论文笔记之:Deep Attention Recurrent Q-Network
Deep Attention Recurrent Q-Network
5vision groups
摘要:本文将 DQN 引入了 Attention 机制,使得学习更具有方向性和指导性。(前段时间做一个工作打算就这么干,谁想到,这么快就被这几个孩子给实现了,自愧不如啊( ⊙ o ⊙ ))
引言:我们知道 DQN 是将连续 4帧的视频信息输入到 CNN 当中,那么,这么做虽然取得了不错的效果,但是,仍然只是能记住这 4 帧的信息,之前的就会遗忘。所以就有研究者提出了 Deep Recurrent Q-Network (DRQN),一个结合 LSTM 和 DQN 的工作:
1. the fully connected layer in the latter is replaced for a LSTM one ,
2. only the last visual frame at each time step is used as DQN's input.
作者指出虽然只是使用了一帧的信息,但是 DRQN 仍然抓住了帧间的相关信息。尽管如此,仍然没有看到在 Atari game上有系统的提升。
另一个缺点是:长时间的训练时间。据说,在单个 GPU 上训练时间达到 12-14天。于是,有人就提出了并行版本的算法来提升训练速度。作者认为并行计算并不是唯一的,最有效的方法来解决这个问题。
最近 visual attention models 在各个任务上都取得了惊人的效果。利用这个机制的优势在于:仅仅需要选择然后注意一个较小的图像区域,可以帮助降低参数的个数,从而帮助加速训练和测试。对比 DRQN,本文的 LSTM 机制存储的数据不仅用于下一个 actions 的选择,也用于 选择下一个 Attention 区域。此外,除了计算速度上的改进之外,Attention-based models 也可以增加 Deep Q-Learning 的可读性,提供给研究者一个机会去观察 agent 的集中区域在哪里以及是什么,(where and what)。
Deep Attention Recurrent Q-Network:
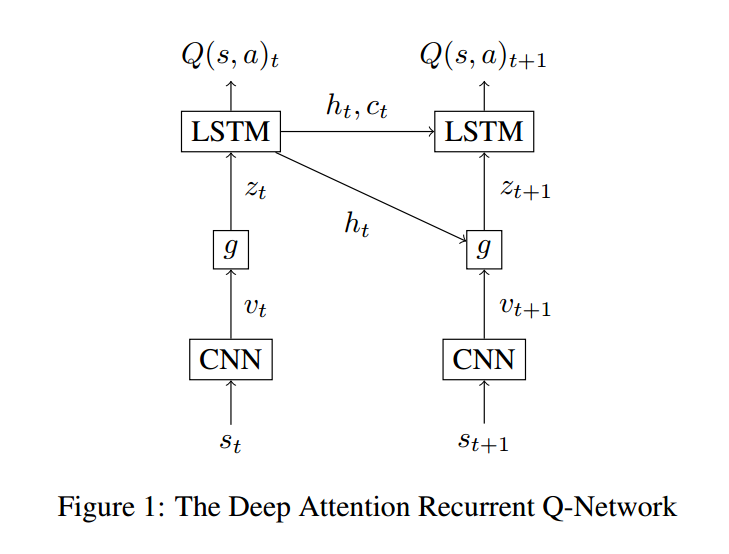
如上图所示,DARQN 结构主要由 三种类型的网络构成:convolutional (CNN), attention, and recurrent . 在每一个时间步骤 t,CNN 收到当前游戏状态 $s_t$ 的一个表示,根据这个状态产生一组 D feature maps,每一个的维度是 m * m。Attention network 将这些 maps 转换成一组向量 $v_t = \{ v_t^1, ... , v_t^L \}$,L = m*m,然后输出其线性组合 $z_t$,称为 a context vector. 这个 recurrent network,在我们这里是 LSTM,将 context vector 作为输入,以及 之前的 hidden state $h_{t-1}$,memory state $c_{t-1}$,产生 hidden state $h_t$ 用于:
1. a linear layer for evaluating Q-value of each action $a_t$ that the agent can take being in state $s_t$ ;
2. the attention network for generating a context vector at the next time step t+1.
Soft attention :
这一小节提到的 "soft" Attention mechanism 假设 the context vector $z_t$ 可以表示为 所有向量 $v_t^i$ 的加权和,每一个对应了从图像不同区域提取出来的 CNN 特征。权重 和 这个 vector 的重要程度成正比例,并且是通过 Attention network g 衡量的。g network 包含两个 fc layer 后面是一个 softmax layer。其输出可以表示为:
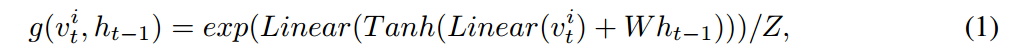
其中,Z是一个normalizing constant。W 是权重矩阵,Linear(x) = Ax + b 是一个放射变换,权重矩阵是A,偏差是 b。我们一旦定义出了每一个位置向量的重要性,我们可以计算出 context vector 为:

另一个网络在第三小节进行详细的介绍。整个 DARQN model 是通过最小化序列损失函数完成训练:
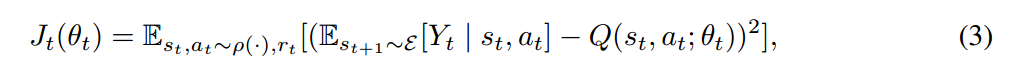
其中,$Y_t$ 是一个近似的 target value,为了优化这个损失函数,我们利用标准的 Q-learning 更新规则:
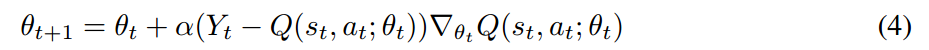
DARQN 中的 functions 都是可微分的,所以每一个参数都有梯度,整个模型可以 end-to-end 的进行训练。本文的算法也借鉴了 target network 和 experience replay 的技术。
Hard Attention:
此处的 hard attention mechanism 采样的时候要求仅仅从图像中采样一个图像 patch。
假设 $s_t$ 从环境中采样的时候,受到了 attention policy 的影响,attention network g 的softmax layer 给出了带参数的类别分布(categorical distribution)。然后,在策略梯度方法,策略参数的更新可以表示为:

其中 $R_t$ 是将来的折扣的损失。为了估计这个值,另一个网络 $G_t = Linear(h_t)$ 才引入进来。这个网络通过朝向 期望值 $Y_t$ 进行网络训练。Attention network 参数最终的更新采用如下的方式进行:

其中 $G_t - Y_t$ 是advantage function estimation。
作者提供了源代码:https://github.com/5vision/DARQN
实验部分:
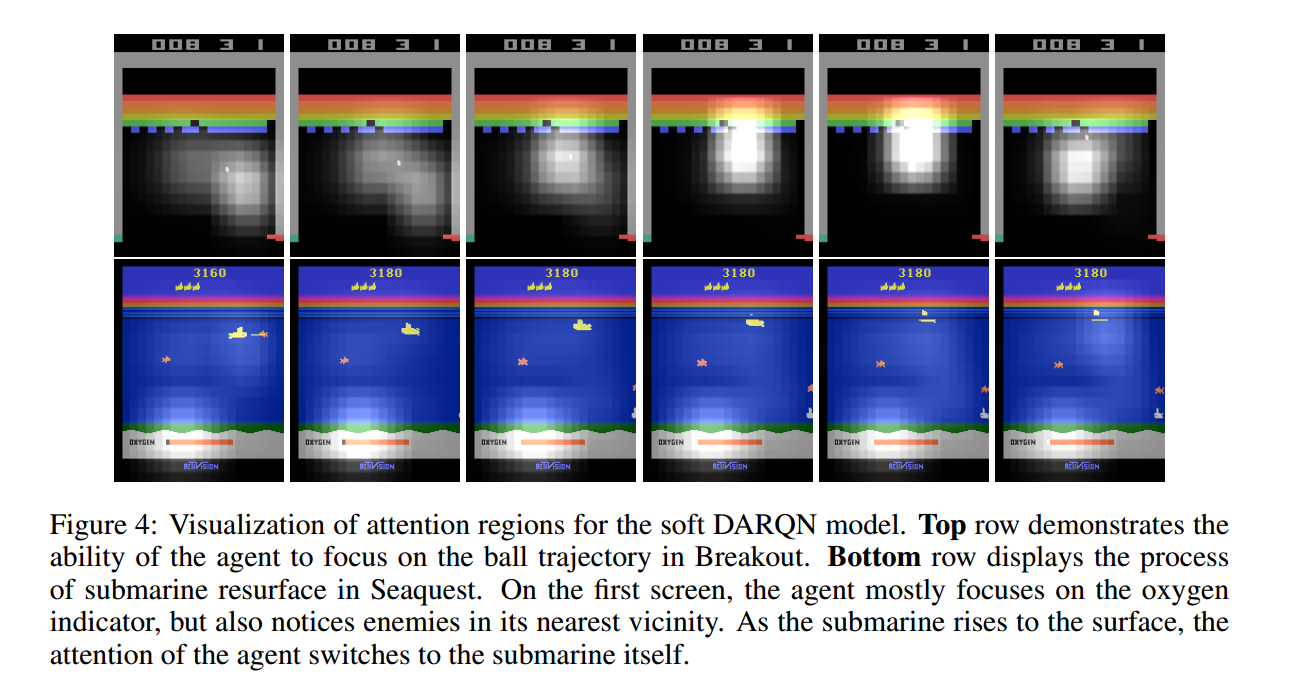
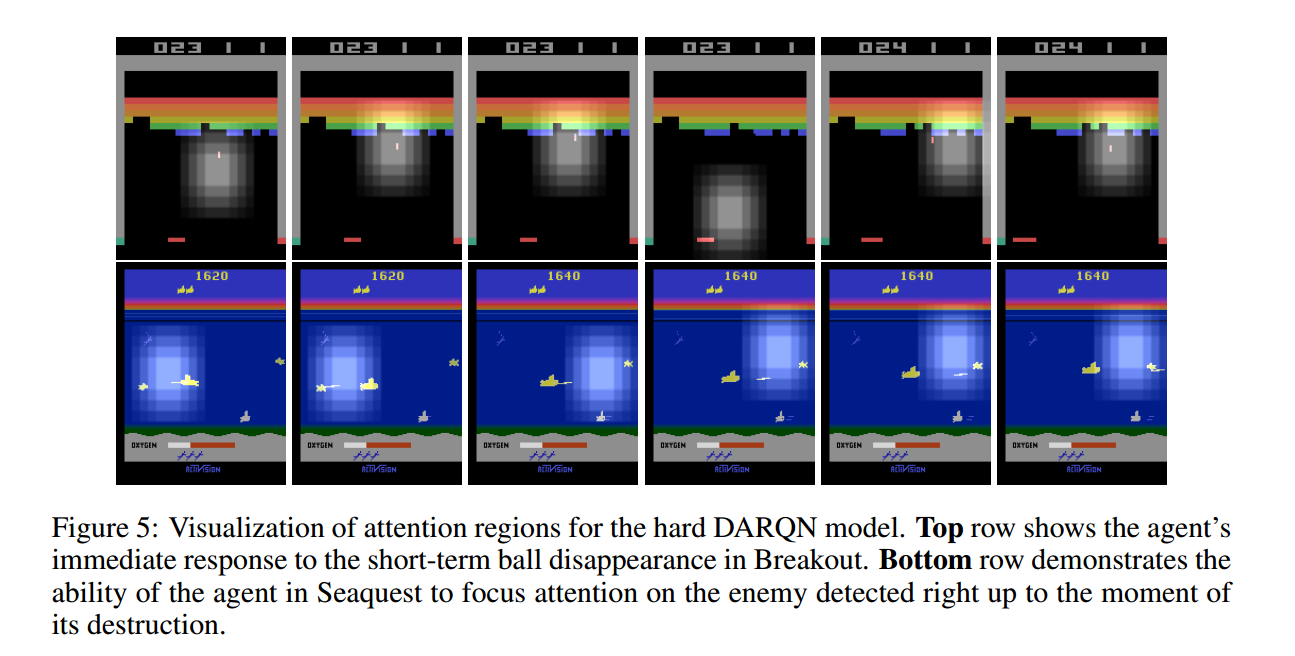
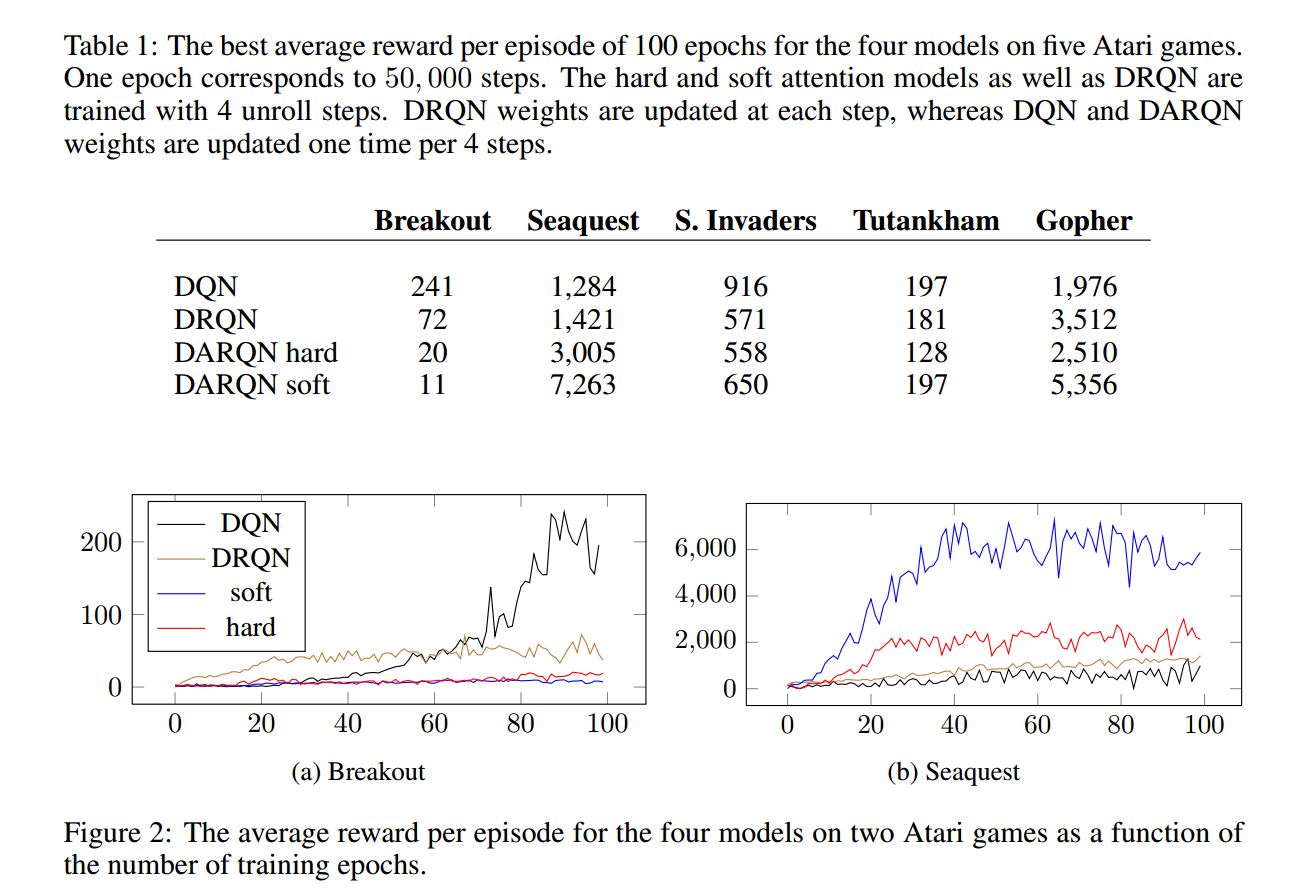

总结:
论文笔记之:Deep Attention Recurrent Q-Network的更多相关文章
- 论文笔记:ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks
ReNet: A Recurrent Neural Network Based Alternative to Convolutional Networks2018-03-05 11:13:05 ...
- 论文笔记 《Maxout Networks》 && 《Network In Network》
论文笔记 <Maxout Networks> && <Network In Network> 发表于 2014-09-22 | 1条评论 出处 maxo ...
- 论文笔记——A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding
论文<A Deep Neural Network Compression Pipeline: Pruning, Quantization, Huffman Encoding> Prunin ...
- 论文笔记:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning NIPS18_tracking Type:Tracking-By-Detection 本篇论文地主 ...
- 论文笔记之:RATM: RECURRENT ATTENTIVE TRACKING MODEL
RATM: RECURRENT ATTENTIVE TRACKING MODEL ICLR 2016 本文主要内容是 结合 RNN 和 attention model 用来做目标跟踪. 其中模型的组成 ...
- 论文笔记之:Attention For Fine-Grained Categorization
Attention For Fine-Grained Categorization Google ICLR 2015 本文说是将Ba et al. 的基于RNN 的attention model 拓展 ...
- 论文笔记:Deep feature learning with relative distance comparison for person re-identification
这篇论文是要解决 person re-identification 的问题.所谓 person re-identification,指的是在不同的场景下识别同一个人(如下图所示).这里的难点是,由于不 ...
- 论文笔记:Deep Residual Learning
之前提到,深度神经网络在训练中容易遇到梯度消失/爆炸的问题,这个问题产生的根源详见之前的读书笔记.在 Batch Normalization 中,我们将输入数据由激活函数的收敛区调整到梯度较大的区域, ...
- 论文笔记 Pose-driven Deep Convolutional Model for Person Re-identification_tianqi_2017_ICCV
1. 摘要 为解决姿态变化的问题,作者提出Pose-driven-deep convolutional model(PDC),结合了global feature跟local feature, 而loc ...
随机推荐
- oracle 之索引,同义词 ,关键词,视图 ,存储过程,函数,触发器
--创建索引 关键词 index create[unique] index index_name on table_name(column_name [,column_name…]) [tablesp ...
- CAD迷你看图
CAD迷你看图http://www.aec188.com/CAD迷你看图 2016R12超快.超小的CAD多功能看图工具,完全脱离AutoCAD浏览R14-R2016各版本DWG/DXF/DWF的二三 ...
- zoj 1203 Swordfish prim算法
#include "stdio.h". #include <iostream> #include<math.h> using namespace std; ...
- ABAP之PINYING拼音
前面说了声母韵母,那么现在来说说ABAP里的拼音——域,数据元素,结构 PINGGUO = 苹果 T-CODE : SE11 如下图 域:是一些特定值的集合,或者某一种特殊用途的集合.如:需要定义 ...
- qml 封装技巧-利用数据来进行适配
Text属于用的频率比较高而且需要定义的地方又比较多的地方,看一下如下的把Text封装成Label进行使用. 使用的例子: Label { id: titleLabel anchors { left: ...
- 嵌入式文件I/O操作
今天把这块的东西算是看完了.总结一下,(1)这里包括底层文件的I/O操作,实际上是系统调用函数借口,是基于文件描述符的文件操作:(2)还有标准I/O操作,是基于缓冲流的文件操作:还有(3)串口的操作, ...
- Swift学习
Swift 中文教程(一)基础数据类型 基础类型 虽然Swift是一个为开发iOS和OS X app设计的全新编程语言,但是Swift的很多特性还是跟和Objective-C相似. Swift也提供了 ...
- 【62测试】【状压dp】【dfs序】【线段树】
第一题: 给出一个长度不超过100只包含'B'和'R'的字符串,将其无限重复下去. 比如,BBRB则会形成 BBRBBBRBBBRB 现在给出一个区间[l,r]询问该区间内有多少个字符'B'(区间下标 ...
- mybaits入门
1.回顾jdbc开发 orm概述 orm是一种解决持久层对象关系映射的规则,而不是一种具体技术.jdbc/dbutils/springdao,hibernate/springorm,mybaits同属 ...
- Java 获取网络重定向文件的真实URL
其实Java 使用HttpURLConnection下载的的时候,会自动下载重定向后的文件,但是我们无法获知目标文件的真实文件名,文件类型,用下面的方法可以得到真实的URL,下面是一个YOUKU视频的 ...