Spring Cloud Sleuth+ZipKin+ELK服务链路追踪(七)
序言
sleuth是spring cloud的分布式跟踪工具,主要记录链路调用数据,本身只支持内存存储,在业务量大的场景下,为拉提升系统性能也可通过http传输数据,也可换做rabbit或者kafka来传输数据。
zipkin是Twitter开源的分布时追踪系统,可接收数据,存储数据(内存/cassandra/mysql/es),检索数据,展示数据,他本神不会直接在分布式的系统服务种trace追踪数据,可便捷的使用sleuth来收集传输数据。
这样描述,大家应该很清晰啦。
服务追踪意义
目前流行的架构现状,都是站在微服务架构的基础之上,那么势必会产生出越来越多的服务,相互依赖调用,那么如果服务调用关系如下图所示。

越来越多的服务可能,调用关系就如下啦,一团乱麻,如果没有服务之间的链路追踪的记录查询方案,想快速定位问题,翻代码都不知从何翻起,估计锁定责任人更要撕逼一翻啦,哈哈。

行业方案
Google开源的 Dapper链路追踪组件,并在2010年发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这篇文章是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。
链路追踪组件有如下产品,都很赞,很值得学习:
- Google的Dapper
- Twitter的Zipkin
- 阿里的Eagleeye (鹰眼)
- 美团点评的Cat
- 新浪的Watchman
- 京东的Hydra
- 个人吴晟(华为开发者)开源的skywalking (很赞)
- 韩国团队naver团队开源pinpoint
有时间大家学习一番啊。
Sleuth链路追踪专业术语
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
- Span:基本工作单元,例如,在一个新建的span中发送一个RPC等同于发送一个回应请求给RPC,span通过一个64位ID唯一标识,trace以另一个64位ID表示,span还有其他数据信息,比如摘要、时间戳事件、关键值注释(tags)、span的ID、以及进度ID(通常是IP地址),span在不断的启动和停止,同时记录了时间信息,当你创建了一个span,你必须在未来的某个时刻停止它。
- Trace:一系列spans组成的一个树状结构,例如,如果你正在跑一个分布式大数据工程,你可能需要创建一个trace。
- Annotation:用来及时记录一个事件的存在,一些核心annotations用来定义一个请求的开始和结束
- cs - Client Sent -客户端发起一个请求,这个annotion描述了这个span的开始
- sr - Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络延迟
- ss - Server Sent -注解表明请求处理的完成(当请求返回客户端),如果ss减去sr时间戳便可得到服务端需要的处理请求时间
- cr - Client Received -表明span的结束,客户端成功接收到服务端的回复,如果cr减去cs时间戳便可得到客户端从服务端获取回复的所有所需时间
将Span和Trace在一个系统中使用Zipkin注解的过程图形化:

trace id 整个链路中是唯一不变的,这样也方便查询。
zipkin介绍
zipkin主要有四个组件:collector,storage,API,web UI。collector用于收集各服务发送到zipkin的数据,storage用于存储这些链路数据,目前支持Cassandra,ElasticSearch(推荐使用,易于大规模扩展)和MySQL,API用来查找和检索跟踪链,提供给界面UI展示。
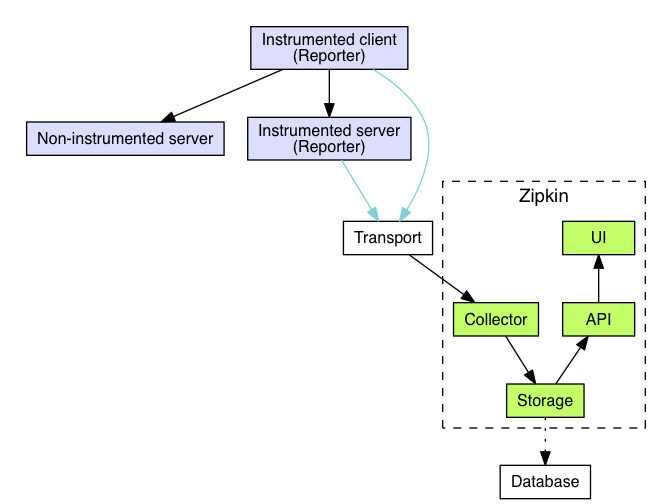
链路的追踪原理:跟踪器位于应用程序中,记录发生的操作的时间和元数据,收集的跟踪数据称为Span,将数据发送到Zipkin的仪器化应用程序中的组件称为Reporter,Reporter通过几种传输方式(http,kafka)之一将追踪数据发送到Zipkin收集器(collector),然后将跟踪数据进行存储(storage),由API查询存储以向UI提供数
具体项目搭建

上面是我的示例项目。
1.trade-zipkin-server是zipkinserver,是用来展示,搜索,存储trade追踪数据用的。
2.shop-->order-->shouhou & promotion(简单的调用链路,这里是具体需要的业务链路追踪的trace项目哈)。
zipkinserver配置代码
@EnableZipkinServer
public class StartMain {
public static void main(String[] args) {
SpringApplication.run(StartMain.class, args);
}
}
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
业务项目配置
spring.sleuth.enabled=true
spring.sleuth.sampler.percentage=1
spring.zipkin.base-url=http://localhost:8087
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
note:
spring.sleuth.sampler.percentage参数配置(如果不配置默认0.1),如果我们调大此值为1,可以看到信息收集就更及时。但是当这样调整后,我们会发现我们的rest接口调用速度比0.1的情况下慢了很多,即使在0.1的采样率下,我们多次刷新consumer的接口,会发现对同一个请求两次耗时信息相差非常大,如果取消spring-cloud-sleuth后我们再测试,会发现并没有这种情况,可以看到这种方式追踪服务调用链路会给我们业务程序性能带来一定的影响。
zipkin收集展示数据界面如下:



seluth+zipkin数据写入Elasticsearch,使用kibana展示
配置zipkinserver
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId>
<version>2.8.4</version>
</dependency>
zipkin.storage.StorageComponent=elasticsearch
zipkin.storage.type=elasticsearch
#可以做集群,我用的本地测试没有部署elastic集群
zipkin.storage.elasticsearch.hosts=es.me.com
zipkin.storage.elasticsearch.cluster=iron-man
zipkin.storage.elasticsearch.index=trade-zipkin
zipkin.storage.elasticsearch.index-shards=5
zipkin.storage.elasticsearch.index-replicas=1

总结
其实,我这个案例,只是让你熟悉了解服务链路追踪,能够兼顾性能的整体方案如下。


Spring Cloud Sleuth+ZipKin+ELK服务链路追踪(七)的更多相关文章
- Spring Cloud Sleuth通过Kafka将链路追踪日志输出到ELK
1.工程简介 elk-eureka-server作为其他三个项目的服务注册中心 elk-kafka-client调用elk-kafka-server,elk-kafka-server再调用elk-ka ...
- 分布式链路追踪之Spring Cloud Sleuth+Zipkin最全教程!
大家好,我是不才陈某~ 这是<Spring Cloud 进阶>第九篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得 ...
- spring cloud 入门系列八:使用spring cloud sleuth整合zipkin进行服务链路追踪
好久没有写博客了,主要是最近有些忙,今天忙里偷闲来一篇. =======我是华丽的分割线========== 微服务架构是一种分布式架构,微服务系统按照业务划分服务单元,一个微服务往往会有很多个服务单 ...
- Spring Cloud Sleuth + Zipkin 链路监控
原文:https://blog.csdn.net/hubo_88/article/details/80878632 在微服务系统中,随着业务的发展,系统会变得越来越大,那么各个服务之间的调用关系也就变 ...
- Spring Cloud Alibaba学习笔记(23) - 调用链监控工具Spring Cloud Sleuth + Zipkin
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求陷入性能瓶颈或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何 ...
- Spring Cloud 微服务六:调用链跟踪Spring cloud sleuth +zipkin
前言:随着微服务系统的增加,服务之间的调用关系变得会非常复杂,这给运维以及排查问题带来了很大的麻烦,这时服务调用监控就显得非常重要了.spring cloud sleuth实现了对分布式服务的监控解决 ...
- 【Spring Cloud】Spring Cloud之Spring Cloud Sleuth,分布式服务跟踪(1)
一.Spring Cloud Sleuth组件的作用 为微服务架构增加分布式服务跟踪的能力,对于每个请求,进行全链路调用的跟踪,可以帮助我们快速发现错误根源以及监控分析每条请求链路上的性能瓶颈等. 二 ...
- 阿里高级架构师教你使用Spring Cloud Sleuth跟踪微服务
随着微服务数量不断增长,需要跟踪一个请求从一个微服务到下一个微服务的传播过程,Spring Cloud Sleuth 正是解决这个问题,它在日志中引入唯一ID,以保证微服务调用之间的一致性,这样你就能 ...
- 全链路spring cloud sleuth+zipkin
http://blog.csdn.net/qq_15138455/article/details/72956232 版权声明:@入江之鲸 一.About ZipKin please google 二. ...
随机推荐
- python基础(25):面向对象三大特性二(多态、封装)
1. 多态 1.1 什么是多态 多态指的是一类事物有多种形态. 动物有多种形态:人,狗,猪. import abc class Animal(metaclass=abc.ABCMeta): #同一类事 ...
- 仅支持基本增删改查的学生自制php操作mysql的工具类 DB.class.php (学生笔记)
<?php class DB{ //主机地址 var $host; //用户名 var $username; //密码 var $password; //数据库名 var $dbname; // ...
- TCP三次握手四次分手—简单详解
关于TCP三次握手四次分手,之前看资料解释的都很笼统,很多地方都不是很明白,所以很难记,前几天看的一个博客豁然开朗,可惜现在找不到了.现在把之前的疑惑总结起来,方便一下大家. 疑问一,上图传递过程中出 ...
- JS 中 判断数据类型 typeof详解
typeof 可用来获取检测变量的数据类型 语法 typeof operand typeof(operand) 参数 operand 一个表示对象或原始值的表达式,其类型将被返回. 描述 下表总结 ...
- 学习springboot第一天~
1. springboot是对spring的缺点进行改善和优化,它的约定大于配置,开箱即用,没有代码生成,也不需要xml文件配置,可以修改属性值来满足需求 2. springboot的入门程序 在id ...
- BayaiM__MYSQL千万级数据量的优化方法积累__初级菜鸟
-----------------------------------------------------------------------------———————-------------- ...
- Linux--简单实现nfs的目录挂载,ntp时间同步
一.NFS (Network FileSystem) 网络文件系统 是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源. 在NFS的应用中,本地NFS的客户端 ...
- greenlet实现协程
#greenlet 1 import time from greenlet import greenlet # greenlet可以实现一个自行调度的微线程 def work1(): while Tr ...
- Linux:使用LVM进行磁盘管理
LVM的概念 LVM 可以实现对磁盘的动态管理,在磁盘不用重新分区的情况下动态调整文件系统的大 小,利用 LVM 管理的文件系统可以跨越磁盘. "/boot"分区用于存放系统引导文 ...
- 使用响应的json数据判断订单查询是否成功;
#查询中通快递import requestsrr=requests.session()headers={"User-Agent": "Mozilla/5.0 (Windo ...