_B.o
export_B-objs := test_export_B.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
+ 测试方法
1. 将 test_export_A.c 和对应的 Makefile 拷贝到 module_A 文件夹中
2. 将 test_export_B.c 和对应的 Makefile 拷贝到 module_B 文件夹中
3. 编译 module_A 中的 test_export_A.c
4. 将编译 module_A 后生成的 Module.symvers 拷贝到 module_B 文件夹中
5. 编译 module_B 中的 test_export_B.c
6. 先安装 模块A,再安装模块B
7. dmesg 查看log
8. 用 rmmod 卸载模块B 和 模块A (注意卸载顺序,先卸载B再卸载A)
[root@vbox wzh]# ll
total 8
drwxrwxr-x 2 root root 4096 Dec 7 22:14 module_A
drwxrwxr-x 2 root root 4096 Dec 7 22:14 module_B
[root@vbox wzh]# ll module_A
total 8
-rw-r--r-- 1 root root 517 Dec 7 21:58 Makefile
-rw-r--r-- 1 root root 893 Dec 7 21:58 test_export_A.c
[root@vbox wzh]# ll module_B
total 8
-rw-r--r-- 1 root root 532 Dec 7 21:58 Makefile
-rw-r--r-- 1 root root 830 Dec 7 21:58 test_export_B.c [root@vbox wzh]# cd module_A/
[root@vbox module_A]# ll
total 8
-rw-r--r-- 1 root root 517 Dec 7 21:58 Makefile
-rw-r--r-- 1 root root 893 Dec 7 21:58 test_export_A.c
[root@vbox module_A]# make
make -C /usr/src/kernels/2.6.32-279.el6.x86_64 M=/root/wzh/module_A modules
make[1]: Entering directory `/usr/src/kernels/2.6.32-279.el6.x86_64'
CC [M] /root/wzh/module_A/test_export_A.o
LD [M] /root/wzh/module_A/export_A.o
Building modules, stage 2.
MODPOST 1 modules
CC /root/wzh/module_A/export_A.mod.o
LD [M] /root/wzh/module_A/export_A.ko.unsigned
NO SIGN [M] /root/wzh/module_A/export_A.ko
make[1]: Leaving directory `/usr/src/kernels/2.6.32-279.el6.x86_64'
rm -rf modules.order .*.cmd *.o *.mod.c .tmp_versions *.unsigned
[root@vbox module_A]# ll
total 120
-rw-r--r-- 1 root root 110452 Dec 7 22:31 export_A.ko
-rw-r--r-- 1 root root 517 Dec 7 21:58 Makefile
-rw-r--r-- 1 root root 69 Dec 7 22:31 Module.symvers
-rw-r--r-- 1 root root 893 Dec 7 21:58 test_export_A.c [root@vbox module_A]# cd ../module_B
[root@vbox module_B]# ll
total 8
-rw-r--r-- 1 root root 532 Dec 7 21:58 Makefile
-rw-r--r-- 1 root root 830 Dec 7 21:58 test_export_B.c
[root@vbox module_B]# cp ../module_A/Module.symvers .
[root@vbox module_B]# ll
total 12
-rw-r--r-- 1 root root 532 Dec 7 21:58 Makefile
-rw-r--r-- 1 root root 69 Dec 7 22:32 Module.symvers
-rw-r--r-- 1 root root 830 Dec 7 21:58 test_export_B.c
[root@vbox module_B]# make
make -C /usr/src/kernels/2.6.32-279.el6.x86_64 M=/root/wzh/module_B modules
make[1]: Entering directory `/usr/src/kernels/2.6.32-279.el6.x86_64'
CC [M] /root/wzh/module_B/test_export_B.o
LD [M] /root/wzh/module_B/export_B.o
Building modules, stage 2.
MODPOST 1 modules
CC /root/wzh/module_B/export_B.mod.o
LD [M] /root/wzh/module_B/export_B.ko.unsigned
NO SIGN [M] /root/chap17/module_B/export_B.ko
make[1]: Leaving directory `/usr/src/kernels/2.6.32-279.el6.x86_64'
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
[root@vbox module_B]# ll
total 116
-rw-r--r-- 1 root root 108596 Dec 7 22:32 export_B.ko
-rw-r--r-- 1 root root 532 Dec 7 21:58 Makefile
-rw-r--r-- 1 root root 830 Dec 7 21:58 test_export_B.c [root@vbox module_B]# insmod ../module_A/export_A.ko
[root@vbox module_B]# insmod export_B.ko
[root@vbox module_B]# dmesg | tail -18
*************************
ENTRY test_export_A!
************************* *************************
ENTRY test_export_B!
************************* param from other module is : 100
result from test_export_A: 110 [root@vbox module_B]# rmmod export_B
[root@vbox module_B]# rmmod export_A
注:
1. 必须把编译模块A后生成的 Module.symvers 拷贝到module_B 中再编译模块B,否在模块B找不到模块A导出的函数
2. 先安装模块A,再安装模块B。
3. 先卸载模块B,再卸载模块A。
4. 安装卸载如果不按照上面的顺序,会有错误提示,大家可以试试看。
5. 我实验的系统是 ubuntu x86_64
3. 内核对象
2.6内核中增加了一个引人注目的新特性--统一设备模型(device model)。
统一设备模型的最初动机是为了实现智能的电源管理,linux 内核为了实现智能电源管理,需要建立表示系统中所有设备拓扑关系的树结构,这样在关闭电源时,可以从树的节点开始关闭。
实现了统一设备模型之后,还给内核带来了如下的好处:
1. 代码重复最小化(统一处理的东西多了)
2. 可以列举系统中所有设备,观察它们的状态,并查看它们连接的总线
3. 可以将系统中的全部设备以树的形式完整,有效的展示出来--包括所有总线和内部连接
4. 可以将设备和其对应的驱动联系起来,反之亦然
5. 可以将设备按照类型加以归类,无需理解物理设备的拓扑结构
6. 可以沿设备树的叶子向其根的反向依次遍历,以保证能以正确的顺序关闭设备电源
3.1 kobject 简介
统一设备模型的核心部分就是 kobject,通过下面对kobject结构体的介绍,可以大致了解它是如何使得各个物理设备能够以树结构的形式组织起来的。
3.1.1. kobject
kobject的定义在 <linux/kobject.h> 中
struct kobject {
const char *name; /* kobject 名称 */
struct list_head entry; /* kobject 链表 */
struct kobject *parent; /* kobject 的父对象,说明kobject是有层次结构的 */
struct kset *kset; /* kobject 的集合,接下来有详细介绍 */
struct kobj_type *ktype; /* kobject 的类型,接下来有详细介绍 */
struct sysfs_dirent *sd; /* 在sysfs中,这个结构体表示kobject的一个inode结构体,sysfs之后也会介绍 */
struct kref kref; /* 提供 kobject 的引用计数 */
/* 一些标志位 */
unsigned int state_initialized:1;
unsigned int state_in_sysfs:1;
unsigned int state_add_uevent_sent:1;
unsigned int state_remove_uevent_sent:1;
unsigned int uevent_suppress:1;
};
kobject 本身不代表什么实际的内容,一般都是嵌在其他数据结构中来发挥作用。(感觉有点像内核数据结构链表的节点)
比如 <linux/cdev.h> 中的 struct cdev (表示字符设备的struct)
struct cdev {
struct kobject kobj; /* 嵌在 cdev 中的kobject */
struct module *owner;
const struct file_operations *ops;
struct list_head list;
dev_t dev;
unsigned int count;
};
cdev中嵌入了kobject之后,就可以通过 cdev->kboj.parent 建立cdev之间的层次关系,通过 cdev->kobj.entry 获取关联的所有cdev设备等。
总之,嵌入了kobject之后,cdev设备之间就有了树结构关系,cdev设备和其他设备之间也有可层次关系。
3.1.2. ktype
ktype是为了描述一族的kobject所具有的普遍属性,也就是将这一族的kobject的属性统一定义一下,避免每个kobject分别定义。
(感觉有点像面向对象语言中的抽象类或者接口)
ktype的定义很简单,参见<linux/kobject.h>
struct kobj_type {
void (*release)(struct kobject *kobj); /* kobject的引用计数降到0时触发的析构函数,负责释放和清理内存的工作 */
struct sysfs_ops *sysfs_ops; /* sysfs操作相关的函数 */
struct attribute **default_attrs; /* kobject 相关的默认属性 */
};
3.1.3. kset
kset是kobject对象的集合体,可以所有相关的kobject置于一个kset之中,比如所有“块设备”可以放在一个表示块设备的kset中。
kset的定义也不复杂,参见 <linux/kobject.h>
struct kset {
struct list_head list; /* 表示kset中所有kobject的链表 */
spinlock_t list_lock; /* 用于保护 list 的自旋锁*/
struct kobject kobj; /* kset中嵌入的一个kobject,使得kset也可以表现的像一样kobject一样*/
struct kset_uevent_ops *uevent_ops; /* 处理kset中kobject的热插拔事件 提供了与用户空间热插拔进行通信的机制 */
};

3.1.4. kobject,ktype和kset之间的关系
这3个概念中,kobject是最基本的。kset和ktype是为了将kobject进行分类,以便将共通的处理集中处理,从而减少代码量,也增加维护性。
这里kset和ktype都是为了将kobject进行分类,为什么会有2中分类呢?
从整个内核的代码来看,其实kset的数量是多于ktype的数量的,同一种ktype的kobject可以位于不同的kset中。
做个不是很恰当的比喻,如果把kobject比作一个人的话,kset相当于一个一个国家,ktype则相当于人种(比如黄种人,白种人等等)。
人种的类型只有少数几个,但是国家确有很多,人种的目的是描述一群人的共通属性,而国家的目地则是为了管理一群人。
同样,ktype侧重于描述,kset侧重于管理。
3.1.5. kref
kref记录kobject被引用的次数,当引用计数降到0的时候,则执行release函数释放相关资源。
kref的定义参见:<linux/kref.h>
struct kref {
atomic_t refcount; /* 只有一个表示引用计数的属性,atomic_t 类型表示对它的访问是原子操作 */
};
void kref_set(struct kref *kref, int num); /* 设置引用计数的值 */
void kref_init(struct kref *kref); /* 初始化引用计数 */
void kref_get(struct kref *kref); /* 增加引用计数 +1 */
int kref_put(struct kref *kref, void (*release) (struct kref *kref)); /* 减少引用计数 -1 当减少到0时,释放相应资源 */
上面这些函数的具体实现可以参考内核代码 lib/kref.c
3.2 kobject 操作
kobject的相关都在 <linux/kobject.h> 中定义了,主要由以下一些:
extern void kobject_init(struct kobject *kobj, struct kobj_type *ktype); /* 初始化一个kobject,设置它是哪种ktype */
extern int __must_check kobject_add(struct kobject *kobj,
struct kobject *parent,
const char *fmt, ...); /* 设置此kobject的parent,将此kobject加入到现有对象层次结构中 */
extern int __must_check kobject_init_and_add(struct kobject *kobj,
struct kobj_type *ktype,
struct kobject *parent,
const char *fmt, ...); /* 初始化kobject,完成kobject_add 函数的功能*/ extern void kobject_del(struct kobject *kobj); /* 将此kobject从现有对象层次结构中取消 */ extern struct kobject * __must_check kobject_create(void); /* 创建一个kobject,比kobject_init更常用 */
extern struct kobject * __must_check kobject_create_and_add(const char *name,
struct kobject *parent); /* 创建一个kobject,并将其加入到现有对象层次结构中 */ extern int __must_check kobject_rename(struct kobject *, const char *new_name); /* 改变kobject的名称 */
extern int __must_check kobject_move(struct kobject *, struct kobject *); /* 给kobject设置新的parent */ extern struct kobject *kobject_get(struct kobject *kobj); /* 增加kobject的引用计数 +1 */
extern void kobject_put(struct kobject *kobj); /* 减少kobject的引用计数 -1 */ extern char *kobject_get_path(struct kobject *kobj, gfp_t flag); /* 生成并返回与给定的一个kobj和kset相关联的路径 */
上面这些函数的具体实现可以参考内核代码 lib/kobject.c
4. sysfs
sysfs是一个处于内存中的虚拟文件系统,它提供了kobject对象层次结构的视图。
可以用下面这个命令来查看 /sys 的结构
tree /sys # 显示所有目录和文件
或者
tree -L 1 /sys # 只显示一层目录
4.1 sysfs中的kobject
既然sysfs是kobject的视图,那么内核中肯定提供了在sysfs中操作kobject的API。
kobject结构体中与sysfs关联的字段就是 「struct sysfs_dirent *sd; 」这是一个目录项结构,它表示kobject在sysfs中的位置。
4.1.1. sysfs中添加和删除kobject非常简单,就是上面介绍的 kobject操作中提到的
extern int __must_check kobject_add(struct kobject *kobj,
struct kobject *parent,
const char *fmt, ...); /* 设置此kobject的parent,将此kobject加入到现有对象层次结构中 */
extern int __must_check kobject_init_and_add(struct kobject *kobj,
struct kobj_type *ktype,
struct kobject *parent,
const char *fmt, ...); /* 初始化kobject,完成kobject_add 函数的功能*/ extern void kobject_del(struct kobject *kobj); /* 将此kobject从现有对象层次结构中取消 */
... ...等等
添加了kobject之后,只会增加文件夹,不会增加文件。
因为kobject在sysfs中就是映射成一个文件夹。
添加删除kobject的示例代码如下:
/******************************************************************************
* @file : test_kobject.c
* @author : wuzhihang
* @date :
*
* @brief : 测试 kobject的创建和删除
* history : init
******************************************************************************/ #include<linux/init.h>
#include<linux/module.h>
#include<linux/kernel.h>
#include<linux/kobject.h> MODULE_LICENSE("Dual BSD/GPL"); struct kobject* kobj = NULL; static int test_kobject_init(void)
{
/* 初始化kobject,并加入到sysfs中 */
kobj = kobject_create_and_add("test_kobject", NULL); /* 进入内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "test_kobject is inited!\n");
printk(KERN_ALERT "*************************\n"); return 0;
} static void test_kobject_exit(void)
{
/* 如果 kobj 不为空,则将其从sysfs中删除 */
if (kobj != NULL)
kobject_del(kobj);
/* 退出内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "test_kobject is exited!\n");
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "\n\n\n\n\n");
} module_init(test_kobject_init);
module_exit(test_kobject_exit);
对应的Makefile
# must complile on customize kernel
obj-m += mykobject.o
mykobject-objs := test_kobject.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
测试方法:(我使用的测试系统是:Centos6.5 x86)
[root@localhost test_kobject]# ll <-- 开始时只有2个文件,一个测试代码,一个Makefile
total 8
-rw-r--r-- 1 root root 533 Dec 24 09:44 Makefile
-rw-r--r-- 1 root root 908 Dec 24 09:44 test_kobject.c
[root@localhost test_kobject]# make <-- 编译用于测试的内核模块
make -C /usr/src/kernels/2.6.32-431.el6.i686 M=/home/wyb/chap17/test_kobject modules
make[1]: Entering directory `/usr/src/kernels/2.6.32-431.el6.i686'
CC [M] /home/wyb/chap17/test_kobject/test_kobject.o
LD [M] /home/wyb/chap17/test_kobject/mykobject.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/wyb/chap17/test_kobject/mykobject.mod.o
LD [M] /home/wyb/chap17/test_kobject/mykobject.ko.unsigned
NO SIGN [M] /home/wyb/chap17/test_kobject/mykobject.ko
make[1]: Leaving directory `/usr/src/kernels/2.6.32-431.el6.i686'
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
[root@localhost test_kobject]# ll <-- 编译后多出来的一个内核模块 ***.ko
total 100
-rw-r--r-- 1 root root 533 Dec 24 09:44 Makefile
-rw-r--r-- 1 root root 91902 Dec 24 09:54 mykobject.ko
-rw-r--r-- 1 root root 908 Dec 24 09:44 test_kobject.c
[root@localhost test_kobject]# ll /sys/ <-- 安装内核模块 mykobject.ko 之前的 sysfs结构
total 0
drwxr-xr-x 2 root root 0 Dec 24 09:28 block
drwxr-xr-x 17 root root 0 Dec 24 09:28 bus
drwxr-xr-x 40 root root 0 Dec 24 09:28 class
drwxr-xr-x 4 root root 0 Dec 24 09:28 dev
drwxr-xr-x 12 root root 0 Dec 24 09:28 devices
drwxr-xr-x 4 root root 0 Dec 24 09:28 firmware
drwxr-xr-x 3 root root 0 Dec 24 09:28 fs
drwxr-xr-x 2 root root 0 Dec 24 09:44 hypervisor
drwxr-xr-x 5 root root 0 Dec 24 09:28 kernel
drwxr-xr-x 84 root root 0 Dec 24 09:46 module
drwxr-xr-x 2 root root 0 Dec 24 09:44 power
[root@localhost test_kobject]# insmod mykobject.ko <-- 安装内核模块
[root@localhost test_kobject]# ll /sys/ <-- 安装后,sysfs中多了一个文件夹 test_kobject
total 0
drwxr-xr-x 2 root root 0 Dec 24 09:28 block
drwxr-xr-x 17 root root 0 Dec 24 09:28 bus
drwxr-xr-x 40 root root 0 Dec 24 09:28 class
drwxr-xr-x 4 root root 0 Dec 24 09:28 dev
drwxr-xr-x 12 root root 0 Dec 24 09:28 devices
drwxr-xr-x 4 root root 0 Dec 24 09:28 firmware
drwxr-xr-x 3 root root 0 Dec 24 09:28 fs
drwxr-xr-x 2 root root 0 Dec 24 09:44 hypervisor
drwxr-xr-x 5 root root 0 Dec 24 09:28 kernel
drwxr-xr-x 85 root root 0 Dec 24 09:54 module
drwxr-xr-x 2 root root 0 Dec 24 09:44 power
drwxr-xr-x 2 root root 0 Dec 24 09:55 test_kobject
[root@localhost test_kobject]# ll /sys/test_kobject/ <-- 追加kobject只能增加文件夹,文件夹中是没有文件的
total 0
[root@localhost test_kobject]# rmmod mykobject.ko <-- 卸载内核模块
[root@localhost test_kobject]# ll /sys/ <-- 卸载后,sysfs 中的文件夹 test_kobject 也消失了
total 0
drwxr-xr-x 2 root root 0 Dec 24 09:28 block
drwxr-xr-x 17 root root 0 Dec 24 09:28 bus
drwxr-xr-x 40 root root 0 Dec 24 09:28 class
drwxr-xr-x 4 root root 0 Dec 24 09:28 dev
drwxr-xr-x 12 root root 0 Dec 24 09:28 devices
drwxr-xr-x 4 root root 0 Dec 24 09:28 firmware
drwxr-xr-x 3 root root 0 Dec 24 09:28 fs
drwxr-xr-x 2 root root 0 Dec 24 09:44 hypervisor
drwxr-xr-x 5 root root 0 Dec 24 09:28 kernel
drwxr-xr-x 84 root root 0 Dec 24 09:55 module
drwxr-xr-x 2 root root 0 Dec 24 09:44 power
4.1.2. sysfs中添加文件
kobject是映射成sysfs中的目录,那sysfs中的文件是什么呢?
其实sysfs中的文件就是kobject的属性,属性的来源有2个:
+ 默认属性 :: kobject所关联的ktype中的 default_attrs 字段
默认属性 default_attrs 的类型是结构体 struct attribute, 定义在 <linux/sysfs.h>
struct attribute {
const char *name; /* sysfs文件树中的文件名 */
struct module *owner; /* x86体系结构中已经不再继续使用了,可能在其他体系结构中还会使用 */
mode_t mode; /* sysfs中该文件的权限 */
};
ktype中的 default_attrs 字段(即默认属性)描述了sysfs中的文件,还有一个字段 sysfs_ops 则描述了如何使用默认属性。
struct sysfs_ops 的定义也在 <linux/sysfs.h>
struct sysfs_ops {
/* 在读sysfs文件时该方法被调用 */
ssize_t (*show)(struct kobject *kobj, struct attribute *attr,char *buffer);
/* 在写sysfs文件时该方法被调用 */
ssize_t (*store)(struct kobject *kobj,struct attribute *attr,const char *buffer, size_t size);
};
show 方法在读取sysfs中文件时调用,它会拷贝attr提供的属性到buffer指定的缓冲区
store 方法在写sysfs中文件时调用,它会从buffer中读取size字节的数据到attr提供的属性中
增加默认属性的示例代码
/******************************************************************************
* @file : test_kobject_default_attr.c
* @author : wuzhihang
* @date :
*
* @brief : 测试 kobject 的默认属性的创建和删除
* history : init
******************************************************************************/ #include<linux/init.h>
#include<linux/module.h>
#include<linux/kernel.h>
#include<linux/kobject.h>
#include<linux/sysfs.h> MODULE_LICENSE("Dual BSD/GPL"); static void myobj_release(struct kobject*);
static ssize_t my_show(struct kobject *, struct attribute *, char *);
static ssize_t my_store(struct kobject *, struct attribute *, const char *, size_t); /* 自定义的结构体,2个属性,并且嵌入了kobject */
struct my_kobj
{
int ival;
char* cname;
struct kobject kobj;
}; static struct my_kobj *myobj = NULL; /* my_kobj 的属性 ival 所对应的sysfs中的文件,文件名 val */
static struct attribute val_attr = {
.name = "val",
.owner = NULL,
.mode = 0666,
}; /* my_kobj 的属性 cname 所对应的sysfs中的文件,文件名 name */
static struct attribute name_attr = {
.name = "name",
.owner = NULL,
.mode = 0666,
}; static int test_kobject_default_attr_init(void)
{
struct attribute *myattrs[] = {NULL, NULL, NULL};
struct sysfs_ops *myops = NULL;
struct kobj_type *mytype = NULL; /* 初始化 myobj */
myobj = kmalloc(sizeof(struct my_kobj), GFP_KERNEL);
if (myobj == NULL)
return -ENOMEM; /* 配置文件 val 的默认值 */
myobj->ival = 100;
myobj->cname = "test"; /* 初始化 ktype */
mytype = kmalloc(sizeof(struct kobj_type), GFP_KERNEL);
if (mytype == NULL)
return -ENOMEM; /* 增加2个默认属性文件 */
myattrs[0] = &val_attr;
myattrs[1] = &name_attr; /* 初始化ktype的默认属性和析构函数 */
mytype->release = myobj_release;
mytype->default_attrs = myattrs; /* 初始化ktype中的 sysfs */
myops = kmalloc(sizeof(struct sysfs_ops), GFP_KERNEL);
if (myops == NULL)
return -ENOMEM; myops->show = my_show;
myops->store = my_store;
mytype->sysfs_ops = myops; /* 初始化kobject,并加入到sysfs中 */
memset(&myobj->kobj, 0, sizeof(struct kobject)); /* 这一步非常重要,没有这一步init kobject会失败 */
if (kobject_init_and_add(&myobj->kobj, mytype, NULL, "test_kobj_default_attr"))
kobject_put(&myobj->kobj); printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "test_kobject_default_attr is inited!\n");
printk(KERN_ALERT "*************************\n"); return 0;
} static void test_kobject_default_attr_exit(void)
{
kobject_del(&myobj->kobj);
kfree(myobj); /* 退出内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "test_kobject_default_attr is exited!\n");
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "\n\n\n\n\n");
} static void myobj_release(struct kobject *kobj)
{
printk(KERN_ALERT, "release kobject");
kobject_del(kobj);
} /* 读取属性文件 val 或者name时会执行此函数 */
static ssize_t my_show(struct kobject *kboj, struct attribute *attr, char *buf)
{
printk(KERN_ALERT "SHOW -- attr-name: [%s]\n", attr->name);
if (strcmp(attr->name, "val") == 0)
return sprintf(buf, "%d\n", myobj->ival);
else
return sprintf(buf, "%s\n", myobj->cname);
} /* 写入属性文件 val 或者name时会执行此函数 */
static ssize_t my_store(struct kobject *kobj, struct attribute *attr, const char *buf, size_t len)
{
printk(KERN_ALERT "STORE -- attr-name: [%s]\n", attr->name);
if (strcmp(attr->name, "val") == 0)
sscanf(buf, "%d\n", &myobj->ival);
else
sscanf(buf, "%s\n", myobj->cname);
return len;
} module_init(test_kobject_default_attr_init);
module_exit(test_kobject_default_attr_exit);
对应的Makefile如下:
# must complile on customize kernel
obj-m += mykobject_with_default_attr.o
mykobject_with_default_attr-objs := test_kobject_default_attr.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
测试方法:(我使用的测试系统是:ubuntu x86)
############################ 编译 ########################################################
[root@localhost test_kobject_defalt_attr]# ll
total 8
-rw-r--r-- 1 root root 582 Dec 24 15:02 Makefile
-rw-r--r-- 1 root root 4032 Dec 24 16:58 test_kobject_default_attr.c
[root@localhost test_kobject_defalt_attr]# make
make -C /usr/src/kernels/2.6.32-431.el6.i686 M=/home/wzh/chap17/test_kobject_defalt_attr modules
make[1]: Entering directory `/usr/src/kernels/2.6.32-431.el6.i686'
CC [M] /home/wzh/chap17/test_kobject_defalt_attr/test_kobject_default_attr.o
/home/wzh/chap17/test_kobject_defalt_attr/test_kobject_default_attr.c: In function ‘myobj_release’:
/home/wzh/chap17/test_kobject_defalt_attr/test_kobject_default_attr.c:109: warning: too many arguments for format
LD [M] /home/wzh/chap17/test_kobject_defalt_attr/mykobject_with_default_attr.o
Building modules, stage 2.
MODPOST 1 modules
CC /home/wzh/chap17/test_kobject_defalt_attr/mykobject_with_default_attr.mod.o
LD [M] /home/wzh/chap17/test_kobject_defalt_attr/mykobject_with_default_attr.ko.unsigned
NO SIGN [M] /home/wzh/chap17/test_kobject_defalt_attr/mykobject_with_default_attr.ko
make[1]: Leaving directory `/usr/src/kernels/2.6.32-431.el6.i686'
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
[root@localhost test_kobject_defalt_attr]# ll
total 104
-rw-r--r-- 1 root root 582 Dec 24 15:02 Makefile
-rw-r--r-- 1 root root 96805 Dec 24 16:58 mykobject_with_default_attr.ko
-rw-r--r-- 1 root root 4032 Dec 24 16:58 test_kobject_default_attr.c ############################ 安装 ########################################################
[root@localhost test_kobject_defalt_attr]# insmod mykobject_with_default_attr.ko
[root@localhost test_kobject_defalt_attr]# ll /sys/ <-- kobject对应的文件夹
total 0
drwxr-xr-x 2 root root 0 Dec 24 15:50 block
drwxr-xr-x 17 root root 0 Dec 24 15:50 bus
drwxr-xr-x 40 root root 0 Dec 24 15:50 class
drwxr-xr-x 4 root root 0 Dec 24 15:50 dev
drwxr-xr-x 12 root root 0 Dec 24 15:50 devices
drwxr-xr-x 4 root root 0 Dec 24 15:50 firmware
drwxr-xr-x 3 root root 0 Dec 24 15:50 fs
drwxr-xr-x 2 root root 0 Dec 24 16:06 hypervisor
drwxr-xr-x 5 root root 0 Dec 24 15:50 kernel
drwxr-xr-x 85 root root 0 Dec 24 16:59 module
drwxr-xr-x 2 root root 0 Dec 24 16:06 power
drwxr-xr-x 2 root root 0 Dec 24 16:59 test_kobj_default_attr
[root@localhost test_kobject_defalt_attr]# ll /sys/test_kobj_default_attr/ <-- kobject的2个属性文件
total 0
-rw-rw-rw- 1 root root 4096 Dec 24 16:59 name
-rw-rw-rw- 1 root root 4096 Dec 24 16:59 val
[root@localhost test_kobject_defalt_attr]# dmesg <-- dmesg 中只有初始化的信息
*************************
test_kobject_default_attr is inited!
************************* ############################ 读取属性文件 ###############################################
[root@localhost test_kobject_defalt_attr]# cat /sys/test_kobj_default_attr/val <-- 属性值就是我们在测试代码中输入的值
100
[root@localhost test_kobject_defalt_attr]# cat /sys/test_kobj_default_attr/name <-- 属性值就是我们在测试代码中输入的值
test
[root@localhost test_kobject_defalt_attr]# dmesg <-- dmesg 中多了2条读取属性文件的log
SHOW -- attr-name: [val]
SHOW -- attr-name: [name] ############################ 写入属性文件 ################################################
[root@localhost test_kobject_defalt_attr]# echo "200" > /sys/test_kobj_default_attr/val <-- val文件中写入 200
[root@localhost test_kobject_defalt_attr]# echo "abcdefg" > /sys/test_kobj_default_attr/name <-- name文件中写入 adcdefg
[root@localhost test_kobject_defalt_attr]# dmesg <-- dmesg 中又多了2条写入属性文件的log
STORE -- attr-name: [val]
STORE -- attr-name: [name]
[root@localhost test_kobject_defalt_attr]# cat /sys/test_kobj_default_attr/val <-- 再次查看 val文件中的值,已变为200
200
[root@localhost test_kobject_defalt_attr]# cat /sys/test_kobj_default_attr/name <-- 再次查看 name文件中的值,已变为abcdefg
abcdefg ############################ 卸载 ########################################################
[root@localhost test_kobject_defalt_attr]# rmmod mykobject_with_default_attr.ko
注:参考博客 Linux设备模型 (2)
+ 新属性 :: kobject 自己定义的属性
一般来说,使用默认属性就足够了。因为具有共同ktype的kobject在本质上区别都不大,比如都是块设备的kobject,
它们使用默认的属性集合不但可以让事情简单,有助于代码合并,还可以使类似的对象在sysfs中的外观一致。
在一些特殊的情况下,kobject可能会需要自己特有的属性。内核也充分考虑到了这些情况,提供了创建或者删除新属性的方法。
在sysfs中文件的操作方法参见: fs/sysfs/file.c
/* 文件的相关操作非常多,这里只列出创建文件和删除文件的方法 */ /**
* 给 kobj 增加一个新的属性 attr
* kobj 对应sysfs中的一个文件夹, attr 对应sysfs中的一个文件
*/
int sysfs_create_file(struct kobject * kobj, const struct attribute * attr)
{
BUG_ON(!kobj || !kobj->sd || !attr); return sysfs_add_file(kobj->sd, attr, SYSFS_KOBJ_ATTR); } /**
* 给 kobj 删除一个新的属性 attr
* kobj 对应sysfs中的一个文件夹, attr 对应sysfs中的一个文件
*/
void sysfs_remove_file(struct kobject * kobj, const struct attribute * attr)
{
sysfs_hash_and_remove(kobj->sd, attr->name);
}
除了可以在sysfs中增加/删除的文件,还可以在sysfs中增加或者删除一个符号链接。
具体实现参见:fs/sysfs/symlink.c
/* 下面只列出了创建和删除符号链接的方法,其他方法请参考 symlink.c 文件 */ /**
* 在kobj对应的文件夹中创建一个符号链接指向 target
* 符号链接的名称就是 name
*/
int sysfs_create_link(struct kobject *kobj, struct kobject *target,
const char *name)
{
return sysfs_do_create_link(kobj, target, name, 1);
} void sysfs_remove_link(struct kobject * kobj, const char * name)
{
struct sysfs_dirent *parent_sd = NULL; if (!kobj)
parent_sd = &sysfs_root;
else
parent_sd = kobj->sd; sysfs_hash_and_remove(parent_sd, name);
}
增加新的属性的示例代码 (这里只演示了增加文件的方法,增加符号链接的方法与之类似)
/******************************************************************************
* @file : test_kobject_new_attr.c
* @author : wangyubin
* @date : Tue Dec 24 17:10:31 2013
*
* @brief : 测试 kobject 中增加和删除新属性
* history : init
******************************************************************************/ #include<linux/init.h>
#include<linux/module.h>
#include<linux/kernel.h>
#include<linux/kobject.h>
#include<linux/sysfs.h> MODULE_LICENSE("Dual BSD/GPL"); static void myobj_release(struct kobject*);
static ssize_t my_show(struct kobject *, struct attribute *, char *);
static ssize_t my_store(struct kobject *, struct attribute *, const char *, size_t); /* 自定义的结构体,其中嵌入了kobject,通过属性 c_attr 来控制增加或者删除新属性 */
struct my_kobj
{
int c_attr; /* 值为0:删除新属性, 值为1:增加新属性*/
int new_attr;
struct kobject kobj;
}; static struct my_kobj *myobj = NULL; /* my_kobj 的属性 c_attr 所对应的sysfs中的文件,文件名 c_attr */
static struct attribute c_attr = {
.name = "c_attr",
.owner = NULL,
.mode = 0666,
}; /* 用于动态增加或者删除的新属性 */
static struct attribute new_attr = {
.name = "new_attr",
.owner = NULL,
.mode = 0666,
}; static int test_kobject_new_attr_init(void)
{
struct attribute *myattrs[] = {NULL, NULL};
struct sysfs_ops *myops = NULL;
struct kobj_type *mytype = NULL; /* 初始化 myobj */
myobj = kmalloc(sizeof(struct my_kobj), GFP_KERNEL);
if (myobj == NULL)
return -ENOMEM; /* 配置文件 val 的默认值 */
myobj->c_attr = 0; /* 初始化 ktype */
mytype = kmalloc(sizeof(struct kobj_type), GFP_KERNEL);
if (mytype == NULL)
return -ENOMEM; /* 增加1个默认属性文件 */
myattrs[0] = &c_attr; /* 初始化ktype的默认属性和析构函数 */
mytype->release = myobj_release;
mytype->default_attrs = myattrs; /* 初始化ktype中的 sysfs */
myops = kmalloc(sizeof(struct sysfs_ops), GFP_KERNEL);
if (myops == NULL)
return -ENOMEM; myops->show = my_show;
myops->store = my_store;
mytype->sysfs_ops = myops; /* 初始化kobject,并加入到sysfs中 */
memset(&myobj->kobj, 0, sizeof(struct kobject)); /* 这一步非常重要,没有这一步init kobject会失败 */
if (kobject_init_and_add(&myobj->kobj, mytype, NULL, "test_kobj_new_attr"))
kobject_put(&myobj->kobj); printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "test_kobject_new_attr is inited!\n");
printk(KERN_ALERT "*************************\n"); return 0;
} static void test_kobject_new_attr_exit(void)
{
kobject_del(&myobj->kobj);
kfree(myobj); /* 退出内核模块 */
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "test_kobject_new_attr is exited!\n");
printk(KERN_ALERT "*************************\n");
printk(KERN_ALERT "\n\n\n\n\n");
} static void myobj_release(struct kobject *kobj)
{
printk(KERN_ALERT "release kobject");
kobject_del(kobj);
} /* 读取属性文件 c_attr 或者 new_attr 时会执行此函数 */
static ssize_t my_show(struct kobject *kboj, struct attribute *attr, char *buf)
{
printk(KERN_ALERT "SHOW -- attr-name: [%s]\n", attr->name);
if (strcmp(attr->name, "c_attr") == 0)
return sprintf(buf, "%d\n", myobj->c_attr);
else if (strcmp(attr->name, "new_attr") == 0)
return sprintf(buf, "%d\n", myobj->new_attr); return 0;
} /* 写入属性文件c_attr 或者 new_attr 时会执行此函数 */
static ssize_t my_store(struct kobject *kobj, struct attribute *attr, const char *buf, size_t len)
{
printk(KERN_ALERT "STORE -- attr-name: [%s]\n", attr->name);
if (strcmp(attr->name, "c_attr") == 0)
sscanf(buf, "%d\n", &myobj->c_attr);
else if (strcmp(attr->name, "new_attr") == 0)
sscanf(buf, "%d\n", &myobj->new_attr); if (myobj->c_attr == 1) /* 创建新的属性文件 */
{
if (sysfs_create_file(kobj, &new_attr))
return -1;
else
myobj->new_attr = 100; /* 新属性文件的值默认设置为 100 */
} if (myobj->c_attr == 0) /* 删除新的属性文件 */
sysfs_remove_file(kobj, &new_attr); return len;
} module_init(test_kobject_new_attr_init);
module_exit(test_kobject_new_attr_exit);
对应的Makefile如下:
# must complile on customize kernel
obj-m += mykobject_with_new_attr.o
mykobject_with_new_attr-objs := test_kobject_new_attr.o #generate the path
CURRENT_PATH:=$(shell pwd)
#the current kernel version number
LINUX_KERNEL:=$(shell uname -r)
#the absolute path
LINUX_KERNEL_PATH:=/usr/src/kernels/$(LINUX_KERNEL)
#complie object
all:
make -C $(LINUX_KERNEL_PATH) M=$(CURRENT_PATH) modules
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c .tmp_versions *.unsigned
#clean
clean:
rm -rf modules.order Module.symvers .*.cmd *.o *.mod.c *.ko .tmp_versions *.unsigned
测试方法:(我使用的测试系统是:ubuntu x86)
根据测试代码,增加/删除新属性是根据默认属性 c_attr 的值来决定的。
c_attr 设置为0 时,删除新属性 new_attr
c_attr 设置为1 时,新增新属性 new_attr
############################ 编译,安装,卸载同测试默认属性时一样 #######################
... 省略 ...
############################ 动态增加新属性文件 #########################################
[root@localhost test_kobject_new_attr]# ll /sys/test_kobj_new_attr/ <-- 默认没有新属性 new_attr
total 0
-rw-rw-rw- 1 root root 4096 Dec 24 18:47 c_attr
[root@localhost test_kobject_new_attr]# cat /sys/test_kobj_new_attr/c_attr <-- c_attr 的值为0
0
[root@localhost test_kobject_new_attr]# echo "1" > /sys/test_kobj_new_attr/c_attr <-- c_attr 的值设为1
[root@localhost test_kobject_new_attr]# ll /sys/test_kobj_new_attr/ <-- 增加了新属性 new_attr
total 0
-rw-rw-rw- 1 root root 4096 Dec 24 19:02 c_attr
-rw-rw-rw- 1 root root 4096 Dec 24 19:02 new_attr ############################ 动态删除属性文件 ###########################################
[root@localhost test_kobject_new_attr]# echo "0" > /sys/test_kobj_new_attr/c_attr <-- c_attr 的值为0
[root@localhost test_kobject_new_attr]# ll /sys/test_kobj_new_attr/ <-- 删除了新属性 new_attr
total 0
-rw-rw-rw- 1 root root 4096 Dec 24 19:03 c_attr
4.1.3. sysfs相关约定
为了保持sysfs的干净和直观,在内核开发中涉及到sysfs相关内容时,需要注意以下几点:
+ sysfs属性保证每个文件只导出一个值,该值为文本形式并且可以映射为简单的C类型
+ sysfs中要以一个清晰的层次组织数据
+ sysfs提供内核到用户空间的服务
4.2 基于sysfs的内核事件
内核事件层也是利用kobject和sysfs来实现的,用户空间通过监控sysfs中kobject的属性的变化来异步的捕获内核中kobject发出的信号。
用户空间可以通过一种netlink的机制来获取内核事件。
内核空间向用户空间发送信号使用 kobject_uevent() 函数,具体参见: <linux/kobject.h>
int kobject_uevent(struct kobject *kobj, enum kobject_action action);
下面用个小例子演示一些内核事件的实现原理:
4.2.1. 内核模块安装或者删除时,会发送 KOBJ_ADD 或者 KOBJ_REMOVE 的消息
内核模块的代码就用上面最简单的那个例子 test_kobject.c 的代码即可
4.2.2. 用户态程序: 通过 netlink机制来接收 kobject 的事件通知
/******************************************************************************
* @file : test_netlink_client.c
* @author : wuzhihang
* @date :
*
* @brief : 通过 netlink机制接收kobject发出的信号
* history : init
******************************************************************************/ #include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <sys/types.h>
#include <asm/types.h>
#include <sys/socket.h>
#include <linux/netlink.h> void MonitorNetlinkUevent()
{
int sockfd;
struct sockaddr_nl sa;
int len;
char buf[4096];
struct iovec iov;
struct msghdr msg;
int i; memset(&sa,0,sizeof(sa));
sa.nl_family = AF_NETLINK;
sa.nl_groups = NETLINK_KOBJECT_UEVENT;
sa.nl_pid = 0;//getpid(); both is ok
memset(&msg,0,sizeof(msg));
iov.iov_base = (void *)buf;
iov.iov_len = sizeof(buf);
msg.msg_name = (void *)&sa;
msg.msg_namelen = sizeof(sa);
msg.msg_iov = &iov;
msg.msg_iovlen = 1; sockfd = socket(AF_NETLINK, SOCK_RAW, NETLINK_KOBJECT_UEVENT);
if(sockfd == -1)
printf("socket creating failed:%s\n",strerror(errno));
if(bind(sockfd,(struct sockaddr *)&sa,sizeof(sa)) == -1)
printf("bind error:%s\n", strerror(errno));
while(1) {
memset(buf, 0, sizeof(buf));
len=recvmsg(sockfd, &msg, 0);
if(len < 0){}
//printf("receive error\n");
else if(len < 32||len > sizeof(buf))
printf("invalid message");
for(i=0; i<len; i++)
if(*(buf+i) == '\0')
buf[i] = '\n';
printf("received %d bytes\n%s\n", len, buf);
}
} int main(int argc, char *argv[])
{
MonitorNetlinkUevent();
return 0;
}
注:代码是拷贝的 《Linux设备节点创建》内核kobject上报uevent过滤规则 中的用户态程序部分
4.2.3. 测试方法:(我使用的测试系统是:ubuntu x86)
############################ 编译并启动用户态程序 (窗口1)###################################
[root@localhost test_kobject_event]# ll
total 4
-rw-r--r-- 1 root root 1846 Dec 24 20:36 test_netlink_client.c
[root@localhost test_kobject_event]# gcc -o test_netlink_client test_netlink_client.c <-- 编译用户态程序
[root@localhost test_kobject_event]# ./test_netlink_client <-- 启动后等待内核kobject的事件到来 ############################ 安装内核模块并查看用户态程序输出 (窗口2)#######################
[root@localhost test_kobject]# insmod mykobject.ko <-- 在窗口2中安装内核模块,窗口1中会接收到 KOBJ_ADD 信号
############################ 卸载内核模块并查看用户态程序输出 (窗口2)#######################
[root@localhost test_kobject]# rmmod mykobject.ko <-- 在窗口2中安装内核模块,窗口1中会接收到 KOBJ_REMOVE 信号
5. 总结
kobject加sysfs给内核带来的好处不是三言两语能够说得清楚的,上面的例子也只是通过简单的使用来直观的感受一下kobject,例子本身没有什么实际意义。
最后一个例子中使用了 netlink机制,我在之前的项目中使用过netlink来监控系统进程的I/O信息,对netlink有一些初步的了解。
但是例子中只是用来获取一下 kobject的事件而已,这里主要为了说明kobject,netlink的相关内容以后有机会再补充。
内核调试
内核调试的难点在于它不能像用户态程序调试那样打断点,随时暂停查看各个变量的状态。也不能像用户态程序那样崩溃后迅速的重启,恢复初始状态。用户态程序和内核交互,用户态程序的各种状态,错误等可以由内核来捕获并显示。而内核是直接和硬件交互的,内核出错之后整个系统就无法正常运行了,所以要想熟练的进行内核调试,首先要熟悉内核已经给我们提供的工具,然后实实在在的去做一些内核功能的开发,在开发的过程中不断熟悉内核代码,增加内核调试的经验。
主要内容:
- 内核调试的难点
- 内核调试的工具和方法
- 总结
1. 内核调试的难点
内核调试的难点大致有以下几个:
- 重现bug困难 - 如果能够重现一个bug, 相当于成功了一半. (特别是有些bug和硬件相关, 执行几百万次之后才有一次错误)
- 调试风险比较大 - 稍有不慎, 即造成系统崩溃
- 定位bug的初始版本困难 - 内核版本更新很快, 很难确定bug是在那个版本开始出现的
2. 内核调试的工具和方法
内核调试虽然困难, 但同时也极具挑战性, 如果能够解决一个困扰大家多时的内核bug, 那将会给自己带来极大的成就感. :)
而且, 随着内核的不断发展, 内核调试的手段和方法也在不断进步, 下面是书中提到的一些常用的调试手段.
2.1 输出 LOG
输出LOG不光是内核调试, 即使是在用户态程序的调试中, 也是经常使用的一个调试手段.
通过在可疑的代码周围加上一些LOG输出, 可以准确的了解bug发生前后的一些重要信息.
2.1.1 LOG等级
linux内核中输出LOG的函数是 printk (语法和printf几乎雷同, 唯一的区别是printk可以指定日志级别)
printk之所以好用, 就在与它随时都可以被调用, 没有任何限制条件.
printk的输出日志级别如下:
|
等级 |
描述 |
| KERN_EMERG | 一个紧急情况 |
| KERN_ALERT | 一个需要立即被注意到的错误 |
| KERN_CRIT | 一个临界情况 |
| KERN_ERR | 一个错误 |
| KERN_WARNING | 一个警告 |
| KERN_NOTICE | 一个普通的, 不过也有可能需要注意的情况 |
| KERN_INFO | 一条非正式的消息 |
| KERN_DEBUG | 一条调试信息--一般是冗余信息 |
输出示例:
printk(KERN_WARNING "This is a warning!\n");
printk(KERN_DEBUG "This is a debug notice!\n");
2.1.2 LOG记录
标准linux系统上, printk 输出log之后, 由用户空间的守护进程klogd从缓冲区中读取内核消息, 然后再通过syslogd守护进程将它们保存在系统日志文件中.
syslogd 将接受到的所有内核消息添加到一个文件中, 该文件默认为: /var/log/dmesg (系统Centos6.4 x86_64)
PS. 上篇博客中的内核模块的输出LOG, 都可以在 /var/log/dmesg 中看到
2.2 oops
oopss是个拟声词, 类似 "哎哟" 的意思. 它是内核通知用户有不幸发生的最常用方式.
触发一个oops很简单, 其实只要在上篇博客中的那些内核模块示例中随便找一个, 里面加上一段给未初始化的指针赋值的代码, 就能触发一个oops
oops中包含错误发生时的一些重要信息(比如, 寄存器上下文和回溯线索), 对调试bug很有帮助!
调试内核时, 还可以开启内核编译参数中的各种和内核调试相关的选项, 那样还可以给我们提供内核崩溃时的一些额外信息.
2.3 主动触发bug
调试中有时将某些情况下标记为bug, 执行到这些情况时, 提供断言并输出信息.
BUG 和 BUG_ON 就是2个可以主动触发oops的内核调用.
在不应该被执行到的地方使用 BUG 或者 BUG_ON 来捕获.
比如:
if (bad_thing)
BUG();
// 或者
BUG_ON(bad_thing);
如果想要触发更为严重的错误, 可以使用 panic() 函数
比如:
if (terrible_thing)
panic("terrible thing is %ld\n", terrible_thing);
此外, 还有dump_stack 函数可以打印寄存器上下文和回溯信息.
比如:
if (!debug_check) {
printk(KERN_DEBUG "provide some information...\n");
dump_statck();
}
2.4 神奇的系统请求键
这个系统请求键之所以神奇, 在于它可以在一个快挂了的系统上输出一些有用的信息.
这个按键一般就是标准键盘上的 [SysRq] 键 (就在 F12 键右边, 其实就是windows中截整个屏幕的按键)
单独按那个键相当于截屏, 按住 ALT + [SysRq] = [SysRq]的功能
启用这个键的功能有2个方法:
- 开启内核编译选项 : CONFIG_MAGIC_SYSRQ
- 动态启用: echo 1 > /proc/sys/kernel/sysrq
支持 SysRq 的命令如下: (注意要在控制台界面下使用这个键, 比如通过 ALT+CTRL+F2 进入一个控制台界面)
|
主要命令 |
描述 |
| SysRq-b | 重新启动机器 |
| SysRq-e | 向init以外的所有进程发送SIGTERM信号 |
| SysRq-h | 在控制台显示SysRq的帮助信息 |
| SysRq-i | 向init以外的所有进程发送SIGKILL信号 |
| SysRq-k | 安全访问键:杀死这个控制台上的所有程序 |
| SysRq-l | 向包括init的所有进程发送SIGKILL信号 |
| SysRq-m | 把内存信息输出到控制台 |
| SysRq-o | 关闭机器 |
| SysRq-p | 把寄存器信息输出到控制台 |
| SysRq-r | 关闭键盘原始模式 |
| SysRq-s | 把所有已安装文件系统都刷新到磁盘 |
| SysRq-t | 把任务信息输出到控制台 |
| SysRq-u | 卸载所有已加载文件系统 |
2.5 内核调试器 gdb和kgdb
linux内核的调试器可以使用 gdb或者kgdb, 配置比较麻烦, 准备实际用调试的时候再去试试效果如何..
2.6 探测系统
下面一些方法是在修改内核后, 用来试探内核反应的小技巧.
2.6.1 用UID控制内核执行
比如在内核中加入了新的特性, 为了测试特性, 可以用UID来控制内核是否执行新特性.
if (current->uid != 7777) {
/* 原先的代码 */
} else {
/* 新的特性 */
}
2.6.2 用条件变量控制内核执行
也可以设置一些条件变量来控制内核是否执行某段代码.
条件变量可以像上篇博客中那样, 设置在 sys 文件系统的某个文件中. 当文件中的值变化时, 通知内核执行相应的代码.
2.6.3 使用统计量观察内核执行某段代码的频率
实现思路就是在内核中的设置一个全局变量, 比如 my_count, 当内核执行到某段代码时, 给 my_count + 1 就行.
同时还要将 my_count 打印出来(可以用printk), 便于随时查看它的值.
2.6.4 控制内核执行某段代码的频率
有时侯, 我们需要在内核发生错误时打印错误相关的信息, 如果这个错误不会导致内核崩溃, 并且这个错误每秒会发生几百次甚至更多.
那么, 用printk输出的信息会非常多, 给系统造成额外的负担.
这时, 我们就需要想办法控制错误输出的频率, 有2种方法:
方法1: 隔一段时间才输出一次错误
static unsigned long prev_jiffy = jiffies; /* 频率限制 */
if (time_after(jiffies, prev_jiffy + 2*HZ)) { /* 输出间隔至少 2HZ */
prev_jiffy = jiffies;
printk(KERN_ERR "错误信息....\n");
}
方法2: 输出 N 次之后, 不再输出(N是正整数)
static unsigned long limit = 0;
if (limit < 5) { /* 输出5次错误信息后就不再输出 */
limit++;
printk(KERN_ERR "错误信息....\n");
}
2.7 二分法查找bug发生的最初内核版本
在内核发生了bug之后, 如果能够知道是bug从哪个内核版本开始出现的, 那对修正这个bug会有很大的帮助.
由于内核代码非常庞大, 即使用二分查找法, 手工去找哪个版本开始出现bug的话, 仍然是非常耗时和繁琐的.
好在 Git 给我们提供了一个非常有用的二分搜索机制.
git bisect start # 开始二分搜索
git bisect bad <bad_revision> # 指定一个bug出现的内核版本号
git bisect good <good_revision> # 指定一个没有bug的内核版本号, 此时git会检测2个版本直接的隐患 # 根据结果再次设置 bad 和 good 的版本号, 缩小Git检索范围, 直至找到可疑之处为止.
2.8 社区
当你在调试bug时用尽了一切手段仍然无济于事时, 可以考虑求助linux社区, 求助时注意一定要描述清楚bug的状况.
(可以参考一下别人汇报bug的格式)
linux 内核相关的邮件列表非常多: 参见 http://vger.kernel.org/vger-lists.html
和内核开发, bug汇报相关的邮件列表参见: http://vger.kernel.org/vger-lists.html#linux-kernel (这个邮件列表非常活跃, 每天的邮件都非常多!!!)
3. 总结
linux内核调试必须要依靠大量的实践来掌握, 仅仅靠上面介绍的一些技巧还远远不够, 只有实实在在的去阅读内核代码, 实实在在的去修正一个个bug, 才算真正掌握内核, 真正了解内核.
多看看之前linux内核bug的修正案例, 也是个不错的积累经验的方法.
PS.
对于初学者来说, 在真机上做内核开发动辄导致机器崩溃(panic), 非常麻烦. 现在的虚拟机这么强大, 建议都在虚拟机上测试linux内核修改的效果.
我之前的关于<<Linux内核设计与实现>>笔记的博客中的代码都是在虚拟机上运行测试的.
可移植性
linux内核的移植性非常好, 目前的内核也支持非常多的体系结构(有20多个).
但是刚开始时, linux也只支持 intel i386 架构, 从 v1.2版开始支持 Digital Alpha, Intel x86, MIPS和SPARC(虽然支持的还不是很完善).
从 v2.0版本开始加入了对 Motorala 68K和PowerPC的官方支持, v2.2版本开始新增了 ARMS, IBM S390和UltraSPARC的支持.
v2.4版本支持的体系结构数达到了15个, v2.6版本支持的体系结构数目提高到了21个.
目前的我使用的系统是 Fedora20, 支持的体系结构有31个之多.(源码树中 arch目录下有支持的体系结构, 每种体系结构一个文件夹)
考虑到内核支持如此之多的架构, 在内核开发的时候就需要考虑编码的可移植性.
提高可移植性最重要的就是要搞明白不同体系结构之间究竟是什么对移植代码的影响比较大.
主要内容:
- 字长
- 数据类型
- 数据对齐
- 字节顺序
- 时间
- 页长度
- 处理器顺序
- SMP, 内核抢占, 高端内存
- 总结
1. 字长
这里的字是指处理器能够一次完成处理的数据. 字长即使处理器能够一次完成处理的数据的最大长度.
目前的处理器主要有32位和64为2种, 注意这里的32位和64位并不是指操作系统的版本, 而是指处理器的能力.
一般来说, 32位的处理器只能安装32位的操作系统, 而64位的处理器可以安装32位的操作系统, 也可以安装64位的操作系统.
对于一种体系结构来说, 处理器通用寄存器(general-purpose registers, GPR)的大小和它的字长是相同的.
C语言定义的long类型总是对等于机器的字长, 而int型有时会比字长小.
- 32位的体系结构中, int型和long型都是32位的
- 64位的体系结构中, int型是32位的, long型是64位的.
内核编码中涉及到字长的部分时, 牢记以下准则:
- ANSI C标准规定, 一个char的长度一定是一个字节(8位)
- linux当前所支持的体系结构中, int型都是32位的
- linux当前所支持的体系结构中, short型都是16位的
- linux当前所支持的体系结构中, 指针和long型的长度不定, 在32位和64位中变化
- 不能假设 sizeof(int) == sizeof(long)
- 类似的, 不能假定 指针的长度和int型相同.
此外, 操作系统有个简单的助记符来描述此系统中数据类型的大小.
- LLP64 :: 64位的Windows, long类型和指针都是64位
- LP64 :: 64位的Linux, long类型和指针都是64位
- ILP32 :: 32位的Linux, int类型, long类型和指针都是32位
- ILP64 :: int类型, long类型和指针都是64位(非Linux)
2. 数据类型
编写可移植性代码时, 内核中的数据类型有以下3点需要注意:
2.1 不透明类型
linux内核中定义了很多不透明类型, 它们是在C语言标准类型上的一个封装, 比如 pid_t, uid_t, gid_t 等等.
例如, pid_t的定义可以在源码中找到:
typedef __kernel_pid_t pid_t; /* include/linux/types.h */ typedef int __kernel_pid_t; /* arch/asm/include/asm/posix_types.h */
使用这些不透明类型时, 以下原则需要注意:
- 不要假设该类型的长度(那怕通过源码看到了它的C语言类型), 这些类型在不同体系结构中可能长度会变, 内核开发者也有可能修改它们
- 不要将这些不透明类型转换为C标准类型来使用
- 编程时保证不透明类型实际存储空间或者格式发生变化时代码不受影响
2.2 长度确定的类型
除了不透明类型, linux内核中还定义了一系列长度明确的数据类型, 参见 include/asm-generic/int-l64.h 或者 include/asm-generic/int-ll64.h
typedef signed char s8;
typedef unsigned char u8; typedef signed short s16;
typedef unsigned short u16; typedef signed int s32;
typedef unsigned int u32; typedef signed long s64;
typedef unsigned long u64;
上面这些类型只能在内核空间使用, 用户空间无法使用. 用户空间有对应的变量类型, 名称前多了2个下划线:
typedef __signed__ char __s8;
typedef unsigned char __u8; typedef __signed__ short __s16;
typedef unsigned short __u16; typedef __signed__ int __s32;
typedef unsigned int __u32; typedef __signed__ long __s64;
typedef unsigned long __u64;
2.3 char类型
之所以把char类型单独拿出来说明, 是因为char类型在不同的体系结构中, 有时默认是带符号的, 有时是不带符号的.
比如, 最简单的例子:
/*
* 某些体系结构中, char类型默认是带符号的, 那么下面 i 的值就为 -1
* 某些体系结构中, char类型默认是不带符号的, 那么下面 i 的值就为 255, 与预期可能有差别!!!
*/
char i = -1;
避免上述问题的方法就是, 给char类型赋值时, 明确是否带符号, 如下:
signed char i = -1; /* 明确 signed, i 的值在哪种体系结构中都是 -1 */
unsigned char i = 255; /* 明确 unsigned, i 的值在哪种体系结构中都是 255 */
3. 数据对齐
数据对齐也是增强可移植性的一个重要方面(有的体系结构对数据对齐要求非常严格, 载入未对齐的数据可导致性能下降, 甚至错误).
数据对齐的意思就是: 数据的内存地址可以被 4 整除
1. 通过指针转换类型时, 不要转换长度不一样的类型, 比如下面的代码有可能出错
/*
* 下面的代码将一个变量从 char 类型转换为 unsigned long 类型,
* char 类型只占 1个字节, 它的地址不一定能被4整除, 转换为 4个字节或者8个字节的 usigned long之后,
* 导致 unsigned long 出现数据不对齐的现象.
*/
char wolf[] = "Like a wolf";
char *p = &wolf[1];
unsigned long p1 = *(unsigned long*) p;
2. 对于数组, 安装基本数据类型进行对齐就行.(数组元素的存放在内存中是连续的, 第一个对齐了, 后面的都自动对齐了)
3. 对于联合体, 长度最大的数据对齐就可以了
4. 对于结构体, 保证结构体中每个元素能够正确对齐即可
如果结构体中的元素没有对齐, 编译器会自动填充结构体, 保证它是对齐的. 比如下面的代码, 预计应该输出12, 实际却输出了24
我的代码运行环境: ubuntu x86_64
/******************************************************************************
* @file : struct_align.c
* @author : wuzhihang
* @date : 2019-09-27
*
* @brief :
* history : init
******************************************************************************/ #include <stdio.h> struct animal_struct
{
char dog; /* 1个字节 */
unsigned long cat; /* 8个字节 */
unsigned short pig; /* 2个字节 */
char fox; /* 1个字节 */
}; int main(int argc, char *argv[])
{
/* 在我的64bit 系统中是按8位对齐, 下面的代码输出 24 */
printf ("sizeof(animal_struct)=%d\n", sizeof(struct animal_struct));
return 0;
}
测试方法:
gcc -o test struct_align.c
./test # 输出24
结构体应该被填充成如下形式:
struct animal_struct
{
char dog; /* 1个字节 */
/* 此处填充了7个字节 */
unsigned long cat; /* 8个字节 */
unsigned short pig; /* 2个字节 */
char fox; /* 1个字节 */
/* 此处填充了5个字节 */
};
通过调整结构体中元素顺序, 可以减少填充的字节数, 比如上述结构体如果定义成如下顺序:
struct animal_struct
{
unsigned long cat; /* 8个字节 */
unsigned short pig; /* 2个字节 */
char dog; /* 1个字节 */
char fox; /* 1个字节 */
};
那么为了保证8位对齐, 只需在后面补充 4位即可:
struct animal_struct
{
unsigned long cat; /* 8个字节 */
unsigned short pig; /* 2个字节 */
char dog; /* 1个字节 */
char fox; /* 1个字节 */
/* 此处填充了4个字节 */
};
调整后的代码会输出 16, 不是之前的24
#include <stdio.h> struct animal_struct
{
unsigned long cat; /* 8个字节 */
unsigned short pig; /* 2个字节 */
char dog; /* 1个字节 */
char fox; /* 1个字节 */
}; int main(int argc, char *argv[])
{
/* 在我的64bit 系统中是按8位对齐, 下面的代码输出 16 */
printf ("sizeof(animal_struct)=%d\n", sizeof(struct animal_struct));
return 0;
}
测试方法:
gcc -o test struct_align.c
./test # 输出16
注意: 虽然调整结构体中元素的顺序可以减少填充的字节, 从而降低内存的消耗.
但是对于内核中已有的那些结构, 千万不能随便调整其元素顺序, 因为内核中很多现存的方法都是通过元素在结构体中位置偏移来获取元素的.
4. 字节顺序
字节顺序其实只有2种:
- 低位优先 :: little-endian 数据由低位地址->高位地址存放
- 高位优先 :: big-endian 数据由高位地址->低位地址存放
比如占有四个字节的整数的二进制表示如下:
00000001 00000002 00000003 00000004
内存地址方向: 高位 <--------------------> 低位
little-endian 表示如下:
00000001 00000002 00000003 00000004
big-endian 表示如下:
00000004 00000003 00000002 00000001
判断一个体系结构是 big-endian 还是 little-endian 非常简单.
int x = 1; /* 二进制 00000000 00000000 00000000 00000001 */ /*
* 内存地址方向: 高位 <--------------------> 低位
* little-endian 表示: 00000000 00000000 00000000 00000001
* big-endian 表示: 00000001 00000000 00000000 00000000
*/
if (*(char *) &x == 1) /* 这句话把int型转为char型, 相当于只取了int型的最低8bit */
/* little-endian */
else
/* big-endian */
5. 时间
内核中使用到时间相关概念时, 为了提高可移植性, 不要使用时间中断的发生频率(也就是每秒产生的jiffies), 而应该使用 HZ 来正确使用时间.
关于 jiffies 和 HZ 的概念,上文有提哦
6. 页长度
当处理用页管理的内存时, 不要既定页的长度为 4KB, 在不同的体系结构中长度会不一样.
而应该使用 PAGE_SIZE 以字节数来表示页长度, 使用 PAGE_SHIFT 表示从最右端屏蔽了多少位能够得到该地址对应的页的页号.
PAGE_SIZE 和 PAGE_SHIFT 都是宏, 定义在 include/asm-generic/page.h 中
下表是一些体系结构中页长度:
|
体系结构 |
PAGE_SHIFT |
PAGE_SIZE |
| alpha | 13 | 8KB |
| arm | 12, 14, 15 | 4KB, 16KB, 32KB |
| avr | 12 | 4KB |
| cris | 13 | 8KB |
| blackfin | 12 | 16KB |
| h8300 | 14 | 4KB |
| 12 | 4KB, 8KB, 16KB, 32KB | |
| m32r | 12, 13, 14, 16 | 4KB |
| m68k | 12 | 4KB, 8KB |
| m68knommu | 12, 13 | 4KB |
| mips | 12 | 4KB |
| min10300 | 12 | 4KB |
| parisc | 12 | 4KB |
| powerpc | 12 | 4KB |
| s390 | 12 | 4KB |
| sh | 12 | 4KB |
| sparc | 12, 13 | 4KB, 8KB |
| um | 12 | 4KB |
| x86 | 12 | 4KB |
| xtensa | 12 | 4KB |
7. 处理器顺序
还有最后一个和可移植性相关的注意点就是处理器对代码的执行顺序, 在有些体系结构中, 处理器并不是严格按照代码编写的顺序执行的,
可能为了优化性能或者其他原因, 处理器执行指令的顺序与编写的代码的顺序稍有出入.
如果我们的某段代码需要严格的执行顺序, 需要在代码中使用 rmb() wmb() 等内存屏障来确保处理器的执行顺序.
8. SMP, 内核抢占, 高端内存
SMP, 内核抢占和高端内存本身虽然和可移植性没有太大的关系, 但它们都是内核中重要的配置选项,
如果编码时能够考虑到这些的话, 那么即使内核修改SMP等这些配置选项, 我们的代码仍然可以安全可靠的运行.
所以, 在编写内核代码时最好加上如下假设:
- 假设代码会在SMP系统上运行, 要正确选择和使用锁
- 假设代码会在支持内核抢占的情况下运行, 要正确使用锁和内核抢占语句
- 假设代码会运行在使用高端内存(非永久映射内存)的系统上, 必要时使用 kmap()
9. 总结
编写简洁, 可移植性的代码还需要通过实践来积累经验, 上面的准则可以作为代码是否满足可移植性的一些检测条件.
书中还提到的2点注意事项, 我觉得不仅是编写内核代码, 编写任何代码时, 都应该注意:
- 编码尽量选取最大公因子 :: 假定任何事情都有可能发生, 任何潜在的约束也都存在
- 编码尽量选取最小公约数 :: 不要假定给定的内核特性是可用的, 仅仅需要最小的体系结构功能
虽然编写可移植性代码需要遵守这么多的原则, 但是不能畏惧, 在学习内核开发的过程中, 只有不断的尝试, 不断的犯错, 才能确实的掌握内核.
补丁, 开发和社区
linux最吸引我的地方之一就是它拥有一个高手云集的社区, 还有就是如果能=为linux内核中贡献代码, 一定是一件令人自豪的事情.
下面主要总结一些和贡献代码相关的主要内容.
- 加入社区
- 编码风格
- 提交补丁
- 总结
1. 加入社区
如果想为linux贡献代码, 那么加入linux社区是必须的, 加入了社区, 不仅可以及时内核的最新消息, 而且可以及时和社区内有经验的内核开发者交流经验.
同时也是提交代码和讨论代码的地方, 了解社区的规则, 融入社区环境之中, 才能更好的学习内核, 体会内核开发的乐趣和成就感.
内核社区说白了就是内核邮件列表(LKML linux kernel mail list)
订阅邮件列表的网址: http://vger.kernel.org/vger-lists.html 这里面有linux相关的各种邮件列表
关于内核的邮件列表是: http://vger.kernel.org/vger-lists.html#linux-kernel
除了邮件列表之外, 还有2个本书作者推荐的网站也适合linux内核新手去关注:
- http://kernelnewbies.org 有很多适合内核开发入门的资源
- http://lwn.net linux 新闻周刊
2. 编码风格
社区给我们提供了学习和贡献内核的地方, 但是为了避免不必要的麻烦(被别人指责或者无人理睬), 首先得好好了解一些内核代码的编码风格.
linux的编码风格都记录在 Documentation/CodingStyle 内核开发前要好好研读以下, 之后有时间我会整理到博客中.
3. 提交补丁
准备工作都完成之后, 就可以开始内核开发之旅了 :)
只要坚持不断的学习和尝试, 总有一天会为了内核贡献自己的代码, 这时候, 就需要了解如何提交代码, 也就是内核补丁.
如果是发现了BUG或者有改善, 可以将BUG的描述或者改善代码发送给对应的维护者.(内核各个子系统的维护者信息在内核代码根目录下的 MAINTAINERS 文件中)
生成BUG或者改善代码的补丁有2种方法:
1. 用diff命令创建补丁
# 生成patch
diff -urN linux-old/ linux-new/ > my-patch # 比对整个内核代码文件夹
OR
diff -u linux-old/some/file linux-new/some/file > my-patch # 比对某个文件 # 应用patch, 应用了patch之后, linux-old 和 linux-new 中的代码就一样了
cd linux-old
patch -p1 < ../my-patch # 这个命令是进入linux内核代码根目录内执行的 # PS. 还有个很有用的工具 diffstat
diffstat -p1 my-patch # 列出补丁所引起的变更的统计(加入或移去的代码行)
2. 用git命令创建补丁
# 提交修改的或新增的代码
git commit -a # 提交所有修改的代码
OR
git commit linux-src/some/file.c # 提交某个修改的代码
OR
git add linux-src/some/new-file.c # 把新增的文件加入版本库
git commit -a # 提交新增的文件 # 生成patch
git format-patch -N # N 是正整数, 这条命令生成最后N次提交产生的补丁
OR
git format-patch -1 # 最后1次提交产生的补丁 # 应用patch: 和第一种方法一样
4. 总结
本章的内容都是和提交内核patch有关, 我还是内核的入门者, 没有社区的经验, 更别说提交内核patch的经验了.
这篇笔记只是简单记录一些对入门者有用的信息, 便于以后查看.
参考文档:https://www.cnblogs.com/wang_yb/p/3514730.html
初探内核之《Linux内核设计与实现》笔记下的更多相关文章
- 【原创】解BUG-xenomai内核与linux内核时间子系统之间存在漂移
版权声明:本文为本文为博主原创文章,转载请注明出处.如有问题,欢迎指正.博客地址:https://www.cnblogs.com/wsg1100/ 一.问题起源 何为漂移?举个例子两颗32.768kH ...
- Android内核和Linux内核的区别
1.Android系统层面的底层是Linux,并且在中间加上了一个叫做Dalvik的Java虚拟机,从表面层看是Android运行库.每个Android应用都运行在自己的进程上,享有Dalvik虚拟机 ...
- 【内核】linux内核启动流程详细分析
Linux内核启动流程 arch/arm/kernel/head-armv.S 该文件是内核最先执行的一个文件,包括内核入口ENTRY(stext)到start_kernel间的初始化代码, 主要作用 ...
- 【内核】linux内核启动流程详细分析【转】
转自:http://www.cnblogs.com/lcw/p/3337937.html Linux内核启动流程 arch/arm/kernel/head-armv.S 该文件是内核最先执行的一个文件 ...
- 内核操作系统Linux内核变迁杂谈——感知市场的力量
本篇文章个人在青岛游玩的时候突然想到的...今天就有想写几篇关于内核操作系统的博客,所以回家到以后就奋笔疾书的写出来发表了 Jack:什么是操作系统? 我:你买了一台笔记本,然后把整块硬盘彻底格式化, ...
- 【内核】Linux内核Initrd机制解析,内核更新步骤,grub配置说明
什么是Initrd initrd的英文含义是 boot loader initialized RAM disk,就是由boot loader初始化的内存盘.在 linux内核启动前, boot loa ...
- Linux内核分析——Linux内核学习总结
马悦+原创作品转载请注明出处+<Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 Linux内核学习总结 一 ...
- 《Linux内核--分析Linux内核创建一个新进程的过程 》 20135311傅冬菁
20135311傅冬菁 分析Linux内核创建一个新进程的过程 一.学习内容 进程控制块——PCB task_struct数据结构 PCB task_struct中包含: 进程状态.进程打开的文件. ...
- [内核同步]Linux内核同步机制之completion
转自:http://blog.csdn.net/bullbat/article/details/7401688 内核编程中常见的一种模式是,在当前线程之外初始化某个活动,然后等待该活动的结束.这个活动 ...
- Linux内核分析-Linux内核如何装载和启动一个可执行程序
ID:fuchen1994 实验要求: 理解编译链接的过程和ELF可执行文件格式,详细内容参考本周第一节: 编程使用exec*库函数加载一个可执行文件,动态链接分为可执行程序装载时动态链接和运行时动态 ...
随机推荐
- tomcat,nginx日志定时清理
1. Crontab定时任务 Crontab 基本语法 t1 t2 t3 t4 t5 program 其中 t1 是表示分钟,t2 表示小时,t3 表示一个月份中的第几日,t4 表示月份,t5 表示一 ...
- java中父类子类静态代码块、构造代码块执行顺序
父类静态(代码块,变量赋值二者按顺序执行) 子类静态 父类构造代码块 父类构造方法 子类构造代码块 子类构造方法 普通方法在实列调用的时候执行,肯定位于上面之后了 //父类A public class ...
- Spring boot拦截器的实现
Spring boot拦截器的实现 Spring boot自带HandlerInterceptor,可通过继承它来实现拦截功能,其的功能跟过滤器类似,但是提供更精细的的控制能力. 1.注册拦截器 @C ...
- SSM框架学习笔记(一)
Spring框架 Spring :是一个开源框架,起初是为解决企业应用开发的复杂性而创建的,但是现在已经不止 企业级应用开发,Spring的核心就是提供了一个轻量级的控制反转和面向切面编程. SPri ...
- JAVA父类的静态方法能否被子类重写?
静态: 在编译时所分配的内存会一直存在(不会被回收),直到程序退出内存才会释放这个空间,在实例化之前这个方法就已经存在于内存,跟类的对象没什么关系.子类中如果定义了相同名称的静态方法,并不会重写,而应 ...
- 【学习笔记】第二章 python安全编程基础---正则表达式
一.python正则表达式 定义:正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式相匹配: 1.1RE模块:是python语言拥有全部的正则表达式功能的一个正则模块: 常见 ...
- 解决chrome浏览器崩溃,再次安装不上问题
上网重新下载了个安装包,发现安装包都打不来 很绝望,查了很多资料 很多人说要删除注册表的东西 但是打开注册表,发现一堆google的东西,手动删根本不现实 在绝望中看到了解决方案:google Upd ...
- 多线程——Runnable接口
以实现Runable接口的方式创建线程比继承Thread类有很大的优越性,因为类不能多重继承,即一个类只能继承一个类,那么如果该类已经继承了一个类,就不能实现多线程了,但是可以通过实现Runable接 ...
- [Pandas] 04 - Efficient I/O
SQLITE3接口 调动 SQLITE3数据库 import sqlite3 as sq3 query = 'CREATE TABLE numbs (Date date, No1 real, No2 ...
- LCX使用心得
最近在搞内网渗透,碰到 端口转发&边界处理 的时候,我们就可以借助一些小工具了,这类工具有很多,这里主要说明lcx的用法. lcx是个很老的端口转发工具,而它的使用也很简单.不过想要把lcx玩 ...