人工智能大语言模型起源篇,低秩微调(LoRA)

上一篇: 《规模法则(Scaling Law)与参数效率的提高》
序言:您在找工作时会不会经常听到LoRA微调,这项技术的来源就是这里了。
(12)Hu、Shen、Wallis、Allen-Zhu、Li、L Wang、S Wang 和 Chen 于2021年发表的《LoRA: Low-Rank Adaptation of Large Language Models》,https://arxiv.org/abs/2106.09685
现代的大型语言模型在大数据集上进行预训练后,展现了突现能力,并且在多种任务中表现优异,包括语言翻译、总结、编程和问答。然而,如果我们希望提升变换器在特定领域数据和专业任务上的能力,微调变换器是非常值得的。
低秩适配(LoRA)是微调大型语言模型的一种非常有影响力的方法,它具有参数高效的特点。虽然还有其他一些参数高效的微调方法(见下文的综述),但LoRA特别值得一提,因为它既优雅又非常通用,可以应用于其他类型的模型。
虽然预训练模型的权重在预训练任务上是全秩的,但LoRA的作者指出,当预训练的大型语言模型适配到新任务时,它们具有低“内在维度”。因此,LoRA的核心思想是将权重变化(ΔW)分解成低秩表示,这样可以更高效地使用参数。

LoRA 的示例及其性能来自 https://arxiv.org/abs/2106.09685。
(13)Lialin、Deshpande 和 Rumshisky 于2022年发表的《Scaling Down to Scale Up: A Guide to Parameter-Efficient Fine-Tuning》,https://arxiv.org/abs/2303.15647
现代的大型语言模型在大数据集上进行预训练后,展现了突现能力,并且在多种任务中表现优异,包括语言翻译、总结、编程和问答。然而,如果我们希望提升变换器在特定领域数据和专业任务上的能力,微调变换器是非常值得的。本文综述了40多篇关于参数高效微调方法的论文(包括前缀调优、适配器、低秩适配等流行技术),旨在使微调过程(变得)更加高效,尤其是在计算上。
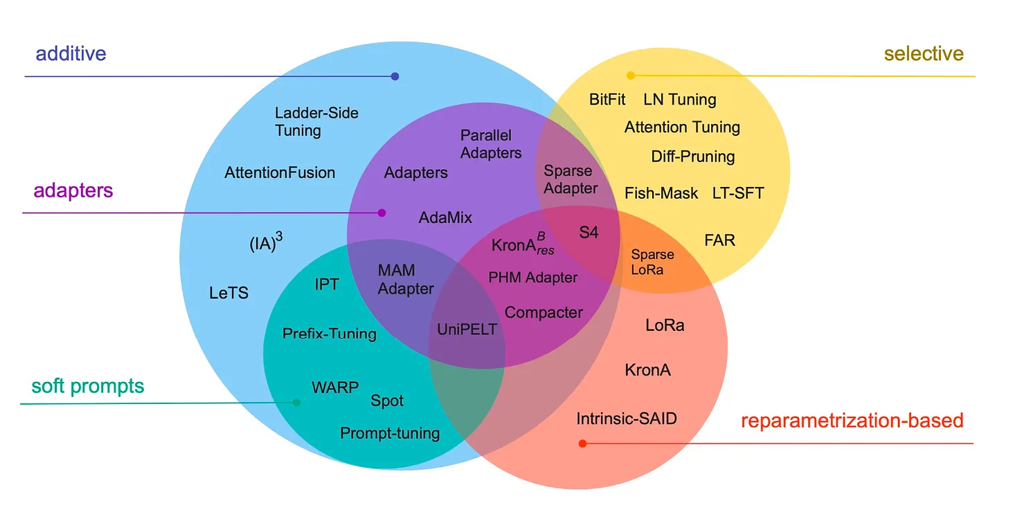
来源:https://arxiv.org/abs/2303.15647
人工智能大语言模型起源篇,低秩微调(LoRA)的更多相关文章
- 本地推理,单机运行,MacM1芯片系统基于大语言模型C++版本LLaMA部署“本地版”的ChatGPT
OpenAI公司基于GPT模型的ChatGPT风光无两,眼看它起朱楼,眼看它宴宾客,FaceBook终于坐不住了,发布了同样基于LLM的人工智能大语言模型LLaMA,号称包含70亿.130亿.330亿 ...
- DyLoRA:使用动态无搜索低秩适应的预训练模型的参数有效微调
又一个针对LoRA的改进方法: DyLoRA: Parameter-Efficient Tuning of Pretrained Models using Dynamic Search-Free Lo ...
- 使用 LoRA 和 Hugging Face 高效训练大语言模型
在本文中,我们将展示如何使用 大语言模型低秩适配 (Low-Rank Adaptation of Large Language Models,LoRA) 技术在单 GPU 上微调 110 亿参数的 F ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- 人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载
人工智能大数据,公开的海量数据集下载,ImageNet数据集下载,数据挖掘机器学习数据集下载 ImageNet挑战赛中超越人类的计算机视觉系统微软亚洲研究院视觉计算组基于深度卷积神经网络(CNN)的计 ...
- zz【清华NLP】图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐
[清华NLP]图神经网络GNN论文分门别类,16大应用200+篇论文最新推荐 图神经网络研究成为当前深度学习领域的热点.最近,清华大学NLP课题组Jie Zhou, Ganqu Cui, Zhengy ...
- 大数据工具篇之Hive与MySQL整合完整教程
大数据工具篇之Hive与MySQL整合完整教程 一.引言 Hive元数据存储可以放到RDBMS数据库中,本文以Hive与MySQL数据库的整合为目标,详细说明Hive与MySQL的整合方法. 二.安装 ...
- 大数据工具篇之Hive与HBase整合完整教程
大数据工具篇之Hive与HBase整合完整教程 一.引言 最近的一次培训,用户特意提到Hadoop环境下HDFS中存储的文件如何才能导入到HBase,关于这部分基于HBase Java API的写入方 ...
- 吴恩达机器学习笔记59-向量化:低秩矩阵分解与均值归一化(Vectorization: Low Rank Matrix Factorization & Mean Normalization)
一.向量化:低秩矩阵分解 之前我们介绍了协同过滤算法,本节介绍该算法的向量化实现,以及说说有关该算法可以做的其他事情. 举例:1.当给出一件产品时,你能否找到与之相关的其它产品.2.一位用户最近看上一 ...
- 【RS】Local Low-Rank Matrix Approximation - LLORMA :局部低秩矩阵近似
[论文标题]Local Low-Rank Matrix Approximation (icml_2013 ) [论文作者]Joonseok Lee,Seungyeon Kim,Guy Lebanon ...
随机推荐
- 使用Minio Clinet将老版本Minio的数据迁移到新版本的Minio
1. 关于Minio Client: MinIO Client是一个命令行工具,用于与Minio或云存储服务进行交互.它支持文件系统和Amazon S3兼容的云存储服务(AWS Signature v ...
- Tomcat——idea集成本地Tomcat
IDEA 集成本地Tomcat 添加配置 添加本地Tomcat服务器 配置本地Tomcat路径 部署项目 在 webapp 中添加一个简单的页面作 ...
- 图解MQTT概念、mosquitto编译和部署 ,写代码,分别使用外网和本地服务器进行测试
前沿提要: MQTT是什么不知道? 看这一篇:https://www.cnblogs.com/happybirthdaytoyou/p/10362336.html 阿里云官网玩不转? 看这一篇: ht ...
- SpringBoot+Docker +Nginx 部署前后端项目
部署SpringBoot项目(通关版) 一.概述 使用 java -jar 命令直接部署项目的JAR包和使用Docker制作镜像进行部署是两种常见的部署方式.以下是对这两种方式的概述和简要的优劣势分析 ...
- Flutter 实现骨架屏
什么是骨架屏 在客户端开发中,我们总是需要等待拿到服务端的响应后,再将内容呈现到页面上,那么在用户发起请求到客户端成功拿到响应的这段时间内,应该在屏幕上呈现点什么好呢? 答案是:骨架屏 那么什么是骨架 ...
- C++指针等于地址加偏移量
概述 本文通过c++示例代码演示指针的加减法运算及对 "指针 = 地址 + 偏移量" 的理解. 研究示例 1. 首先来检查各种变量类型所占的内存大小 #include <io ...
- 1. 王道OS-操作系统的概念、功能
1. 操作系统是指控制和管理整个计算机的硬件和软件资源,并合理地组织调度计算机的工作和资源的分配:以提供给用户和其他软件方便的接口和环境:他是计算机系统最基本的系统软件: 操作系统需要向其他软件提供服 ...
- 如何对 Vue 首屏加载实现优化 ?
首屏加载优化是对于 SPA 来说的 ,首次加载所有的 html css js 所需的文件 ,后面就不会因为用户对页面的操作而跳转页面 ,没有跳转页面如何展示不同的内容呢 ? 使用 Vue 的路由机制 ...
- 在C#中基于Semantic Kernel的检索增强生成(RAG)实践
Semantic Kernel简介 玩过大语言模型(LLM)的都知道OpenAI,然后微软Azure也提供了OpenAI的服务:Azure OpenAI,只需要申请到API Key,就可以使用这些AI ...
- 什么是APP原生开发
什么是APP原生开发?原生App实际上是一种基于智能手机本地操作系统如Android.IOS并且使用原生程序编写运行的第三方移动应用程序.开发原生App软件需要针对不同智能手机的操作系统来选择不同的A ...