【机器学习笔记】来吧!解析k-NN
序:
监督型学习与无监督学习,其最主要区别在于:已知的数据里面有没有标签(作为区别数据的内容)。
监督学习大概是这个套路:
1.给定很多很多数据(假设2000个图片),并且给每个数据加上标签(与图片一一对应的2000个标签数据),以上统称为样本数据;
2.取一定比例的样本数据集(剩下的数据还有别的作用,此处一般可设为取90%)放入到训练模型,训练之后得到一个目标模型;
3.出模型后,还需要确定模型(识别或分类等的)准确度,
此时,需要投入测试数据集(即剩下那10%的数据集),从模型得到结果之后比较对应的标签值,以得到准确率如何。
一、k-NN原理
k-邻近(k-NearestNeighbor):
通过近邻数据的类别来对无标签样本进行分类。
首先找到样本集中与输入样本数据差距最小的k个样本,然后根据这k个样本里哪个分类最多从而确定输入样本的分类是什么。
k-NN是一种基于实例的学习,其分类并非取决于内在模型,而是对带标签的测试集进行参考比较,是一种非归纳的方法。
字面上应该是很好理解的,我跟着《机器学习实战》跑第二章代码,发现代码还是得写得很细致。
我用的是Win7 Python3.6的环境,与书本的语言版本可能不同,不过下文贴出的代码都有修改,验证能跑的。
有意思的是一些类库的方法,至于如何看待这些类库,一个原则:“只要觉得合理存在的就应该有”。
已知有数据:

求待预测数据与 已作分类的各个样本 的差距(对,就是粗暴的减法):

据矩阵加减法的格式要求,样本数据要稍作处理(使用numpy提供的tile()),结果设为diffMat:

避免出现负值,加个平方(是点乘,仅矩阵内的数值操作平方):
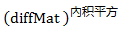
此时diffMatsq是1000 * 3的矩阵,内容是待测样本X与所有样本的差距,但是不同特征之间如何看待这个差距呢?每个特征信息对于分类结果的影响,可能是不一样的,这里就涉及到归一化、赋予权重的问题,但此处仅为捋过程,暂且不做处理,粗暴地当每个特征的影响程度都是平等的。现取行之和作为矩阵sqDistances:

numpy里的 .sum(axis = 1) 处理过后,会为矩阵转置,也即矩阵大小变化:n * m –> n * 1 –> 1 * n 。(注:sum函数中axis = 0 是一列当中的每行数据相加,axis = 1 是一行中的每列数据相加)
接下来就很明显了,取前 k 个最小差距的样本,这里用到一个很有意思的函数 .argsort(),它可以返回从小到大排序的索引值。注意,是索引值。下表为一个数值demo:
|
索引号 |
0 |
1 |
2 |
3 |
4 |
|
差值 |
1.4 |
0.4 |
0.1 |
0 |
2.5 |
|
.argsort() 设为sortedDistIndicies |
3 |
2 |
1 |
0 |
4 |
这样解读第三行,.argsort() 就发光发热了:
第一个最小的数值,索引编号在3;第二小的索引号在2,以此类推。
回归正题,k-NN是要干嘛?是时候展现k-NN的技术了:
取到前k个最小差距的样本,再记录这个样本的标签值,最后统计哪个标签出现次数最多,就判断带分类样本为该标签分类结果。
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
这个 i 表面上是k里面的第几个,但实际上,也是表示第几个最小差值,那个标签索引就在 sortedDistIndicies 里面找。
这波操作结束之后,再排序(classCount是字典类型,{标签,出现次数}),返回出现次数最多的标签值就完事了。
二、python3.6实现k-NN
1.踏踏实实,一个勤恳的宝宝:
def classify0(inX, dataSet, labels, k): # inX:待分类目标,dataSet:数据集,labels:数据集对应标签
dataSetSize = dataSet.shape[0] #
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # 1000 * 3
sqDiffMat = diffMat ** 2 # 矩阵内数值平方 1000 * 3
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances ** 0.5
sortedDistIndicies = distances.argsort()
classCount = {}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
return sortedClassCount[0][0]
2. Scikit-learn,k-NN带回家
既然“只要觉得合理存在,就应该存在”,那么k-NN有没有省事点调用的方法呢?
Scikit-learn类库帮助你!pip install sklearn即刻免费带回家 ~ 只要添加引用:
from sklearn.neighbors import KNeighborsClassifier as knn
麻麻再也不担心我不会写啦:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier as knn
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap def knnDemo(X, y, k):
res = 0.05
k1 = knn(n_neighbors = k, p = 2, metric = 'minkowski')
k1.fit(X,y) # sets up the grid
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 # 第一行数据最值
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 # 第二行数据最值
# xx1,xx2是伪造的数据①
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, res), np.arange(x2_min, x2_max, res)) Z = k1.predict(np.array([xx1.ravel(), xx2.ravel()]).T) # 括号里矩阵大小 2 * 9856
Z = Z.reshape(xx1.shape) # 9856个结果。因为下文是按照xx1和xx2构建的直角坐标系,所以点的(x,y)这样换算 # creates the color map
cmap_light = ListedColormap(['#FFAAAA','#AAFFAA','#AAAAFF']) # 3个标签,3个颜色
cmap_bold = ListedColormap(['#FF0000','#00FF00','#0000FF']) # plots the decision surface
plt.contourf(xx1, xx2, Z, alpha = 0.4, cmap = cmap_light) # 渲染背景色
plt.xlim(xx1.min(), xx1.max()) # x、y轴起始
plt.ylim(xx2.min(), xx2.max()) # plots the samples
for idx, c1 in enumerate(np.unique(y)):
plt.scatter(X[:, 0], X[:, 1], c = y, cmap = cmap_bold) # 绘制散点
plt.show() iris = datasets.load_iris() # 数据集②
X1 = iris.data[:, 0:3:2] # 0:3:2 意思是,取所有行,取列中由0~3以2递增的索引值。
X2 = iris.data[:, 0:2]
X3 = iris.data[:, 1:3]
y = iris.target
knnDemo(X2, y, 15)
太长的备注放在这里八:
① # xx1是伪造的数据,是第一行;xx2是伪造数据的第二行
# np.array([xx1.ravel(), xx2.ravel()]).T 是创造出来的待分类数据
# np.arange(start, end, step) 创建从start开始到end并且以step步伐递增的矩阵
# (n * m 变为 nm * 1 大小的矩阵,与flatten()相似,后者占据内存空间,而ravel()是视图)
② # 鸢尾属植物数据集,该数据集包含了三种iris类型(Setosa、Versicolor 和 Virginica)的150个样本,每个样本具有4个特征,也即 iris.data 矩阵大小是 150 * 4
# 特征分别是萼片宽度、萼片长度、花瓣长度和花瓣宽度,单位是cm。
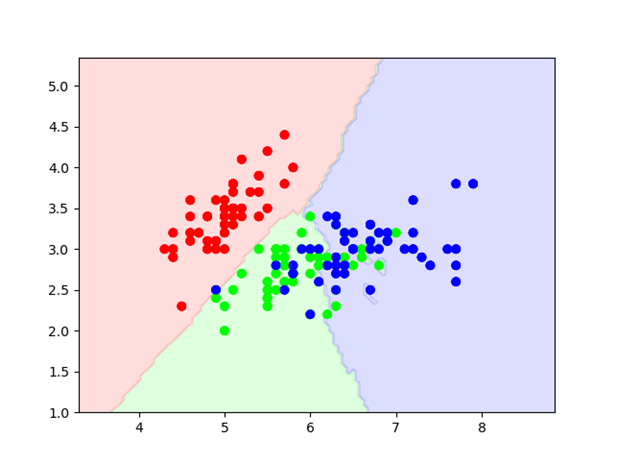
图1 3-Class classification(k=15, weight=’uniform’)
图像可见分类,红色、绿色、蓝色三个类别的花朵。后面懒得写了,自行感悟吧。
三、我的k-NN之感(k-NN优势与劣势)
优:
比较简单亲民?还有……可能某些方面的分类效果还是不错的?
劣:
数据收集这方面,就不多说了。首先,有些难以确定没想特征值对结果影响的比重(归一化感觉还是有些粗暴?);其次,算待分类样本与已分类样本的差距,感觉这个很有拓展性;还有,如果得出多个标签出现次数相同的情况,可能还得进一步处理?
另外,矩阵运算量还蛮多的,如果每一次都要计算样本差值,求平方再开,遍历一次求最值,感觉代价有些大。
==================================== 题外 ====================================
一开始没get到 .argsort() 的神奇作用,还写了快速排序,既然写了,那就贴吧:
def QuickSort(array1):
left = 0
right = array1.shape[0] - 1
pilot = array1[0]
while left < right :
while right != left and array1[right] > pilot :
right -= 1
array1[left] = array1[right]
while left != right and array1[left] < pilot :
left += 1
array1[right] = array1[left]
array1[left] = pilot count = array1.shape[0]
if left > 1 :
array2 = array1[0 : left]
array1[0 : left] = QuickSort(array2)
if right < count - 2:
array3 = array1[right + 1 : count]
array1[right + 1 : count] = QuickSort(array3)
return array1
写到后来我也觉得莫名的,感觉不太“好看”,语法不熟悉?于是search,我是有空间性能上的一点点优势吧,但感觉可读性没这么好。
================================== 结束题外 ==================================
立Flag:下一波应该是关于回归。
参考书目:
- 机器学习系统设计 David Julian
- 机器学习实战 Perter Harrington
【机器学习笔记】来吧!解析k-NN的更多相关文章
- 【机器学习笔记五】聚类 - k均值聚类
参考资料: [1]Spark Mlib 机器学习实践 [2]机器学习 [3]深入浅出K-means算法 http://www.csdn.net/article/2012-07-03/2807073- ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
- Python机器学习笔记:不得不了解的机器学习知识点(2)
之前一篇笔记: Python机器学习笔记:不得不了解的机器学习知识点(1) 1,什么样的资料集不适合用深度学习? 数据集太小,数据样本不足时,深度学习相对其它机器学习算法,没有明显优势. 数据集没有局 ...
- Python机器学习笔记:使用Keras进行回归预测
Keras是一个深度学习库,包含高效的数字库Theano和TensorFlow.是一个高度模块化的神经网络库,支持CPU和GPU. 本文学习的目的是学习如何加载CSV文件并使其可供Keras使用,如何 ...
- Python机器学习笔记:不得不了解的机器学习面试知识点(1)
机器学习岗位的面试中通常会对一些常见的机器学习算法和思想进行提问,在平时的学习过程中可能对算法的理论,注意点,区别会有一定的认识,但是这些知识可能不系统,在回答的时候未必能在短时间内答出自己的认识,因 ...
- 机器学习笔记(4):多类逻辑回归-使用gluton
接上一篇机器学习笔记(3):多类逻辑回归继续,这次改用gluton来实现关键处理,原文见这里 ,代码如下: import matplotlib.pyplot as plt import mxnet a ...
- 【转】机器学习笔记之(3)——Logistic回归(逻辑斯蒂回归)
原文链接:https://blog.csdn.net/gwplovekimi/article/details/80288964 本博文为逻辑斯特回归的学习笔记.由于仅仅是学习笔记,水平有限,还望广大读 ...
- Python机器学习笔记 集成学习总结
集成学习(Ensemble learning)是使用一系列学习器进行学习,并使用某种规则把各个学习结果进行整合,从而获得比单个学习器显著优越的泛化性能.它不是一种单独的机器学习算法啊,而更像是一种优 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
随机推荐
- C#在循环中使用Random时生成的随机数相同的解决办法
场景 在循环中使用 Random y = new Random(); 生成随机数时每次循环生成的数是一样的. ; i < ;i++ ) { Random y = new Random(); Po ...
- elasticsearch 心得
1.es 一台机器一般为一个节点.一台机器不设置的情况下是无法创建副本集的,副本集和主本必须不在一个节点下,方便故障转移等 2.es7.x后一个索引后只能创建一个类型,可以通过修改更改 出现这个的原因 ...
- flex布局开发
flex布局开发 布局原理 flex时flexible Box的缩写,意为"弹性布局",用来为盒子模型提供最大的灵活性,任何一个容器都可以定位flex布局 [注意] 当我们为父盒子 ...
- vue项目中使用sass
1 安装sass npm install --save-loader npm install --save-dev node-sass 2 安装依赖 cnpm install stylus-loade ...
- [b0042] python 归纳 (二七)_gui_tkinter_基本使用
# -*- coding: utf-8 -*- """ 学习 Tkinter画图基本控件使用 逻辑: 放几个 输入控件.点击按钮,将输入控件内容打印出来 使用: 1. 创 ...
- 初学JavaScript正则表达式(十)
前瞻与后顾 断言 === assert 符合断言为正向,不符合为负向 例 'a2*3'.replace(/\w(?=\d)/g,'x') ------- x2*3 看看'\d'前面是不是'\w',如果 ...
- appium常使用的命令
1.查看apk安装包的appPackagehe和appActivity aapt dump badging E:\taobao.apk > E:\taobao.txt -- 将appPack ...
- [转] 从零推导支持向量机 (SVM)
原文连接 - https://zhuanlan.zhihu.com/p/31652569 摘要 支持向量机 (SVM) 是一个非常经典且高效的分类模型.但是,支持向量机中涉及许多复杂的数学推导,并需要 ...
- 接口自动化与UI自动化两者的可行性
1.首先接口测试是跳过前端界面对服务端的测试,UI测试是对前端界面的测试,从分层测试的角度考虑,两者不应该是可以互相取代的关系. 2.从公司开展自动化的的角度考虑,可以重点关注这个项目开展接口自动 ...
- echarts使用------地图生成----省市地图的生成及其他相关细节调整
为使用多种业务场景,百度echarts地图示例只有中国地图,那么在使用省市地图的时候,就需要我们使用省市的地图数据了 以下为陕西西安市的地图示例: 此页面引用echarts的js:http://ech ...