lucene教程【转】【补】
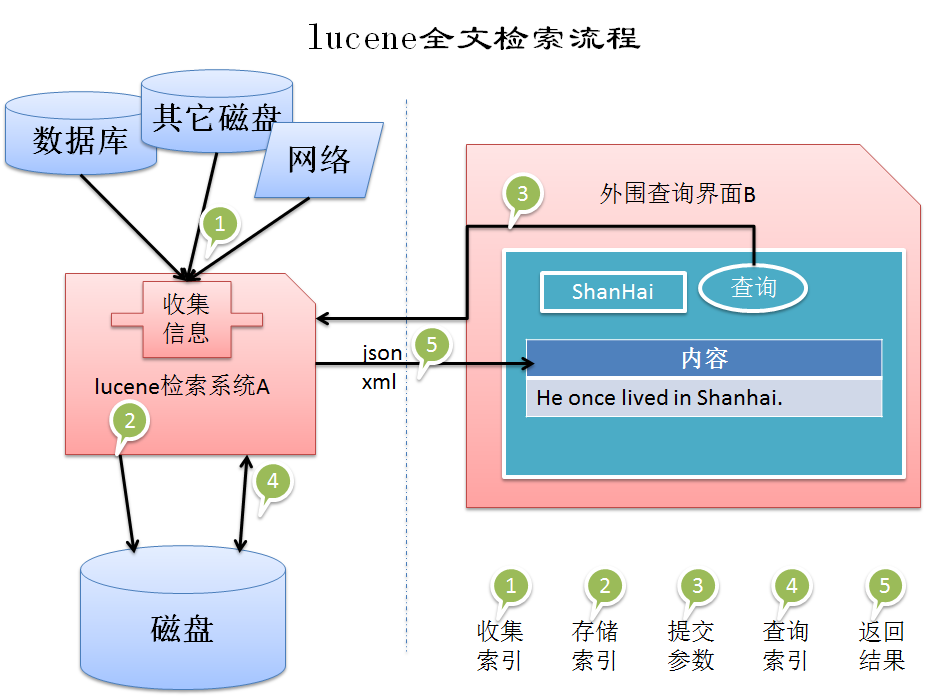
现实流程
lucene 相关jar包
第一个:Lucene-core-4.0.0.jar,
其中包括了常用的文档,索引,搜索,存储等相关核心代码。
第二个:Lucene-analyzers-common-4.0.0.jar,
这里面包含了各种语言的词法分析器,用于对文件内容进行关键字切分,提取。
第三个:Lucene-highlighter-4.0.0.jar,
这个jar包主要用于搜索出的内容高亮显示。
第四个和第五个:
lucene-queries-4.0.0.jar 和 Lucene-queryparser-4.0.0.jar,
提供了搜索相关的代码,用于各种搜索,
比如模糊搜索,范围搜索,等等。
lucene IndexManager.java基本类
package lucene; import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Date;
import java.util.Iterator;
import java.util.List; import java.util.Map; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.LongField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version; public class IndexManager{
private static IndexManager indexManager;
private static String content=""; public static String INDEX_DIR = "D:\\luceneIndex";
public static String DATA_DIR = "D:\\luceneData";
private static Analyzer analyzer = null;
private static Directory directory = null;
private static IndexWriter indexWriter = null; /**
* 创建索引管理器
* @return 返回索引管理器对象
*/
public IndexManager getManager(){
if(indexManager == null){
indexManager = new IndexManager();
}
return indexManager;
}
/**
* 创建当前文件目录的索引
* @param path 当前文件目录
* @return 是否成功
*/
public static boolean createIndex(String path){
Date date1 = new Date();
List<File> fileList = getFileList(path);
analyzer = new StandardAnalyzer(Version.LUCENE_40);
try {
directory = FSDirectory.open(new File(INDEX_DIR));
} catch (IOException e1) {
e1.printStackTrace();
}
for (File file : fileList) {
content = "";
//获取文件后缀
String type = file.getName().substring(file.getName().lastIndexOf(".")+1);
if("txt".equalsIgnoreCase(type)){
content += txt2String(file);
}
System.out.println("name :"+file.getName());
System.out.println("path :"+file.getPath());
System.out.println("content :"+content);
System.out.println(); try{ File indexFile = new File(INDEX_DIR);
if (!indexFile.exists()) {
indexFile.mkdirs();
}
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_40, analyzer);
indexWriter = new IndexWriter(directory, config); Document document = new Document();
document.add(new TextField("filename", file.getName(), Store.YES));
document.add(new TextField("content", content, Store.YES));
document.add(new TextField("path", file.getPath(), Store.YES));
indexWriter.addDocument(document);
indexWriter.commit();
closeWriter(); }catch(Exception e){
e.printStackTrace();
}
content = "";
}
Date date2 = new Date();
System.out.println("创建索引-----耗时:" + (date2.getTime() - date1.getTime()) + "ms\n");
return true;
} /**
* 从数据库中创建索引<br/>
* @param list 代表从数据库中提取的一整张表,其中的Map为<String,Object>格式,一个Map代表一行数据 <br/>
* 单个Map中存放形式 <br/>
* key -- value <br/>
* -------------- <br/>
* ID -- 23 <br/>
* NAME -- bobo <br/>
* AGE -- 29 <br/>
* -------------- <br/>
* 所以多个Map形成的List就成了一整张表 <br/>
* @return
*/
public static boolean createIndexFromDB(List<Map> list) {
if (null == list)
return false;
try {
analyzer = new StandardAnalyzer(Version.LUCENE_40);
directory = FSDirectory.open(new File(INDEX_DIR));
IndexWriterConfig config = new IndexWriterConfig(Version.LUCENE_40, analyzer);
indexWriter = new IndexWriter(directory, config);
for (Map map : list) {
Document document = new Document();
Iterator iterator = map.keySet().iterator();
while (iterator.hasNext()) {
String name = (String) iterator.next();//name为列名
document.add(new TextField(name, (String) map.get(name),Store.YES));
}
indexWriter.addDocument(document);
}
indexWriter.commit();
closeWriter();
} catch (IOException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
return true;
} /**
* 根据field字段(值为 keyword)删除指定的document.
* @param field 指定的某个字段,目前建议只用ID唯一主键进行删除
* @param keywords keywords 中不能有""空串. <br/>
* 而且删的是 keywords中并集,而不是keywords的交集.<br/>
* <br/>
* 因为并集关系,目前该field字段必需是唯一的,不然删除时可能会引出其它多余删除问题<br/>
*/
public static void deleteIndexes(String field, String[] keywords) {
Directory dir;
IndexWriterConfig config;
try {
dir = FSDirectory.open(new File(INDEX_DIR));
analyzer = new StandardAnalyzer(Version.LUCENE_40);
config = new IndexWriterConfig(Version.LUCENE_40, analyzer);
indexWriter = new IndexWriter(dir, config);
QueryParser parser = new QueryParser(Version.LUCENE_40, field, analyzer);
Query query;
for(String keyword : keywords){
query = parser.parse(keyword);
indexWriter.deleteDocuments(query);
}
indexWriter.commit();
indexWriter.close();
} catch (IOException e1) {
e1.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
} } /**
* 读取txt文件的内容
* @param file 想要读取的文件对象
* @return 返回文件内容
*/
public static String txt2String(File file){
String result = "";
try{
BufferedReader br = new BufferedReader(new FileReader(file));//构造一个BufferedReader类来读取文件
String s = null;
while((s = br.readLine())!=null){//使用readLine方法,一次读一行
result = result + "\n" +s;
}
br.close();
}catch(Exception e){
e.printStackTrace();
}
return result;
} /**
* 查找索引,返回符合条件的文件
* @param text 查找的字符串
* @return 符合条件的文件List
*/
public static void searchIndex(String text){
Date date1 = new Date();
try{
directory = FSDirectory.open(new File(INDEX_DIR));
DirectoryReader ireader = DirectoryReader.open(directory);
IndexSearcher isearcher = new IndexSearcher(ireader); analyzer = new StandardAnalyzer(Version.LUCENE_40);
QueryParser parser = new QueryParser(Version.LUCENE_40, "content", analyzer);
parser.setDefaultOperator(QueryParser.AND_OPERATOR);//查询条件用and
Query query = parser.parse(text); ScoreDoc[] hits = isearcher.search(query, null, 1000).scoreDocs; for (int i = 0; i < hits.length; i++) {
Document hitDoc = isearcher.doc(hits[i].doc);
System.out.println("↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓结果↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓结果↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓");
// System.out.println(hitDoc.get("filename"));
System.out.println(hitDoc.get("content"));
// System.out.println(hitDoc.get("path"));
System.out.println("↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑结果↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑结果↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑\n");
}
ireader.close();
directory.close();
}catch(Exception e){
e.printStackTrace();
}
Date date2 = new Date();
System.out.println("查看索引-----耗时:" + (date2.getTime() - date1.getTime()) + "ms\n");
} /**
* 过滤目录下的文件
* @param dirPath 想要获取文件的目录
* @return 返回文件list
*/
public static List<File> getFileList(String dirPath) {
File[] files = new File(dirPath).listFiles();
List<File> fileList = new ArrayList<File>();
for (File file : files) {
if (isTxtFile(file.getName())) {
fileList.add(file);
}
}
return fileList;
}
/**
* 判断是否为目标文件,目前支持txt xls doc格式
* @param fileName 文件名称
* @return 如果是文件类型满足过滤条件,返回true;否则返回false
*/
public static boolean isTxtFile(String fileName) {
if (fileName.lastIndexOf(".txt") > 0) {
return true;
}
return false;
} public static void closeWriter() throws Exception {
if (indexWriter != null) {
indexWriter.close();
}
} /**
* 删除文件目录下的所有文件<br/>
* 测试的时候每次都delete一下被创建的索引目录,不然相同索引会一直往里添加
* @param file 要删除的文件目录
* @return 如果成功,返回true.
*/
public static boolean deleteDir(File file){
if(file.isDirectory()){
File[] files = file.listFiles();
for(int i=0; i<files.length; i++){
deleteDir(files[i]);
}
}
file.delete();
return true;
} }
扩展:多个字段组合查询
import java.io.File;
import java.io.IOException;
import org.apache.lucene.document.Document;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.BooleanClause.Occur;
import org.apache.lucene.search.BooleanQuery;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.search.WildcardQuery;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; /**
* lucene利用BooleanQuery进行多个Query组合查询
*
*/
public class LuceneWildCardSearcher { public static void main(String[] args) { String dir = "D:\\index";
try { Directory directory = FSDirectory.getDirectory(new File(dir));
@SuppressWarnings("deprecation")
IndexReader reader = IndexReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
Term term1 = new Term("filename", "<<傲慢与偏见>>");
WildcardQuery wildcardQuery = new WildcardQuery(term1);
Term term2 = new Term("content", "傲慢让别人无法来爱我,偏见让我无法去爱别人");
TermQuery termQuery = new TermQuery(term2);
//创建booleanQuery,然后把其它query串起来
BooleanQuery booleanQuery = new BooleanQuery();
booleanQuery.add(wildcardQuery, Occur.MUST);
booleanQuery.add(termQuery, Occur.MUST);
TopDocs topDocs = indexSearcher.search(booleanQuery,null, 10);
ScoreDoc scoreDocs[] = topDocs.scoreDocs;
for (int i = 0; i < scoreDocs.length; i++) {
Document document = indexSearcher.doc(scoreDocs[i].doc);
System.out.println(document.get("id"));
System.out.println(document.get("name"));
System.out.println(document.get("text"));
System.out.println(document.get("datetime"));
}
directory.close();
} catch (IOException e) { e.printStackTrace();
}
}
}
用文件创建索引main入口
package entrance; import java.io.File; import lucene.IndexManager;
/**
* 用文件创建索引main入口
* @author King
*
*/
public class FileEntrance {
public static void main(String[] args){
IndexManager.deleteDir(new File(IndexManager.INDEX_DIR));
IndexManager.createIndex(IndexManager.DATA_DIR);
IndexManager.searchIndex("杭州");
}
}
从数据库创建索引入口
package entrance; import java.io.File;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map; import lucene.IndexManager; /**
* 从数据库创建索引入口
* @author King
*
*/
public class DbEntrance { @SuppressWarnings("unchecked")
public static void main(String[] args){
List<Map> list = new ArrayList<Map>();
Map map = new HashMap();
map.put("ID", "23");
map.put("NAME", "bobo");
map.put("AGE", "29");
map.put("content", "23 bobo 29");
list.add(map); IndexManager.deleteDir(new File(IndexManager.INDEX_DIR));
IndexManager.createIndexFromDB(list);
IndexManager.searchIndex("23");
}
}
删除索引main入口
package entrance; import java.io.File; import lucene.IndexManager;
/**
* 删除索引main入口
* @author King
*
*/
public class delIndexEntrance {
public static void main(String[] args){
String[] delArray={"杭州","Hi"};//删的是并集,而非交集,特别注意
//先清空索引
IndexManager.deleteDir(new File(IndexManager.INDEX_DIR));
//再创建索引
IndexManager.createIndex(IndexManager.DATA_DIR);
//再删除和杭州相关的某个索引
IndexManager.deleteIndexes("content", delArray);
//最后搜索"杭州",看结果是否查到
IndexManager.searchIndex("杭州");
//找不到结果了,证明确实删除了
}
}
AnalyzerTool分词辅助工具.
可以查看某串字符最终被分割成什么样子,这样便于查询时明白为什么有的查不到有的却能查到.
不同的Analyzer就是组合不同的Tokenizer和TokenFilter得到最后的TokenStream
package com.analyzer.www.tool;
import java.io.IOException;
import java.io.StringReader; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.TokenStream;
import org.apache.lucene.analysis.core.SimpleAnalyzer;
import org.apache.lucene.analysis.core.StopAnalyzer;
import org.apache.lucene.analysis.core.WhitespaceAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.analysis.tokenattributes.CharTermAttribute;
import org.apache.lucene.util.Version; /**
*展示分词后的效果
*/
public class AnalyzerTool { /**
* 打印分词后的信息
* @param str 待分词的字符串
* @param analyzer 分词器
*/
public static void displayToken(String str,Analyzer analyzer){
try {
//将一个字符串创建成Token流
TokenStream stream = analyzer.tokenStream("content", new StringReader(str));
CharTermAttribute cta = stream.addAttribute(CharTermAttribute.class);
stream.reset();//一定要重置,不然老报错
while(stream.incrementToken()){
System.out.print("【" + cta + "】");
}
System.out.println();
} catch (IOException e) {
e.printStackTrace();
}
} public static void main(String[] args) {
Analyzer aly1 = new StandardAnalyzer(Version.LUCENE_40);
Analyzer aly2 = new StopAnalyzer(Version.LUCENE_40);
Analyzer aly3 = new SimpleAnalyzer(Version.LUCENE_40);
Analyzer aly4 = new WhitespaceAnalyzer(Version.LUCENE_40); String str = "Hello ,I am King,我是 中国人,my email is jianyuan_5731@qq.com"; AnalyzerTool.displayToken(str, aly1);
AnalyzerTool.displayToken(str, aly2);
AnalyzerTool.displayToken(str, aly3);
AnalyzerTool.displayToken(str, aly4);
}
}
QueryParser 中的 setDefaultOperator(xxx)
QueryParser.OR_OPERATOR和QueryParser.AND_OPERATOR用于设置关键词中空格的关系,即存在空格时,空格之间的词是and还是or关系.
StandardAnalyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
QueryParser parser = new QueryParser("content",analyzer);
parser.setDefaultOperator(QueryParser.OR_OPERATOR);// 设置检索的条件.OR_OPERATOR表示"或"
parser.setDefaultOperator(QueryParser.AND_OPERATOR);// 设置检索的条件.OR_OPERATOR表示"与"
于是当你的content字符串"he is once lived in HangZhou" 在置入content字段分完词建好索引以后.
当使用QueryParser.AND_OPERATOR时
- 如果你的content参数传来了 he once那么是能查到结果的(by he&once).
- 如果你的content参数传来了 she once那么是不能查到结果的.
当使用QueryParser.OR_OPERATOR时
- 如果你的content参数传来了 he once那么是能查到结果的(by he || by once)
- 如果你的content参数传来了 she once那么是能到结果的(by once).
参考:
【手把手教你全文检索】Apache Lucene初探 要特别注意的是: FSDirectory.open(new File(INDEX_DIR)); 这条语句使用得越少越好,不停的打开非常极超级耗时. 所以 该网页中的open()位置是有点问题的,要改成本页面中的IndexManager.java类才优雅.
http://www.yiibai.com/lucene/lucene_analysis.html
$$$$$$$$Lucene 中的Tokenizer, TokenFilter学习 (让我了解到Filter链)
$$$$$[Lucene] 使用Lucene创建自定义的词干分析器
我的笔记
lucene field 入门【转】--https://www.cnblogs.com/whatlonelytear/p/9151233.html
补充说明
根据官方说明,从lucene 4.8.0开始,需要jdk7之上才行
集群2018-06-08
lucene分布式架构-满足高并发的实时检索需求--https://blog.csdn.net/a276202460/article/details/62426189
下载
百度云盘lucene pdf相关文档--https://pan.baidu.com/s/1jGxGi6E
百度云盘分享 (附源码,jar包,ppt)
git: https://git.oschina.net/KingBoBo/lucene.git
lucene教程【转】【补】的更多相关文章
- Lucene教程(转)
Lucene教程 1 lucene简介1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来 ...
- Lucene教程--转载
Lucene教程 1 lucene简介1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来 ...
- Lucene教程具体解释
(建立索引)] )中生成的索引文件的存放地址.详细步骤简单介绍例如以下: 1.创建Directory对象,索引目录 2.创建IndexSearch对象,建立查询(參数是Directory对象) 3.创 ...
- Lucene教程
一:简单的示例 1.1:生成索引 1.1.1:Field.Store和Field.Index 1.1.2:为数字生成索引 1.1.3:为索引加权 1.1.4:为日期生成索引 1.2:查询 1.2.1: ...
- lucene教程简介
1 lucene简介 1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是 ...
- lucene教程--全文检索技术
1 Lucene 示例代码 https://blog.csdn.net/qzqanzc/article/details/80916430 2 Lucene 实例教程(一)初识L ...
- Lucene教程 -------(一、初始Lucene)
一.lucene的介绍 lucene是一个全文检索的框架,apache组织提供了一个用java实现的全文检索的开源项目.功能非常的强大,api非常简单,并且有了全文检索的功能支持可以非常方便的实现根据 ...
- Lucene教程(四) 索引的更新和删除
这篇文章是基于上一篇文章来写的,使用的是IndexUtil类,下面的例子不在贴出整个类的内容,只贴出具体的方法内容. 3.5版本: 先写了一个check()方法来查看索引文件的变化: /** ...
- Lucene入门教程
Lucene教程 1 lucene简介 1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么 ...
随机推荐
- Spring IOP 面向切面编程
Spring IOP 面向切面编程 AOP操作术语 Joinpoint(连接点):所谓连接点是指那些被拦截到的点.在spring中,这些点指的是方法,因为spring只支持方法类型的连接点.(类里面 ...
- PAT 1036 跟奥巴马一起编程
https://pintia.cn/problem-sets/994805260223102976/problems/994805285812551680 美国总统奥巴马不仅呼吁所有人都学习编程,甚至 ...
- [wiki]陶德曼调停
陶德曼调停[编辑] 维基百科,自由的百科全书 凯申物流差点和谈 目录 1背景 2调停经过 3评价 4参见 背景[编辑] 主条目:中德合作 (1911年-1941年) 1936年11月25日,德国与日本 ...
- BFC——块级格式化上下文
BFC(块级格式化上下文) 一.BFC是什么? 从样式上看,具有BFC的容器和普通的容器没有区别.从功能上看,具有BFC的容器可以看作是隔离了的容器,容器里面的元素不会影响到外面的元素,并且BFC具有 ...
- 软件工程_8th weeks
第八周PSP 个人时间管理 由于本周主要在做论文实验,除了学习时间外有一些零散的时间也在思考代码的书写以及论文实验的流程,但是这些零散的时间并没有在总的表记录,所以想问一下老师,像这种平时零散思考的时 ...
- RSS & Server-Sent Events & HTML5 Notification API
RSS Rich Site Summary https://en.wikipedia.org/wiki/RSS https://www.lifewire.com/what-is-rss-2483592 ...
- 洛谷 P3237 [HNOI2014]米特运输
题面链接 get到新技能当然要来记录一下辣 题意:给一棵树,每个点有一个权值,要求同一个父亲的儿子的权值全部相同,父亲的取值必须是所有儿子的权值和,求最少的修改数量 sol:自己瞎鸡巴yy一下可以发现 ...
- Linux 系统免密码登陆远程服务器
在当前Linux生成公钥私钥ssh-keygen公钥私钥存放路径为:~/root/.ssh/id_rsa id_rsa.pub 登陆被远程主机,进入目录~/root/.ssh/是否存在authoriz ...
- 洛谷P1776 宝物筛选_NOI导刊2010提高(02)(多重背包,单调队列)
为了学习单调队列优化DP奔向了此题... 基础的多重背包就不展开了.设\(f_{i,j}\)为选前\(i\)个物品,重量不超过\(j\)的最大价值,\(w\)为重量,\(v\)为价值(蒟蒻有强迫症,特 ...
- 05 Zabbix triggers--action--event
点击返回:自学Zabbix之路 点击返回:自学Zabbix4.0之路 点击返回:自学zabbix集锦 05 Zabbix triggers--action--event 动作action: 在配置好监 ...