day3 zookeeper
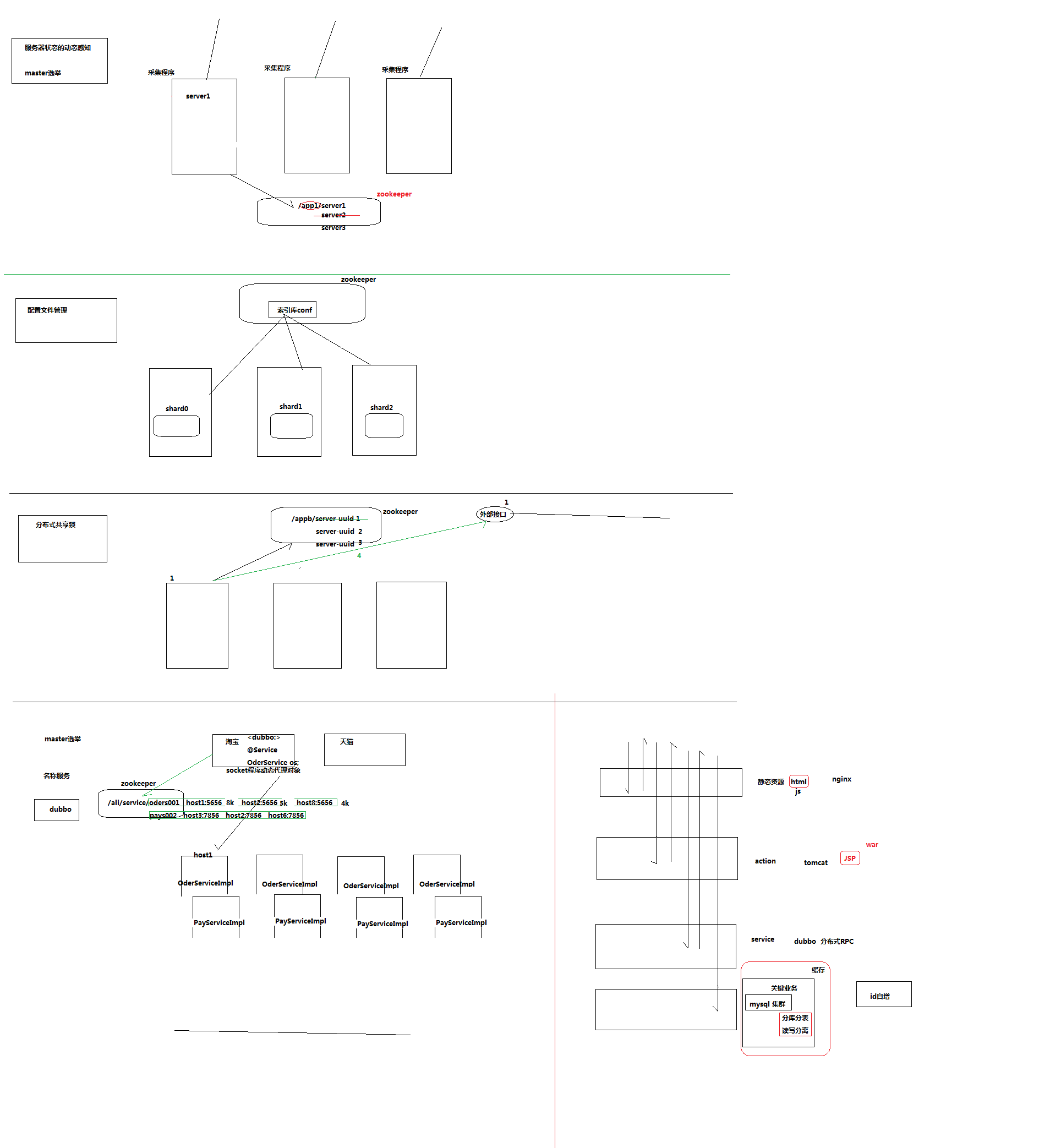
PS:在生产的场景中,一般有两个需求:
1.提供设备的注册
2.对所注册的接口进行监听。
zookeeper就是提供这样的功能,它本身就是一个集群,如果存在半数以上的节点活着就能提供服务,本身就具备很高的高可用。一个为奇数个 PS :很多场景虽然用不用不到大数据,但是只要用到分布式协调都能用到 zookeeper; 比如dubbo

PS:因为zookeeper是java程序,所有首先必须安装jdk----------------------------------、!!!!

PS:zookeeper主要管理,不仅仅是大数据开发,非大数据的开发也能用到。主要是负责中间节点的数据
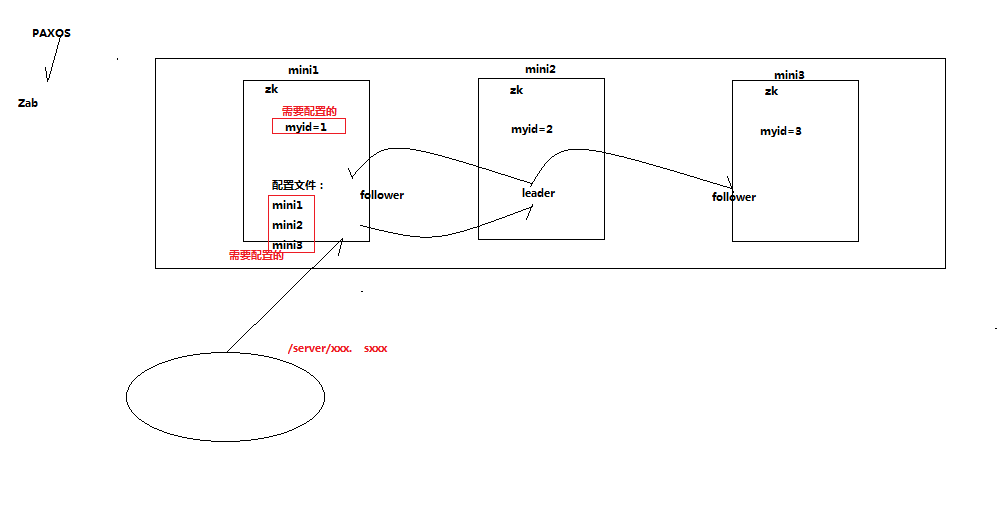
PS : 下图是zookeeper的集群结构:zookeeper使用的是PAXOS算法或Zab算法
zookeeper内部是有选举制度的,来选举出谁是leader,当leader确定后,后面的都是follower; 所需配置的myid就是投票的机制的东西,配置所有参加选举的机器
最后,在选举出leader以后就可以数据就可以共享了。
PS:对于大数据的学习会学到很多的框架,我们不必太深究每一个框架,知道大概使用配置即可。但是某些常用的还是要学会,还要深入源码。
上图为zookeeper集群结构,对于多台机器中间会选举一个leader,这是zookeeper内部的算法。如果集群的数量非常多的话,zookeeper并不是很快,所以只是在要求不太高的地方。
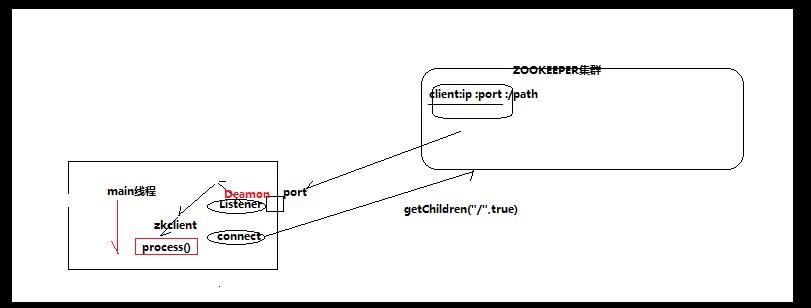
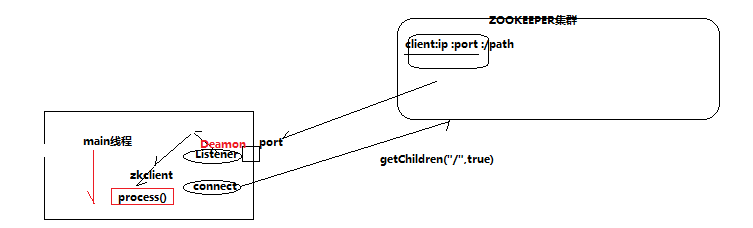
PS:其实我感觉zookeeper就像他的名字一样,他在服务器集群中,充当中间商的 管理,更好的服务,客户端这边通过zookeeper的管理,通过api获取相关的数据,进行相应。
上图,是zookeeper客户端内守护线程的监听机制。
---------------------------------------------------ZooKeeper的安装配置
1、 集群部署的基本流程
集群部署的流程:下载安装包、解压安装包、修改配置文件、分发安装包、启动集群
注意:
1.现在讲解修改配置文件,复制配置文件,修改配置文件
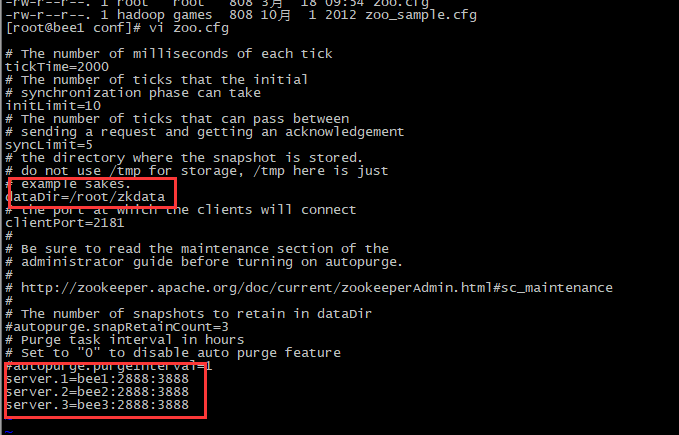
PS :把zookeeper发送给其他的机器
2.为每一台机器添加server的myid,这样才能标识机器
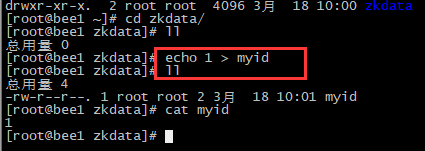


3.为所有的机器启动zookeeper

4.查看zookeeper的状态
1.1.1. 查看集群状态
0.启动zookeeper bin/zkServer.sh start
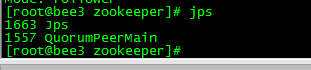
1、 jps(查看进程)
2、 zkServer.sh status(查看集群状态,主从信息)

PS : 如果一台一台启动,通常中间那台是leader;
*************************************************
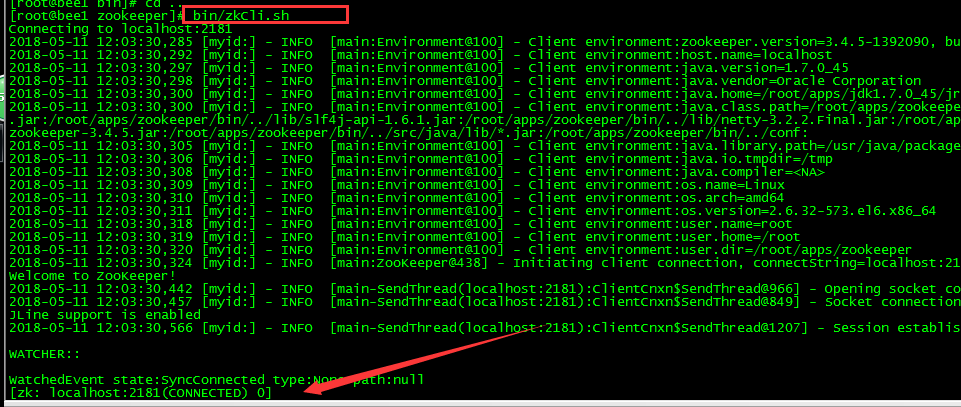
-PS : 通过bin/zkCli.sh来启动zookeeper的客户端
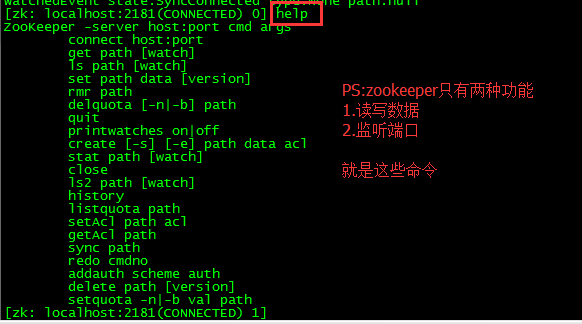


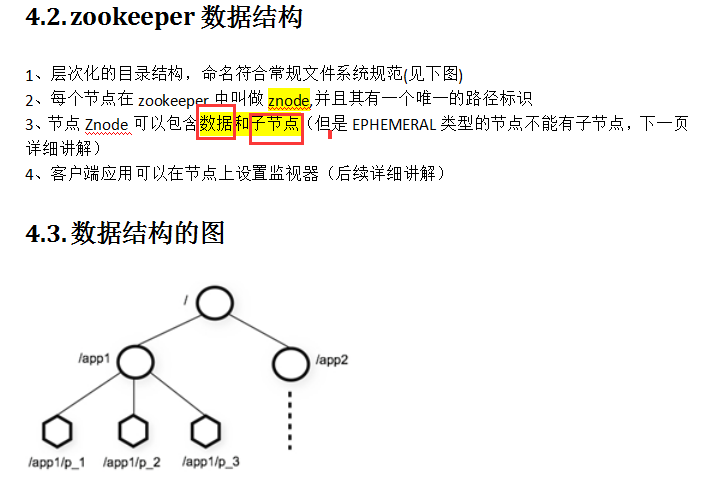

PS : 带上这个-e 就是临时的,退出客户端数据就会消失;
-s 就是 创建的文件夹会带上序列号



1、使用 ls 命令来查看当前 ZooKeeper 中所包含的内容:
[zk: 202.115.36.251:2181(CONNECTED) 1] ls /
2、创建一个新的 znode ,使用 create /zk myData 。这个命令创建了一个新的 znode 节点“ zk ”以及与它关联的字符串:
[zk: 202.115.36.251:2181(CONNECTED) 2] create /zk "myData“
3、我们运行 get 命令来确认 znode 是否包含我们所创建的字符串:
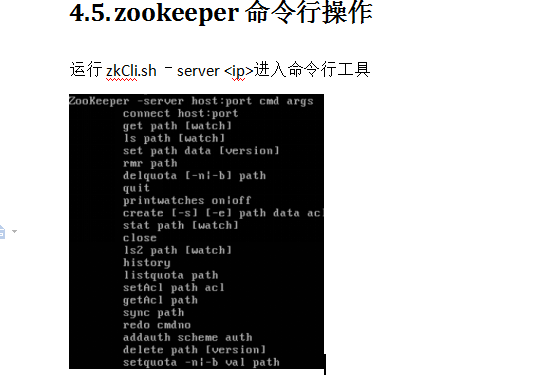
[zk: 202.115.36.251:2181(CONNECTED) 3] get /zk
#监听这个节点的变化,当另外一个客户端改变/zk时,它会打出下面的
#WATCHER::
#WatchedEvent state:SyncConnected type:NodeDataChanged path:/zk
[zk: localhost:2181(CONNECTED) 4] get /zk watch 这种监听是一次性的,第二次的就不会管用了
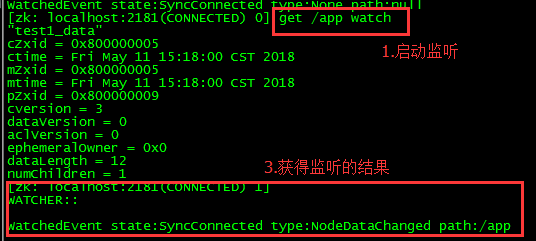
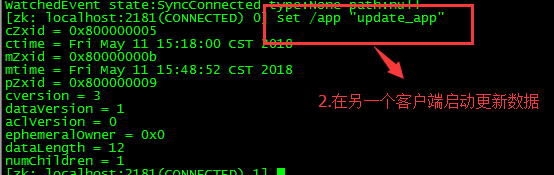
PS:监控子类的节点,

PS:等待查看数据的更新
4、下面我们通过 set 命令来对 zk 所关联的字符串进行设置:
[zk: 202.115.36.251:2181(CONNECTED) 4] set /zk "zsl“ 更新
5、下面我们将刚才创建的 znode 删除:
[zk: 202.115.36.251:2181(CONNECTED) 5] delete /zk
6、删除节点:rmr
[zk: 202.115.36.251:2181(CONNECTED) 5] rmr /zk
PS: .zookeeper原理解析-选举之QuorumPeerMain加载 ,QuorumPeerMain是 zookeeper启动的进程
PS :关闭进程 kill -9 1557(进程号)
--------------------------------自动化启动Zookeeper脚本
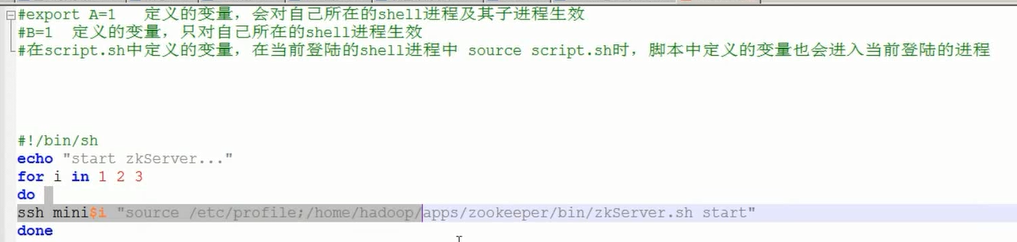
1.创建目录,把sh放入文件夹

2.把root/bin设置为环境变量

3.给文件夹执行的权限,启动

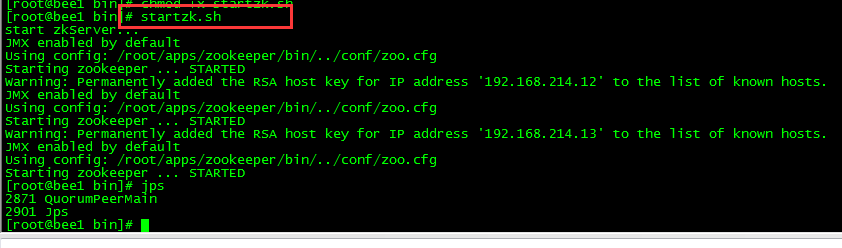
4.测试

-----------------------------------------------------------------------------------
package cn.itcast.bigdata.zk; import java.io.IOException;
import java.util.List; import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import org.junit.Before;
import org.junit.Test; public class SimpleZkClient { private static final String connectString = "bee1:2181,bee2:2181,bee3:2181";
private static final int sessionTimeout = 2000; ZooKeeper zkClient = null; @Before
public void init() throws Exception {
zkClient = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 收到事件通知后的回调函数(应该是我们自己的事件处理逻辑)
System.out.println(event.getType() + "---" + event.getPath());
try {
zkClient.getChildren("/", true);//这里是为了解决 一次性相应的问题。 如果在linux发生节点变化,就会重新执行zkClient.get就解决了
} catch (Exception e) {
}
}
}); } /**
* 数据的增删改查
*
* @throws InterruptedException
* @throws KeeperException
*/ // 创建数据节点到zk中
@Test
public void testCreate() throws KeeperException, InterruptedException {
// 参数1:要创建的节点的路径 参数2:节点大数据 参数3:节点的权限 参数4:节点的类型
String nodeCreated = zkClient.create("/eclipse", "hellozk".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
//输出 :None---null 初始化事件

//在系统端测试
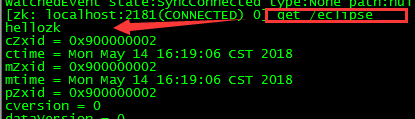
//上传的数据可以是任何类型,但都要转成byte[]
} //判断znode是否存在
@Test
public void testExist() throws Exception{
Stat stat = zkClient.exists("/eclipse", false);
System.out.println(stat==null?"not exist":"exist");
} // 获取子节点
@Test
public void getChildren() throws Exception {
List<String> children = zkClient.getChildren("/", true);// “/”跟下面的是子节点
for (String child : children) {
System.out.println(child);
}
Thread.sleep(Long.MAX_VALUE);//为了监测服务器程序的执行
} //获取znode的数据
@Test
public void getData() throws Exception { byte[] data = zkClient.getData("/eclipse", false, null);
System.out.println(new String(data));
输出:
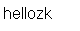
}
//删除znode
@Test
public void deleteZnode() throws Exception {
//参数2:指定要删除的版本,-1表示删除所有版本
zkClient.delete("/eclipse", -1);
}
//修改znode
@Test
public void setData() throws Exception {
zkClient.setData("/app1", "imissyou angelababy".getBytes(), -1);
byte[] data = zkClient.getData("/app1", false, null);
System.out.println(new String(data));
}
}
PS: 正常情况下,只能监测一次znode的变化,但是在watch中写程序后就可以持续的监控了
------------------------------服务器动态上下线程序的工作机制
PS:就是能够动态查看服务器:当服务器启动的时候会在zookeeper中注册server,当有服务器下线的时候相当于nodechanged,重新获取服务器列表
PS: 这点有点小问题,回去需研究
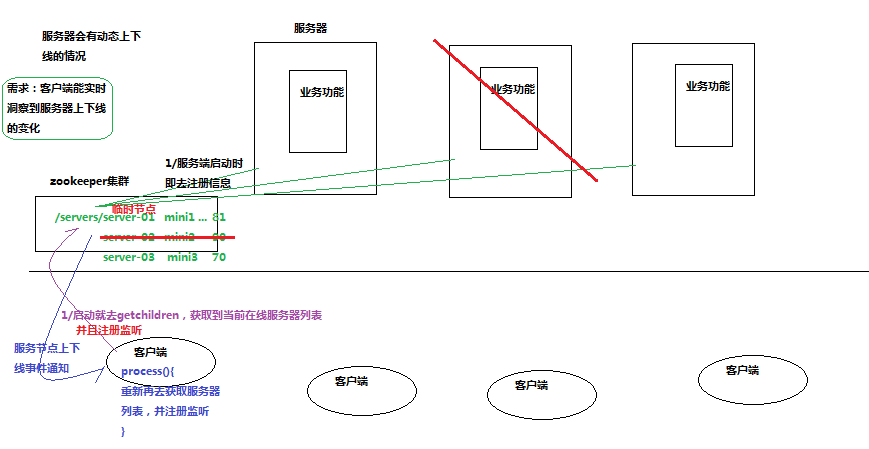
PS:客户端程序 ,先启动客户端
package cn.itcast.bigdata.zkdist; import java.util.ArrayList;
import java.util.List; import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper; public class DistributedClient { private static final String connectString = "bee1:2181,bee2:2181,bee3:2181";
private static final int sessionTimeout = 2000;
private static final String parentNode = "/servers";
// 注意:加volatile的意义何在?
private volatile List<String> serverList;
private ZooKeeper zk = null; /**
* 创建到zk的客户端连接
*
* @throws Exception
*/
public void getConnect() throws Exception { zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 收到事件通知后的回调函数(应该是我们自己的事件处理逻辑)
try {
//重新更新服务器列表,并且注册了监听
getServerList(); } catch (Exception e) {
}
}
}); } /**
* 获取服务器信息列表
*
* @throws Exception
*/
public void getServerList() throws Exception { // 获取服务器子节点信息,并且对父节点进行监听
List<String> children = zk.getChildren(parentNode, true); // 先创建一个局部的list来存服务器信息
List<String> servers = new ArrayList<String>();
for (String child : children) {
// child只是子节点的节点名
byte[] data = zk.getData(parentNode + "/" + child, false, null);
servers.add(new String(data));
}
// 把servers赋值给成员变量serverList,已提供给各业务线程使用
serverList = servers; //打印服务器列表
System.out.println(serverList); } /**
* 业务功能
*
* @throws InterruptedException
*/
public void handleBussiness() throws InterruptedException {
System.out.println("client start working.....");
Thread.sleep(Long.MAX_VALUE);
} public static void main(String[] args) throws Exception { // 获取zk连接
DistributedClient client = new DistributedClient();
client.getConnect();
// 获取servers的子节点信息(并监听),从中获取服务器信息列表
client.getServerList(); // 业务线程启动
client.handleBussiness(); } }
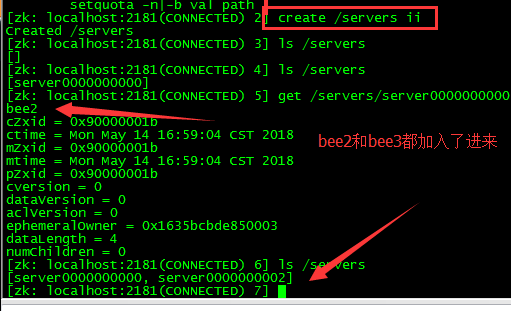
PS:启动服务器端并配置参数,依次为bee2 、bee3
package cn.itcast.bigdata.zkdist; import org.apache.zookeeper.CreateMode;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooDefs.Ids;
import org.apache.zookeeper.ZooKeeper; public class DistributedServer {
private static final String connectString = "bee1:2181,bee2:2181,bee3:2181";
private static final int sessionTimeout = 2000;
private static final String parentNode = "/servers"; private ZooKeeper zk = null; /**
* 创建到zk的客户端连接
*
* @throws Exception
*/
public void getConnect() throws Exception { zk = new ZooKeeper(connectString, sessionTimeout, new Watcher() {
@Override
public void process(WatchedEvent event) {
// 收到事件通知后的回调函数(应该是我们自己的事件处理逻辑)
System.out.println(event.getType() + "---" + event.getPath());
try {
zk.getChildren("/", true);
} catch (Exception e) {
}
}
}); } /**
* 向zk集群注册服务器信息
*
* @param hostname
* @throws Exception
*/
public void registerServer(String hostname) throws Exception { String create = zk.create(parentNode + "/server", hostname.getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
System.out.println(hostname + "is online.." + create); } /**
* 业务功能
*
* @throws InterruptedException
*/
public void handleBussiness(String hostname) throws InterruptedException {
System.out.println(hostname + "start working.....");
Thread.sleep(Long.MAX_VALUE);
} public static void main(String[] args) throws Exception { // 获取zk连接
DistributedServer server = new DistributedServer();
server.getConnect(); // 利用zk连接注册服务器信息
server.registerServer(args[0]); // 启动业务功能
server.handleBussiness(args[0]); } }
PS:这个是为了程序稳定一直执行,程序退出,才退出
package cn.itcast.bigdata.zkdist;
public class Test {
public static void main(String[] args) {
System.out.println("主线程开始了");
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("线程开始了");
while(true){
}
}
});
thread.setDaemon(true);
thread.start();
}
}
PS: 测试
day3 zookeeper的更多相关文章
- 架构设计:远程调用服务架构设计及zookeeper技术详解(下篇)
一.下篇开头的废话 终于开写下篇了,这也是我写远程调用框架的第三篇文章,前两篇都被博客园作为[编辑推荐]的文章,很兴奋哦,嘿嘿~~~~,本人是个很臭美的人,一定得要截图为证: 今天是2014年的第一天 ...
- [译]ZOOKEEPER RECIPES-Leader Election
选主 使用ZooKeeper选主的一个简单方法是,在创建znode时使用Sequence和Ephemeral标志.主要思想是,使用一个znode,比如"/election",每个客 ...
- zookeeper源码分析之六session机制
zookeeper中session意味着一个物理连接,客户端连接服务器成功之后,会发送一个连接型请求,此时就会有session 产生. session由sessionTracker产生的,sessio ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
- zookeeper源码分析之三客户端发送请求流程
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的 ...
- zookeeper源码分析之二客户端启动
ZooKeeper Client Library提供了丰富直观的API供用户程序使用,下面是一些常用的API: create(path, data, flags): 创建一个ZNode, path是其 ...
- zookeeper源码分析之一服务端启动过程
zookeeper简介 zookeeper是为分布式应用提供分布式协作服务的开源软件.它提供了一组简单的原子操作,分布式应用可以基于这些原子操作来实现更高层次的同步服务,配置维护,组管理和命名.zoo ...
- zookeeper集群的搭建以及hadoop ha的相关配置
1.环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源 ...
随机推荐
- 通过滑动条控制Cube旋转
private float speed = 10; private float speedValue; private GameObject slider; private GameObject cu ...
- Java日期时间,以及相互转换
Java日期时间,以及相互转化 package com.study.string; import java.text.ParseException; import java.text.SimpleDa ...
- mysql插入中文乱码
https://www.cnblogs.com/zhchoutai/p/7364835.html 最简单的一招,不用修改my.ini文件: 1.停掉mysql服务 2.启动:X:\%path%\MyS ...
- SignalR NuGet程序包
最近公司有一个边看直播边聊天的需求,直播好搞,直接用腾讯的小直播,组装推流和播放地址,把推流地址拿出去就OK,只要一推流,就可以使用播放地址观看直播,看完后通过webclient去异步下载直播的视频到 ...
- sas 选择一段日期,和一定周期,生成日期序列和周期序列
工作需要,得选择一段日期,和一定周期,生成日期序列和周期序列.暂时用七天为一个周期 data d; format date date9.; do date='04mar2018'd to'05may2 ...
- Java垃圾回收理解
gc是垃圾回收,Java的垃圾回收分为年轻代回收和老年代回收,其中年轻代回收速度快,频率高,因为Java对象大多具有朝生夕灭的特性,Java对象都是new出来的,当new出很多对象的时候,年轻代很容易 ...
- struts请求参数注入的三种方式
.请求参数的注入 在Struts2框架中,表单的提交的数据会自动注入到与Action对象相对应的属性.它与Spring框架中的IoC的注入原理相同,通过Action对象为属性提供setter方法注入 ...
- [MyBatis] MyBatis理论入门
什么是MyBatis iBATIS提供的持久层框架包括SQL Maps和Data Access Objects(DAOs) 是一款优秀的持久层框架,它支持定制化 SQL.存储过程以及高级映射. MyB ...
- [转]内存分配malloc, new , heapalloc
malloc,new,VirtualAlloc,HeapAlloc性能(速度)比较 http://www.cppblog.com/woaidongmao/archive/2011/08/12/1531 ...
- threejs绘制顺序
renderer.sortObjects = false; 然后,scene.add(),就可以先add先画了,否则add的顺序和渲染出来的顺序不一定一致.