机器学习课程-第8周-聚类(Clustering)—K-Mean算法
1. 聚类(Clustering)
1.1 无监督学习: 简介
在一个典型的监督学习中,我们有一个有标签的训练集,我们的目标是找到能够区分正样本和负样本的决策边界,在这里的监督学习中,我们有一系列标签,我们需要据此拟合一个假设函数。与此不同的是,在非监督学习中,我们的数据没有附带任何标签,我们拿到的数据就是这样的:
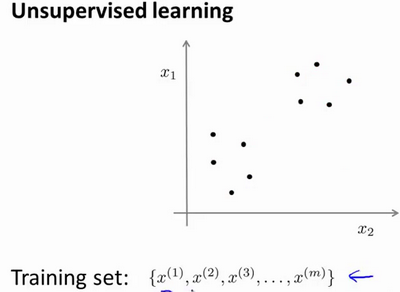
在非监督学习中,我们需要将一系列无标签的训练数据,输入到一个算法中,然后我们告诉这个算法,快去为我们找找这个数据的内在结构给定数据。我们可能需要某种算法帮助我们寻找一种结构。图上的数据看起来可以分成 两个分开的点集(称为簇),一个能够找到我圈出的这些点集的算法,就被称为聚类算法。
这将是我们介绍的第一个非监督学习算法。当然,此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者其他的一些模式,而不只是簇。
1.11 聚类算法用途

1.2 K-均值算法
K-均值 是最普及的聚类算法,算法接受一个未标记的数据集,然后将数据聚类成不同的组。
K-均值 是一个迭代算法,假设我们想要将数据 聚类成n个组,其方法为:
首先选择 K 个随机的点,称为聚类中心(cluster centroids);
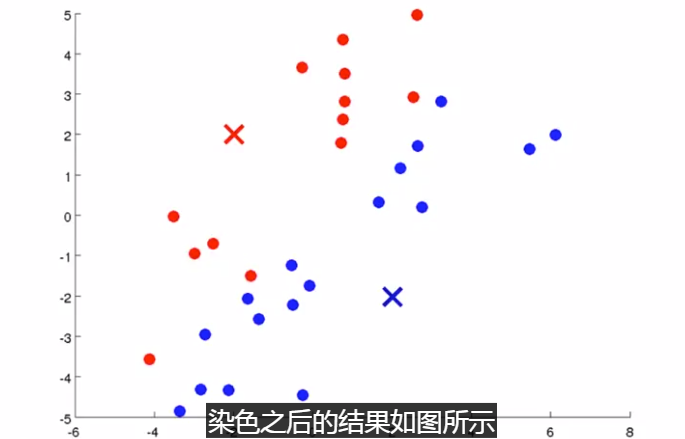
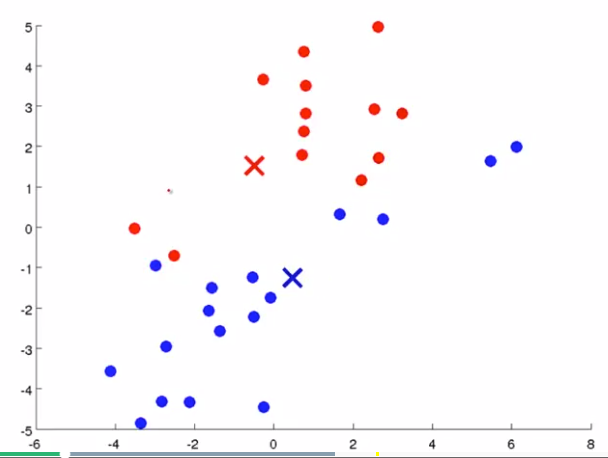
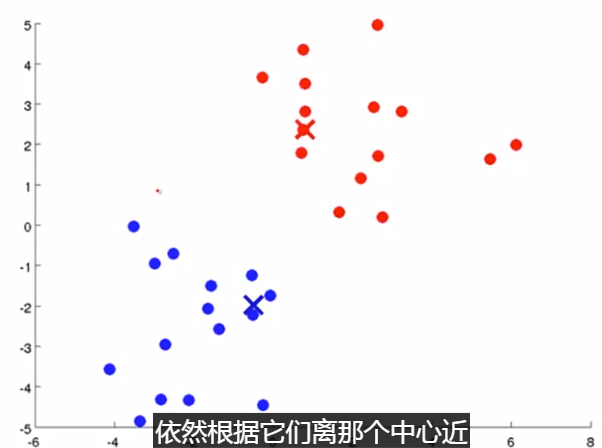
簇分配:对于数据集中的每一个数据,按照 距离 K个中心点的距离,将其 与距离最近的中心点 关联起来,与 同一个中心点 关联的所有点聚成一类。
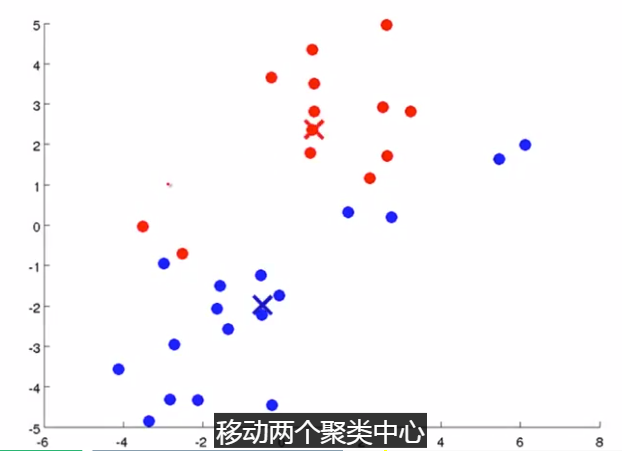
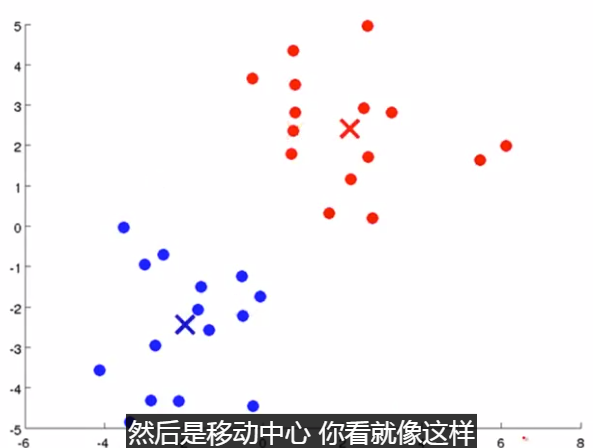
移动聚类中心:计算每一个组的平均值,将该组 所关联的中心点 移动到 该组平均值的位置。
重复步骤2-4直至中心点不再变化。
下面是一个聚类示例:
(簇分配) (移动聚类中心)

重复该步骤。

Repeat {
for i = to m # 簇分配
c(i) := index (form to K) of cluster centroid closest to x(i) # 是接近 哪一个聚类中心 k; c(i) = min_k:||x^(i) - u_k||^2
for k = to K # 移动聚类中心
μk := average (mean) of points assigned to cluster k
}

注意:
没有分配点的聚类中心直接删除;
K-均值算法也可以很便利地用于将数据分为许多不同组,即使在 没有非常明显区分的组群 的情况下也可以。
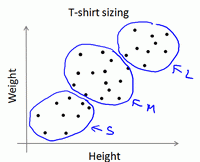
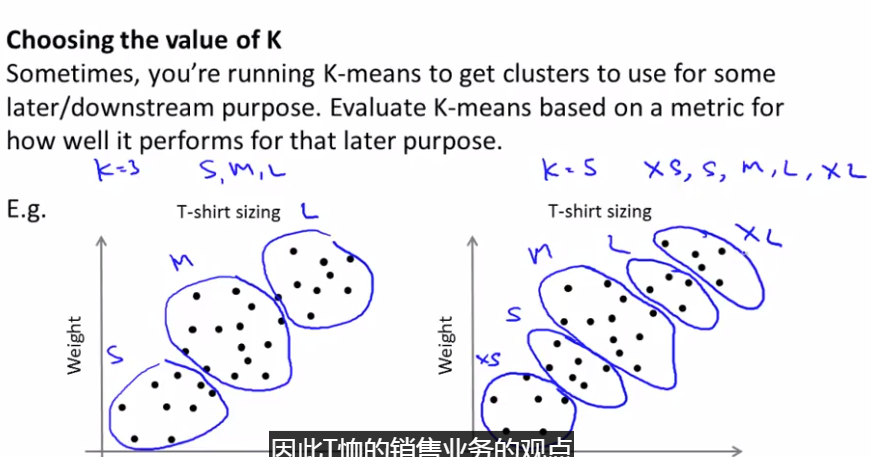
下图所示的数据集包含 身高和体重 两项特征构成的,利用K-均值算法将数据分为三类,用于帮助确定将要生产的T-恤衫的三种尺寸。
1.3 优化目标
K-均值最小化问题:最小化 所有的数据点 与 其所关联的聚类中心点 之间的 距离之和,因此 K-均值的代价函数(又称畸变函数 Distortion function)为:
$$J(c^{(1)},...,c^{(m)},μ_1,...,μ_K)=\dfrac {1}{m}\sum^{m}_{i=1}\left\| X^{\left( i\right) }-\mu_{c^{(i)}}\right\| ^{2}$$
其中 ${{\mu }_{{{c}^{(i)}}}}$ 代表与 ${{x}^{(i)}}$ 最近的聚类中心点。
优化目标:
- 找出使得代价函数最小的 $c^{(1)}$,$c^{(2)}$,...,$c^{(m)}$ 和 $μ^1$,$μ^2$,...,$μ^k$:
 (代价函数会一直变小,不可能上升)
(代价函数会一直变小,不可能上升)


1.4 随机初始化
在运行K-均值算法的之前,我们首先要 随机初始化 所有的聚类中心点,下面介绍怎样做:
- 我们应该选择 $K<m$,即 聚类中心点的个数 要小于 所有训练集实例的数量
- 随机选择 $K$ 个训练实例,然后令 $K$ 个聚类中心分别与这 $K$ 个训练实例相等
K-均值 的一个问题在于,它有可能会停留在一个局部最小值处,而这取决于初始化的情况。

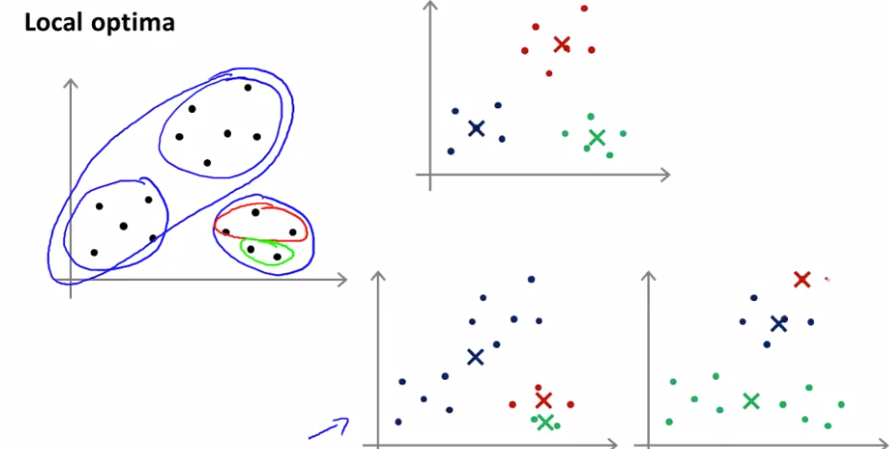
尝试多次随机初始化

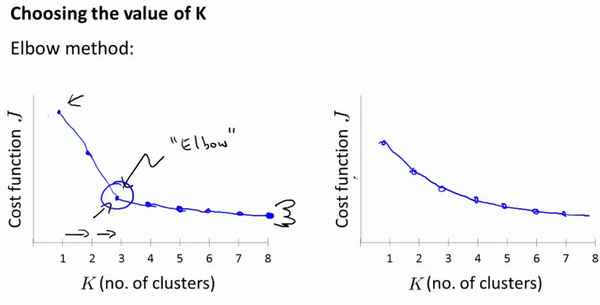
1.5 选择聚类数
没有所谓最好的 选择聚类数目 的方法,通常是需要根据不同的问题,人工进行选择的。选择的时候思考我们运用K-均值算法聚类的动机是什么,然后选择能 最好 服务于该目的 的聚类数。
当人们在讨论,选择聚类数目 的方法时, “肘部法则”:
改变 K 值,也就是 聚类类别数目的总数。我们用一个聚类来运行 K均值聚类方法。
这就意味着,所有的数据都会分到一个聚类里,然后计算成本函数或者计算畸变函数 J 。K 代表聚类数字。
机器学习课程-第8周-聚类(Clustering)—K-Mean算法的更多相关文章
- 机器学习(九)-------- 聚类(Clustering) K-均值算法 K-Means
无监督学习 没有标签 聚类(Clustering) 图上的数据看起来可以分成两个分开的点集(称为簇),这就是为聚类算法. 此后我们还将提到其他类型的非监督学习算法,它们可以为我们找到其他类型的结构或者 ...
- 机器学习课程-第8周-降维(Dimensionality Reduction)—主成分分析(PCA)
1. 动机一:数据压缩 第二种类型的 无监督学习问题,称为 降维.有几个不同的的原因使你可能想要做降维.一是数据压缩,数据压缩不仅允许我们压缩数据,因而使用较少的计算机内存或磁盘空间,但它也让我们加快 ...
- 机器学习课程-第7周-支持向量机(Support Vector Machines)
1. 优化目标 在监督学习中,许多学习算法的性能都非常类似,因此,重要的不是你该选择使用学习算法A还是学习算法B,而更重要的是,应用这些算法时,所创建的大量数据在应用这些算法时,表现情况通常依赖于你的 ...
- Andrew Ng机器学习课程,第一周作业,python版本
Liner Regression 1.梯度下降算法 Cost Function 对其求导: theta更新函数: 代码如下: from numpy import * import numpy as n ...
- Andrew Ng机器学习课程笔记--汇总
笔记总结,各章节主要内容已总结在标题之中 Andrew Ng机器学习课程笔记–week1(机器学习简介&线性回归模型) Andrew Ng机器学习课程笔记--week2(多元线性回归& ...
- SIGAI机器学习第二十四集 聚类算法1
讲授聚类算法的基本概念,算法的分类,层次聚类,K均值算法,EM算法,DBSCAN算法,OPTICS算法,mean shift算法,谱聚类算法,实际应用. 大纲: 聚类问题简介聚类算法的分类层次聚类算法 ...
- 机器学习之&&Andrew Ng课程复习--- 聚类——Clustering
第十三章.聚类--Clustering ******************************************************************************** ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 13—Clustering 聚类
Lecture 13 聚类 Clustering 13.1 无监督学习简介 Unsupervised Learning Introduction 现在开始学习第一个无监督学习算法:聚类.我们的数据没 ...
- Stanford机器学习笔记-9. 聚类(Clustering)
9. Clustering Content 9. Clustering 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means al ...
随机推荐
- “using NoSQL” under MySQL
https://dev.mysql.com/doc/refman/5.7/en/document-store.html https://dev.mysql.com/doc/refman/5.7/en/ ...
- Tomcat启动错误一例org.apache.catalina.core.StandardContext resources Start Error starting static Resources
org.apache.catalina.core.StandardContext resources Start Error starting static Resources 引发原因:Eclips ...
- centos7 搭建svn服务器
1.安装svn服务器: yum install subversion 2.配置svn服务器: 建立svn版本库根目录及相关目录即svndata及密码权限命令svnpasswd: mkdir -p /a ...
- spark中saveAsTextFile的错误
写了很简单的一段spark代码,将结果保存为windows本地文件,执行之后总是报错NullPointerException 查询之后 发现是本地缺少hadoop需要的一个文件所致 如果本地已经安装了 ...
- async中await是干啥的,用不用有什么区别?
最近在研究异步编程,用的async await task啥的,但是都这几个概念很模糊,还有不太清楚await是干啥的,task又是干啥的,用不用await有什么区别,他们三个之间的联系是什么? tas ...
- fix
rounds the elements of A toward zero, resulting in an array of integers. For complex A, the imaginar ...
- linux 运维常用的一些命令收集
1.删除0字节文件find -type f -size 0 -exec rm -rf {} ; 2.查看进程按内存从大到小排列ps -e -o “%C : %p : %z : %a”|sort ...
- jQuery之制作简单的轮播图效果
[源代码] 链接:https://pan.baidu.com/s/1XpZ66D9fmSwWX3pCnGBqjA 密码:w104 [整体构思] 这个轮播图使用的是jQuery,所以Js的整体代量比较少 ...
- MT【55】近零点
[Among the natural enemy of mathematics, the most important thing is that how do we konw somethi ...
- Heaven of Imaginary(PKUSC2018)
Day-4 巨佬一个星期前就停了课,而蒟蒻还在教室里,收拾一地学科的烂摊子. 蒟蒻为什么要停课呢?真的有\(1\%\)的可能,成功报名PKUSC吗? 真的有. 蒟蒻滚回了机房. 三天,能做些什么呢?可 ...