Hive函数以及自定义函数讲解(UDF)
Hive函数介绍
HQL内嵌函数只有195个函数(包括操作符,使用命令show functions查看),基本能够胜任基本的hive开发,但是当有较为复杂的需求的时候,可能需要进行定制的HQL函数开发。HQL支持三种方式来进行功能的扩展(只支持使用java编写实现自定义函数),分别是:UDF(User-Defined Function)、UDAF(User-Defined Aggregate Function)和UDTF(User-Defined Table-Generating Function)。当我们使用java语言进行开发完成后,将生成的jar包移到linux机器(hive机器)上,进行函数的创建,然后进行使用即可。

函数创建命令
HQL函数的创建一般分为以下几步:
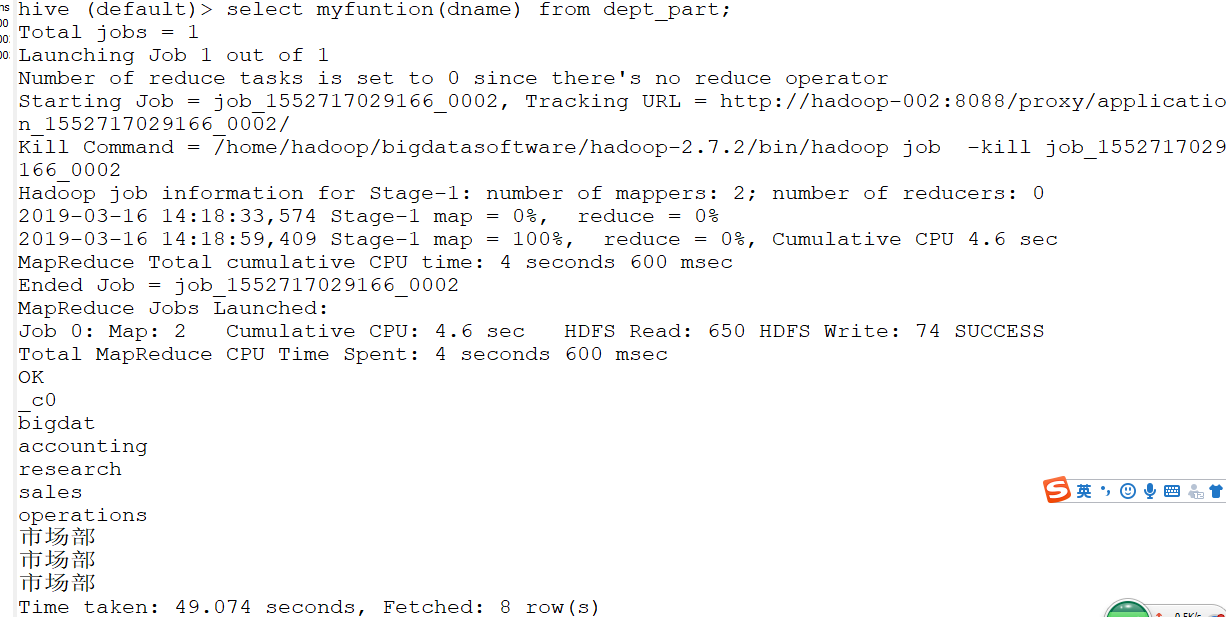
1. 添加jar(0.13.*不支持hdfs上的jar添加,14版本才开始支持)
add jar linux_jar_path
add jar /home/hadoop/bigdatasoftware/datas/hive-1.0-SNAPSHOT.jar

2. 创建function,语法规则如下:
create [temporary] function [dbname.]function_name AS class_name;
create temporary function myfuntion as 'com.gec.demo.LowerUDF';

3. 使用function,和使用其他函数一样。
函数删除命令
我们可以通过drop命令删除自定义函数,语法规则如下:
drop [temporary] function [if exists] [dbname.]function_name;

自定义UDF介绍
UDF(User-Defined Function)支持一个输入产生一个输出,是一个最常用的自定义函数类型。实现自定义UDF要求继承类org.apache.hadoop.hive.ql.exec.UDF,并且在自定义UDF类中重载实现evaluate方法,我们可以通过重载多个evaluate方法达到函数参数多样化的需求。
实现案例:实现一个大小写转换的函数,要求函数通过参数的不同决定是进行那种转换,默认是转换为小写。
UDAF介绍
UDAF(User-Defined Aggregate Function)支持多个输入,一个输出。在原来的版本中可以通过继承UDAF类来实现自定义UDAF,但是现在hive已经将这个类标注为弃用状态。现在一般通过继承AbstractGenericUDAFResolver类来实现自定义UDAF,通过这种方式要求实现自定义的GenericUDAFEvaluator。也就是说在现在的hive版本中,实现自定义UDAF,那么需要实现两个类,分别是AbstractGenericUDAFResolver和GenericUDAFEvaluator。
AbstractGenericUDAFResolver介绍
AbstractGenericUDAFResolver类主要作用就是根据hql调用时候的函数参数来获取具体的GenericUDAFEvaluator实例对象,也就是说实现方法getEvaluator即可,该方法的主要作用就是根据参数的不同返回不同的evaluator实例对象,实现多态性。
maven依赖配置如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>BigdataStudy</artifactId>
<groupId>com.gec.demo</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion> <artifactId>hive</artifactId> <name>hive</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url> <properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.7.2</hadoop.version>
<!--<hive.version> 0.13.1</hive.version>-->
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.2</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency> <dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>0.13.1</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>0.13.1</version>
</dependency> </dependencies>
</project>
自定义的函数如下:
package com.gec.demo; import org.apache.hadoop.hive.ql.exec.UDF;
import org.apache.hadoop.io.Text; public class LowerUDF extends UDF {
public Text evaluate(Text str){
if (null==str.toString()){
return null;
}
return new Text(str.toString().toLowerCase());
} public static void main(String[] args) {
System.out.println(new LowerUDF().evaluate(new Text("HIVE")));
} }
然后打包jar包,

将jar包发送到Linux的/home/hadoop/bigdatasoftware/datas目录下
GenericUDAFEvaluator介绍
GenericUDAFEvaluator类主要作用就是根据job的不同阶段执行不同的方法。hive通过GenericUDAFEvaluator.Model来确定job的执行阶段。PARTIAL1:从原始数据到部分聚合,会调用方法iterate和terminatePartial方法;PARTIAL2:从部分数据聚合和部分数据聚合,会调用方法merge和terminatePartial;FINAL:从部分数据聚合到全部数据聚合,会调用方法merge和terminate;COMPLETE:从原始数据到全部数据聚合,会调用方法iterate和terminate。除了上面提到的iterate、merge、terminate和terminatePartial以外,还有init(初始化并返回返回值的类型)、getNewAggregationBuffer(获取新的buffer对象,也就是方法之间传递参数的对象),reset(重置buffer对象)。
UDTF介绍
UDTF(User-Defined Table-Generating Function)支持一个输入多个输出。一般用于解析工作,比如说解析url,然后获取url中的信息。要求继承类org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现方法:initialize(返回返回值的参数类型)、process具体的处理方法,一般在这个方法中会调用父类的forward方法进行数据的写出、close关闭资源方法,最终会调用close方法,同MR程序中的cleanUp方法。
实现功能:解析爬虫数据,从数据中读取产品id、产品名称、价格。
常用的三种集成自定义函数的方式
首先要求创建的function是永久function,不能是临时function。
第一种:修改hive-site.xml文件,添加参数hive.aux.jars.path,value为jar包的linux本地路径,要求是以file:///开头的绝对路径。
第二种:直接将jar包移动到hive的lib文件夹中。
第三种:将jar包移动到hdfs上,然后在创建function的时候指定function使用的hdfs上的jar文件绝对路径(包括hdfs://hh:8020/前缀),这样在使用的时候,hive会自动将jar下载到本地进行缓存的。
Hive函数以及自定义函数讲解(UDF)的更多相关文章
- MySQL之运算符与函数、自定义函数
一自定义函数简介 (1)自定义函数定义 用户自定义函数(user-defined function,UDF)是一种对MySQL数据库扩展的途径,其用法与内置函数相同. (2)自定义函数的两个必要条件 ...
- PHP函数之自定义函数
像数学中的函数一样,y=f(x)是函数基本的表达形式,x可看做是参数,y可看做是返回值,即函数定义就是一个被命名的.独立的代码段,它执行特定的任务,并可能给调用它的程序返回一个值. 自定义函数 函数的 ...
- PHP学习之[第05讲]PHP5.4 循环结构、系统函数和自定义函数
一.while/for/break/continue: while (expr){ statements } for (expr1:expr2:expr3){ statement } break n ...
- Python之函数(自定义函数,内置函数,装饰器,迭代器,生成器)
Python之函数(自定义函数,内置函数,装饰器,迭代器,生成器) 1.初始函数 2.函数嵌套及作用域 3.装饰器 4.迭代器和生成器 6.内置函数 7.递归函数 8.匿名函数
- PHP基础函数、自定义函数以及数组
2.10 星期五 我们已经真正开始学习PHP 了,今天的主要内容是php基础函数.自定义函数以及数组, 内容有点碎,但是对于初学者来说比较重要,下面是对今天所讲内容的整理: 1 php的基本语法和 ...
- hive的内置函数和自定义函数
一.内置函数 1.一般常用函数 .取整函数 round() 当传入第二个参数则为精度 bround() 银行家舍入法:为5时,前一位为偶则舍,奇则进. .向下取整 floor() .向上取整 ceil ...
- Hive内置函数和自定义函数的使用
一.内置函数的使用 查看当前hive版本支持的所有内置函数 show function; 查看某个函数的使用方法及作用,比如查看upper函数 desc function upper; 查看upper ...
- Hive之函数与自定义函数
系统自带的函数 1)查看系统自带的函数 hive> show functions; 2)显示自带的函数的用法 hive> desc function upper; 3)详细显示自带的函数的 ...
- Hive(九)【自定义函数】
目录 自定义函数 编程步骤 案例 需求 1.创建工程 2.导入依赖 3.创建类 4.打jar包 5.上传hive所在服务器 6.将jar添加到hive的classpath 7.创建临时函数与开发好的j ...
随机推荐
- 5--Selenium环境准备--firefox与geckodriver
selenium2时打开firefox浏览器是不需要安装firefoxdriver的,但是selenium3不支持向前支持火狐浏览器了,40以后版本的火狐,运行会出现问题. 1.下载geckodriv ...
- m3u8编码视频webgl、threejs渲染视频纹理demo
<!DOCTYPE html> <html> <head> <meta charset=utf-8 /> <title>fz-live< ...
- sscanf 与 ssprintf 用法 (转载--https://www.cnblogs.com/Anker/p/3351168.html)
sprintf函数 sprintf函数原型为 int sprintf(char *str, const char *format, ...).作用是格式化字符串,具体功能如下所示: (1)将数字变量转 ...
- 关于 transparent rgba display:none; opacity visiblity 关于em
关于 transparent rgba display:none; opacity visiblity display 之后不会占位. 其余都会占位 opacity 还会继承,子元素也会 ...
- PTA——念数字
PTA 7-30 念数字 #include<stdio.h> #include<stdlib.h> #define N 50 int main() { ] = {"l ...
- JavaScript 缓存基本原理
// 这是个闭包函数,接收一个函数,可以把接收的函数转换成具有缓存能力的函数 var memoize = function(f) { // 使用一个 cache 对象来进行缓存 var cache = ...
- pageContext中page、request、session、application四种范围变量的用法。
在PageContext中有很多作用域 第一种:PageContext.PAGE_SCOPE适用于当前页面的作用域,其接受数据的代码是pageContext.getAttribute();访问页面也是 ...
- Go Example--结构体
package main import "fmt" //定义一个私有结构体 type person struct { name string age int } func main ...
- LeetCode - Number of Recent Calls
Write a class RecentCounter to count recent requests. It has only one method: ping(int t), where t r ...
- CF643D Bearish Fanpages
题意 英文版题面 Problems Submit Status Standings Custom test .input-output-copier { font-size: 1.2rem; floa ...