Spark学习笔记——RDD编程
1.RDD——弹性分布式数据集(Resilient Distributed Dataset)
RDD是一个分布式的元素集合,在Spark中,对数据的操作就是创建RDD、转换已有的RDD和调用RDD操作进行求值。
Spark 中的 RDD 就是一个不可变的分布式对象集合。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。
object WordCount {
def main(args: Array[String]) {
val inputFile = "file:///home/common/coding/coding/Scala/word-count/test.segmented"
val conf = new SparkConf().setAppName("WordCount").setMaster("local") #创建一个SparkConf对象来配置应用<br> #集群URL:告诉Spark连接到哪个集群,local是单机单线程,无需连接到集群,应用名:在集群管理器的用户界面方便找到应用
val sc = new SparkContext(conf) #然后基于这SparkConf创建一个SparkContext对象
val textFile = sc.textFile(inputFile) #读取输入的数据
val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b) #切分成单词,转换成键值对并计数
wordCount.foreach(println)
}
}
创建一个RDD
val textFile = sc.textFile(inputFile)
或者
val lines = sc.parallelize(List("pandas", "i like pandas"))
RDD支持两种类型的操作: 转化操作(transformation)和行动操作(action)。
转化操作,是返回一个新的RDD的操作:
filter()函数
val RDD = textFile.filter(line => line.contains("Hadoop"))
map()函数
val input = sc.parallelize(List(1, 2, 3, 4))
val result = input.map(x => x * x)
println(result.collect().mkString(","))
输出
1,4,9,16
map()和flatMap()的区别
val input1 = sc.parallelize(List("hello world","hi"))
val lines = input1.map(line => line.split(" "))
for(line <- lines)
println(line) //输出是两个List的地址
val lines_ = input1.flatMap(line => line.split(" "))
for(line_ <- lines_)
println(line_) //输出是[hello world hi]
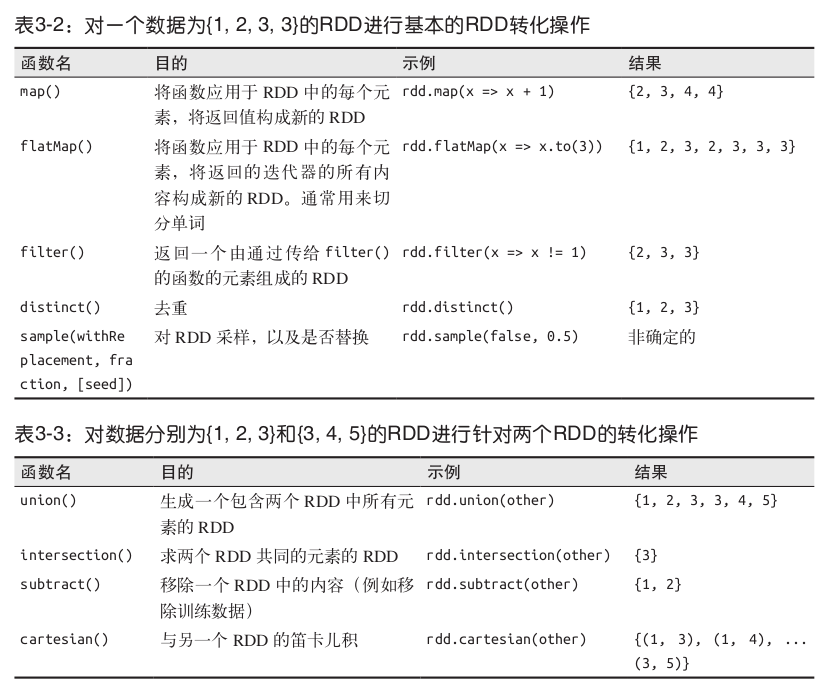
行动操作,是向驱动器程序返回结果或把结果写入外部系统的操作,会触发实际的计算:first()、count()、take()、collect()[获取整个RDD中的数据,只有想在本地处理这些数据的时候,才可以使用,因为一般情况下RDD很大]
take()函数
textFile.take(5).foreach(println)
reduce函数,接收一个函数作为参数
val input = sc.parallelize(List(1, 2, 3, 4))
val sum = input.reduce((x, y) => x + y)
println(sum) //输出1-4的累加和,10
aggregate()函数,计算List的和以及List的元素个数,然后计算平均值
val input = sc.parallelize(List(1, 2, 3, 4))
val result = input.aggregate((0, 0))(
(acc, value) => (acc._1 + value, acc._2 + 1),
(acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2))
val avg = result._1 / result._2.toDouble
println(result)
println(avg)
输出
(10,4)
2.5
对于
val sum1 = input.aggregate((0, 0))((x, y) => (x._1 + y, x._2 + 1), (x, y) => (x._1 + y._1, x._2 + y._2))
输出(10,4)
理解
过程大概这样:
首先,初始值是(0,0),这个值在后面2步会用到。
然后,(acc,number) => (acc._1 + number, acc._2 + 1),number即是函数定义中的T,这里即是List中的元素。所以acc._1 + number, acc._2 + 1的过程如下。
1. 0+1, 0+1
2. 1+2, 1+1
3. 3+3, 2+1
4. 6+4, 3+1
5. 10+5, 4+1
6. 15+6, 5+1
7. 21+7, 6+1
8. 28+8, 7+1
9. 36+9, 8+1
结果即是(45,9)。这里演示的是单线程计算过程,实际Spark执行中是分布式计算,可能会把List分成多个分区,假如3个,p1(1,2,3,4),p2(5,6,7,8),p3(9),经过计算各分区的的结果(10,4),(26,4),(9,1),这样,执行(par1,par2) => (par1._1 + par2._1, par1._2 + par2._2)就是(10+26+9,4+4+1)即(45,9).再求平均值就简单了。
top()函数,可以返回RDD的前几个元素
fold()函数,和reduce()函数的功能差不多,但是需要提供初始值
val numbers = List(1, 2, 3, 4)
println(
numbers.fold(1) {
(a, b) => a + b
}
)
输出11

转化操作和行动操作的区别:
1.转换操作只会惰性计算这些 RDD
2.行动操作会对 RDD 计算出一个结果,并把结果返回到驱动器程序中,或把结果存储到外部存储系统(如 HDFS)中
默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist() 让 Spark 把这个 RDD 缓存下来
2.向Spark传递函数
在 Scala 中,我们可以把定义的内联函数、方法的引用或静态方法传递给 Spark。
我们可以把需要的字段放到一个局部变量中,来避免传递包含该字段的整个对象
class SearchFunctions(val query: String) {
def isMatch(s: String): Boolean = {
s.contains(query)
}
def getMatchesFunctionReference(rdd: RDD[String]): RDD[String] = {
// 问题: "isMatch"表示"this.isMatch",因此我们要传递整个"this"
rdd.map(isMatch)
}
def getMatchesFieldReference(rdd: RDD[String]): RDD[String] = {
// 问题: "query"表示"this.query",因此我们要传递整个"this"
rdd.map(x => x.split(query))
}
def getMatchesNoReference(rdd: RDD[String]): RDD[String] = {
// 安全:只把我们需要的字段拿出来放入局部变量中
val query_ = this.query
rdd.map(x => x.split(query_))
}
}
3.持久化(缓存)
Spark RDD 是惰性求值的,而有时我们希望能多次使用同一个 RDD的时候需要对RDD进行持久化
两次调用行动操作,每次Spark都会重新计算RDD和它的所有依赖
val result = input.map(x => x*x)
println(result.count())
println(result.collect().mkString(","))
使用persist()来进行持久化
val result = input.map(x => x * x)
result.persist(StorageLevel.DISK_ONLY)
println(result.count())
println(result.collect().mkString(","))
如果要缓存的数据太多,内存中放不下,Spark 会自动利用最近最少使用(LRU)的缓存策略把最老的分区从内存中移除。
RDD 还有一个方法叫作 unpersist() ,调用该方法可以手动把持久化的 RDD 从缓存中移除。
Spark学习笔记——RDD编程的更多相关文章
- Spark学习之RDD编程(2)
Spark学习之RDD编程(2) 1. Spark中的RDD是一个不可变的分布式对象集合. 2. 在Spark中数据的操作不外乎创建RDD.转化已有的RDD以及调用RDD操作进行求值. 3. 创建RD ...
- Spark学习之RDD编程总结
Spark 对数据的核心抽象——弹性分布式数据集(Resilient Distributed Dataset,简称 RDD).RDD 其实就是分布式的元素集合.在 Spark 中,对数据的所有操作不外 ...
- Spark学习(2) RDD编程
什么是RDD RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.弹性.里面的元素可并行计算的集合 RDD允 ...
- Spark学习笔记3——RDD(下)
目录 Spark学习笔记3--RDD(下) 向Spark传递函数 通过匿名内部类 通过具名类传递 通过带参数的 Java 函数类传递 通过 lambda 表达式传递(仅限于 Java 8 及以上) 常 ...
- Spark学习笔记2——RDD(上)
目录 Spark学习笔记2--RDD(上) RDD是什么? 例子 创建 RDD 并行化方式 读取外部数据集方式 RDD 操作 转化操作 行动操作 惰性求值 Spark学习笔记2--RDD(上) 笔记摘 ...
- spark学习笔记总结-spark入门资料精化
Spark学习笔记 Spark简介 spark 可以很容易和yarn结合,直接调用HDFS.Hbase上面的数据,和hadoop结合.配置很容易. spark发展迅猛,框架比hadoop更加灵活实用. ...
- Spark学习笔记0——简单了解和技术架构
目录 Spark学习笔记0--简单了解和技术架构 什么是Spark 技术架构和软件栈 Spark Core Spark SQL Spark Streaming MLlib GraphX 集群管理器 受 ...
- Spark学习笔记之SparkRDD
Spark学习笔记之SparkRDD 一. 基本概念 RDD(resilient distributed datasets)弹性分布式数据集. 来自于两方面 ① 内存集合和外部存储系统 ② ...
- Spark学习笔记-GraphX-1
Spark学习笔记-GraphX-1 标签: SparkGraphGraphX图计算 2014-09-29 13:04 2339人阅读 评论(0) 收藏 举报 分类: Spark(8) 版权声明: ...
随机推荐
- BZOJ.3510.首都(LCT 启发式合并 树的重心)
题目链接 BZOJ 洛谷 详见这. 求所有点到某个点距离和最短,即求树的重心.考虑如何动态维护. 两棵子树合并后的重心一定在两棵树的重心之间那条链上,所以在合并的时候用启发式合并,每合并一个点检查sz ...
- 如何实现跨域获取iframe子页面动态的url
有的时候iframe的子页面会动态的切换页面,我们在父页面通过iframe1.contentWindow.window.location只能获取同源的子页面的信息.获取跨域的子页面信息会报错. 这时可 ...
- Codeforces Round #532 (Div. 2)
Codeforces Round #532 (Div. 2) A - Roman and Browser #include<bits/stdc++.h> #include<iostr ...
- windows命名管道
命名管道是通过网络来完成进程间的通信,它屏蔽了底层的网络协议细节. 将命名管道作为一种网络编程方案时,它实际上建立了一个C/S通信体系,并在其中可靠的传输数据.命名管道服务器和客户机的区别在于:服务器 ...
- 针对UDP丢包问题,进行系统层面和程序层面调优
转自:https://blog.csdn.net/xingzheouc/article/details/49946191 1. UDP概念 用户数据报协议(英语:User Datagram Proto ...
- Spring AOP获取拦截方法的参数名称跟参数值
注意:这种方式需要JDK1.8版本支持 开始:http://www.cnblogs.com/wing7319/p/9592184.html 1.aop配置: <aop:aspectj-autop ...
- Android进程命令查看
• 进程 是指一个具有独立功能的程序在某个数据集上的一次动态运行过程,它是系统进行资源分配和调度的最小单元. • 一个进程能够拥有多个线程.每一个线程必须有一个父进程. • ...
- windows IOCP入门的一些资料
最近需要看一个中间件的IOCP处理模块,需要了解这方面的知识 https://www.codeproject.com/articles/13382/a-simple-application-using ...
- Visual Studio 统计代码行数
介绍一种简单的统计代码行数的小技巧, 使用正则表达式,用VS强大的查找功能 b[^:b#/]+.$ 最后结果:
- springMVC之mvc:interceptors拦截器的用法
1.配置拦截器 在springMVC.xml配置文件增加: <mvc:interceptors> <!-- 日志拦截器 --> <mvc:interceptor> ...