Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求,使得我们的爬虫更强大、更高效。
一、项目分析
豆瓣电影网页爬虫,要求使用scrapy框架爬取豆瓣电影 Top 250网页(https://movie.douban.com/top250?start=0)上所罗列上映电影的标题、主要信息、评分和电影简介等的信息,将所爬取的内容保存输出为CSV和JSON格式文件,在python程序代码中要求将所输出显示的内容进行utf-8类型编码。
1. 网页分析
对于本例实验,要求爬取的豆瓣电影 Top 250网页上的电影信息,显而易见,网页(https://movie.douban.com/top250?start=0)的页面布局结构可如图2-1所示:
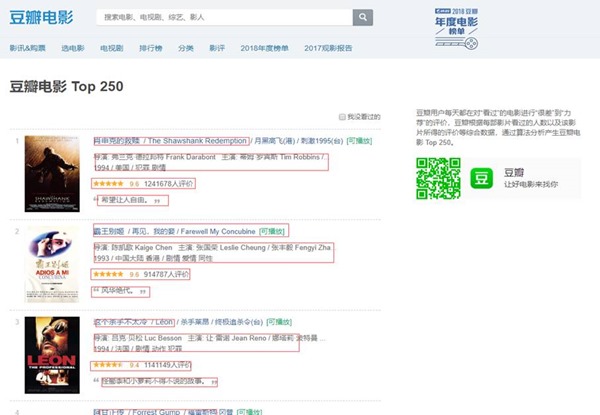
图1-1 所要爬取的信息页面布局
使用xpath_helper_2_0_2辅助工具,对其中上映电影的标题、主要信息、评分和电影简介等的信息内容进行xpath语法分析如下:
标题://div[@class='info']//span[@class='title'][1]/text()
信息://div[@class='info']//div[@class='bd']/p[@class='']/text()
评分:.//div[@class='bd']/div[@class='star']/span[@class='rating_num']/text()
简介://div[@class='info']//div[@class='bd']/p[@class='quote']/span/text()
2. url分析
获取url进行解析移交给scrapy,而对于request类,含有的参数 url 与callback回调函数为parse_details。出现搜索到的url不全,加上当前目录的url拼接,采用prase.urljoin(base,url),最后获取下一页url交给scrapy ,再用Request进行返回。
换句话说,Spiders处理response时,提取数据并将数据经ScrapyEngine交给ItemPipeline保存,提取url重新经ScrapyEngine交给Scheduler进行下一个循环。直到无Url请求程序停止结束。
二、项目工具
Python 3.7.1 、 JetBrains PyCharm 2018.3.2 其它辅助工具:略
三、项目过程
(一)使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析,绘制如图3-1所示的程序逻辑框架图:
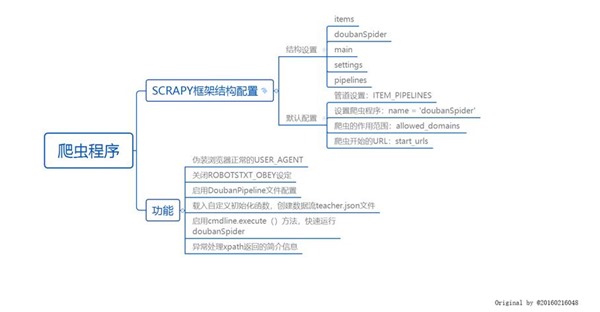
图3-1 程序逻辑框架图
(二)爬虫程序调试过程BUG描述(截图)
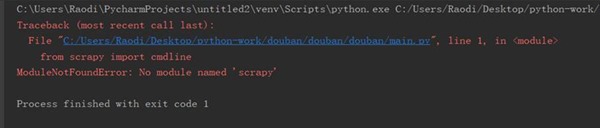
图3-2 爬虫程序BUG描述①
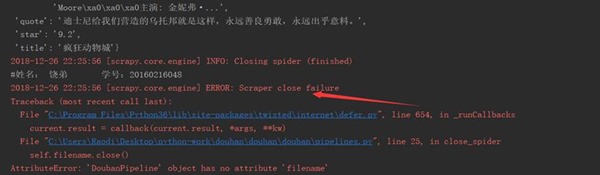
图3-3 爬虫程序BUG描述②
(三)爬虫运行结果
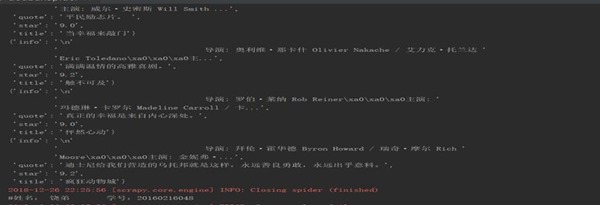
图3-4 爬虫程序输出运行结果1
图3-5 爬虫程序输出文件
四、项目心得
关于本例实验心得可总结如下:
1、 当Scrapy执行crawl命令报错:ModuleNotFoundError: No module named ***时,应该首先检查Project Interpreter是否为系统安装的python环境路径,如图4-1所示:
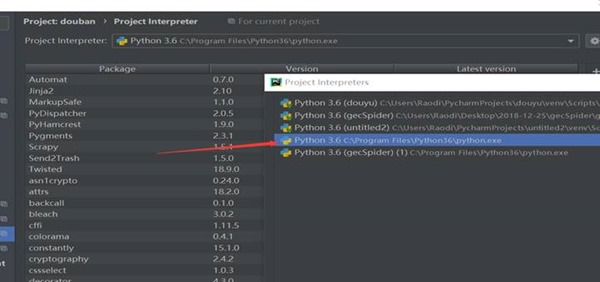
图4-1 检查Project Interpreter路径
2、 schelduler会按照一定的次序取出请求,经由引擎, 下载器中间键,发送给下载器dowmloader 这里的下载器中间键是设定在请求执行前,因此可以设定代理,请求头,cookie等
3、 spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器scheduler request特别多并且速度特别快会在scheduler形成请求队列queue,由scheduler安排执行
Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计的更多相关文章
- Scrapy项目 - 源码工程 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.项目目录结构 spiders文件夹内包含doubanSpider.py文件,对于项目的构建以及结构逻辑,详见环境搭建篇. 二.项目源码 1.doubanSpider.py # -*- coding ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
- Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等.熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析. 一.项目 ...
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- python 豆瓣top250电影的爬取
我们先看一下豆瓣的robot.txt 然后我们查看top250的网页链接和源代码 通过对比不难发现网页间只是start数字发生了变化. 我们可以知道电影内容都存在ol标签下的 div class属性为 ...
- Scrapy项目 - 数据简析 - 实现斗鱼直播网站信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 2-3个图,作业文字描述) 本次将所爬取的数据信息,如:房间数,直播类别和人气,导入Weka 3.7工具进行数据分析.有关本次的数据分析详情详见下图所示: ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- Scrapy项目 - 项目源码 - 实现腾讯网站社会招聘信息爬取的爬虫设计
1.tencentSpider.py # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem #创建爬虫 ...
- requests爬取豆瓣top250电影信息
''' 1.爬取豆瓣top250电影信息 - 第一页: https://movie.douban.com/top250?start=0&filter= - 第二页: https://movie ...
随机推荐
- 随笔编号-15 重构--改善既有代码的设计--Day01--学习笔记
最近公司开发的系统在进行大批量数据查询的时候发现响应速度变得让人无法忍受,so 老大安排我进行代码重构的工作,主要目的就是为提高代码的执行效率.减小方法之间的响应时间.降低方法之间的耦合度.= =! ...
- 剖析nsq消息队列(一) 简介及去中心化实现原理
分布式消息队列nsq,简单易用,去中心化的设计使nsq更健壮,nsq充分利用了go语言的goroutine和channel来实现的消息处理,代码量也不大,读不了多久就没了.后期的文章我会把nsq的源码 ...
- Sql Server中变的定义以及赋值的应用
--申明变量declare @ad_begin datetimedeclare @fydl varchar(50)declare @userid varchar(50)declare @jdrbm v ...
- lightoj 1030-B - Discovering Gold (概率dp)
题意:有一个直线的金矿,每个点有一定数量的金子:你从0开始,每次扔个骰子,扔出几点就走几步, 然后把那个点的金子拿走:如果扔出的骰子超出了金矿,就重新扔,知道你站在最后一个点:问拿走金 子的期望值是多 ...
- hdu 3966 Aragorn's Story(树链剖分+区间修改+单点查询)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3966 题意:给一棵树,并给定各个点权的值,然后有3种操作: I C1 C2 K: 把C1与C2的路径上 ...
- Codeforces Round #582 (Div. 3)
题目链接:https://codeforces.com/contest/1213 A: 题意:给定数的位置,位置为整数,每个数可以向左或右移动一格或者两格,移动一格花费一个硬币,两格不花费硬币,问所有 ...
- ASP.NET Core结合Nacos来完成配置管理和服务发现
目录 前言 Nacos的简介 启动Nacos 配置管理 服务发现 写在最后 前言 今年4月份的时候,和平台组的同事一起调研了一下Nacos,也就在那个时候写了.net core版本的非官方版的SDK. ...
- Win7下部署Lepus企业级MySQL数据库监控
从官网下载(http://www.lepus.cc/soft/17)安装包后,解压到phpStudy的www目录下: 打开phpStudy管理界面,找到站点管理,并新增站点: 在浏览器里面打开后,报此 ...
- .NetCore技术研究-ConfigurationManager在单元测试下的坑
最近在将原有代码迁移.NET Core, 代码的迁移基本很快,当然也遇到了不少坑,重构了不少,后续逐步总结分享给大家.今天总结分享一下ConfigurationManager遇到的一个问题. 先说一下 ...
- 对TD tree系统评价及改进
该系统是由石家庄铁道大学2017级信息学院的同学研发并改进,分享给我们18级新生的一份体验,这项app可安装在任意一个智能手机上,当听到学长们像我们介绍这款app的时候,着实让我惊呆了,惊叹学长们的编 ...