ML: 聚类算法R包-对比
测试验证环境
数据: 7w+ 条,数据结构如下图:
- > head(car.train)
- DV DC RV RC SOC HV LV HT LT Type TypeName
- 1 379 85.09 0.00 0.0 62.99 3.99 0.00 12 0 10f689e8-e6cc-47a3-be5a-dbc3833428ef EV200
- 2 379 85.09 370.89 59.9 63.99 4.01 0.00 12 0 10f689e8-e6cc-47a3-be5a-dbc3833428ef EV200
- 3 379 85.09 0.00 0.0 64.99 4.01 0.00 12 0 10f689e8-e6cc-47a3-be5a-dbc3833428ef EV200
- 4 379 85.09 0.00 0.0 66.00 4.03 1.55 12 11 10f689e8-e6cc-47a3-be5a-dbc3833428ef EV200
- 5 379 85.09 0.00 0.0 67.00 4.03 0.00 12 0 10f689e8-e6cc-47a3-be5a-dbc3833428ef EV200
- 6 379 85.09 0.00 0.0 68.00 4.05 0.00 13 0 10f689e8-e6cc-47a3-be5a-dbc3833428ef EV200
机器配置:

R version:
- > version
- _
- platform x86_64-w64-mingw32
- arch x86_64
- os mingw32
- system x86_64, mingw32
- status
- major 3
- minor 2.5
- year 2016
- month 04
- day 14
- svn rev 70478
- language R
- version.string R version 3.2.5 (2016-04-14)
- nickname Very, Very Secure Dishes
R包性能对比
全局函数及参数设置
- ##----------------------全局设置-------------------------------
- remove(list=ls())
- space_path <- c("E:\\RScore\\kmeans\\")
- setwd(space_path)
- Sys.setlocale(category = "LC_ALL",local="chinese")
- ##table 行列转换函数
- tblView <- function (tbl)
- {
- ##install.packages("tidyr")
- library(tidyr)
- df <- as.data.frame(tbl)
- df <- spread(data = df, key = Var2, value = Freq)
- datatable(df)
- }
- ## 公共函数:数据读写及计算
- source("core.R",encoding="utf-8")
- teld.ml.init()
- ##训练样本
- car.train <- teld.ml.rQuery("D_Cluster")
- newdata <- car.train[1:8]
stats::kmeans
source code:
- > ################################################stats::kmeans######################################
- > startTime <- Sys.time();
- >
- > library(stats)
- > kc <- kmeans(x=newdata, centers = 13)
- > #plot(newdata[,c("DV","DC")],col=kc$cluster)
- > tbl <- table(car.train$TypeName,kc$cluster)
- > tblView(tbl)
- >
- > ##耗时间
- > endTime <- Sys.time()
- > difTime <- difftime(endTime,startTime,units = "secs")
- > print(paste0("stats::kmeans total time:", difTime))
- [1] "stats::kmeans total time:0.195545196533203"
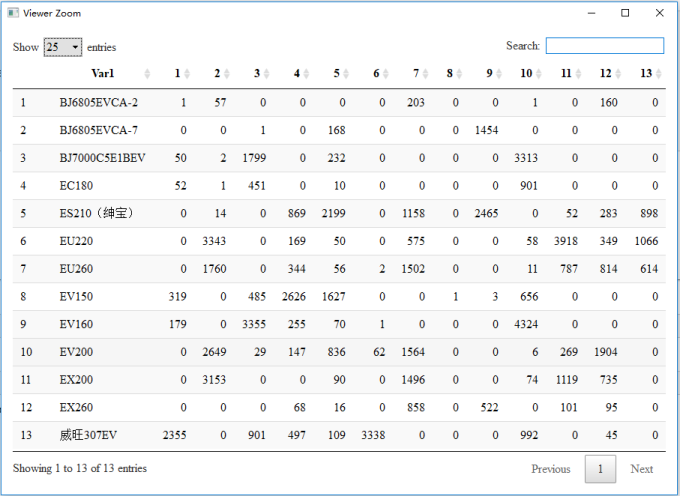
- stats::kmeans total time:0.195545196533203, result view:
fpc::kmeansruns
source code:
- > ################################################fpc::kmeansruns######################################
- > startTime <- Sys.time();
- >
- > library(fpc)
- > kc1 <- kmeansruns(data = newdata,krange = 1:15,critout = TRUE)
- 2 clusters 9394.437
- 3 clusters 185919.7
- 4 clusters 482630.4
- 5 clusters 414875.3
- 6 clusters 376338
- 7 clusters 334493.6
- 8 clusters 303976.7
- 9 clusters 279036.3
- 10 clusters 432009.9
- 11 clusters 363074.8
- 12 clusters 405784.7
- 13 clusters 397422.8
- 14 clusters 371842.5
- 15 clusters 408561.7
- Warning messages:
- 1: Quick-TRANSfer stage steps exceeded maximum (= 3507150)
- 2: Quick-TRANSfer stage steps exceeded maximum (= 3507150)
- 3: Quick-TRANSfer stage steps exceeded maximum (= 3507150)
- > tbl<- table(car.train$TypeName,kc1$cluster)
- > tblView(tbl)
- >
- > ##耗时间
- > endTime <- Sys.time()
- > difTime <- difftime(endTime,startTime,units = "secs")
- > print(paste0("fpc::kmeansruns total time:", difTime))
- [1] "fpc::kmeansruns total time:107.454074859619"
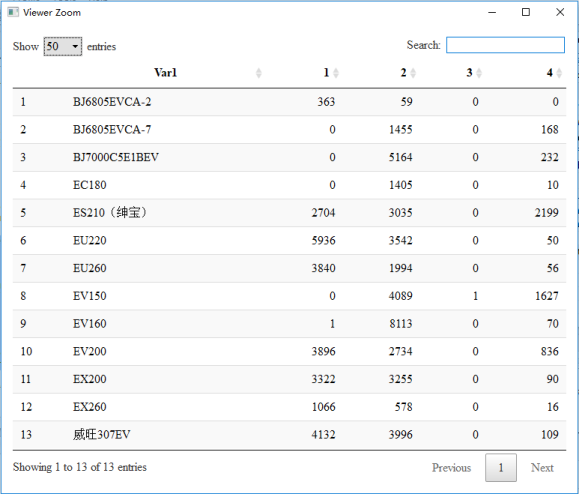
- [1] "fpc::kmeansruns total time:107.454074859619" result view:
cluster::pam
source code
- > ################################################cluster::pam######################################
- >
- > library(cluster)
- > cPam <- pam(x=newdata,k=13)
- Error in pam(x = newdata, k = 13) :
- have 70143 observations, but not more than 65536 are allowed
Error: 待确认
fpc::pamk
source code
- > ################################################fpc::pamk######################################
- >
- > library(fpc)
- > fPamk <- pamk(newdata,krang=1:15)
- Error in pam(sdata, k, diss = diss, ...) :
- have 70143 observations, but not more than 65536 are allowed
Error: 待确认
stats::hclust
source code:
- ################################################fpc::pamk######################################
- >
- > library(fpc)
- > fPamk <- pamk(newdata,krang=1:15)
- Error in pam(sdata, k, diss = diss, ...) :
- have 70143 observations, but not more than 65536 are allowe
Error: 待确认
mclust::Mclust
source code:
- > ################################################mclust::Mclust######################################
- > library(mclust)
- > EM<-Mclust(newdata)
- Error in hcVVV(data = c(379, 379, 379, 379, 379, 379, 379, 379, 379, 379, :
- NAs in foreign function call (arg 13)
- In addition: Warning message:
- In hcVVV(data = c(379, 379, 379, 379, 379, 379, 379, 379, 379, 379, :
- NAs introduced by coercion to integer range
Error: 待确认
cluster::fanny
source code:
- > ################################################cluster::fanny######################################
- > library(cluster)
- > fannyz=fanny(newdata,13,metric="SqEuclidean")
- Error in fanny(newdata, 13, metric = "SqEuclidean") :
- long vectors (argument 5) are not supported in .Fortran
Error: 待确认
e1071::cmeans
source code:
- > ################################################e1071::cmeans######################################
- > startTime <- Sys.time();
- >
- > library("e1071")
- > eCm<-cmeans(newdata,15)
- > tbl <- table(car.train$TypeName,eCm$cluster)
- > tblView(tbl)
- >
- > ##耗时间
- > endTime <- Sys.time()
- > difTime <- difftime(endTime,startTime,units = "secs")
- > print(paste0("stats::kmeans total time:", difTime))
- [1] "stats::kmeans total time:8.7237401008606"
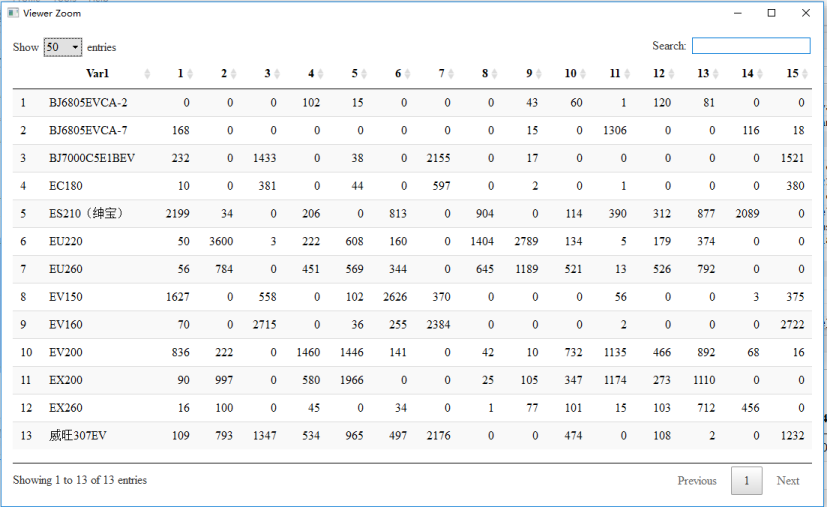
[1] "stats::kmeans total time:8.7237401008606" result view:
待验证
ML: 聚类算法R包-对比的更多相关文章
- ML: 聚类算法R包 - 模型聚类
模型聚类 mclust::Mclust RWeka::Cobweb mclust::Mclust EM算法也称为期望最大化算法,在是使用该算法聚类时,将数据集看作一个有隐形变量的概率模型,并实现模型最 ...
- ML: 聚类算法R包-层次聚类
层次聚类 stats::hclust stats::dist R使用dist()函数来计算距离,Usage: dist(x, method = "euclidean", di ...
- ML: 聚类算法R包-模糊聚类
1965年美国加州大学柏克莱分校的扎德教授第一次提出了'集合'的概念.经过十多年的发展,模糊集合理论渐渐被应用到各个实际应用方面.为克服非此即彼的分类缺点,出现了以模糊集合论为数学基础的聚类分析.用模 ...
- ML: 聚类算法R包-网格聚类
网格聚类算法 optpart::clique optpart::clique CLIQUE(Clustering In QUEst)是一种简单的基于网格的聚类方法,用于发现子空间中基于密度的簇.CLI ...
- ML: 聚类算法R包-K中心点聚类
K-medodis与K-means比较相似,但是K-medoids和K-means是有区别的,不一样的地方在于中心点的选取,在K-means中,我们将中心点取为当前cluster中所有数据点的平均值, ...
- ML: 聚类算法R包 - 密度聚类
密度聚类 fpc::dbscan fpc::dbscan DBSCAN核心思想:如果一个点,在距它Eps的范围内有不少于MinPts个点,则该点就是核心点.核心和它Eps范围内的邻居形成一个簇.在一个 ...
- ML: 聚类算法-K均值聚类
基于划分方法聚类算法R包: K-均值聚类(K-means) stats::kmeans().fpc::kmeansruns() K-中心点聚类(K-Medoids) ...
- ML: 聚类算法-概论
聚类分析是一种重要的人类行为,早在孩提时代,一个人就通过不断改进下意识中的聚类模式来学会如何区分猫狗.动物植物.目前在许多领域都得到了广泛的研究和成功的应用,如用于模式识别.数据分析.图像处理.市场研 ...
- 【转】利用python的KMeans和PCA包实现聚类算法
转自:https://www.cnblogs.com/yjd_hycf_space/p/7094005.html 题目: 通过给出的驾驶员行为数据(trip.csv),对驾驶员不同时段的驾驶类型进行聚 ...
随机推荐
- WebService远程调用技术
1.---------------------------------介绍-------------------------------------------------- (1)远程调用:一个系统 ...
- 标准I/O读写文件
一.函数原型 1.FILE *fopen(const char *path, const char *mode); path:要打开文件路径及文件名: mode: r 打开只读文件,该文件必须存在. ...
- Java 构造器Constructor 继承
Java默认构造方法 构造方法作用:初始化所定义的类的对象和属性. 构造方法没有返回类型. 2 继承中的构造器 子类是不继承父类的构造器(构造方法或者构造函数)的,它只是调用(隐式或显式). 如果父类 ...
- Oracle查询行对应block_id,file_id
select id,rowid, dbms_rowid.rowid_object(rowid) object#, dbms_rowid.rowid_relative_fno(rowid) file#, ...
- ImportError: No module named 'xml'
/********************************************************************************* * ImportError: No ...
- [LeetCode&Python] Problem 520. Detect Capital
Given a word, you need to judge whether the usage of capitals in it is right or not. We define the u ...
- Gym - 101981M:(南京) Mediocre String Problem(回文树+exkmp)
#include<bits/stdc++.h> #define ll long long #define rep(i,a,b) for(int i=a;i<=b;i++) using ...
- 如何在git上创建的本地仓库
一.安装git(在git) 二. 三.输入个人信息(代码提交者) git config --global user.name "xxxx" git config --global ...
- xdoj 1028 (素数线性筛+dp)
#include <bits/stdc++.h> using namespace std; ; int prime[N]; int dp[N]; int main () { memset ...
- rest-framework之版本控制
rest-framework之版本控制 本文目录 一 作用 二 内置的版本控制类 三 局部使用 四 全局使用 五 示例 源码分析 回到目录 一 作用 用于版本的控制 回到目录 二 内置的版本控制类 f ...