使用scrapy-redis搭建分布式爬虫环境
scrapy-redis简介
scrapy-redis是scrapy框架基于redis数据库的组件,用于scrapy项目的分布式开发和部署。
有如下特征:
分布式爬取
您可以启动多个spider工程,相互之间共享单个redis的requests队列。最适合广泛的多个域名网站的内容爬取。
分布式数据处理
爬取到的scrapy的item数据可以推入到redis队列中,这意味着你可以根据需求启动尽可能多的处理程序来共享item的队列,进行item数据持久化处理
Scrapy即插即用组件
Scheduler调度器 + Duplication复制 过滤器,Item Pipeline,基本spider
scrapy-redis架构
scrapy-redis整体运行流程如下:
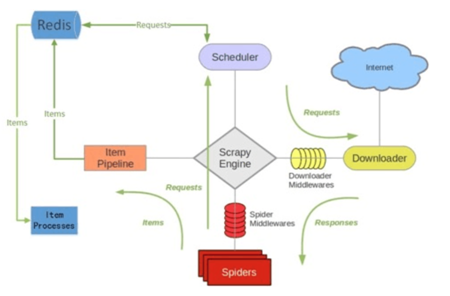
1. 首先Slaver端从Master端拿任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master 处理;
2. Master端只有一个Redis数据库,负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
Scrapy-Redis默认使用的就是这种策略,我们实现起来很简单,因为任务调度等工作Scrapy-Redis都已经帮我们做好了,我们只需要继承RedisSpider、指定redis_key就行了。
缺点是,Scrapy-Redis调度的任务是Request对象,里面信息量比较大(不仅包含url,还有callback函数、headers等信息),
可能导致的结果就是会降低爬虫速度、而且会占用Redis大量的存储空间,所以如果要保证效率,那么就需要一定硬件水平。
scrapy-redis安装
通过pip安装即可:pip install scrapy-redis
一般需要python、redis、scrapy这三个安装包
官方文档:https://scrapy-redis.readthedocs.io/en/stable/
源码位置:https://github.com/rmax/scrapy-redis
参考博客:https://www.cnblogs.com/kylinlin/p/5198233.html
scrapy-redis常用配置
一般在配置文件中添加如下几个常用配置选项:
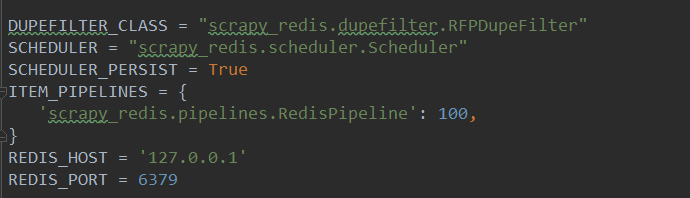
1(必须). 使用了scrapy_redis的去重组件,在redis数据库里做去重
- DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
2(必须). 使用了scrapy_redis的调度器,在redis里分配请求
- SCHEDULER = "scrapy_redis.scheduler.Scheduler"
3(可选). 在redis中保持scrapy-redis用到的各个队列,从而允许暂停和暂停后恢复,也就是不清理redis queues
- SCHEDULER_PERSIST = True
4(必须). 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item 这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
- ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100 ,
}
5(必须). 指定redis数据库的连接参数
- REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
scrapy-redis键名介绍
scrapy-redis中都是用key-value形式存储数据,其中有几个常见的key-value形式:
1、 “项目名:items” -->list 类型,保存爬虫获取到的数据item 内容是 json 字符串
2、 “项目名:dupefilter” -->set类型,用于爬虫访问的URL去重 内容是 40个字符的 url 的hash字符串
3、 “项目名: start_urls” -->List 类型,用于获取spider启动时爬取的第一个url
4、 “项目名:requests” -->zset类型,用于scheduler调度处理 requests 内容是 request 对象的序列化 字符串
scrapy-redis简单实例
在原来非分布式爬虫的基础上,使用scrapy-redis简单搭建一个分布式爬虫,过程只需要修改一下spider的继承类和配置文件即可,很简单。
原非分布式爬虫项目,参见:https://www.cnblogs.com/pythoner6833/p/9018782.html
首先修改配置文件,在settings.py文件中添加代码:
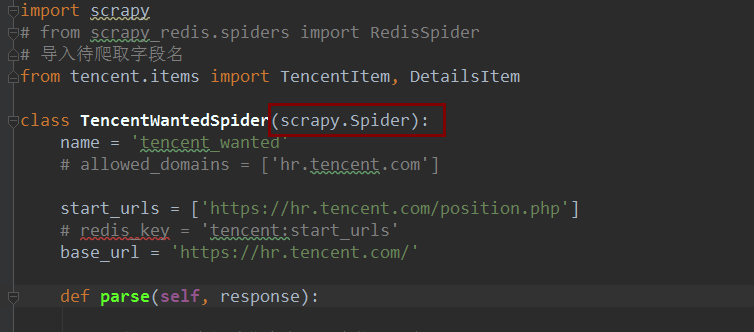
然后需要修改的文件,是spider文件,原文件代码为:
修改为:
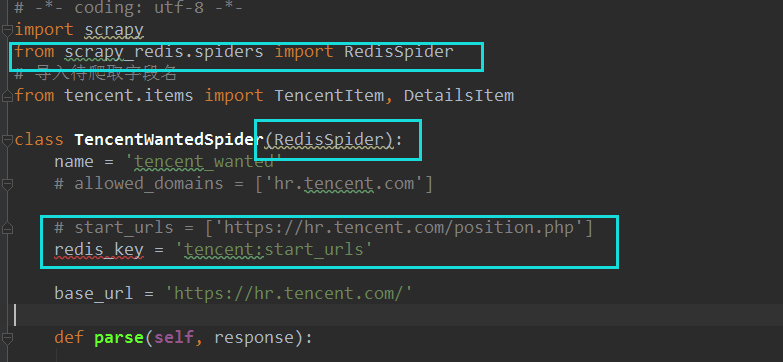
只修改了两个地方,一个是继承类:由scrapy.Spider修改为RedisSpider
然后start_url已经不需要了,修改为:redis_key = "xxxxx",其中,这个键的值暂时是自己取的名字,
一般用项目名:start_urls来代替初始爬取的url。由于分布式scrapy-redis中每个请求都是从redis中取出来的,因此,在redis数据库中,设置一个redis_key的值,作为初始的url,scrapy就会自动在redis中取出redis_key的值,作为初始url,实现自动爬取。
因此:来到redis中,添加代码:

即:在redis中设置一个键值对,键为tencent2:start_urls , 值为:初始化url。即可将传入的url作为初始爬取的url。
如此一来,分布式已经搭建完毕。
使用scrapy-redis搭建分布式爬虫环境的更多相关文章
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- Scrapy+redis实现分布式爬虫
概述 什么是分布式爬虫 需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一网络资源进行联合且分布的数据爬取. 原生Scrapy无法实现分布式的原因 原生Scrapy中调度器 ...
- 使用scrapy-redis 搭建分布式爬虫环境
scrapy-redis 简介 scrapy-redis 是 scrapy 框架基于 redis 数据库的组件,用于 scraoy 项目的分布式开发和部署. 有如下特征: 分布式爬取: 你可以启动多个 ...
- 使用Docker Swarm搭建分布式爬虫集群
https://mp.weixin.qq.com/s?__biz=MzIxMjE5MTE1Nw==&mid=2653195618&idx=2&sn=b7e992da6bd1b2 ...
- scrapy——7 scrapy-redis分布式爬虫,用药助手实战,Boss直聘实战,阿布云代理设置
scrapy——7 什么是scrapy-redis 怎么安装scrapy-redis scrapy-redis常用配置文件 scrapy-redis键名介绍 实战-利用scrapy-redis分布式爬 ...
- 基于scrapy框架的分布式爬虫
分布式 概念:可以使用多台电脑组件一个分布式机群,让其执行同一组程序,对同一组网络资源进行联合爬取. 原生的scrapy是无法实现分布式 调度器无法被共享 管道无法被共享 基于 scrapy+redi ...
- scrapy如何实现分布式爬虫
使用scrapy爬虫的时候,记录一下如何分布式爬虫问题: 关键在于多台主机协作的关键:共享爬虫队列 主机:维护爬取队列从机:负责数据抓取,数据处理,数据存储 队列如何维护:Redis队列Redis 非 ...
- 阿里云Centos7.6上面部署基于redis的分布式爬虫scrapy-redis将任务队列push进redis
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个服务器的处理能力就不能满足我们的需求了(无论是处理速度还是网络请 ...
- 在阿里云Centos7.6上面部署基于Redis的分布式爬虫Scrapy-Redis
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_83 Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的 ...
随机推荐
- Java多线程编程(二)对象及变量的并发访问
一.synchronized同步方法 1.方法内的变量为线程安全 “非线程安全”问题存在于“实例变量”中,如果是方法内部的私有变量,则不存在“非线程安全”问题,所得结果也就是“线程安全”的了. 示例: ...
- 使用pyquery
简单举例 from pyquery import PyQuery as pq html = ''' <div> <ul> <li class="item-O&q ...
- 转:nginx和php-fpm的两种通信方式
原文地址:https://segmentfault.com/q/1010000004854045 Nginx和PHP-FPM的进程间通信有两种方式,一种是TCP,一种是UNIX Domain Sock ...
- [考试反思]0917csp-s模拟测试45:天命
又倒一了. 关于心态,有不少想说的. 首先旁边坐了一个kx.他上来入手T1没多久就切了然后开始对拍拍了几十万组AC. 然而我觉得T1是神仙题.先进T2. 挺简单的,5分钟出正解,然后在打出来的时候突然 ...
- [考试反思]0719NOIP模拟测试6 + 0722NOIP模拟测试7
连续爆炸,颇为愉快. 第6次:Rank #4 第7次:Rank #9 对于第6次考试,个人比较满意,因为T1只是差了一个卡常. 因为在考试前两天刚讲了矩阵,满脑子都是矩阵,还想到了循环矩阵优化. 整个 ...
- python之装饰器的概念
装饰器对于程序来说虽然不是必要的,但有时候却可以提高效率,也可以保证程序的安全. 说装饰器之前需要掌握闭包,前面一篇文章已经介绍过,这里不再重复. 那么,装饰器到底是什么东西呢?看下面这个例子 首先定 ...
- [UWP]使用CompositionAPI的翻转动画
1. 运行效果 在 使用GetAlphaMask和ContainerVisual制作长阴影(Long Shadow) 这篇文章里我介绍了一个包含长阴影的番茄钟,这个番茄钟在状态切换时用到了翻转动画,效 ...
- jquery mobiscroll移动端日期选择控件(无乱码)
jquery mobiscroll移动端日期选择控件(无乱码) <pre><!DOCTYPE html><html lang="en">< ...
- cmake 编译安装mysql5.5.32
1.安装cmake 上传tar包 rz cmake-2.8.8.tar.gz 解压tar包,并进入解压后的文件夹 tar xf cmake-2.8.8.tar.gz cd cmake-2.8.8 编译 ...
- 大数据HDFS相关的一些运维题
1.在 HDFS 文件系统的根目录下创建递归目录“1daoyun/file”,将附件中的BigDataSkills.txt 文件,上传到 1daoyun/file 目录中,使用相关命令查看文件系统中 ...