kmeans笔记
1.算法过程
a.随机选取k个初始点作为中心点
b.依次计算剩余所有点分别与哪个初始点距离较近,则该点属于哪个簇
c.移动中心点到现在的簇的中心
d.重复b,c两步,直到中心点不再变化算法结束
2.优缺点
优点:容易实现
缺点:可能收敛到局部最小值,大规模数据集上收敛速度较慢
3.代码使用中出现的问题思考
调用sklearn中该模块:
k=8
kmeans = KMeans(n_clusters=k, random_state=0).fit(X)
也就是需要指定聚类个数,但是如何确定k值?有以下几种方法
a.最好有经验,通过经验指定
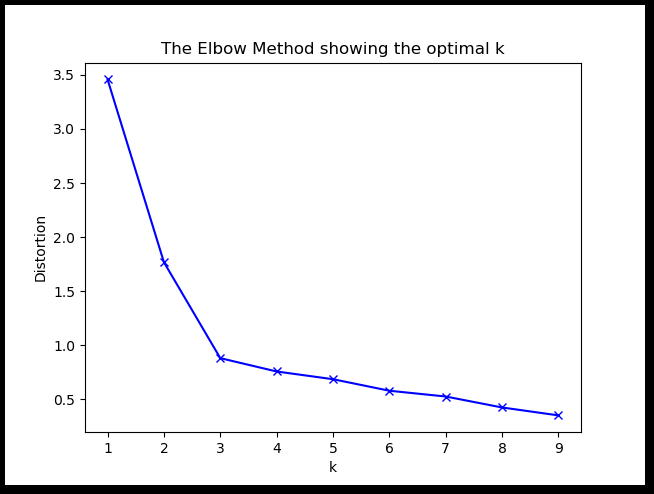
b.通过elbow method来确定,选取绘图结果k-elbow 直线拐点处对应的k值作为聚类个数。如下代码:
# clustering dataset
# determine k using elbow method from sklearn.cluster import KMeans
from sklearn import metrics
from scipy.spatial.distance import cdist
import numpy as np
import matplotlib.pyplot as plt x1 = np.array([3, 1, 1, 2, 1, 6, 6, 6, 5, 6, 7, 8, 9, 8, 9, 9, 8])
x2 = np.array([5, 4, 5, 6, 5, 8, 6, 7, 6, 7, 1, 2, 1, 2, 3, 2, 3]) plt.plot()
plt.xlim([0, 10])
plt.ylim([0, 10])
plt.title('Dataset')
plt.scatter(x1, x2)
plt.show() # create new plot and data
plt.plot()
X = np.array(list(zip(x1, x2))).reshape(len(x1), 2)
colors = ['b', 'g', 'r']
markers = ['o', 'v', 's'] # k means determine k
distortions = []
K = range(1,10)
for k in K:
kmeanModel = KMeans(n_clusters=k).fit(X)
kmeanModel.fit(X)
distortions.append(sum(np.min(cdist(X, kmeanModel.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0]) # Plot the elbow
plt.plot(K, distortions, 'bx-')
plt.xlabel('k')
plt.ylabel('Distortion')
plt.title('The Elbow Method showing the optimal k')
plt.show()
如上图,取k值为3. c.ISODATA算法针对这个问题进行了改进:当属于某个类别的样本数过少时把这个类别去除,当属于某个类别的样本数过多、分散程度较大时把这个类别分为两个子类别(类的自动合并和分裂)
d.还有以下几种方法,不过目前我没有理解其中的意义(2018.10.24)
- 根据方差分析理论,应用混合 F 统计量来确定最佳分类数,并应用了模糊划分熵来验证最佳分类数的正确性
- 使用了一种结合全协方差矩阵的 RPCL 算法,并逐步删除那些只包含少量训练数据的类(一种聚类算法)
- 使用的是一种称为次胜者受罚的竞争学习规则,来自动决定类的适当数目。它的思想是:对每个输入而言,不仅竞争获胜单元的权值被修正以适应输入值,而且对次胜单元采用惩罚的方法使之远离输入值。
4.噪声处理
k-means对离群值很敏感,,算法目标是簇内差异最小化,即SSE最小。
1.可以改用密度聚类,目标为类内距离最小,类间距离最大。
2.在假设目前聚类结果正确的前提下,通过计算p-value来决定聚类效果是否具有显著差异,去掉每个簇中的异常点。
(p-value指的是比较的两者的差别是由机遇所致的可能性大小。P值越小,越有理由认为对比事物间存在差异。例如,P<0.05,就是说结果显示的差别是由机遇所致的可能性不足5%,或者说,别人在同样的条件下重复同样的研究,得出相反结论的可能性不足5%。P>0.05称“不显著”;P<=0.05称“显著”,P<=0.01称“非常显著”)
kmeans笔记的更多相关文章
- retrival and clustering : week 3 k-means 笔记
华盛顿大学 machine learning 笔记. K-means algorithm 算法步骤: 0. 初始化几个聚类中心 (cluster centers)μ1,μ2, … , μk 1. 将所 ...
- 机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记
机器学习实战(Machine Learning in Action)学习笔记————06.k-均值聚类算法(kMeans)学习笔记 关键字:k-均值.kMeans.聚类.非监督学习作者:米仓山下时间: ...
- k-means学习笔记
最近看了吴恩达老师的机器学习教程(可以在Coursera,或者网易云课堂上找到)中讲解的k-means聚类算法,k-means是一种应用非常广泛的无监督学习算法,使用比较简单,但其背后的思想是EM算法 ...
- Deep Learning论文笔记之(一)K-means特征学习
Deep Learning论文笔记之(一)K-means特征学习 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感 ...
- Python机器学习笔记:K-Means算法,DBSCAN算法
K-Means算法 K-Means 算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means 算法有大量的变体,本文就从最传统的K-Means算法学起,在其基础上学习 ...
- 郑捷《机器学习算法原理与编程实践》学习笔记(第四章 推荐系统原理)(二)kmeans
(上接第二章) 4.3.1 KMeans 算法流程 算法的过程如下: (1)从N个数据文档随机选取K个文档作为质心 (2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类 (3)重新计 ...
- python ML 笔记:Kmeans
kmeans算法的python实现: 参考与样本来源<Machine Learning in Action> #-*-coding:UTF-8-*- ''' Created on 2015 ...
- 机器学习公开课笔记(8):k-means聚类和PCA降维
K-Means算法 非监督式学习对一组无标签的数据试图发现其内在的结构,主要用途包括: 市场划分(Market Segmentation) 社交网络分析(Social Network Analysis ...
- Python_sklearn机器学习库学习笔记(五)k-means(聚类)
# K的选择:肘部法则 如果问题中没有指定 的值,可以通过肘部法则这一技术来估计聚类数量.肘部法则会把不同 值的成本函数值画出来.随着 值的增大,平均畸变程度会减小:每个类包含的样本数会减少,于是样本 ...
随机推荐
- 批量 kill mysql 线程
时常有一些烂sql跑在数据库里,我们要进行kill,避免影响拖垮数据库. mysql> show processlist; +----+------+---------------------+ ...
- GitHub私有代码库将免费开放
1月8号消息,微软收购 GitHub 后,官方宣布了一项重大更新:免费开放私有代码库, 即 GitHub 用户现在可以免费创建无限量的私有存储库.同时还有另一项更新——GitHub Enterpris ...
- [PHP] 03 - Form & Input
PHP 完整表单实例 一.表单示范 二.对应代码 <!DOCTYPE HTML> <html> <head> <meta charset="utf- ...
- opencv各种绘图 直线 矩形 圆 椭圆
画图函数 (1)直线cvLine函数 其结构 void cvLine(//画直线 CvArr* array,//画布图像 CvPoint pt1,//起始点 CvPoint pt2,//终点 CvSc ...
- WebApi中的Session与Token间的处理对接
首先,说起来创建session,一般会针对注册登录或者授权等情况: session 从字面上讲,就是会话.这个就类似于你和一个人交谈,你怎么知道当前和你交谈的是张三而不是李四呢?对方肯定有某种特征(长 ...
- 国外源码精品-Android-PullToRefresh 简介与DEMO导入
转载地址:http://my.oschina.net/cuitongliang/blog/170708 (一)&&http://my.oschina.net/cuitongliang/ ...
- js - 常用功能方法汇总(updating...)
一.查值的类型(可用于拷贝) /* * @Author: guojufeng@ * @Date: 2017-12-20 15:07:06 * @purpose 获取一个值的类型 * @param {v ...
- Shape使用
<shape> <!-- 实心 --> <solid android:color="#ff9d77"/> <!-- 渐变 --> & ...
- ASP.NET MVC与ASP.NET Web Form简单区别
概论: Asp.net 微软 提供web开发框架或者技术.分Web Form和ASP.NET MVC.下面简单说明各自优缺点及使用场景. Web Form 优点: 1.支持丰富的服务器控件.如:Gr ...
- Android定时执行和停止某任务
一.定义全局变量 int runCount = 0;// 全局变量,用于判断是否是第一次执行 Handler handlerCount = new Handler(); 二.创建Runnable Ru ...