05 requests模块进阶
一、简介
1.下载:pip install lxml
推荐使用douban提供的pipy国内镜像服务,如果想手动指定源,可以在pip后面跟-i 来指定源,比如用豆瓣的源来安装web.py框架:
- pip install web.py -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
2.导包
- from lxml import etree
3.xpath解析原理:
- 实例化一个etree对象,然后将即将被解析的页面源码数据加载到该对象中。
- 通过调用etree对象中的xpath方法,结合着xpath表达式进行标签定位和数据提取
4.如何实例化一个etree对象:
将html文档或者xml文档转换成一个etree对象,然后调用对象中的方法查找指定的节点
- 本地文件:将本地的一个html文档中的数据加载到etree对象中, 使用的比较少
- tree = etree.parse(文件名fileName)
- tree.xpath("xpath表达式")
- 网络数据:将互联网爬取到的页面源码数据加载到该对象中
- tree = etree.HTML(网页内容字符串page_text)
- tree.xpath("xpath表达式")
启动和关闭插件 ctrl + shift + x

二、常用xpath表达式
首先,本地新建一个html文档,所以要使用etree.parse(fileName)
- <html lang="en">
- <head>
- <meta charset="UTF-8" />
- <title>测试bs4</title>
- </head>
- <body>
- <div>
- <p>百里守约</p>
- </div>
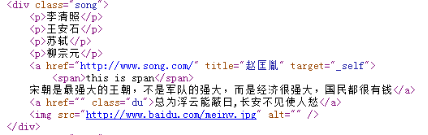
- <div class="song">
- <p>李清照</p>
- <p>王安石</p>
- <p>苏轼</p>
- <p>柳宗元</p>
- <a href="http://www.song.com/" title="赵匡胤" target="_self">
- <span>this is span</span>
- 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a>
- <a href="" class="du">总为浮云能蔽日,长安不见使人愁</a>
- <img src="http://www.baidu.com/meinv.jpg" alt="" />
- </div>
- <div class="tang">
- <ul>
- <li><a href="http://www.baidu.com" title="qing">清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村</a></li>
- <li><a href="http://www.163.com" title="qin">秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山</a></li>
- <li><a href="http://www.126.com" alt="qi">岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君</a></li>
- <li><a href="http://www.sina.com" class="du">杜甫</a></li>
- <li><a href="http://www.dudu.com" class="du">杜牧</a></li>
- <li><b>杜小月</b></li>
- <li><i>度蜜月</i></li>
- <li><a href="http://www.haha.com" id="feng">凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘</a></li>
- </ul>
- </div>
- </body></html>
页面显示如下

层级&索引定位
- #找到class属性值为tang的div的直系子标签ul下的第二个子标签li下的直系子标签a
- //div[@class="tang"]/ul/li[2]/a
- 下面这三个结果相同
- r = tree.xpath('/html/head/title')
- r = tree.xpath('/html//title')
- r = tree.xpath('//title')

- r = tree.xpath('//p') # 所有的p标签


标签定位:
- //div[@class="song"] # 找到class属性值为song的div标签
模糊匹配:
- //div[contains(@class, "ng")] # class属性值包含ng的div
- //div[starts-with(@class, "ta")] # class属性以ta开头的div
取属性:
- //div[@class="tang"]//li[2]/a/@href
- r = tree.xpath('//div[@class="song"]/img/@src')
- print(r)

取文本: /text()直系的文本内容 //text()所有的文本内容
- //div[@class="song"]/p[1]/text() # /表示获取某个标签下的文本内容
- //div[@class="tang"]//text() # //表示获取某个标签下的文本内容和所有子标签下的文本内容
- # 获得的是列表,只不过里面只有一个元素
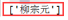
- r = tree.xpath('//div[@class="song"]/p[4]/text()')
- print(r)
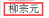
- r = tree.xpath('//div[@class="song"]/p[4]/text()')[0]
- print(r)
- r = tree.xpath('//div[@class="song"]//text()')
- print(r)

逻辑运算:
- # 找到href属性值为空且class属性值为du的a标签
- //a[@href="" and @class="du"]
三、案例
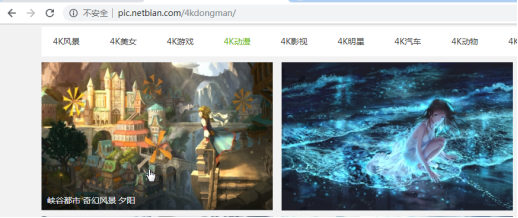
案例1:解析图片数据:http://pic.netbian.com/4kmeinv/
查看:网址鼠标悬浮上去会有图片名称,所以爬取图片以及对应的名称,要提前确定不是动态加载的。
- import requests
- from lxml import etree
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
- }
- url = 'http://pic.netbian.com/4kdongman/'
- response = requests.get(url=url,headers=headers)
- # response.encoding = 'utf-8' #手动设定响应数据的编码
- page_text = response.text
- #数据解析(图片地址,图片名称)
- tree = etree.HTML(page_text)
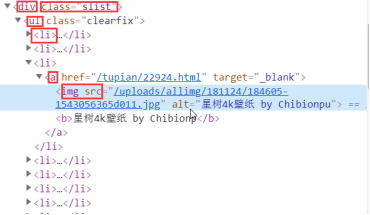
- li_list = tree.xpath('//div[@class="slist"]/ul/li')
- for li in li_list:
- #局部内容解析一定是以./开头。etree和element都可以调用xpath
- img_src = 'http://pic.netbian.com'+li.xpath('./a/img/@src')[0] # 解析出来的没有域名,要加上
- img_name = li.xpath('./a/img/@alt')[0] #不要忘记前面加点号,表示从当前li标签开始
- img_name = img_name.encode('iso-8859-1').decode('gbk') #处理中文乱码的通用形式
- img_data = requests.get(url=img_src,headers=headers).content
- img_path = './qiutuLibs/'+img_name+'.jpg'
- with open(img_path,'wb') as fp:
- fp.write(img_data)
- print(img_name,'下载成功!!!')
解析:
1.
- li_list = tree.xpath('//div[@class="slist"]/ul/li')
- print(li_list) # 返回的是一个element类型的数据对象

2.
li标签里面有a标签,然后再里面是img标签, 然后有一个src属性和alt属性
- img_src = 'http://pic.netbian.com'+li.xpath('./a/img/@src')[0] # 解析出来的没有域名,要加上
- img_name = li.xpath('./a/img/@alt')[0]
3. 出现乱码,有两种解决策略:
(1)对整体设定响应数据的编码
手动设定响应数据的编码,查看页面是用哪种编码方式是utf-8,还是gbk等。如果这种方式不行,用下面的方式
- response.encoding = 'utf-8'
(2)针对具体的内容手动设定
- img_name = img_name.encode('iso-8859-1').decode('gbk') #处理中文乱码的通用形式
案例2:xpath解析-boss直聘
- import requests
- from lxml import etree
- import json
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
- }
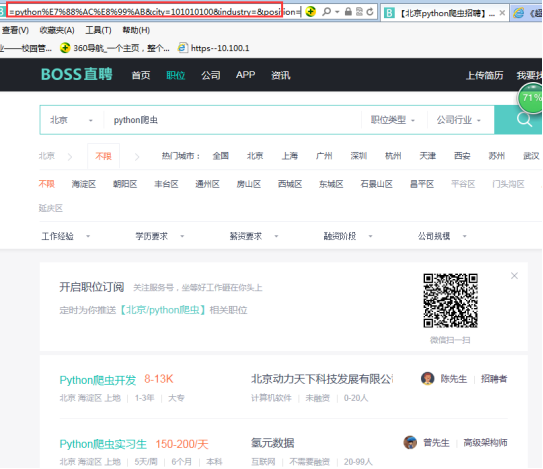
- url = 'https://www.zhipin.com/job_detail/?query=python%E7%88%AC%E8%99%AB&city=101010100&industry=&position='
- page_text = requests.get(url=url, headers=headers).text
- # 数据解析:jobName,salary,company,jobDesc
- tree = etree.HTML(page_text)
- li_list = tree.xpath('//div[@class="job-list"]/ul/li')
- job_data_list = []
- for li in li_list:
- job_name = li.xpath('.//div[@class="info-primary"]/h3/a/div/text()')[0] # 记得后面加[0]
- salary = li.xpath('.//div[@class="info-primary"]/h3/a/span/text()')[0]
- company = li.xpath('.//div[@class="company-text"]/h3/a/text()')[0]
- detail_url = 'https://www.zhipin.com' + li.xpath('.//div[@class="info-primary"]/h3/a/@href')[0]
- # 详情页的页面源码数据
- detail_page_text = requests.get(url=detail_url, headers=headers).text
- detail_tree = etree.HTML(detail_page_text)
- job_desc = detail_tree.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div//text()')
- job_desc = ''.join(job_desc)
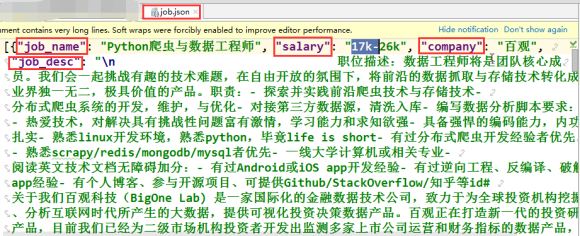
- dic = {
- 'job_name': job_name,
- 'salary': salary,
- 'company': company,
- 'job_desc': job_desc
- }
- job_data_list.append(dic)
- fp = open('job.json', 'w', encoding='utf-8')
- json.dump(job_data_list, fp, ensure_ascii=False)
- fp.close()
- print('over')

解析:
1. 因为有br标签,所以用//
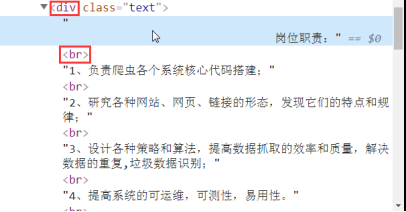
- job_desc = detail_tree.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div//text()')
- print(job_desc)
2. 输出的是列表,里面是元素

所以,字符串拼接
- job_desc = detail_tree.xpath('//*[@id="main"]/div[3]/div/div[2]/div[2]/div[1]/div//text()')
- job_desc = ''.join(job_desc)
- print(job_desc)

最终文件
案例3:xpath解析-热门城市全国城市名称 https://www.aqistudy.cn/historydata
- import requests
- from lxml import etree
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
- }
- url = 'https://www.aqistudy.cn/historydata/'
- page_text = requests.get(url=url,headers=headers).text
- tree = etree.HTML(page_text)
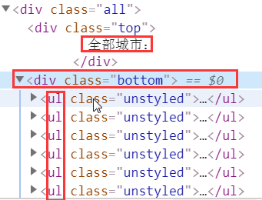
- city_list = tree.xpath('//div[@class="bottom"]/ul/li/a/text() | //div[@class="bottom"]/ul/div[2]/li/a/text()') # 逻辑
- #hot_city://div[@class="bottom"]/ul/li/a/text()
- #all_city://div[@class="bottom"]/ul/div[2]/li/a/text()
- print(city_list)
- print(len(city_list))

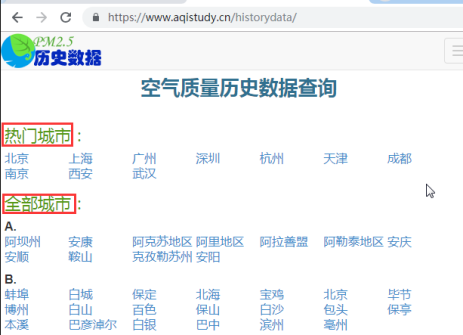
全部城市: //div[@class="bottom"]/ul/div[2]/li/a/text()

案例4:获取好段子中段子的内容和作者http://www.haoduanzi.com
- from lxml import etree
- import requests
- url='http://www.haoduanzi.com/category-10_2.html'
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
- }
- url_content=requests.get(url,headers=headers).text
- tree=etree.HTML(url_content) # 使用xpath解析从网络上获取的数据
- title_list=tree.xpath('//div[@class="log cate10 auth1"]/h3/a/text()') # 解析获取当页所有段子的标题
- ele_div_list=tree.xpath('//div[@class="log cate10 auth1"]')
- text_list=[] # 最终会存储12个段子的文本内容
- for ele in ele_div_list:
- text_list=ele.xpath('./div[@class="cont"]//text()') # 段子的文本内容(是存放在list列表中)
- text_str=str(text_list) # list列表中的文本内容全部提取到一个字符串中
- text_list.append(text_str) # 字符串形式的文本内容防止到all_text列表中
- print(title_list)
- print(text_list)
案例5:58二手房
- import requests
- from lxml import etree
- url ='https://bj.58.com/shahe/ershoufang/?utm_source=market&spm=u-2d2yxv86y3v43nkddh1.BDPCPZ_BT&PGTID=0d30000c-0047-e4e6-f587-683307ca570e&ClickID=1'
- headers = {
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
- }
- page_text = requests.get(url=url,headers=headers).text
- tree = etree.HTML(page_text)
- li_list = tree.xpath('//ul[@class="house-list-wrap"]/li')
- fp = open('58.csv','w',encoding='utf-8')
- for li in li_list:
- title = li.xpath('./div[2]/h2/a/text()')[0]
- price = li.xpath('./div[3]//text()')
- price = ''.join(price)
- fp.write(title+":"+price+'\n')
- fp.close()
- print('over')
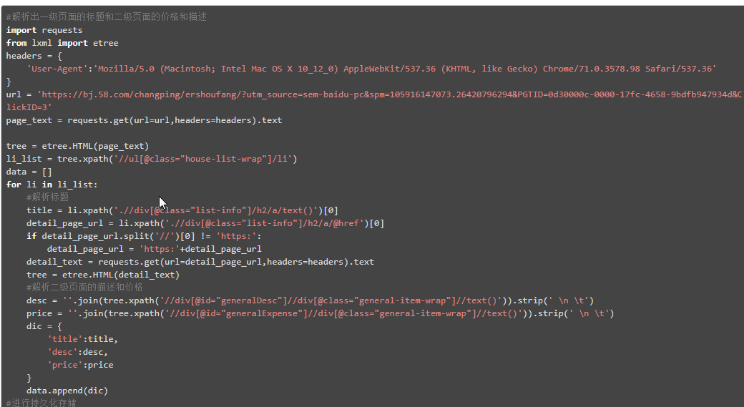
案例6:http://pic.netbian.com/4kmeinv/
- import requests
- from lxml import etree
- import os
- import urllib
- url = 'http://pic.netbian.com/4kmeinv/'
- headers = {
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
- }
- response = requests.get(url=url,headers=headers)
- #response.encoding = 'utf-8'
- if not os.path.exists('./imgs'):
- os.mkdir('./imgs')
- page_text = response.text
- tree = etree.HTML(page_text)
- li_list = tree.xpath('//div[@class="slist"]/ul/li')
- for li in li_list:
- img_name = li.xpath('./a/b/text()')[0]
- #处理中文乱码
- img_name = img_name.encode('iso-8859-1').decode('gbk')
- img_url = 'http://pic.netbian.com'+li.xpath('./a/img/@src')[0]
- img_path = './imgs/'+img_name+'.jpg'
- urllib.request.urlretrieve(url=img_url,filename=img_path)
- print(img_path,'下载成功!')
- print('over!!!')
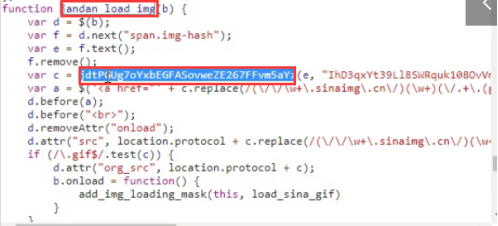
案例7:下载煎蛋网中的图片数据:http://jandan.net/ooxx【重点】src加密*****
- import requests
- from lxml import etree
- from fake_useragent import UserAgent
- import base64
- import urllib.request
- url = 'http://jandan.net/ooxx'
- ua = UserAgent(verify_ssl=False,use_cache_server=False).random
- headers = {
- 'User-Agent':ua
- }
- page_text = requests.get(url=url,headers=headers).text
- tree = etree.HTML(page_text)
- #在抓包工具的数据包响应对象对应的页面中进行xpath的编写,而不是在浏览器页面中。
- #获取了加密的图片url数据
- imgCode_list = tree.xpath('//span[@class="img-hash"]/text()')
- imgUrl_list = []
- for url in imgCode_list:
- img_url = 'http:'+base64.b64decode(url).decode() #base64.b64decode(url)为byte类型,需要转成str
- imgUrl_list.append(img_url)
- for url in imgUrl_list:
- filePath = url.split('/')[-1]
- urllib.request.urlretrieve(url=url,filename=filePath)
- print(filePath+'下载成功')
查看页面源码:发现所有图片的src值都是一样的。简单观察会发现每张图片加载都是通过jandan_load_img(this)这个js函数实现的。在该函数后面还有一个class值为img-hash的标签,里面存储的是一组hash值,该值就是加密后的img地址。加密就是通过js函数实现的,所以分析js函数,获知加密方式,然后进行解密。
通过抓包工具抓取起始url的数据包,在数据包中全局搜索js函数名(jandan_load_img),然后分析该函数实现加密的方式。在该js函数中发现有一个方法调用,该方法就是加密方式,对该方法进行搜索。搜索到的方法中会发现base64和md5等字样,md5是不可逆的所以优先考虑使用base64解密。




案例7:爬取站长素材中的简历模板
- import requests
- import random
- from lxml import etree
- headers = {
- 'Connection':'close', # 当请求成功后,马上断开该次请求(及时释放请求池中的资源)
- 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'
- }
- url = 'http://sc.chinaz.com/jianli/free_%d.html'
- for page in range(1,4): # 因为第一页和其他页url格式不一样,所以分情况讨论
- if page == 1:
- new_url = 'http://sc.chinaz.com/jianli/free.html'
- else:
- new_url = format(url%page)
- response = requests.get(url=new_url,headers=headers)
- response.encoding = 'utf-8' # 中文乱码,先调整编码方式
- page_text = response.text
- tree = etree.HTML(page_text)
- div_list = tree.xpath('//div[@id="container"]/div')
- for div in div_list:
- detail_url = div.xpath('./a/@href')[0]
- name = div.xpath('./a/img/@alt')[0]
- detail_page = requests.get(url=detail_url,headers=headers).text
- tree = etree.HTML(detail_page)
- download_list = tree.xpath('//div[@class="clearfix mt20 downlist"]/ul/li/a/@href') # 这样获得的是每个的所有下载链接
- download_url = random.choice(download_list) # 为了防止每个链接因请求过于频繁被禁,随机选择一个
- data = requests.get(url=download_url,headers=headers).content
- fileName = name+'.rar'
- with open(fileName,'wb') as fp:
- fp.write(data)
- print(fileName,'下载成功')
Alt里面的图片名称是中文,要注意打印看一下会不会有乱码

有乱码,尝试用第一种方式是否可以解决,可以解决就不用第二种方式
详情页中每个li标签对应一个下载地址
li标签里有一个a

05 requests模块进阶的更多相关文章
- 爬虫中之Requests 模块的进阶
requests进阶内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 引入 有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个 ...
- 爬虫基础之requests模块
1. 爬虫简介 1.1 概述 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本. 1.2 爬虫的价值 在互 ...
- 洗礼灵魂,修炼python(61)--爬虫篇—【转载】requests模块
requests 1.简介 Requests 是用Python语言编写的第三方库,所以你需要pip安装,安装过程就略过了.它基于urllib,采用 Apache2 Licensed 开源协议的 HTT ...
- 2 爬虫 requests模块
requests模块 Requests是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库,Requests它会比urllib更加方便,reques ...
- requests模块基础
requests模块 .caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { bor ...
- 爬虫requests模块 1
让我们从一些简单的示例开始吧. 发送请求¶ 使用 Requests 发送网络请求非常简单. 一开始要导入 Requests 模块: >>> import requests 然后,尝试 ...
- requests 模块
发送请求 使用Requests发送网络请求非常简单. 一开始要导入Requests模块: >>> import requests 然后,尝试获取某个网页.本例子中,我们来获取Gith ...
- requests模块--python发送http请求
requests模块 在Python内置模块(urllib.urllib2.httplib)的基础上进行了高度的封装,从而使得Pythoner更好的进行http请求,使用Requests可以轻而易举的 ...
- Python requests模块学习笔记
目录 Requests模块说明 Requests模块安装 Requests模块简单入门 Requests示例 参考文档 1.Requests模块说明 Requests 是使用 Apache2 Li ...
随机推荐
- python中的字典,if_while使用
1.定义两个字典用于表述你的个人信息 第一个字典存放你的这些信息:姓名.性别.年龄.身高第二个字典存放你的其他信息:性格.爱好.座右铭将两个字典合并为第三个字典之后,打印出来 觉得自己很年轻的,可以去 ...
- Java EE产生的背景
为了满足开发多层体系结构的企业级应用的需求,Java公司的创始人Sun公司在早期的J2SE(Java 2 Platform Standard Edition)基础上,针对企业级应用的各种需求,提出了J ...
- 【Arduino】66种传感器系列实验(1)---干簧管传感器模块
37款传感器与模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器和各种模块,依照实践(动手试试)出真知的理念,以学习和交流为目的,这里 ...
- Hack The Box Web Pentest 2019
[20 Points] Emdee five for life [by L4mpje] 问题描述: Can you encrypt fast enough? 初始页面,不管怎么样点击Submit都会显 ...
- 【Java】Map
今天用到了键-值对,于是想起了 Java 的 Map,由于之前并不很熟悉,就看了下源码,如下: /* * Copyright (c) 1997, 2006, Oracle and/or its aff ...
- DevOps相关知识点
DevOps 持续集成 简述 持续集成简称CI,是软件的开发和发布标准流程的最重要的部分 作为一个开发实践,在C中可以通过自动化等手段高频地去获取产品反馈并响应反馈的过程 简单的来说,持续集成就是持续 ...
- 自定义SWT控件七之自定义Shell(可伸缩窗口)
7.可伸缩窗口 该自定义窗口可以通过鼠标随意更改窗口大小 package com.hikvision.encapsulate.view.control.shell; import org.eclips ...
- Kibana对数据的可视化
基于上一篇的操作,我们已经获得了数据,接下来我们就要处理数据,因此选用了Kibana 先来介绍一下, Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索.查看交互存储在E ...
- Resource 使用详解
极力推荐文章:欢迎收藏 Android 干货分享 阅读五分钟,每日十点,和您一起终身学习,这里是程序员Android 本篇文章主要介绍 Android 开发中的部分知识点,通过阅读本篇文章,您将收获以 ...
- 商贸型企业 Java 收货 + 入库 + 生成付款单
package cn.hybn.erp.modular.system.service.impl; import cn.hybn.erp.core.common.page.LayuiPageFactor ...