fasttext与Linear SVC 分类测试结果
任务:分类出优质问题与非优质问题。
任务背景:用户实际与智能客服交互的时候,如果只做阈值限制,在相似问题匹配的时候(由于词的重复),依然会匹配出部分结果。如:问题为 "设置好了?", "可以操作?",
并不属于优质问题,但是却因为跟库里的问题有一定的相似度,所以依然会返回问题list。所以我们需要训练一个分类器,作为非优质问题的另外一个判断依据。并且后续,该分类器也可用于意图识别。 样本:
正类POS:为 既往的所有已标注的问题 + 去除停用词的既往的所有已标注的问题
之所以增加去除停用词的部分,是因为用户可能会简略的问,“优惠券?”,或者“优惠券设置?”,而不会完整的问“优惠券怎么设置?”,而库里的问题都是非常完整的,所以增加去除停用词的版本,进行训练。 负类NEG:为 SELECT content FROM kfmessage WHERE char_length(content)<6 and char_length(content)>2
之所以选择这个长度的样本,是因为,大部分不优质的问题,都在这个长度区间,这样选取出来的样本90%以上,即便不标注,都是确实是非优质问题,而我也另外导出了一部分给文其标注。 样本分词使用HMM=False, is_ignore_words=False 模型选择:
在有限的时间和人力下,只做一个baseline,要求训练快、易于调整、准确率95左右。
因为本次任务只是二分类,任务简单,且每个分类之间,有很明显的区别,所以经验上觉得使用传统的机器学习方法,或者浅层神经网络应该可以达到。
有以下几个可选
sklearn 库里现成的Linear SVC, Bayes
facebook 2016年开源 fasttext
深度学习(备选):
textCNN, 双向LSTM 测试结果:
Linear SVC:
self.train_vector = SelectKBest(chi2, k=4000).fit_transform(train_vector, self.training_tags) self.classifier = LinearSVC(C=1.0, loss='squared_hinge', penalty='l2')
分类器参数基本猜用默认参数,特征使用卡方检验选取4000个特征,10折的交叉检验结果如下
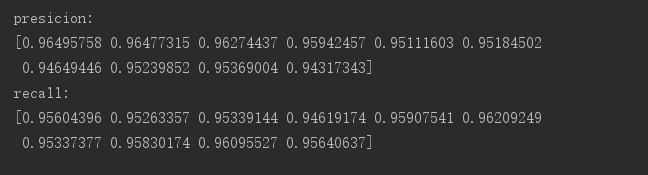
fasttext:
参数如下
classifier = fasttext.supervised(input_file = './data/binary_svc_train/fasttext/training1.txt',
output = './data/binary_svc_train/fasttext/model',
word_ngrams = 2, #n-gram
ws = 2, #windows
bucket = 20000, #bucket 用来存放ngram,如果不设置,在windows里会出现内存错误。其大小一般取决于N-gram的数量,数量少会出现两个Ngram共享一个向量
epoch = 10, #epoch
lr=0.05 # learn rate
) 10折,两次交叉验证的平均准确率,召回率:

注意:
1、fasttext原版在windoes下是无法运行的,需要使用另外一个版本,下载之后pip install . 进行安装。
地址:https://github.com/salestock/fastText.py
2、需要cython, pip install cython
3、需要visual C++ 14.0
地址:https://visualstudio.microsoft.com/zh-hans/thank-you-downloading-visual-studio/?sku=Community&rel=15
4、使用的时候,记得加bucket参数, 否则在windoes下会报错。
结果:
经过测试,还是fasttext略高一点,实际当中,也使用这个。
在判定非优质问题的时候,除了使用fasttext,还有相似度最高的检验,如果一个问题,返回的相似度列表TOP1的similarity > 阈值,则我们依然会返回列表,避免了少数情况,比如“优惠券”这种,虽然不是完整的问题,
却依然应该返回问题列表的情况。
fasttext与Linear SVC 分类测试结果的更多相关文章
- 无所不能的Embedding 2. FastText词向量&文本分类
Fasttext是FaceBook开源的文本分类和词向量训练库.最初看其他教程看的我十分迷惑,咋的一会ngram是字符一会ngram又变成了单词,最后发现其实是两个模型,一个是文本分类模型[Ref2] ...
- caffe搭建--WINDOWS+VS2013下生成caffe并进行cifar10分类测试
http://blog.csdn.net/naaaa/article/details/52118437 标签: windowsvs2013caffecifar10 2016-08-04 15:33 1 ...
- 文本分类需要CNN?No!fastText完美解决你的需求(后篇)
http://blog.csdn.net/weixin_36604953/article/details/78324834 想必通过前一篇的介绍,各位小主已经对word2vec以及CBOW和Skip- ...
- 超快的 FastText
Word2Vec 作者.脸书科学家 Mikolov 文本分类新作 fastText:方法简单,号称并不需要深度学习那样几小时或者几天的训练时间,在普通 CPU 上最快几十秒就可以训练模型,得到不错的结 ...
- NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类(paper: ...
- 文本分类学习 (十)构造机器学习Libsvm 的C# wrapper(调用c/c++动态链接库)
前言: 对于SVM的了解,看前辈写的博客加上读论文对于SVM的皮毛知识总算有点了解,比如线性分类器,和求凸二次规划中用到的高等数学知识.然而SVM最核心的地方应该在于核函数和求关于α函数的极值的方法: ...
- 转:fastText原理及实践(达观数据王江)
http://www.52nlp.cn/fasttext 1条回复 本文首先会介绍一些预备知识,比如softmax.ngram等,然后简单介绍word2vec原理,之后来讲解fastText的原理,并 ...
- fasttext(1) -- 认识 fasttext 和 初步使用
fastText 的 Python接口:https://github.com/salestock/fastText.py (1) fasttext 简介:FastText是Facebook开发的一款快 ...
- 一个使用fasttext训练的新闻文本分类器/模型
fastext是什么? Facebook AI Research Lab 发布的一个用于快速进行文本分类和单词表示的库.优点是很快,可以进行分钟级训练,这意味着你可以在几分钟时间内就训练好一个分类模型 ...
随机推荐
- collections模块和os模块
collections模块 在内置数据类型(dict.list.set.tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter.deque.defaultdict. ...
- 智能文件选择列表—— bat 批处理
智能文件选择列表 *.wim @echo off setlocal enabledelayedexpansion title 智能文件选择列表 pushd %~dp0 & cd /d %~dp ...
- Cobbler 登录web界面提示报错“Internal Server Error”解决办法
Cobbler登录web页面报错 查看httpd日志/etc/httpd/logs/ssl_error_log 查看cobbler的py配置文件 sed -n '38,41p' /usr/share/ ...
- 温故KMP算法
最近由于某些原因,又回顾了一次KMP算法.上一次回顾KMP算法还是在刷题的时候遇到的: http://blog.csdn.net/dacc123/article/details/50994611 在我 ...
- RPC框架-通俗易懂的解释
早期单机时代,一台电脑上运行多个进程,大家各干各的,老死不相往来.假如A进程需要一个画图的功能,B进程也需要一个画图的功能,程序员就必须为两个进程都写一个画图的功能.这不是整人么?于是就出现了IPC( ...
- 一窥Spring Cloud Eureka
在Spring Cloud中Eureka负责服务发现功能.服务发现需要解决如何找到服务提供者在网络中位置的问题. 服务端 在Spring Tool Suite的文件菜单中,点击新建Spring Sta ...
- vins-mono代码解读
系统框架介绍 1. Measurement Preprocessing(观测预处理):对图像提feature做feature tracking,输出tracked feature list, 对IMU ...
- Arrays 类的一些常见用法
package cn.ljs; import java.util.Arrays; public class ArrayDemo { public static void main(String [] ...
- 1.7Oob 成员变量可以不初始化 但局部变量必须初始化
成员变量有默认的初始值 像int a; a默认为0:而局部变量没有初始值
- c#如何调用另外一个项目的类
添加引用即可. 参考资料: https://zhidao.baidu.com/question/241402877.html http://blog.csdn.net/a1027/article/de ...