HDFS 读写流程-译
HDFS 文件读取流程
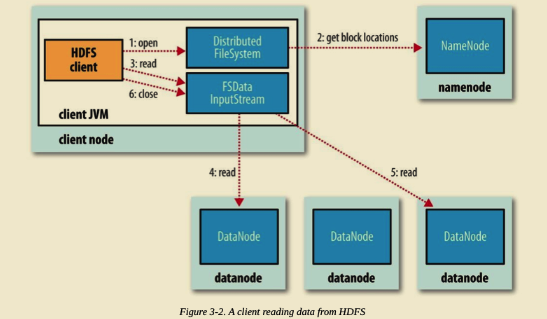
Client 端调用 DistributedFileSystem 对象的 open() 方法。
由 DistributedFileSystem 通过 RPC 向 NameNode 请求返回文件的 Block 块所在的 DataNode 的地址。(我们知道 HDFS 默认策略对某个 Block 会保存三份副本到不同的 DataNode,那么 NameNode 应该返回那个 DataNode?答案是根据 DataNode 到 Client 端的距离。假设请求的 Block 块刚好就落在 Client 端所在机器上,即 Client 端本身也是 DataNode,那么毫无疑问 DataNode 将会返回 Client 端所在机器地址。这也验证了 Hadoop 的一个设计特性,移动计算而不是移动数据,极大了减小了带宽。)
Client 端调用 FSDataInputStream 对象的 read() 方法,通过 FSDataInputStream 向 DataNode 获取 Block 数据。之后数据流源源不断地从 DataNode 返回至 Client。当最后一个 Block 返回至 Client 端后, DFSInputStream 会关闭与 DataNode 连接。上述过程对 Client 端都是透明的,从 Client 来看,它只是在不停的读取数据流。
如果 DFSInputStream 在读取的过程中发生了错误,将会尝试与存有该 Block 副本且距离最近的 DataNode 通信。同时,它会记录下出问题的 DataNode,在之后的数据请求过程中不再与之通信。并报告给 NameNode。DFSInputStream 具备检查数据校验和的功能。
HDFS 文件写入流程
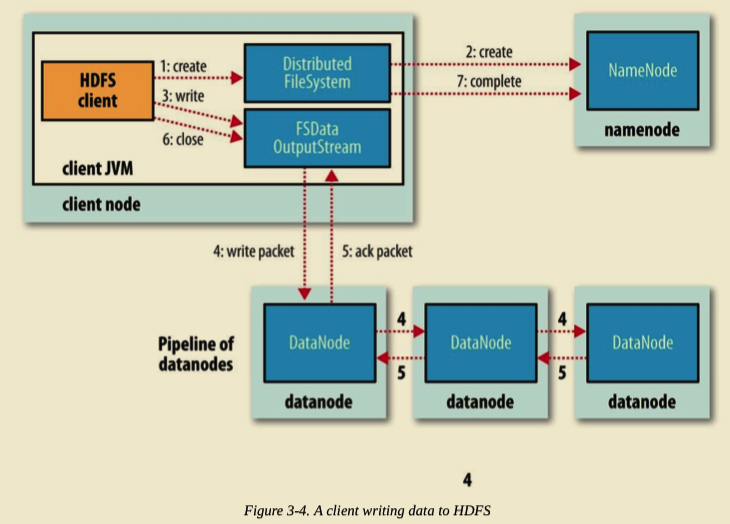
Client 写入文件时,调用 DistributedFileSystem 对象的 create() 方法。
DistributedFileSystem 通过 RPC 请求 NameNode 向其 NameSpace 写入文件元数据信息。NameNode 会做多种检查,如判断文件是否存在,是否有相应的写权限等等。如果检查通过,NameNode 会将文件元数据写入 NameSpace。DistributedFileSystem 将会返回 FSDataOutputStream 用于 Client 端直接向 DataNode 写入数据。
DFSOutputStream 将 Client 要写入的数据分割成 Packets。Packets 会被保存到 Data Queue 队列中,并由 DataStreamer 消费处理。DataStreamer 请求 NameNode 分配 DataNode 列表,将 Packets 写入到 DataNode 中。假设放置副本的默认策略是 3,那么 NameNode 将返回 3 个 DataNode,并串联起来组成一条 Pipeline。 DataStreamer 将 Packets 写入到第一个 DataNode1,DataNode1 存储完后直接转发至 DataNode2,DataNode2 存储完后再直接转发至 DataNode3。(注意,这里直接是 DataNode1 直接将 Packet 转发至 DataNode2。)
DFSOutputStream 为了防止出问题时数据的丢失,维持了一个等待 DataNode 成功写入的 ACK Queue。只有当 Packet 被成功写入 Pipeline 中的每个 DataNode 时,此 Packet 才会从 ACK Queue 中移除。
在 Pipeline 写入的过程中,如果某个 DataNode 出现问题,Pipeline 首先将会被关闭,随后在 ACK Queue 中的 Packets 会被添加到 Data Queue 的最前面,用来防止位于问题节点下游的 DataNode 写入时的数据丢失。出问题的 DataNode 会被从 Pipeline 中移除。NameNode 会重新分配一个健康的 DataNode 构成新的 Pipeline。
当 Client 端写完数据,调用 DFSOutputStream 对象的 close() 方法。该操作将会将所有剩余的 Packets 刷写到 DataNode Pipeline 并等待返回确认,之后向 NameNode 发送文件写入完成信号。
HDFS 读写流程-译的更多相关文章
- 大数据系列文章-Hadoop的HDFS读写流程(二)
在介绍HDFS读写流程时,先介绍下Block副本放置策略. Block副本放置策略 第一个副本:放置在上传文件的DataNode:如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点. 第二 ...
- 【转】HDFS读写流程
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现. 特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性流式数据访问 ...
- HDFS读写流程(转载)
概述开始之前先看看其基本属性,HDFS(Hadoop Distributed File System)是GFS的开源实现.特点如下: 能够运行在廉价机器上,硬件出错常态,需要具备高容错性 ...
- 超详细的HDFS读写流程详解(最容易理解的方式)
HDFS采用的是master/slaves这种主从的结构模型管理数据,这种结构模型主要由四个部分组成,分别是Client(客户端).Namenode(名称节点).Datanode(数据节点)和Seco ...
- Hadoop之HDFS读写流程
hadoophdfs 1. HDFS写流程 2. HDFS写流程 1. HDFS写流程 HDFS写流程 副本存放策略: 上传的数据块后,触发一个新的线程,进行存放. 第一个副本:与client最近的机 ...
- HDFS 读写流程-英
HDFS 文件读取流程 The client opens the file it wishes to read by calling open() on the FileSystem object, ...
- HDFS读写流程(重点)
@ 目录 一.写数据流程 举例: 二.异常写流程 读数据流程 一.写数据流程 ①服务端启动HDFS中的NN和DN进程 ②客户端创建一个分布式文件系统客户端,由客户端向NN发送请求,请求上传文件 ③NN ...
- HDFS读写流程learning
有许多对流程进行描述的博客,但是感觉还是应当学习一遍代码,不然总感觉怪怪的,https://blog.csdn.net/popsuper1982/article/details/51615285,首先 ...
- HDFS读写流程
01.并行读取 02.逐个节点写入
随机推荐
- 开发一个Spring Boot Starter!
在上一篇文章中,我们已经了解了一个starter实现自动配置的基本流程,在这一小结我们将复现上一过程,实现一个自定义的starter. 先来分析starter的需求: 在项目中添加自定义的starte ...
- C程序设计(第四版)课后习题完整版 谭浩强编著
//复习过程中,纯手打,持续更新,觉得好就点个赞吧. 第一章:程序设计和C语言 习题 1.什么是程序?什么是程序设计? 答:程序就是一组计算机能识别和执行的指令.程序设计是指从确定任务到得到结果,写出 ...
- kubernetes lowB安装方式
kubernetes离线安装包,仅需三步 基础环境 关闭防火墙 selinux $ systemctl stop firewalld && systemctl disable fire ...
- SDS模块
早上花了一点时间读了下sds的相关源码,其实sds就是构造了两个字段用来记录len和free的状态,然后还有一个char[]用来记录字符串的值. 然后sds模块的函数都是在模拟str的操作. 比较,追 ...
- Visual Studio Debug
在watch窗口输入,$err,hr可以看到上一个错误代码和相关描述信息 Error Lookup可以将错误代码转换成为相应的文本描述 FormatMessage()
- JavaWeb——Servlet开发3
1.使用初始化参数配置应用程序 初始化参数的方式有两种 在Web.xml文件中使用<context-param>标签声明上下文初始化参数 <context-param> < ...
- todaytt
<?xml version="1.0" encoding="utf-8"?> <android.support.v4.widget.Drawe ...
- ABAP:如何等待小数秒数
WAIT UP TO x SECONDS. 和CALL FUNCTION 'ENQUE_SLEEP'都只能支持整数的秒数(如果是非整数,则四舍五入),如果要WAIT非整数的描述,可以如下写法:
- 5G标准公布,你很快又要换手机了
通常,在4G网络环境下,下载一部1G的电影只需要30秒时间,对于经历过2G和3G网络的我们来说已经非常快了. 但是听说,5G环境中下载一部同样的电影,根本不是用秒来计算的,甚至有外媒说,5G的速率会是 ...
- 贪心算法-过河问题 pojo1700
过桥问题: 黑夜,只有一只手电筒 A过桥需要1s B过桥需要3s C过桥需要5s D过桥需要8s E过桥需要12s 求最小过桥时间 贪心算法: 从最大的开始过去,最小的两个做为辅助. 假如左岸人数为2 ...