《机器学习技法》---AdaBoost算法
1 AdaBoost的推导
首先,直接给出AdaBoost算法的核心思想是:在原数据集上经过取样,来生成不同的弱分类器,最终再把这些弱分类器聚合起来。
关键问题有如下几个:
(1)取样怎样用数学方式表达出来;
(2)每次取样依据什么准则;
(3)最后怎么聚合这些弱分类器。
首先我们看第一个问题,如何表示取样?答案使用原数据集上的加权error。
假设我们对数据集D做的取样如下:

那么我们在新数据集上的01error可以等效为在原数据集上的加权error:

即我们取样相当于确定一组权重μ,对这个加权的error作最小化就能得到一个弱分类器g。
特别的,对于svm和逻辑回归,如果我们已知权重μ,我们可以用下面的方式解:
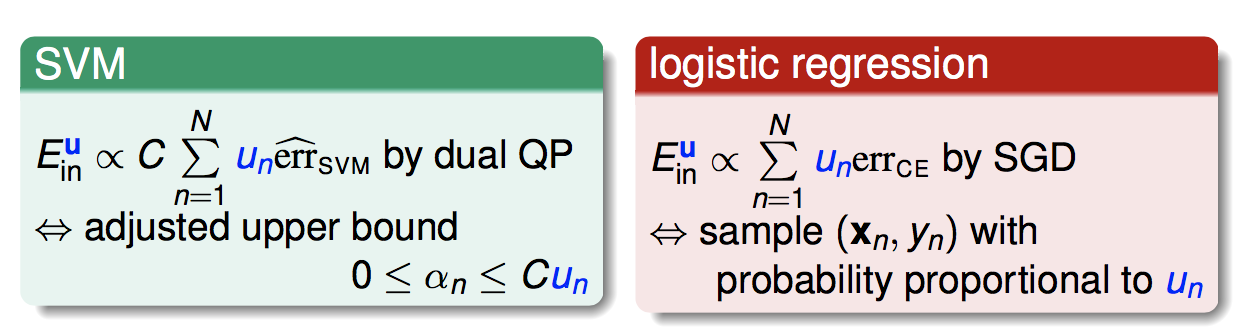
然后是第二个问题,依据什么原则来取样?或者说,怎样选择权重μ。
答案是多样性。即保证生成的每个弱分类器的差别越大,最后的聚合出来的强分类器就会越好。
如何来保证这一点呢?假设我的第t次取样生成了gt,第t+1次取样生成了g(t+1),取样的规则分别是μt和μt+1。即:

那么,要保证gt+1和gt有很大不同,有一个办法,就是使gt用在gt+1的数据集上时,效果很差。效果很差就是错误率是0.5,跟扔硬币一样:

即:

所以,更新这个权重的方法是,对于t轮上分类错误的点,它的u应该更新为乘以总的分类正确率,对于分类正确的点,它的u应该更新为乘以总的分类错误率,注意这里的分类错误率是加权后的分类错误率(或者说在采样后的分类错误率):

这里我们使用另一种与上面等效的方法:

它有一定的物理意义:由于上一轮错误率总是小于0.5,因此方块t是大于1的。因此对于上一次分类正确的权重,除以方块t,减小了权重;对于上一次分类错误的权重,乘以方块t,放大了权重。
类似于水果课堂中老师教学生的例子。
第三个问题,得到了这些弱分类器,如何把他们聚合起来?AdaBoost使用的是Linear Blending的方式,其中的权重应该与方块t成正比,即这个弱分类器表现越好,权重应该越大:

另外,初始的u我们定为均匀的。
这样,AdaBoost算法如下:

2 AdaBoost的理论保证

《机器学习技法》---AdaBoost算法的更多相关文章
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- Adaboost 算法
一 Boosting 算法的起源 boost 算法系列的起源来自于PAC Learnability(PAC 可学习性).这套理论主要研究的是什么时候一个问题是可被学习的,当然也会探讨针对可学习的问题的 ...
- Adaboost 算法的原理与推导
0 引言 一直想写Adaboost来着,但迟迟未能动笔.其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩.昨日11月1日下午,邹博在我组织的机器学习班第8次 ...
- 一个关于AdaBoost算法的简单证明
下载本文PDF格式(Academia.edu) 本文给出了机器学习中AdaBoost算法的一个简单初等证明,需要使用的数学工具为微积分-1. Adaboost is a powerful algori ...
- Adaboost算法初识
1.算法思想很简单: AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(三个臭皮匠,顶个诸葛亮) 它的 ...
- 【AdaBoost算法】积分图代码实现
一.积分图介绍 定义:图像左上方的像素点值的和: 在Adaboost算法中可用于加速计算Haar或MB-LBP特征值,如下图: 二.代码实现 #include <opencv/highgui.h ...
- Adaboost算法结合Haar-like特征
Adaboost算法结合Haar-like特征 一.Haar-like特征 目前通常使用的Haar-like特征主要包括Paul Viola和Michal Jones在人脸检测中使用的由Papageo ...
- adaboost算法
三 Adaboost 算法 AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(很多博客里说的三个臭皮匠 ...
- AdaBoost 算法原理及推导
AdaBoost(Adaptive Boosting):自适应提升方法. 1.AdaBoost算法介绍 AdaBoost是Boosting方法中最优代表性的提升算法.该方法通过在每轮降低分对样例的权重 ...
- 数据挖掘学习笔记--AdaBoost算法(一)
声明: 这篇笔记是自己对AdaBoost原理的一些理解,如果有错,还望指正,俯谢- 背景: AdaBoost算法,这个算法思路简单,但是论文真是各种晦涩啊-,以下是自己看了A Short Introd ...
随机推荐
- 淺談Coach思考模式
我現在是個窮屌,沒錯.我清楚的知道這一點,但是我也知道,我能改變. 之前幹了7年的評估行業,中間換了3家公司,第一家公司待的時間最長,待了5年.2018年開始,我就在思考轉行.之前在第一家企業接觸過一 ...
- 常见Code Review过程中发现的问题
软件环境:Spring MVC + MyBatis 主要体现在两个方面,一个是编码习惯问题,另一个是编码质量的问题.编码习惯主要有日志编写.代码注释以及编码风格的问题,而编码质量则与很多方面相关,比如 ...
- springboot +mybatis分页插件PageHelper
1.问题描述 JAVA界ORM的两位大佬Hibernate和Mybatis,hb自带分页(上手挺快,以前用了好几年hb,后期运维及优化快疯了),mybatis没有分页功能,需要借助第三方插件来完成,比 ...
- android_SurfaceView 画图
有这样一种view类,可以让人在其上面画动画,画图片,它的全名叫做surfaceview.名称就包含两层意思,一层是surface,一层是view.前一层提供一个面可以让人画画,后一层是个view,可 ...
- 基础篇-1.2Java世界的规章制度(上)
1 Java标识符 在Java语言中,有类.对象.方法.变量.接口和自定义数据类型等等,他们的名字并不是确定的,需要我们自己命名.而Java标识符就是用来给类.对象.方法.变量.接口和自定义数据类型命 ...
- 【基础算法-模拟-例题-金币】-C++
原题链接:P2669 金币 这道题目完全是一道模拟题,只要按照题目中的加金币的算法和sum累加就可以很轻易得出最终答案. 说一下有一些点需要注意: 1.用i来计每天发的金币数,n来计已经拿了金币的天数 ...
- 《C Primer Plus(第6版)中文版》勘误
搬运自己2016年11月28日发布于SegmentFault的文章.链接:https://segmentfault.com/a/1190000007626460 本勘误由本人整理并发布,仅针对下方列出 ...
- c++小游戏——彩票
#include <cstdlib> #include <iostream> #include <cstdio> #include <cmath> #i ...
- Excel催化剂开源第42波-与金融大数据TuShare对接实现零门槛零代码获取数据
在金融大数据功能中,使用了TuShare的数据接口,其所有接口都采用WebAPI的方式提供,本来还在纠结着应该搬那些数据接口给用户使用,后来发现,所有数据接口都有其通用性,结合Excel灵活友好的输入 ...
- mysql8.0的连接写法
由于mysql8.0的新特新,所以Driver要写成“com.mysql.cj.jdbc.Driver” url:"jdbc:mysql://host_address:3306/db_nam ...