Redis 学习笔记(篇六):数据库
Redis 是一个使用 C 语言编写的 NoSql 的数据库,本篇就讲解在 Redis 中数据库是如何存储的?以及和数据库有关的一些操作。
Redis 中的所有数据库都保存在 redis.h/redisServer 结构中的 db 数组中,如下:
struct redisServer {......// 数据库redisDb *db;......}
Redis 默认会创建 16 个数据库,每个数据库互不影响。
切换数据库
每个 Redis 客户端也都有自己的目标数据库,默认情况下,Redis客户端的目标数据库是 0 号数据库。但客户端也可以通过 select 命令来切换目标数据库。
在服务器内部,客户端状态 redisClient 结构的 db 属性记录了客户端当前的目标数据库,如下:
typedef struct redisClient {// 套接字描述符int fd;// 当前正在使用的数据库redisDb *db;// 当前正在使用的数据库的 id (号码)int dictid;// 客户端的名字robj *name; /* As set by CLIENT SETNAME */} redisClient;
假如某个客户端的目标数据库为 1 号数据库,那么这个客户端所对应的客户端状态和服务器状态之间的关系如下(出自《Redis设计与实现第二版》第九章:数据库):
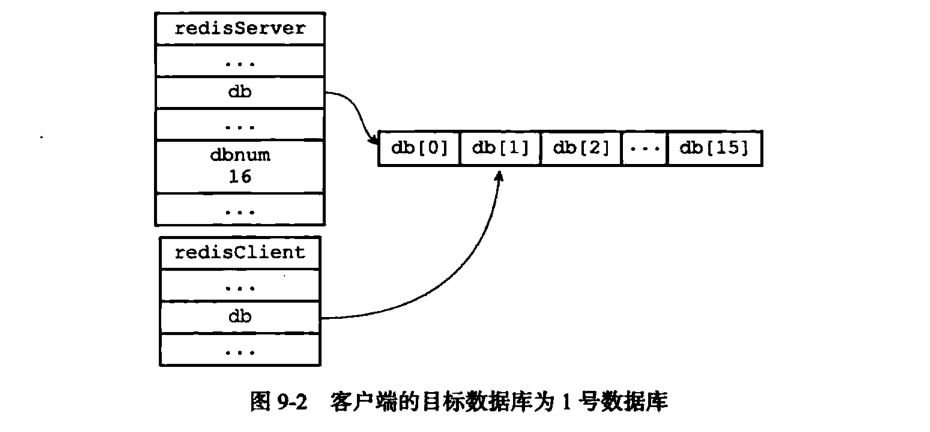
注意: 到目前为止,Redis 仍然没有返回客户端目标数据库的命令,所以尽量不要在项目中使用多数据库,以免造成混乱。
数据库键空间
Redis 是一个键值对数据库服务器,服务器中的每个数据库都由一个 redis.h/redisDb 结构表示,具体结构如下:
typedef struct redisDb {// 数据库键空间,保存着数据库中的所有键值对dict *dict; /* The keyspace for this DB */// 键的过期时间,字典的键为键,字典的值为过期事件 UNIX 时间戳dict *expires; /* Timeout of keys with a timeout set */// 正处于阻塞状态的键dict *blocking_keys; /* Keys with clients waiting for data (BLPOP) */// 可以解除阻塞的键dict *ready_keys; /* Blocked keys that received a PUSH */// 正在被 WATCH 命令监视的键dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */struct evictionPoolEntry *eviction_pool; /* Eviction pool of keys */// 数据库号码int id; /* Database ID */// 数据库的键的平均 TTL ,统计信息long long avg_ttl; /* Average TTL, just for stats */} redisDb;
键空间(db 属性)和用户所见的数据库是直接对应的:
- 键空间的键也就是数据库的键,每个键都是一个字符串对象。
- 键空间的值也就是数据库的值,每个值可以是字符串对象、列表对象、哈希表对象、集合对象和有序集合对象中的任意一种 Redis 对象。
而在数据库中添加、修改、删除键也都是操作的 db 字典。
键的过期策略
Redis 中设置键的过期时间有四种写法:
- expire key t1 :表示将键 key 的生存时间设置为 t1 秒。
- pexpire key t1 :表示将键 key 的生存时间设置为 t1 毫秒。
- expireat key t1 :表示将键 key 的过期时间设置为 t1 所指定的秒数时间戳。
- pexpireat key t1 :表示将键 key 的过期时间设置为 t1 所指定的毫秒数时间戳。
虽然有 4 种不同的写法,但这些做的都是一件事,所以可以抽成一个统一的方法。而实际上 Redis 也正是这么做的,expire、pexpire、expireat 三个命令都是使用 pexpireat 命令来实现的。
Redis 如何存储键的过期时间呢?
redisDb 结构的 expires 字典保存了数据库中所有键的过期时间,我们称这个字典为过期字典:
- 过期字典的键是一个指针,这个指针指向键空间中的某个键对象(也即是某个数据库键)。
- 过期字典的值是一个 long long 类型的整数,这个整数保存了键所指向的数据库键的过期时间(一个毫秒精度的 UNIX 时间戳)。
Redis 如何移除键的过期时间呢?
命令是: persist key
Redis 数据库做的操作也仅仅是在 expires 字典中删除对应的键值对。
Redis 如何判断一个键是否过期呢?
通过 expires 字典,程序可以用以下步骤检查一个给定键是否过期:
- 检查给定键是否存在于过期字典:如果存在,那么取得键的过期时间。
- 检查当前 UNIX 时间戮是否大于键的过期时间:如果是的话,那么键已经过期;否则的话,键未过期。
Redis 具体是如何删除一个过期的键呢?
我们知道数据库键的过期时间都保存在过期字典中,又知道了如何根据过期时间去判断一个键是否过期,现在剩下的问题是:如果一个键过期了,那么它什么时候会被删除呢?
这个问题有三种可能的答案,它们分别代表了三种不同的删除策略:
- 定时删除:在设置键的过期时间的同时,创建一个定时器(timer) 。让定时器在键的过期时间来临时,立即执行对键的侧除操作。
- 惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就侧除该键;如果没有过期,就返回该键。
- 定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键。至于要删除多少过期键,以及要检查多少个数据库,则由算法决定。
在这三种策略中,第一种和第三种为主动删除策略,而第二种为被动侧除策略。而无论是哪种策略都有其优点和缺点。
对于定时删除来说:
- 优点是可以保证过期键会尽可能快的被删除,并释放过期键所占用的内存;
- 缺点则是会占用一部分 CPU 时间,尤其是当键非常多的时候,占用的 CPU 时间也会增多,这是不可忍受的。
对于惰性删除来说:
- 程序只会在取出键是进行检查,所以优点是几乎不不占用 CPU 时间;
- 缺点则是可能会造成内存泄漏,比如当键过期之后永远不再访问,这时候就是内存泄漏了。
对于定期删除来说,则是以上两种策略的一种整合,定期删除策略每隔一段时间执行一次删除过期键操作,并通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响;除此之外,通过定期删除过期键,定期删除策略有效地减少了因为过期键而带来的内存浪费。
定期删除策略的难点是确定删除操作执行的时长和频率:
- 如果删除操作执行得太频繁,或者执行的时间太长,定期删除策略就会退化成定时删除策略,以至于将 CPU 时间过多地消耗在侧除过期键上面。
- 如果删除操作执行得太少,或者执行的时间太短,定期删除策略又会和惰性删除策略一样,出现浪费内存的情况。
因此,如果采用定期侧除策略的话,服务器必须根据情况,合理地设置删除操作的执行时长和执行频率。
而 Redis 中则使用了定期删除和惰性删除两种策略,很好的在 CPU 和内存上面取得了一个平衡。
惰性删除
过期键的惰性删除策略由 db.c/expireIfNeeded 函数实现,所有读写数据库的 Redis 命令在执行之前都会调用 expireIfNeeded 函数对输入键进行检查:
- 如果输人键已经过期,那么 expireIfNeeded 函数将输入键从数据库中删除。
- 如果输人键未过期,那么 expireIfNeeded 函数不做动作。
expireIfNeeded 函数就像一个过滤器,它可以在命令真正执行之前,过滤掉过期的输人键,从而避免命令接触到过期键。函数的具体代码如下:
/** 检查 key 是否已经过期,如果是的话,将它从数据库中删除。** 返回 0 表示键没有过期时间,或者键未过期。** 返回 1 表示键已经因为过期而被删除了。*/int expireIfNeeded(redisDb *db, robj *key) {// 取出键的过期时间mstime_t when = getExpire(db,key);mstime_t now;// 没有过期时间if (when < 0) return 0; /* No expire for this key */// 如果服务器正在进行载入,那么不进行任何过期检查if (server.loading) return 0;/* If we are in the context of a Lua script, we claim that time is* blocked to when the Lua script started. This way a key can expire* only the first time it is accessed and not in the middle of the* script execution, making propagation to slaves / AOF consistent.* See issue #1525 on Github for more information. */now = server.lua_caller ? server.lua_time_start : mstime();/* If we are running in the context of a slave, return ASAP:* the slave key expiration is controlled by the master that will* send us synthesized DEL operations for expired keys.** Still we try to return the right information to the caller,* that is, 0 if we think the key should be still valid, 1 if* we think the key is expired at this time. */// 当服务器运行在 replication 模式时// 附属节点并不主动删除 key// 它只返回一个逻辑上正确的返回值// 真正的删除操作要等待主节点发来删除命令时才执行// 从而保证数据的同步if (server.masterhost != NULL) return now > when;// 运行到这里,表示键带有过期时间,并且服务器为主节点/* Return when this key has not expired */// 如果未过期,返回 0if (now <= when) return 0;/* Delete the key */server.stat_expiredkeys++;// 向 AOF 文件和附属节点传播过期信息propagateExpire(db,key);// 发送事件通知notifyKeyspaceEvent(REDIS_NOTIFY_EXPIRED,"expired",key,db->id);// 将过期键从数据库中删除return dbDelete(db,key);}
命令调用 expireIfNeeded 来删除过期键的过程和 get 命令的执行过程如下(出自《Redis设计与实现第二版》第九章:数据库):

定期删除
过期键的定期删除策略由 redis.c/activeExpireCycle 函数实现,调用流程为 serverCron() -> databasesCron() -> activeExpireCycle()。核心代码如下(为了方便查看核心部分,对代码进行了截取):
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {......// 对数据库执行各种操作databasesCron();......}// 对数据库执行删除过期键,调整大小,以及主动和渐进式 rehashvoid databasesCron(void) {// 函数先从数据库中删除过期键,然后再对数据库的大小进行修改/* Expire keys by random sampling. Not required for slaves* as master will synthesize DELs for us. */// 如果服务器不是从服务器,那么执行主动过期键清除if (server.active_expire_enabled && server.masterhost == NULL)// 清除模式为 CYCLE_SLOW ,这个模式会尽量多清除过期键activeExpireCycle(ACTIVE_EXPIRE_CYCLE_SLOW);/* Perform hash tables rehashing if needed, but only if there are no* other processes saving the DB on disk. Otherwise rehashing is bad* as will cause a lot of copy-on-write of memory pages. */// 在没有 BGSAVE 或者 BGREWRITEAOF 执行时,对哈希表进行 rehashif (server.rdb_child_pid == -1 && server.aof_child_pid == -1) {......}}void activeExpireCycle(int type) {......// 遍历数据库for (j = 0; j < dbs_per_call; j++) {int expired;// 指向要处理的数据库redisDb *db = server.db+(current_db % server.dbnum);// 为 DB 计数器加一,如果进入 do 循环之后因为超时而跳出// 那么下次会直接从下个 DB 开始处理current_db++;do {unsigned long num, slots;long long now, ttl_sum;int ttl_samples;// 获取数据库中带过期时间的键的数量// 如果该数量为 0 ,直接跳过这个数据库if ((num = dictSize(db->expires)) == 0) {db->avg_ttl = 0;break;}// 获取数据库中键值对的数量slots = dictSlots(db->expires);// 当前时间now = mstime();// 这个数据库的使用率低于 1% ,扫描起来太费力了(大部分都会 MISS)// 跳过,等待字典收缩程序运行if (num && slots > DICT_HT_INITIAL_SIZE &&(num*100/slots < 1)) break;/** 样本计数器*/// 已处理过期键计数器expired = 0;// 键的总 TTL 计数器ttl_sum = 0;// 总共处理的键计数器ttl_samples = 0;// 每次最多只能检查 LOOKUPS_PER_LOOP 个键if (num > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP)num = ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP;// 开始遍历数据库while (num--) {dictEntry *de;long long ttl;// 从 expires 中随机取出一个带过期时间的键if ((de = dictGetRandomKey(db->expires)) == NULL) break;// 计算 TTLttl = dictGetSignedIntegerVal(de)-now;// 如果键已经过期,那么删除它,并将 expired 计数器增一if (activeExpireCycleTryExpire(db,de,now)) expired++;if (ttl < 0) ttl = 0;// 累积键的 TTLttl_sum += ttl;// 累积处理键的个数ttl_samples++;}......// 已经超时了,返回if (timelimit_exit) return;// 如果已删除的过期键占当前总数据库带过期时间的键数量的 25 %// 那么不再遍历} while (expired > ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP/4);}}
几点说明:
- serverCron() 函数是 Redis 的定时器,默认每隔 100ms 运行一次。
- 在 databasesCron() 函数中不只进行了删除过期键还进行了 rehash 操作。
- 如果服务器不是从服务器,才会执行主动过期键清除。
- ACTIVE_EXPIRE_CYCLE_LOOKUPS_PER_LOOP 在 redis.h 中定义,为 20。也就是说一次删除20个过期键。如果不超过设定的时间,每个库可以删除多次。
Redis 学习笔记(篇六):数据库的更多相关文章
- Redis学习笔记(六) 对象
前面我们看了Redis用到的主要数据结构,如简单动态字符串(SDS).双向链表.字典.压缩列表.整数集合等. 但是Redis并没有直接使用这些数据结构来实现键值对,而是基于这些数据结构创建了一个对象系 ...
- Redis学习笔记01--主从数据库配置
1.创建公共配置文件 所有配置文件添加到以下目录: /xxxx/redis-slave-master 创建公共的redis配置文件,直接使用redis的默认配置文件,修改以下配置项: bind 127 ...
- Redis 学习笔记(六)Redis 如何实现消息队列
一.消息队列 消息队列(Messeage Queue,MQ)是在分布式系统架构中常用的一种中间件技术,从字面表述看,是一个存储消息的队列,所以它一般用于给 MQ 中间的两个组件提供通信服务. 1.1 ...
- Redis学习笔记(六)---List
1.ArrayList与LinkList的区别 ArrayList的使用数组存入的方式,所以根据索引查询数据速度快,而增删元素是比较慢的,它需要将数据一位一位的移动,知道达到要求. LinkList使 ...
- Redis学习笔记(六、哨兵)
目录: 基本概念 环境部署 哨兵原理 哨兵命令 基本概念: 1.什么是哨兵 我们先从字面意思来了解哨兵,哨兵是对执行警戒任务的士兵的统称:在redis中哨兵也是一样,他监控着redis服务器的状态. ...
- Redis学习笔记(六)——数据结构之Set
一.介绍 Redis的Set是string类型的无序集合.集合成员是唯一的,这就意味着集合中不能出现重复的数据. Redis中集合是通过哈希表实现的,所以添加.删除.查找的复杂度都是O(1). 集合中 ...
- Redis学习笔记(六)有序集合进阶
1.基础操作 ZCARD(获取成员数量) ZINCRBY key_name num member(将member的分数加num) ZCOUNT key_name min max(获取分数在min与ma ...
- Redis学习笔记(六) 基本命令:List操作
原文链接:http://doc.redisfans.com/list/index.html lpush key value[value...] 将一个或多个value插入到列表的表头:例:lpush ...
- Redis学习笔记(二) Redis 数据类型
Redis 支持五种数据类型:string(字符串).list(列表).hash(哈希).set(集合)和 zset(有序集合),接下来我们讲解分别讲解一下这五种类型的的使用. String(字符串) ...
- redis学习笔记(详细)——高级篇
redis学习笔记(详细)--初级篇 redis学习笔记(详细)--高级篇 redis配置文件介绍 linux环境下配置大于编程 redis 的配置文件位于 Redis 安装目录下,文件名为 redi ...
随机推荐
- Centos7安装Mysql-最方便、最快捷
你想在Linux操作系统安装Mysql?你不想去官网下载再复制?,那就来看看我的方案,简单.快捷轻松安装.使用. 首先,检查安装情况 1.查看有没有安装过: yum ...
- Js判断当前浏览者的操作系统
function validataOS(){ var userAgent = navigator.userAgent; if(userAgent.indexOf('Window')>0){ re ...
- asp.net mvc中使用jquery H5省市县三级地区选择控件
地区选择是项目开发中常用的操作,本文讲的控件是在手机端使用的选择控件,不仅可以用于实现地区选择,只要是3个级别的选择都可以实现,比如专业选择.行业选择.职位选择等.效果如下图所示: 附:本实例asp. ...
- "犯罪心理"解读Mybatis拦截器
原文链接:"犯罪心理"解读Mybatis拦截器 Mybatis拦截器执行过程解析 文章写过之后,我觉得 "Mybatis 拦截器案件"背后一定还隐藏着某种设计动 ...
- 程序代写, CS代写, 代码代写, CS编程代写, java代写, python代写, c++/c代写, R代写, 算法代写, web代写
互联网一线工程师程序代写 微信联系 当天完成 查看大牛简介特色: 学霸代写,按时交付,保证原创,7*24在线服务,可加急.用心代写/辅导/帮助客户CS作业. 客户反馈与评价 服务质量:保证honor ...
- 给 Windows 的终端配置代理
初衷 由于项目开发使用go,所以经常要用到go get,但是吧,terminal下根本没办法下载啊,经常下载三个小时包,写代码一个小时 迫于无奈,只好找个方式可以在terminal下使用ss cmd下 ...
- 秒懂Hash算法(一):什么是Hash
Hash函数 在一般的线性表.树结构中,数据的存储位置是随机的,不像数组可以通过索引能一步查找到目标元素.为了能快速地在没有索引之类的结构中找到目标元素,需要为存储地址和值之间做一种映射关系h(key ...
- Visual Studio模板代码注释小技巧分享
在日常开发过程中,难免有这样一种需求:就是你所建的每一个类文件或者接口文件都需要标注下作者姓名以及类的用途.如果我们每次创建文件的时候都需要写一遍这些信息是很烦神的.还好Visual Studio给我 ...
- Confluence5.6.6安装和破解
1.安装confluence 1. 软件环境说明 # 安装 jdk [root@wiki_5-- jar]# cat /etc/redhat-release CentOS Linux release ...
- 一个commit引发的思考
这几天我翻了翻golang的提交记录,发现了一条很有意思的提交:bc593ea,这个提交看似简单,但是引人深思. commit讲了什么 commit的标题是"sync: document i ...