Weka中数据挖掘与机器学习系列之数据格式ARFF和CSV文件格式之间的转换(五)
不多说,直接上干货!
Weka介绍:
Weka是一个用Java编写的数据挖掘工具,能够运行在各种平台上。它不仅提供了可以直接用于数据挖掘的软件,还提供了src代码,使用者可以修改源代码,进行二次开发。但是,由于其使用了Java虚拟机,导致其不适合处理大型数据,运行缓慢。处理超过一定大小数据,还会溢出heap size,使程序崩溃。但作为初学者,很适合通过处理一些小型数据集,以直观地了解各种数据挖掘方法。它还自带一些典型的数据集,可以直接使用。在安装目录下的data子目录中。
Weka通常使用ARFF文件格式的文件。也可以直接使用CSV文件格式的文件,但与传统CSV文件不同,Weka能识别的CSV文件要求第一行给各列的定义。因为CSV文件比较容易获得,excel表格文件可以直接另存为csv文件。推荐使用csv文件。
以著名数据挖掘数据集鸢尾花为例,该数据集对应的iris.csv文件应如下所示:
sepal-length,sepal-width,petal-length,petal-width,class
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
1、使用Weka工具,将ARFF文件转换成CSV文件

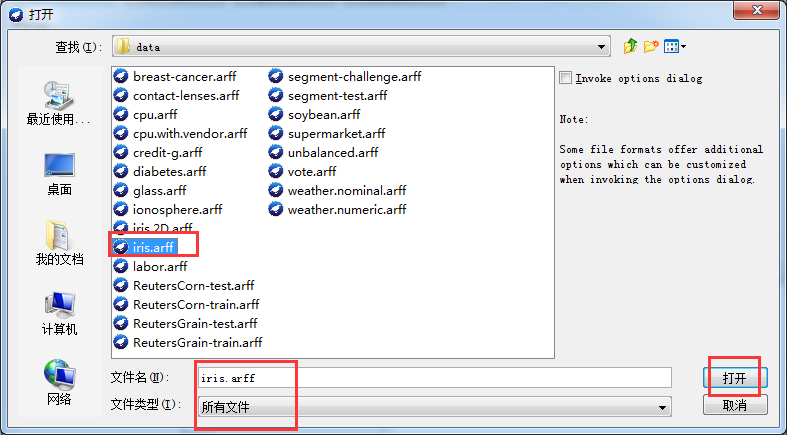
进入Explorer模块,点击界面上方的按钮“open file”打开文件选择面板,将面板下方的文件类型选择“所有文件”,找到
iris.arff文件即可将数据导入到Explorer如下图所示。


得到




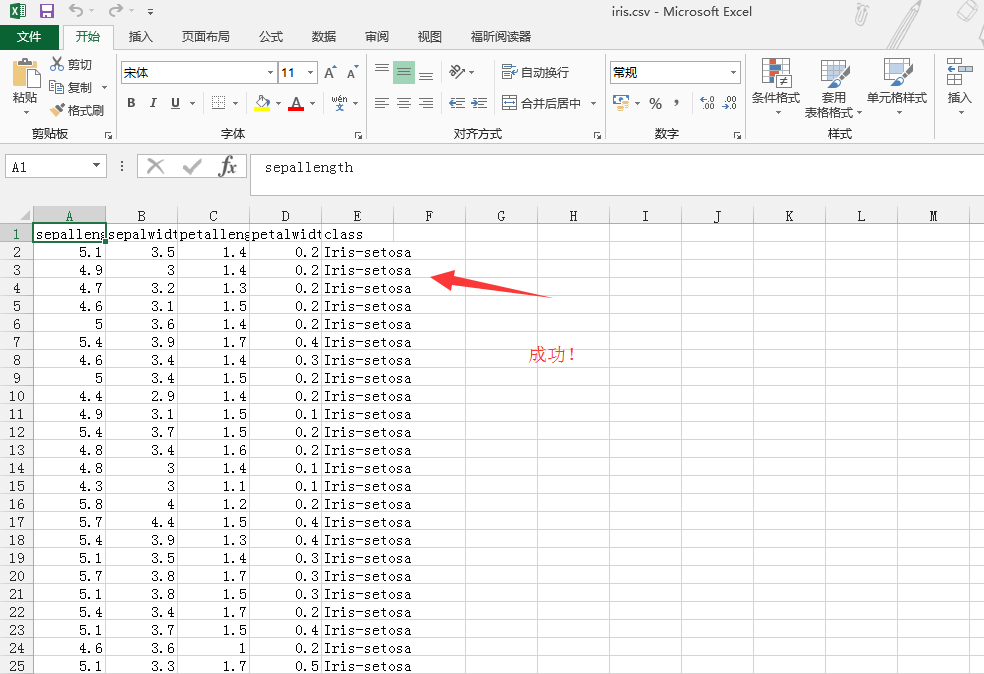
2、使用Weka工具,将CSV文件转换成ARFF文件
打开Weka的Explorer界面
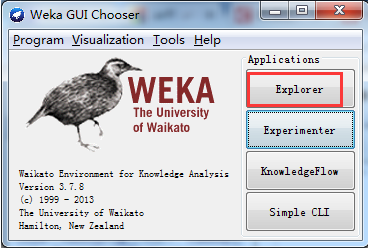
比如,这里,我先把iris.arff拷贝到桌面去。
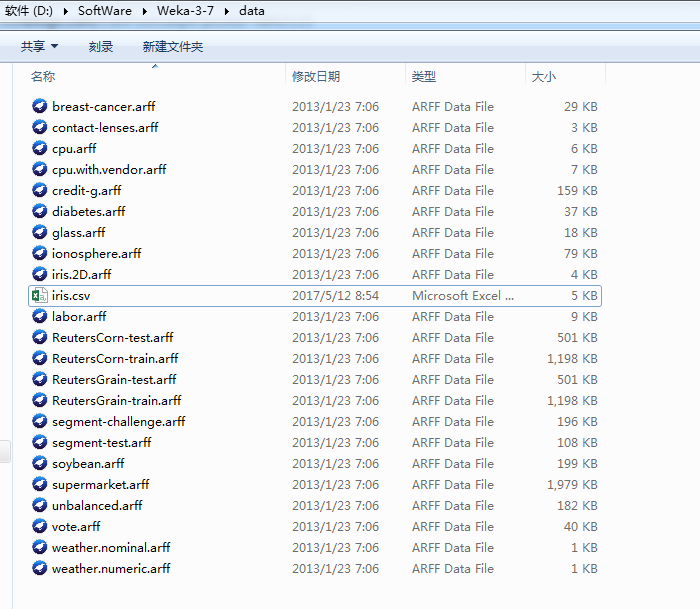
然后,在preprocess->open file

将面板下方的文件类型选择“所有文件”,找到iris.csv
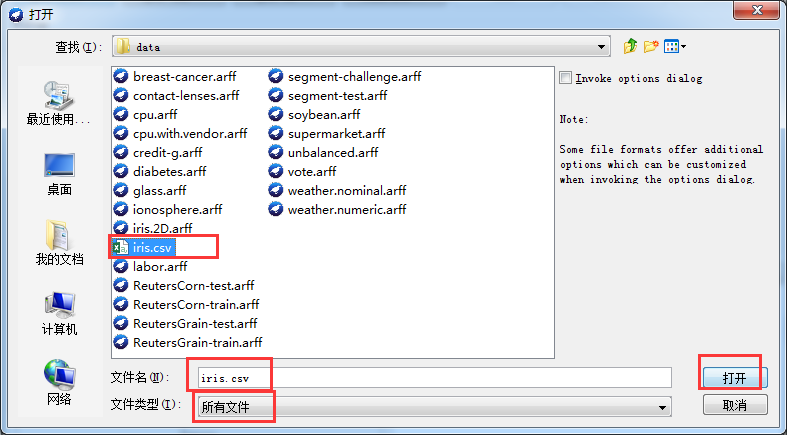

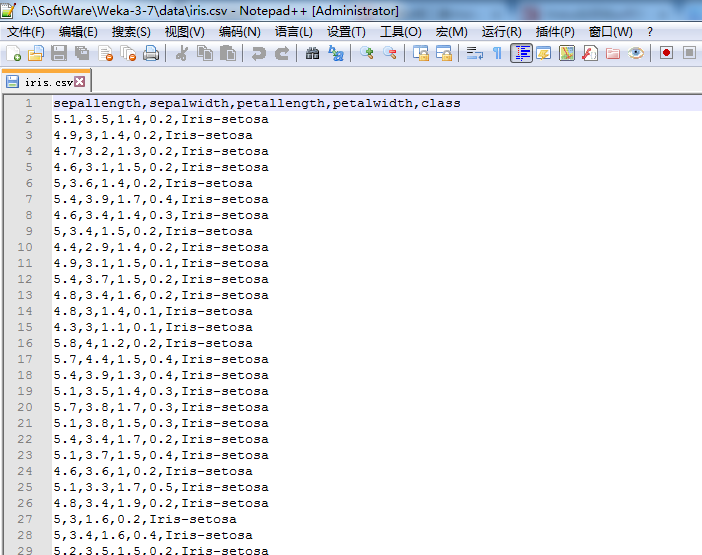
通过save可以将CSV文件另存为ARFF文件。格式如下图所示:


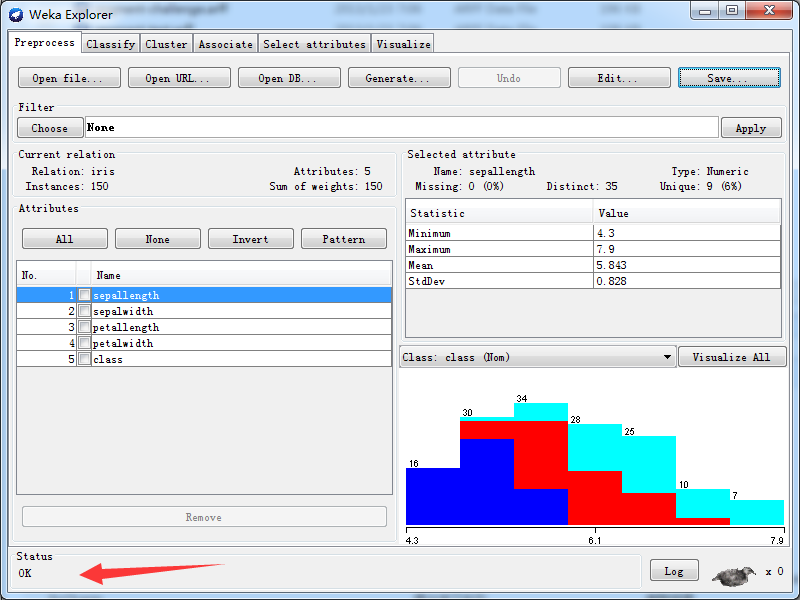
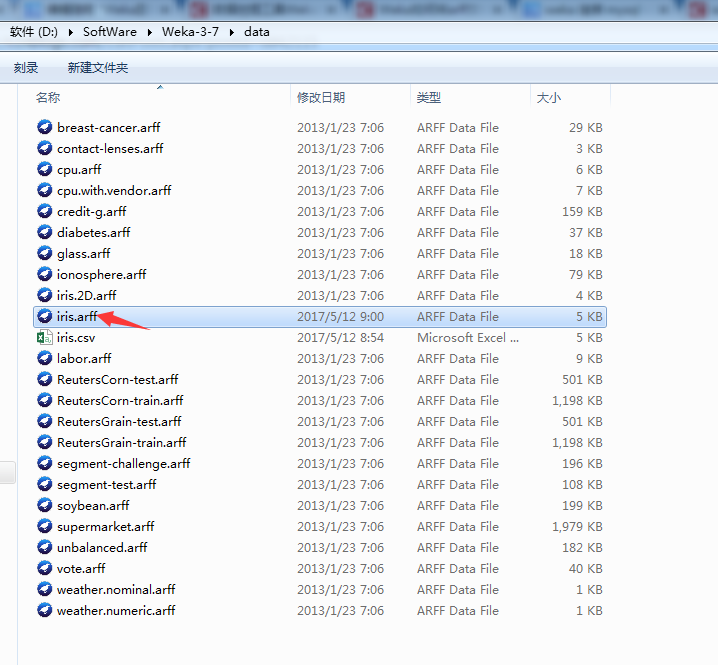
成功!
Weka中数据挖掘与机器学习系列之数据格式ARFF和CSV文件格式之间的转换(五)的更多相关文章
- Weka中数据挖掘与机器学习系列之Weka系统安装(四)
能来看我这篇博客的朋友,想必大家都知道,Weka采用Java编写的,因此,具有Java“一次编译,到处运行”的特性.支持的操作系统有Windows x86.Windows x64.Mac OS X.L ...
- Weka中数据挖掘与机器学习系列之Exploer界面(七)
不多说,直接上干货! Weka的Explorer(探索者)界面,是Weka的主要图形化用户界面,其全部功能都可通过菜单选择或表单填写进行访问.本博客将详细介绍Weka探索者界面的图形化用户界面.预处理 ...
- Weka中数据挖掘与机器学习系列之Weka Package Manager安装所需WEKA的附加算法包出错问题解决方案总结(八)
不多说,直接上干货! Weka中数据挖掘与机器学习系列之Weka系统安装(四) Weka中数据挖掘与机器学习系列之Weka3.7和3.9不同版本共存(七) 情况1 对于在Weka里,通过Weka P ...
- Weka中数据挖掘与机器学习系列之Weka3.7和3.9不同版本共存(七)
不多说,直接上干货! 为什么,我要写此博客,原因是(以下,我是weka3.7.8) 以下是,weka3.7.8的安装版本. Weka中数据挖掘与机器学习系列之Weka系统安装(四) 基于此,我安装最新 ...
- Weka中数据挖掘与机器学习系列之Weka简介(二)
不多说,直接上干货! Weka简介 Weka是怀卡托智能分析环境(Waikato Environment for Knowledge Analysis)的英文字首缩写,官方网址为:http://www ...
- Weka中数据挖掘与机器学习系列之基本概念(三)
数据挖掘和机器学习 数据挖掘和机器学习这两项技术的关系非常密切.机器学习方法构成数据挖掘的核心,绝大多数数据挖掘技术都来自机器学习领域,数据挖掘又向机器学习提出新的要求和任务. 数据挖掘就是在数据中寻 ...
- Weka中数据挖掘与机器学习系列之为什么要写Weka这一系列学习笔记?(一)
本人正值科研之年,同时也在使用Weka来做相关数据挖掘和机器学习的论文工作. 为了记录自己的学习历程,也便于分享和带领入门的你们.废话不多说,直接上干货!
- python中的2、8、16、10进制之间的转换
python除法的坑 众所周知,python除法有两个运算符,一个是/,还有一个是//,那么这两个有什么不同之处呢? 从图片可以得知,使用//返回一个float类型,而使用/返回一个int类型.我们总 ...
- 干货!Python中字符串、列表、元祖、字典,集合之间的转换
一.字符串的转化 1.字符串转换成列表 字符串转换成list 的时候,str可以作为迭代对象,直接放入:也可以使用split对字符串进行切割.然后返回list s = '1a1b1c' print(l ...
随机推荐
- 堆+建堆、插入、删除、排序+java实现
package testpackage; import java.util.Arrays; public class Heap { //建立大顶堆 public static void buildMa ...
- [osg][osgEarth][osgGA][原] EarthManipulator------基于oe的相机漫游器(浅析)
知识基础:osg漫游器基础 class OSGEARTHUTIL_EXPORT EarthManipulator : public osgGA::CameraManipulator EarthMani ...
- leecode第七十题(爬楼梯)
class Solution { public: int climbStairs(int n) { vector<unsigned long long> num;//斐波那契数列 num. ...
- 学习笔记30—Windows那些事
1.win10编程窗口:powerShell 2.Win7设置工具栏折叠:我们只需要在底部任务栏空白位置点击鼠标右键,然后选择“属性”,在弹出额属性对话框中,将“任务栏按钮”后面的“始终合并.隐藏标签 ...
- Mybatis中resultType理解
- Codeforces 1043 F - Make It One
F - Make It One 思路: dp + 容斥 首先, 答案不会超过7, 因为前7个质数的乘积大于3e5(最坏的情况是7个数, 每个数都缺少一个不同的因子) 所以从1到7依次考虑 dp[i][ ...
- 数据渲染模板引擎,template-web的使用
一:下载 template-web.js 下载地址:https://aui.github.io/art-template/zh-cn/docs/installation.html 二:引用: 三:ht ...
- 细胞迁移 | cell migration
一些基本概念: intracellular biochemical signaling pathways:胞内生化信号通路 extracellular mechanical cues: 胞外机械信号 ...
- css图片的全屏显示代码-css3
<!DOCTYPE html><html lang="en"> <head> <meta charset="UTF-8" ...
- linux权限管理之基本权限
基本权限 UGO ======================================================== 文件权限设置: 可以赋于某个用户或组 能够以何种方式 访问某个文件 ...