oracle 11g亿级复杂SQL优化一例(数量级性能提升)
自从16年之后,因为工作原因,项目中就没有再使用oracle了,最近最近支持一个项目,又要开始负责这块事情了。最近在跑性能测试,配置全部调好之后,不少sql还存在性能低下的问题,主要涉及执行计划的不合理,以及相关pga隐含参数的优化。可能因为几年不接触的原因,略微有些生疏需要review了。这里以最近优化过的某个比较典型的例子为例(这里只讲思路、因为涉及到敏感信息,不给出最终结果,16C E5620@2.40GHz/45GB内存/fio 85/15 iops 8500/1500 配置,优化前100G临时空间都爆掉,到20分钟出结果,实际上允许完全调整的话,最多5分钟就可以运行出来),这个例子比较经典,它是一个产品转换的例子,从业务逻辑上来看,它需要对两个100w(100管理人*1w支产品)记录的结果集进行黑名单(是指A产品->B产品是否允许转换,A->B不允许,不意味着B->A不允许)以外的笛卡尔积关联,,重点回顾下一些重要的operation以及如何通过hint强制,子查询独立运行时的operation和作为主查询的子查询运行时的operation不相同可能会造成性能差异巨大。首先,不要指望写一段sql,既可以在oracle下运行、也可以在mysql下运行。原始的sql语句以及执行计划如下:
INSERT INTO C3(
tenantid,c_code,l_serialno,c_txtfundcode,
c_chargetype,f_sharemin,f_sharemax,l_hold,c_txtothercode,
c_targetchargetype,c_custtype,c_flag,d_operatedate,d_cdate,c_cyno)
SELECT a.tenantid,a.c_code,l_serialno,
CASE a.agencytypes WHEN 'AB' THEN a.c_prdcode ELSE COALESCE(b.c_outprdcode,a.c_prdcode) END c_txtfundcode,
c_chargetype,f_sharemin,f_sharemax,l_hold,
CASE a.agencytypes WHEN 'AB'THEN a.c_othercode ELSE COALESCE(c.c_outprdcode,a.c_othercode) END c_txtothercode,
c_targetchargetype,c_custtype,c_flag,d_operatedate,20100511 d_cdate,a.c_cyno
FROM (SELECT 0 l_serialno,
CASE t.c_mutextype WHEN 'A' THEN '' WHEN 'B' THEN '' WHEN 'C' THEN '' ELSE t.c_mutextype END c_chargetype,
CASE t.c_targetsharetype WHEN 'A' THEN '' WHEN 'B' THEN '' WHEN 'C' THEN '' ELSE t.c_targetsharetype END c_targetchargetype,
ar.f_cminmutex f_sharemin,99999999999999.9 f_sharemax,0 l_hold,'' c_custtype,
'' c_flag,'' d_operatedate,
t.*
FROM (SELECT fo.tenantid, fo.c_code, fo.c_prdcode,fi.c_prdcode c_othercode,
fo.c_cyno,fo.c_mutextype,fi.c_mutextype c_targetsharetype,
fo.d_contractdate d_contractdate, fo.c_mutextypes c_mutextypes,
fo.agencytypes,
fi.d_contractdate d_othercontractdate, fi.c_mutextypes c_othersharetypes
FROM (SELECT DISTINCT ss.tenantid, ss.c_code, ss.c_prdcode,
ss.c_cyno,ss.c_mutextype c_mutextype,
ta.c_mutextypes agencytypes,
getsysvalue(ss.tenantid, ss.c_code, ss.c_cyno,ss.c_managercode, ss.c_prdcode,'ContractDate', '') d_contractdate,
getsysvalue(ss.tenantid, ss.c_code, ss.c_cyno,ss.c_managercode, ss.c_prdcode,'ShareTypes', '') c_mutextypes
FROM (SELECT fi.tenantid, fi.c_code, fi.c_prdcode,c.c_cyno,
s.c_mutextype, fi.c_managercode
FROM FUNDINFO fi,
(SELECT 'A' c_mutextype FROM DUAL
UNION ALL
SELECT 'B' c_mutextype FROM DUAL
UNION ALL
SELECT 'C' c_mutextype FROM DUAL) s,
QUALIFY c,
EXPBATCH d
WHERE fi.c_code = 'F6'
AND fi.tenantid = '*'
AND fi.c_fundstatus NOT IN ('', '')
AND c.c_code = 'F6'
AND c.tenantid = '*'
AND c.c_cyno = d.c_cyno
AND c.c_code = d.c_code
AND c.tenantid = d.tenantid
AND INSTR(fi.c_mutextypes, s.c_mutextype) > 0
AND (fi.c_fundtype<>''
OR
NOT EXISTS(SELECT 1 FROM TEXT_PARAMETER
WHERE c_paramitem = 'ChangeLimit'
AND c_paramvalue = ''
AND c_prdcode = fi.c_prdcode
AND c_code = 'F6'
AND tenantid = '*'))
AND fi.c_prdcode = c.c_prdcode
AND c.c_issaleflag = ''
) ss,
EXPBATCH ta
WHERE ss.c_cyno = ta.c_cyno
AND ss.c_code = ta.c_code
AND ss.tenantid = ta.tenantid
AND ta.c_notexpparamfiles = ''
) fo,
(SELECT DISTINCT ss.tenantid, ss.c_code, ss.c_prdcode,
ss.c_cyno,ss.c_mutextype c_mutextype,
getsysvalue(ss.tenantid, ss.c_code, ss.c_cyno,ss.c_managercode, ss.c_prdcode,'ContractDate', 20991231) d_contractdate,
getsysvalue(ss.tenantid, ss.c_code, ss.c_cyno,ss.c_managercode, ss.c_prdcode,'ShareTypes', '') c_mutextypes
FROM (SELECT fi.tenantid, fi.c_code, fi.c_prdcode,
c.c_cyno, s.c_mutextype, fi.c_managercode
FROM FUNDINFO fi,
(SELECT 'A' c_mutextype FROM DUAL
UNION ALL
SELECT 'B' c_mutextype FROM DUAL
UNION ALL
SELECT 'C' c_mutextype FROM DUAL) s,
QUALIFY c,
EXPBATCH d
WHERE fi.c_code = 'F6'
AND fi.tenantid = '*'
AND c.c_code = 'F6'
AND c.tenantid = '*'
AND c.c_cyno = d.c_cyno
AND c.c_code = d.c_code
AND c.tenantid = d.tenantid
AND INSTR(fi.c_mutextypes, s.c_mutextype) > 0
AND fi.c_fundstatus NOT IN ('', '')
AND (fi.c_fundtype <> ''
OR NOT EXISTS
(SELECT 1 FROM TEXT_PARAMETER
WHERE c_paramitem = 'ChangeLimit'
AND c_paramvalue = ''
AND c_prdcode = fi.c_prdcode
AND c_code = 'F6'
AND tenantid = '*'))
AND fi.c_prdcode = c.c_prdcode
AND c.c_issaleflag = ''
) ss,
EXPBATCH ta
WHERE ss.c_cyno = ta.c_cyno
AND ss.c_code = ta.c_code
AND ss.tenantid = ta.tenantid
AND ta.c_notexpparamfiles = ''
) fi
WHERE fo.c_prdcode <> fi.c_prdcode
AND fo.c_mutextype = fi.c_mutextype
AND fo.c_cyno = fi.c_cyno
) t,(SELECT c_prdcode, c_cyno, MIN(a.f_cminmutex) f_cminmutex
FROM ARLIMIT a
WHERE c_cyno <> '*'
AND c_code = 'F6'
AND tenantid = '*'
GROUP BY c_prdcode, c_cyno
UNION ALL
SELECT c_prdcode, b.c_cyno, MIN(f_cminmutex) f_cminmutex
FROM ARLIMIT a, EXPBATCH b
WHERE a.c_cyno = '*'
AND a.c_code = 'F6'
AND a.tenantid = '*'
AND a.c_code = b.c_code
AND a.tenantid = b.tenantid
AND not exists (SELECT 1
FROM ARLIMIT c
WHERE b.c_cyno = c.c_cyno
AND a.c_prdcode = c.c_prdcode
AND a.c_code = c.c_code
AND a.tenantid = c.tenantid)
GROUP BY c_prdcode, b.c_cyno) ar
WHERE t.d_contractdate <= 20100511
AND t.d_othercontractdate <= 20100511
AND INSTR(t.c_mutextypes, t.c_mutextype) > 0
AND INSTR(t.c_othersharetypes, t.c_targetsharetype) > 0
AND t.c_prdcode = ar.c_prdcode
AND t.c_cyno = ar.c_cyno
AND NOT EXISTS
(SELECT 1
FROM CHANGELIMIT b
WHERE t.c_prdcode = b.c_prdcode
AND (t.c_mutextype = b.c_mutextype OR b.c_mutextype = '*')
AND (t.c_cyno = b.c_cyno OR b.c_cyno = '*')
AND (t.c_othercode = b.c_othercode OR b.c_othercode = '*')
AND (t.c_targetsharetype = b.c_othershare OR b.c_othershare = '*')
)
) a
LEFT JOIN FUNDCODECHANGE b
ON (a.c_prdcode = b.c_prdcode
AND a.c_mutextype = b.c_mutextype
AND a.c_code = b.c_code
AND a.tenantid = b.tenantid)
LEFT JOIN FUNDCODECHANGE c
ON (a.c_othercode = c.c_prdcode
AND a.c_targetsharetype = c.c_mutextype
AND a.c_code = c.c_code
AND a.tenantid = c.tenantid)
-- 此处隐藏了谓词部分
Plan Hash Value : 4256998962 --------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost | Time |
--------------------------------------------------------------------------------------------------------------------------
| 0 | INSERT STATEMENT | | 1 | 129 | 2103 | 00:00:26 |
| 1 | LOAD TABLE CONVENTIONAL | C3 | | | | |
| 2 | NESTED LOOPS OUTER | | 1 | 129 | 2103 | 00:00:26 |
| 3 | VIEW | | 1 | 95 | 2102 | 00:00:26 |
| * 4 | FILTER | | | | | |
| * 5 | HASH JOIN | | 1 | 8105 | 2101 | 00:00:26 |
| * 6 | HASH JOIN | | 1 | 8078 | 1827 | 00:00:22 |
| 7 | NESTED LOOPS OUTER | | 1 | 4060 | 914 | 00:00:11 |
| 8 | VIEW | | 1 | 4026 | 913 | 00:00:11 |
| 9 | SORT UNIQUE | | 1 | 72 | 913 | 00:00:11 |
| * 10 | FILTER | | | | | |
| 11 | NESTED LOOPS | | 1 | 72 | 912 | 00:00:11 |
| 12 | NESTED LOOPS | | 1 | 72 | 912 | 00:00:11 |
| 13 | NESTED LOOPS | | 1 | 58 | 911 | 00:00:11 |
| 14 | NESTED LOOPS | | 1 | 49 | 910 | 00:00:11 |
| 15 | NESTED LOOPS | | 1500 | 46500 | 309 | 00:00:04 |
| 16 | VIEW | | 3 | 9 | 6 | 00:00:01 |
| 17 | UNION-ALL | | | | | |
| 18 | FAST DUAL | | 1 | | 2 | 00:00:01 |
| 19 | FAST DUAL | | 1 | | 2 | 00:00:01 |
| 20 | FAST DUAL | | 1 | | 2 | 00:00:01 |
| * 21 | TABLE ACCESS FULL | FUNDINFO | 500 | 14000 | 101 | 00:00:02 |
| * 22 | TABLE ACCESS BY INDEX ROWID | QUALIFY | 1 | 18 | 1 | 00:00:01 |
| * 23 | INDEX RANGE SCAN | UIDX_QUALIFY | 1 | | 1 | 00:00:01 |
| * 24 | INDEX RANGE SCAN | PK_BATCH | 1 | 9 | 1 | 00:00:01 |
| * 25 | INDEX RANGE SCAN | PK_EXPBATCH | 1 | | 1 | 00:00:01 |
| * 26 | TABLE ACCESS BY INDEX ROWID | EXPBATCH | 1 | 14 | 1 | 00:00:01 |
| * 27 | INDEX RANGE SCAN | IDX_TEXTPARAMETER_VALUE | 1 | 30 | 1 | 00:00:01 |
| * 28 | TABLE ACCESS BY INDEX ROWID | FUNDCODECHANGE | 1 | 34 | 1 | 00:00:01 |
| * 29 | INDEX UNIQUE SCAN | PK_FUNDCODECHANGE | 1 | | 1 | 00:00:01 |
| 30 | VIEW | | 1 | 4018 | 913 | 00:00:11 |
| 31 | SORT UNIQUE | | 1 | 69 | 913 | 00:00:11 |
| * 32 | FILTER | | | | | |
| 33 | NESTED LOOPS | | 1 | 69 | 912 | 00:00:11 |
| 34 | NESTED LOOPS | | 1 | 69 | 912 | 00:00:11 |
| 35 | NESTED LOOPS | | 1 | 58 | 911 | 00:00:11 |
| 36 | NESTED LOOPS | | 1 | 49 | 910 | 00:00:11 |
| 37 | NESTED LOOPS | | 1500 | 46500 | 309 | 00:00:04 |
| 38 | VIEW | | 3 | 9 | 6 | 00:00:01 |
| 39 | UNION-ALL | | | | | |
| 40 | FAST DUAL | | 1 | | 2 | 00:00:01 |
| 41 | FAST DUAL | | 1 | | 2 | 00:00:01 |
| 42 | FAST DUAL | | 1 | | 2 | 00:00:01 |
| * 43 | TABLE ACCESS FULL | FUNDINFO | 500 | 14000 | 101 | 00:00:02 |
| * 44 | TABLE ACCESS BY INDEX ROWID | QUALIFY | 1 | 18 | 1 | 00:00:01 |
| * 45 | INDEX RANGE SCAN | UIDX_QUALIFY | 1 | | 1 | 00:00:01 |
| * 46 | INDEX RANGE SCAN | PK_EXPBATCH | 1 | 9 | 1 | 00:00:01 |
| * 47 | INDEX RANGE SCAN | PK_EXPBATCH | 1 | | 1 | 00:00:01 |
| * 48 | TABLE ACCESS BY INDEX ROWID | EXPBATCH | 1 | 11 | 1 | 00:00:01 |
| * 49 | INDEX RANGE SCAN | IDX_TEXTPARAMETER_VALUE | 1 | 30 | 1 | 00:00:01 |
| 50 | VIEW | | 7073 | 190971 | 274 | 00:00:04 |
| 51 | UNION-ALL | | | | | |
| 52 | SORT GROUP BY | | 1 | 16 | 20 | 00:00:01 |
| 53 | TABLE ACCESS BY INDEX ROWID | ARLIMIT | 1 | 16 | 20 | 00:00:01 |
| * 54 | INDEX FULL SCAN | UIDX_ARLIMIT | 1 | | 20 | 00:00:01 |
| 55 | SORT GROUP BY | | 7072 | 275808 | 254 | 00:00:04 |
| * 56 | HASH JOIN RIGHT ANTI | | 2970075 | 115832925 | 175 | 00:00:03 |
| * 57 | INDEX FULL SCAN | UIDX_ARLIMIT | 30000 | 420000 | 20 | 00:00:01 |
| * 58 | HASH JOIN | | 2970075 | 74251875 | 146 | 00:00:02 |
| * 59 | INDEX FULL SCAN | PK_EXPBATCH | 99 | 891 | 1 | 00:00:01 |
| * 60 | TABLE ACCESS FULL | ARLIMIT | 30000 | 480000 | 137 | 00:00:02 |
| * 61 | TABLE ACCESS BY INDEX ROWID | CHANGELIMIT | 1 | 28 | 1 | 00:00:01 |
| * 62 | INDEX RANGE SCAN | IDX_CHANGELIMIT_FUNDCODE | 90 | | 1 | 00:00:01 |
| * 63 | TABLE ACCESS BY INDEX ROWID | FUNDCODECHANGE | 1 | 34 | 1 | 00:00:01 |
| * 64 | INDEX UNIQUE SCAN | PK_FUNDCODECHANGE | 1 | | 1 | 00:00:01 |
--------------------------------------------------------------------------------------------------------------------------
这里不会讲基础优化,比如什么时候用hash join,什么时候nl,lio怎么看,access method,join method,fiter,predicate等基础优化知识。
在某些情况下,查询有left join时,使用了parallel会导致查询一直出不来,不用parallel反而立刻可以出来。
在很多场景中,parallel提升性能很有限、甚至降低了性能以及并行执行中的buffer sort。在并行的执行计划中,我们可以看到有一步是buffer sort,而且这一步占据了挺长的时间,buffer sort实际上没有排序,只是把数据加载到内存,不扫描多次表。通常在并行执行中出现这个操作。parallel为什么会性能提升有限呢,这其实涉及到oracle内部的算法是尽可能大部分场景最优化,这就会导致对于我们知道有规律的关联消除并没有被按预期消除,比如说在我们的这个优化中,每个管理人只有1w支产品,不同管理人之间是无法转换的,但是oracle不知道,即使我们采用hash分区,且在管理人字段,设置最多100个分区(读者肯定会问,为什么要使用hash分区而不是list呢?因为这里的管理人数量是不固定的,而我们使用的是oracle 11.2,如果是12c,就不存在这个问题了,因为12c支持了自动分区,见oracle 12cR1&12cR2核心高实用性新特性),也并不是每个分区一个管理人,很多分区没有数据,所以导致分区间很不均衡,采用并行执行的时候,因为很不均衡,导致执行计划倾斜严重,可能高达40%。同时因为统计信息不一定准确,可能会导致某些时候应该px send hash的成了px send broadcast,这虽然可以通过pq_distriubte hint强制,但是由于优化器会在hint基础上进一步进行查询转换(尤其涉及到子查询套子查询的时候),也可能会导致非预期的情况。实际上,对于超过三五个表以上复杂的sql,parallel效果就不佳的,这种情况,其实应该是应用里面发起多线程并行请求,采用fork-join模式来达到并行执行的效果。这一点只有掌握具体数据库比如oracle/mysql优化原理(oracle做得到的mysql不一定做得到,反过来一般不成立)和实现的架构师做得到。最后,笔者会讲到,本例是应该在设计上进行优化而不是单独的oracle和sql优化的。
- 执行计划相同,select很快,insert select很慢。比如帖子https://bbs.csdn.net/topics/370166028提到问题。对于结果记录成千上万的查询,需要知道select只是fetch了前面几行(即使优化器模式是all_rows),fetch也是要消耗lio的,所以如果不想insert 验证下大概时间,至少需要select count(1) from (select /*+ no_merge*/ from ...),这样才能得到相对比较合理的值(这个值可能和实际insert相差50%-100%之间,主要视数据量以及磁盘的速度而定)。有时候可能count(1)也很快,insert就很慢,执行计划又是完全相同的,这该怎么办呢,结果数据量也不大,也就两三百万而已???还没细看,最近真遇到这个例子了,
- oracle insert select和select执行计划不同。参考insert select和select执行计划不同。
- 主查询中某子查询的执行计划和子查询独立执行的执行计划不同。很有可能在子查询独立执行的时候,表之间的关联采用了hash join,作为主查询子句的时候,就是nl了,也有可能hash group by 变成了sort group by。这一点可以考虑使用with子句+materialize或者no_merge以及其他hint来控制住。
- 多with子句,只有第一个被物化为临时表。以前没注意,这次发现有多个with的时候,只有第一个被物化,后面的都没有被物化,虽然都加上了/*+ materialize */提示。如果实在无法控制执行计划,就考虑创建个临时表吧(可惜oracle 12c之前,gtt和常规表一样会产生大量的undo,oracle 12c引入了临时undo表空间,可以极大的规避redo/undo的生成)。测试可见http://blog.itpub.net/7199859/viewspace-1150868/。
- not exist中有and导致优化器选择了filter。filter从实现上跟nl差不多,对于主查询成千上万的查询,很可能一个filter就查询不出来或者严重影响性能。通常not exist中会出现类似下列的语句:
and not exists (select /*+ qb_name(inn)*/* from inner_table inn where (inn.status = outer_table.status or inn.status = '1') and xxx)
对于这种情况,anti join就失效了,虽然可以让主查询使用nl加上/*+ push_subq(@inn) */来pushdown查询条件,以避免主查询使用hash join产生巨量中间结果,但是nl对于大表性能极为低下。此时可以考虑将not exists拆分为如下:
and not exists (select * from inner_table inn where (inn.status = '1') and xxx)
and not exists (select * from inner_table inn where (inn.status = outer_table.status or inn.status = '1') and xxx)
此时可能就可以做到第一个not exists采用hash anti过滤掉大部分最终结果不需要的数据集。
- exist中有or导致优化器选择了filter。对于exists,通常情况如下:
and exists (outer_table.status = '1' or select 1 from another_table x where x.type = outer_table.type and ... )
对于这类查询,可以考虑使用union实现,但是有些时候,union并不见得合适,比如说查询上使用了分析函数就不合适了。此时就需要考虑其他方法(因为在我们的另一个sql中,结果集还不算大,所以也就没有进一步优化)。
- 在java/c++中运行很慢,拷贝到pl/sql dev中执行就很快。其实了解oracle/mysql优化器原理的都知道绑定变量的概念,所以这就不足为奇了,要在pl/sql dev中完全模拟代码中的行为,要么使用sql*plus的绑定变量,要么放到存储过程(pl/sql默认绑定变量,除非使用execute immediate)中执行,就模拟了在代码中的行为。
- hash group by vs sort group by。hash group by 与 sort group by的区别,可以参考http://www.itpub.net/thread-1813825-1-1.html,要强制指定使用hash group by,可以使用
/*+ NO_USE_HASH_AGGREGATION */提示。 - SQL中调用了自定义函数时性能低下之。在sql语句中调用自定义函数是一大禁忌,内置函数之所以几乎感觉不大太大的性能,是因为内置函数比如upper/lower都是确定性函数,也就是对于相同输入、总是产生相同输出,实际上在一个sql语句中,我们调用自定义函数的时候,做的通常都是类似参数/翻译相关的功能,由于涉及到多个级别的优先级问题,所以一个sql语句实现较为复杂,所以在这个sql执行期间,通常不会是相同的输入、产生不同的输出,此时将自定义函数设置为DETERMINISTIC,在某些情况下,可以极大的提升性能(视在这个SQL执行期间,有多少比例的重复输入而定)。但是,如果几乎没有重复的输入,此时硬是将exists/not exists改为DETERMINISTIC自定义函数,将是悲剧。。
- pga优化。workarea_size_policy模式下主要是pga_aggregate_target、_smm_px_max_size、_smm_max_size、_pga_max_size这四个参数,确定pga是否足够只要查询v$sql_plan_statistics_all,查看ONEPASS_EXECUTIONS、MULTIPASSES_EXECUTIONS、LAST_TEMPSEG_SIZE、MAX_TEMPSEG_SIZE这4个字段,只要MULTIPASSES_EXECUTIONS、LAST_TEMPSEG_SIZE、MAX_TEMPSEG_SIZE都为空或者0就可以保证pga足够。
- $session.event监控并优化服务器配置。当运行时间比较长的时候,我们需要查询下v$session看下该进程当前在等待什么事件,根据此进一步确定是终止执行还是查看os的当前情况。
- v$session_longops。对于并行执行(非并行执行不会体现),可以通过该视图预估语句还需要执行多久,一般来说还是比较可靠的。
- sar -d -p 5 10000。可以监控各个磁盘的饱和度情况,如下:
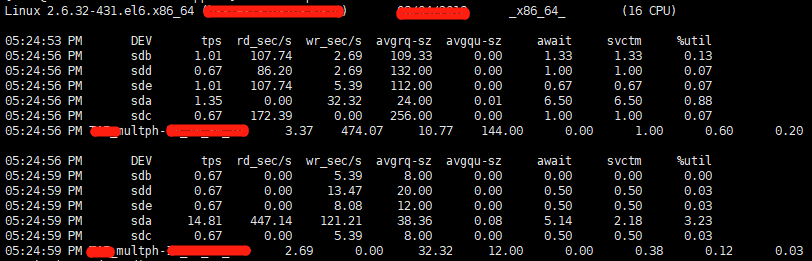
%util 90%以上就说明当前磁盘太忙,要么布局不合理,要么太慢了。
- 问题很有可能在应用架构设计上,这事情已经超出了oracle的范围。分而治之不是数据库自身擅长的,这属于应用设计的一部分,虽然类似分区、parallel算是分而自治的理念,但是它毕竟不知道业务上下文的特殊性,所以,对于这个sql,应该在SQL优化的基础上,5或者10或者20个管理人作为条件,开管理人总数/每次处理的管理人作为线程数,采用fork-join模式实现,无论应用层是java还是c++都可以较为简单的实现,三五分钟完全是可以实现的(181114,我们最近将mysql版本进行了应用架构层的优化,将执行时间从27分钟降低到了8分钟,跑的比oracle还快)。
- 对于复杂的sql,建议加上/*+ gather_plan_statistics */提示以便在v$sql_plan_statistics_all中收集实际的逻辑读、物理读、基数等值,以便进一步优化执行计划。
oracle 11g亿级复杂SQL优化一例(数量级性能提升)的更多相关文章
- oracle 11g杀掉锁的sql
oracle 11g杀掉锁的sql [引用 2013-3-6 17:19:12] 字号:大 中 小 --查询出出现锁的session_idselect session_id from v$lo ...
- 安装ORACLE 11g 64位 pl/sql无法进入的问题。
转载自网上的内容: 1)安装Oracle 11g 64位 2)安装32位的Oracle客户端( instantclient-basic-win32-11.2.0.1.0)下载地址:http://www ...
- 【数据库】百万级数据库SQL优化大总结
网上关于SQL优化的教程很多,但是比较杂乱.近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充. 这篇文章我花费了大量的时间查找资料.修改.排版,希望大家阅读之后,感觉 ...
- 百万级数据库SQL优化大总结
网上关于SQL优化的教程很多,但是比较杂乱.近日有空整理了一下,写出来跟大家分享一下,其中有错误和不足的地方,还请大家纠正补充. 这篇文章我花费了大量的时间查找资料.修改.排版,希望大家阅读之后,感觉 ...
- 树形查询SQL优化一例
上周五一哥们发了条SQL,让我看看,代码如下: SELECT COUNT(1) FROM (select m.sheet_id from cpm_main_sheet_history m, cpm_s ...
- ORACLE 11G在相同的linuxserver从实施例1满库到实例2上
早期的导出命令: [root@powerlong4 ~]# su - oracle [oracle@powerlong4 ~]$ export ORACLE_SID=pt1; [oracle@powe ...
- 有史以来性价比最高最让人感动的一次数据库&SQL优化(DB & SQL TUNING)——半小时性能提升千倍
昨天,一个客户现场人员急急忙忙打电话找我,说需要帮忙调优系统,因为经常给他们干活,所以,也就没多说什么,先了解情况,据他们说,就是他们的系统最近才出现了明显的反应迟钝问题,他们的那个系统我很了解,软硬 ...
- SQL Server 2014里的性能提升
在这篇文章里我想小结下SQL Server 2014引入各种惊艳性能提升!! 缓存池扩展(Buffer Pool Extensions) 缓存池扩展的想法非常简单:把页文件存储在非常快的存储上,例如S ...
- 腾讯 TKE 厉害了!用 eBPF绕过 conntrack 优化K8s Service,性能提升40%
Kubernetes Service[1] 用于实现集群中业务之间的互相调用和负载均衡,目前社区的实现主要有userspace,iptables和IPVS三种模式.IPVS模式的性能最好,但依然有优化 ...
随机推荐
- [LeetCode] 693. Binary Number with Alternating Bits_Easy
Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will a ...
- jupyter 快捷键
Jupyter Notebook 的快捷键 Jupyter Notebook 有两种键盘输入模式.编辑模式,允许你往单元中键入代码或文本:这时的单元框线是绿色的.命令模式,键盘输入运行程序命令:这时的 ...
- mac console color setting
1. 编辑文件 ~/.bash_profile 添加 export CLICOLOR=1 export LSCOLORS=GxFxCxDxBxegedabagaced 2. 加载生效 source ~ ...
- 47.HTML---frame,iframe,frameset之间的关系与区别
iframe 是在html页面内嵌入框架 框架内可以连接另一个页面, 如 <html> <head></head> <body> <iframe ...
- lsof命令简介
lsof命令简介: lsof(list open files)是一个列出当前系统打开文件的工具.在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件 ...
- CSS background-image背景图片相关介绍
这里将会介绍如何通过background-image设置背景图片,以及背景图片的平铺.拉伸.偏移.设置大小等操作. 1. 背景图片样式分类 CSS中设置元素背景图片及其背景图片样式的属性主要以下几个: ...
- 如何用vue组件做个机器人?有趣味的代码
<!DOCTYPE html> <html lang="en"> <div> <meta charset="UTF- ...
- report源码分析——report_object和report_message
uvm的report机制,主要涉及uvm_report_object,uvm_report_handle,uvm_report_server这三个类: uvm_report_object主要是提供uv ...
- python遍历某一位置所有文件夹中的文件
通过多次遍历达到找出所有文件的目的 import os rootdir=["d:/77"] c=[] for i in rootdir: for parent,dirnames,f ...
- 【2017-2-23】C#switch case分支语句,for循环语句
switch case分支语句 switch(一个变量值) { case 值:要执行的代码段;break; case 值:要执行的代码段;break; … default:代码段;break;(def ...