【转】基于keras 的神经网络股价预测模型
from matplotlib.dates import DateFormatter, WeekdayLocator, DayLocator, MONDAY,YEARLY
from matplotlib.finance import quotes_historical_yahoo_ohlc, candlestick_ohlc
#import matplotlib
import tushare as ts
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pylab import date2num
import datetime
import numpy as np
from pandas import DataFrame
from numpy import row_stack,column_stack df=ts.get_hist_data('',start='2016-06-15',end='2017-11-06')
dd=df[['open','high','low','close']] #print(dd.values.shape[0]) dd1=dd .sort_index() dd2=dd1.values.flatten() g1=dd2[::-1] g2=g1[0:120] g3=g2[::-1] gg=DataFrame(g3) gg.T.to_excel('gg.xls') #dd3=pd.DataFrame(dd2)
#dd3.T.to_excel('d8.xls') g=dd2[0:140]
for i in range(dd.values.shape[0]-34): s=dd2[i*4:i*4+140]
g=row_stack((g,s)) fg=DataFrame(g) print(fg)
fg.to_excel('fg.xls') #-*- coding: utf-8 -*-
#建立、训练多层神经网络,并完成模型的检验
#from __future__ import print_function
import pandas as pd inputfile1='fg.xls' #训练数据
testoutputfile = 'test_output_data.xls' #测试数据模型输出文件
data_train = pd.read_excel(inputfile1) #读入训练数据(由日志标记事件是否为洗浴)
data_mean = data_train.mean()
data_std = data_train.std()
data_train1 = (data_train-data_mean)/5 #数据标准化 y_train = data_train1.iloc[:,120:140].as_matrix() #训练样本标签列
x_train = data_train1.iloc[:,0:120].as_matrix() #训练样本特征
#y_test = data_test.iloc[:,4].as_matrix() #测试样本标签列 from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation model = Sequential() #建立模型
model.add(Dense(input_dim = 120, output_dim = 240)) #添加输入层、隐藏层的连接
model.add(Activation('relu')) #以Relu函数为激活函数
model.add(Dense(input_dim = 240, output_dim = 120)) #添加隐藏层、隐藏层的连接
model.add(Activation('relu')) #以Relu函数为激活函数
model.add(Dense(input_dim = 120, output_dim = 120)) #添加隐藏层、隐藏层的连接
model.add(Activation('relu')) #以Relu函数为激活函数
model.add(Dense(input_dim = 120, output_dim = 20)) #添加隐藏层、输出层的连接
model.add(Activation('sigmoid')) #以sigmoid函数为激活函数
#编译模型,损失函数为binary_crossentropy,用adam法求解
model.compile(loss='mean_squared_error', optimizer='adam') model.fit(x_train, y_train, nb_epoch = 100, batch_size = 8) #训练模型
model.save_weights('net.model') #保存模型参数 inputfile2='gg.xls' #预测数据
pre = pd.read_excel(inputfile2) pre_mean = data_mean[0:120]
pre_std = pre.std()
pre1 = (pre-pre_mean)/5 #数据标准化 pre2 = pre1.iloc[:,0:120].as_matrix() #预测样本特征
r = pd.DataFrame(model.predict(pre2))
rt=r*5+data_mean[120:140].as_matrix()
print(rt.round(2)) rt.to_excel('rt.xls') #print(r.values@data_train.iloc[:,116:120].std().values+data_mean[116:120].as_matrix()) a=list(df.index[0:-1]) b=a[0] c= datetime.datetime.strptime(b,'%Y-%m-%d') d = date2num(c) c1=[d+i+1 for i in range(5)]
c2=np.array([c1]) r1=rt.values.flatten()
r2=r1[0:4]
for i in range(4): r3=r1[i*4+4:i*4+8]
r2=row_stack((r2,r3)) c3=column_stack((c2.T,r2))
r5=DataFrame(c3) if len(c3) == 0:
raise SystemExit fig, ax = plt.subplots()
fig.subplots_adjust(bottom=0.2) #ax.xaxis.set_major_locator(mondays)
#ax.xaxis.set_minor_locator(alldays)
#ax.xaxis.set_major_formatter(mondayFormatter)
#ax.xaxis.set_minor_formatter(dayFormatter) #plot_day_summary(ax, quotes, ticksize=3)
candlestick_ohlc(ax, c3, width=0.6, colorup='r', colordown='g') ax.xaxis_date()
ax.autoscale_view()
plt.setp(plt.gca().get_xticklabels(), rotation=45, horizontalalignment='right') ax.grid(True)
#plt.title('000002')
plt.show()
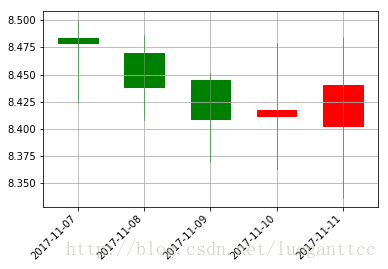
【转】基于keras 的神经网络股价预测模型的更多相关文章
- 基于 Keras 用 LSTM 网络做时间序列预测
目录 基于 Keras 用 LSTM 网络做时间序列预测 问题描述 长短记忆网络 LSTM 网络回归 LSTM 网络回归结合窗口法 基于时间步的 LSTM 网络回归 在批量训练之间保持 LSTM 的记 ...
- 基于双向BiLstm神经网络的中文分词详解及源码
基于双向BiLstm神经网络的中文分词详解及源码 基于双向BiLstm神经网络的中文分词详解及源码 1 标注序列 2 训练网络 3 Viterbi算法求解最优路径 4 keras代码讲解 最后 源代码 ...
- 基于 Keras 用深度学习预测时间序列
目录 基于 Keras 用深度学习预测时间序列 问题描述 多层感知机回归 多层感知机回归结合"窗口法" 改进方向 扩展阅读 本文主要参考了 Jason Brownlee 的博文 T ...
- 基于Keras 的VGG16神经网络模型的Mnist数据集识别并使用GPU加速
这段话放在前面:之前一种用的Pytorch,用着还挺爽,感觉挺方便的,但是在最近文献的时候,很多实验都是基于Google 的Keras的,所以抽空学了下Keras,学了之后才发现Keras相比Pyto ...
- 解析基于keras深度学习框架下yolov3的算法
一.前言 由于前一段时间以及实现了基于keras深度学习框架下yolov3的算法,本来想趁着余热将自己的心得体会进行总结,但由于前几天有点事就没有完成计划,现在趁午休时间整理一下. 二.Keras框架 ...
- keras搭建神经网络快速入门笔记
之前学习了tensorflow2.0的小伙伴可能会遇到一些问题,就是在读论文中的代码和一些实战项目往往使用keras+tensorflow1.0搭建, 所以本次和大家一起分享keras如何搭建神经网络 ...
- [AI开发]centOS7.5上基于keras/tensorflow深度学习环境搭建
这篇文章详细介绍在centOS7.5上搭建基于keras/tensorflow的深度学习环境,该环境可用于实际生产.本人现在非常熟练linux(Ubuntu/centOS/openSUSE).wind ...
- [深度应用]·首届中国心电智能大赛初赛开源Baseline(基于Keras val_acc: 0.88)
[深度应用]·首届中国心电智能大赛初赛开源Baseline(基于Keras val_acc: 0.88) 个人主页--> https://xiaosongshine.github.io/ 项目g ...
- CIKM 18 | 蚂蚁金服论文:基于异构图神经网络的恶意账户识别方法
小蚂蚁说: ACM CIKM 2018 全称是 The 27th ACM International Conference on Information and Knowledge Managemen ...
随机推荐
- 2018年3月最新的Ubuntu 16.04.4漏洞提权代码
2018年3月最新的Ubuntu 16.04.4漏洞提权代码,本代码取自Vitaly Nikolenko的推子 亲测阿里云提权可用. /* * Ubuntu 16.04.4 kernel priv e ...
- SQL语句报错,无法绑定由多个部分组成的标识符解决
无法绑定由多个部分组成的标识符, 表示在查询的时候使用了别名,并且查询的多个表中存在相同的字段,如果在使用该字段时不明确该字段的来源就会报这个错误. 举例: 我们有两张表,B1,B2,他们有一个共同的 ...
- Spring 消息
RMI.Hessian/Burlap的远程调用机制是同步的.当客户端调用远程方法时,客户端必须等到远程方法完成之后,才能继续执行.即使远程方法不向客户端返回任何消息,客户端也要被阻塞知道服务完成. 消 ...
- CentOS中yum安装ffmpeg
1.升级系统 sudo yum install epel-release -y sudo yum update -y sudo shutdown -r now 2.安装Nux Dextop Yum 源 ...
- make clean,make distclean与make depend的区别
make clean仅仅是清除之前编译的可执行文件及配置文件. 而make distclean要清除所有生成的文件. Makefile 在符合GNU Makefiel惯例的Makefile中,包含了一 ...
- ubuntu: firefox+flashplay
更新两步: 1.安装firefox:rm-->下载-->mv-->ln http://www.cnblogs.com/yzsatcnblogs/p/4266985.html 2. f ...
- DG备库,实时应用如何判断,MR进程,及MRP应用归档,三种情况的查询及验证
本篇文档学习,DG备库,实时应用如何判断,MR进程,及MRP应用归档,三种情况的查询及验证 1.取消MRP进程 备库查询进程状态select process,client_process,sequen ...
- leetcode 772.Basic Calculator III
这道题就可以结合Basic Calculator中的两种做法了,分别是括号运算和四则运算的,则使用stack作为保持的结果,而使用递归来处理括号内的值的. class Solution { publi ...
- 学号 20155219 《Java程序设计》第1周学习总结
学号 20155219 <Java程序设计>第1周学习总结 教材学习内容总结 JVM:是JAVA程序唯一认识的操作系统,其可执行文件为.class文档:具有让Java程序跨平台的功能.负责 ...
- 如何简单实用hammer
1,首先引用hammer在html中 <script src="js/jquery.hammer.js"></script> 2.在js中创建 ...